Diseño de arquitectura de bases de datos
En este artículo se proporciona información general sobre las soluciones de Azure Database que se describen en el Centro de arquitectura de Azure.
Apache®, Apache Cassandra® y el logotipo de Hadoop son marcas registradas o marcas comerciales de Apache Software Foundation en Estados Unidos y otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
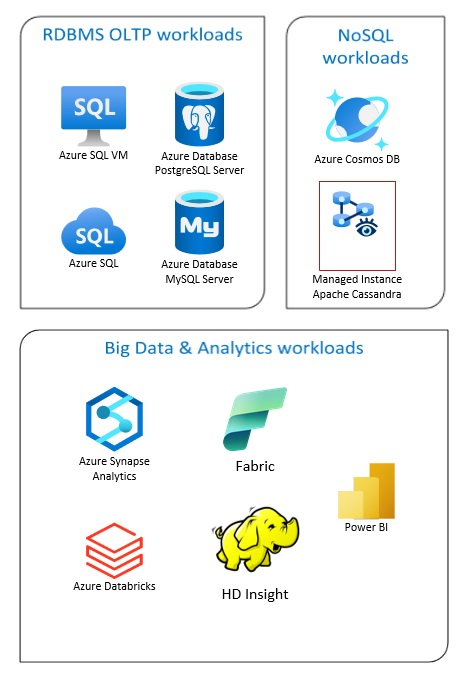
Las soluciones de Azure Database incluyen sistemas tradicionales de administración de bases de datos relacionales (RDBMS y OLTP), cargas de trabajo de macrodatos y análisis (como OLAP) y cargas de trabajo de NoSQL.
Las cargas de trabajo RDBMS utilizan procesamiento de transacciones en línea (OLTP) y procesamiento analítico en línea (OLAP). Los datos de varios orígenes de la organización se pueden consolidar en un almacenamiento de datos. Puede utilizar un proceso de extracción, transformación y carga (ETL) o de extracción, carga y transformación (ELT) para mover y transformar los datos de origen. Para obtener más información sobre las bases de datos RDBMS, consulte Exploración de bases de datos relacionales en Azure.
Una arquitectura de macrodatos está diseñada para controlar la ingesta, el procesamiento y el análisis de datos grandes o complejos. Las soluciones de macrodatos suelen implicar una gran cantidad de datos relacionales y no relacionales y los sistemas RDBMS tradicionales no son adecuados para almacenarlos. Normalmente, se requieren soluciones como Data Lakes, Delta Lakes y lakehouses (almacenes de datos y data lakes). Consulte más información en Diseño de arquitectura de análisis.
Las bases de datos NoSQL se denominan indistintamente no relacionales, bases de datos NoSQL o no SQL para resaltar el hecho de que pueden trabajar con grandes volúmenes de datos no estructurados que cambian rápidamente. No almacenan datos en tablas, filas y columnas, como las bases de datos (SQL). Para obtener más información sobre las bases de datos NoSQL, consulte Datos NoSQL y ¿Qué son las bases de datos NoSQL?.
En este artículo se proporcionan recursos para obtener información sobre las bases de datos de Azure. Describe las rutas de acceso para implementar las arquitecturas que satisfagan sus necesidades y los procedimientos recomendados que se deben tener en cuenta al diseñar las soluciones.
Hay muchas arquitecturas que puede aprovechar para satisfacer las necesidades de base de datos. También proporcionamos ideas de solución que puede aprovechar, entre las que se incluyen vínculos a todos los componentes que necesita.
Más información sobre las bases de datos en Azure
Cuando empiece a pensar en las posibles arquitecturas de la solución, lo primero que debe hacer es elegir el almacén de datos correcto. Si no está familiarizado con las bases de datos en Azure, el mejor punto de partida es Microsoft Learn. Esta plataforma en línea, gratuita proporciona vídeos y tutoriales para el aprendizaje práctico. Microsoft Learn ofrece rutas de aprendizaje basadas en su rol de trabajo, como desarrollador o analista de datos.
Puede empezar con una descripción general de las distintas bases de datos de Azure y su uso. También puede examinar los módulos de datos de Azure y Selección de un enfoque de almacenamiento de datos en Azure. Estos artículos le ayudan a comprender las opciones de soluciones de datos Azure y a saber por qué se recomiendan algunas soluciones en escenarios específicos.
Estos son algunos módulos de Learn que pueden resultar útiles:
- Diseño de la migración a Azure
- Implementación de Azure SQL Database
- Exploración de los servicios de análisis y bases de datos de Azure
- Protección de las bases de datos de Azure SQL
- Azure Cosmos DB
- Azure Database para PostgreSQL
- Azure Database for MySQL
- SQL Server en máquinas virtuales de Azure
Ruta hacia la producción
Para buscar opciones útiles para tratar con datos relacionales, tenga en cuenta estos recursos:
- Para obtener información sobre los recursos para recopilar datos de varios orígenes y cómo aplicar transformaciones de datos en los canales de datos, consulte Análisis en Azure.
- Para obtener información sobre OLAP, que organiza grandes bases de datos empresariales y proporciona análisis complejo, consulte Procesamiento analítico en línea.
- Para obtener información sobre los sistemas de OLTP que registran interacciones empresariales a medida que se producen,consulte Procesamiento de transacciones en línea.
Una base de datos no relacional no usa el esquema tabular de filas y columnas. Para obtener más información, consulte Datos no relacionales y NoSQL.
Para obtener información sobre los lagos de datos, que contienen una gran cantidad de datos en su formato nativo y sin procesar, consulte Lagos de datos.
Una arquitectura de macrodatos puede controlar la ingesta, el procesamiento y el análisis de datos que son demasiado grandes o complejos para los sistemas de bases de datos tradicionales. Para obtener más información, consulte Arquitecturas de macrodatos y Análisis.
Una nube híbrida es un entorno de TI que combina la nube pública y centros de datos locales. Para más información, considere la posibilidad de azure Arc combinadas con bases de datos de Azure.
Azure Cosmos DB es un servicio de bases de datos NoSQL totalmente administrado para el desarrollo de aplicaciones modernas. Para más información, consulte Modelo de recursos de Azure Cosmos DB.
Para obtener información sobre las opciones para transferir datos hacia y desde Azure, consulte Transferencia de datos hacia y desde Azure.
Procedimientos recomendados
Revise estos procedimientos recomendados al diseñar las soluciones.
| Procedimientos recomendados | Descripción |
|---|---|
| Patrón de bandeja de salida transaccional con Azure Cosmos DB | Aprenda a usar el patrón de bandeja de salida transaccional para la mensajería confiable y la entrega garantizada de eventos. |
| Distribución de los datos globalmente con Azure Cosmos DB | Para lograr baja latencia y alta disponibilidad, algunas aplicaciones deben implementarse en centros de datos que están cerca de sus usuarios. |
| Seguridad en Azure Cosmos DB | Los procedimientos recomendados de seguridad ayudan a evitar y detectar vulneraciones en bases de datos, así como a responder a estos incidentes. |
| Copia de seguridad continua con la característica de restauración a un momento dado de Azure Cosmos DB | Obtenga información sobre la característica de restauración a un momento dado de Azure Cosmos DB. |
| Consiga alta disponibilidad con Azure Cosmos DB | Azure Cosmos DB proporciona varias características y opciones de configuración para lograr una alta disponibilidad. |
| Alta disponibilidad para Azure SQL Database e Instancia administrada de SQL | La base de datos no debe ser un único punto de error en la arquitectura. |
Opciones de tecnología
Hay muchas opciones a disposición de las tecnologías para que las usen con las bases de datos de Azure. Estos artículos le ayudarán a elegir las mejores tecnologías según sus necesidades.
- Elegir un almacén de datos
- Elección de un almacén de datos analíticos en Azure
- Elección de una tecnología de análisis de datos en Azure
- Selección de una tecnología de procesamiento por lotes en Azure
- Elección de una tecnología de almacenamiento de macrodatos en Azure
- Elección de una tecnología de orquestación de canalizaciones de datos en Azure
- Elección de un almacén de datos de búsqueda en Azure
- Selección de una tecnología de procesamiento de flujos en Azure
Mantenerse al día con las bases de datos
Consulte las actualizaciones de Azure para mantenerse al día con la tecnología de bases de datos de Azure.
Recursos relacionados
- Escenario de Adatum Corporation para la administración y el análisis de datos en Azure
- Escenario de Lamna Healthcare para la administración y el análisis de datos en Azure
- Optimización de la administración de instancias de SQL Server
- Escenario de Relecloud para la administración y el análisis de datos en Azure
Productos de base de datos similares
Si ya conoce Amazon Web Services (AWS) o Google Cloud, vea las comparaciones siguientes: