Esta arquitectura de referencia muestra una arquitectura sin servidor orientada a eventos que ingiere un flujo de datos, procesa los datos y escribe los resultados en una base de datos de back-end.
Architecture
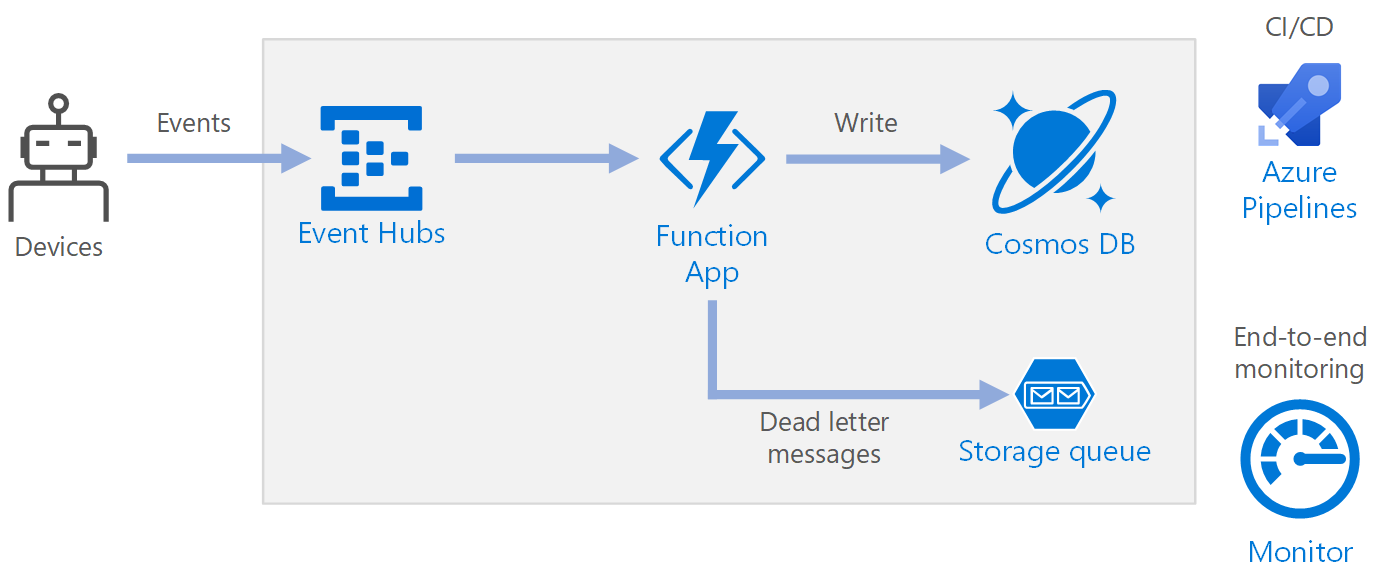
Flujo de trabajo
- Los eventos llegan a Azure Event Hubs.
- Se desencadena una aplicación de funciones para controlar el evento.
- El evento se almacena en una base de datos de Azure Cosmos DB.
- Si la aplicación de funciones no puede almacenar el evento correctamente, este se guarda en una cola de Storage para el procesamiento posterior.
Componentes
Event Hubs ingiere el flujo de datos. Event Hubs está diseñado para escenarios de transmisión de datos de alto rendimiento.
Nota
En escenarios de Internet de las cosas (IoT), se recomienda Azure IoT Hub. IoT Hub tiene un punto de conexión integrado que es compatible con la API de Azure Event Hubs, por lo que puede usar cualquiera de los servicios en esta arquitectura sin realizar ningún cambio importante en el procesamiento de back-end. Para más información, consulte Conexión de dispositivos IoT a Azure: IoT Hub y Event Hubs.
Aplicación de función. Azure Functions es una opción de proceso sin servidor. Utiliza un modelo orientado a eventos, en el que un desencadenador invoca un fragmento de código (una función). En esta arquitectura, cuando los eventos llegan a Event Hubs, desencadenan una función que procesa los eventos y escribe los resultados en el almacenamiento.
Las aplicaciones de función son convenientes para procesar registros individuales procedentes de Event Hubs. Para escenarios de procesamiento de flujos más complejos, considere la posibilidad de usar Apache Spark con Azure Databricks o Azure Stream Analytics.
Azure Cosmos DB. Cosmos DB es un servicio de base de datos de varios modelos que está disponible en un modo sin servidor basado en el consumo. En este escenario, la función de procesamiento de eventos almacena registros JSON mediante Azure Cosmos DB for NoSQL.
Queue Storage. Queue Storage se usa para los mensajes fallidos. Si se produce un error al procesar un evento, la función almacena los datos del evento en una cola de mensajes fallidos para su procesamiento posterior. Para más información, consulte la sección Resistencia más adelante en este artículo.
Azure Monitor. Monitor recopila métricas de rendimiento sobre los servicios de Azure implementados en la solución. Puede visualizarlas en un panel para obtener visibilidad del mantenimiento de la solución.
Azure Pipelines. Pipelines es un servicio de integración continua (CI) y entrega continua (CD) que compila, prueba e implementa la aplicación.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Disponibilidad
La implementación que se muestra aquí reside en una sola región de Azure. Para un enfoque más resistente a la recuperación ante desastres, aproveche las ventajas de las características de distribución geográfica de los distintos servicios:
- Event Hubs. Cree dos espacios de nombres de Event Hubs, un espacio de nombres principal (activo) y un espacio de nombres secundario (pasivo). Los mensajes se enrutan automáticamente al espacio de nombres activo a menos que realice una conmutación por error al espacio de nombres secundario. Para más información, consulte Recuperación ante desastres con localización geográfica de Azure Event Hubs.
- Aplicación de función. Implemente una segunda aplicación de función que está a la espera para leer desde el espacio de nombres secundario de Event Hubs. Esta función escribe en una cuenta de almacenamiento secundaria para la cola de mensajes fallidos.
- Azure Cosmos DB. Azure Cosmos DB admite varias regiones de escritura, lo que permite escribir en cualquier región que se agregue a la cuenta de Azure Cosmos DB. Si no habilita la funcionalidad de escritura múltiple, todavía puede conmutar por error a la región de escritura principal. Los SDK de cliente de Azure Cosmos DB y los enlaces de la función de Azure controlan automáticamente la conmutación por error, por lo que no es necesario actualizar los parámetros de configuración de la aplicación.
- Azure Storage. Use almacenamiento con redundancia geográfica con acceso de lectura para la cola de mensajes fallidos. Esto crea una réplica de solo lectura en otra región. Si la región primaria deja de estar disponible, puede leer los elementos que hay actualmente en la cola. Además, aprovisione otra cuenta de almacenamiento en la región secundaria en la que la función pueda escribir después de una conmutación por error.
Escalabilidad
Event Hubs
La capacidad de procesamiento de Event Hubs se mide en unidades de procesamiento. Para escalar un centro de eventos automáticamente, puede habilitar el inflado automático, que permite escalar las unidades de procesamiento en función del tráfico, hasta un máximo configurado.
El desencadenador de Event Hubs de la aplicación de funciones se escala según el número de particiones del centro de eventos. Se asigna una instancia de la función a cada partición cada vez. Para maximizar el rendimiento, es posible recibir los eventos en un lote, en lugar de uno cada vez.
Azure Cosmos DB
Azure Cosmos DB está disponible en dos modos de capacidad diferentes:
- Sin servidor, para cargas de trabajo con tráfico intermitente o imprevisible y una baja relación de tráfico de promedio a pico.
- Rendimiento aprovisionado, para cargas de trabajo con tráfico sostenido que requieren un rendimiento predecible.
Para asegurarse de que la carga de trabajo sea escalable, es importante elegir una clave de partición adecuada al crear los contenedores de Azure Cosmos DB. Estas son algunas características de una buena clave de partición:
- El espacio de valores de la clave es grande.
- Habrá una distribución uniforme de lecturas y escrituras por valor de clave, evitando las claves frecuentes.
- El máximo de datos almacenados para cualquier valor de clave único no superará el tamaño de partición física máximo (20 GB).
- La clave de partición de un documento no cambiará. No se puede actualizar la clave de partición de un documento existente.
En el escenario de esta arquitectura de referencia, la función almacena exactamente un documento por cada dispositivo que envía datos. La función actualiza continuamente los documentos con el estado del dispositivo más reciente mediante una operación de actualización e inserción. El identificador de dispositivo es una buena clave de partición para este escenario, ya que las escrituras se distribuirán uniformemente entre las claves y el tamaño de cada partición estará enlazado estrictamente porque hay un documento único por cada valor de clave. Para más información sobre las claves de partición, consulte Particionado y escalado en Azure Cosmos DB.
Resistencia
Al usar el desencadenador de Event Hubs con Azure Functions, debe detectar las excepciones dentro del bucle de procesamiento. Si se produce una excepción no controlada, el runtime de Functions no vuelve a intentar el envío de los mensajes. Si no se puede procesar un mensaje, colóquelo en una cola de mensajes fallidos. Utilice un proceso fuera de banda para examinar los mensajes y determinar la acción correctiva.
El código siguiente muestra cómo se detectan las excepciones en la función de ingesta y cómo se colocan los mensajes no procesados en una cola de mensajes fallidos.
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
El código mostrado también registra las excepciones en Application Insights. Puede usar el número de secuencia y la clave de partición para correlacionar los mensajes fallidos con las excepciones en los registros.
Los mensajes de la cola de mensajes fallidos deben tener suficiente información para que pueda entender el contexto del error. En este ejemplo, la clase DeadLetterMessage contiene el mensaje con la excepción, los datos del cuerpo del evento original y el mensaje del evento deserializado (si está disponible).
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Use Azure Monitor para supervisar el centro de eventos. Si ve que hay entrada pero no hay salida, significa que no se están procesando los mensajes. En ese caso, vaya a Log Analytics y busque excepciones u otros errores.
DevOps
Use la infraestructura como código (IaC) siempre que sea posible. IaC administra los recursos de infraestructura, aplicación y almacenamiento con un enfoque declarativo similar al de Azure Resource Manager. De esta forma, podrá automatizar la implementación usando DevOps como una solución de integración continua y entrega continua (CI/CD). Las plantillas deben tener control de versiones e incluirse como parte de la canalización de versión.
Al crear plantillas, agrupe los recursos como una manera de organizarlos y aislarlos por carga de trabajo. Habitualmente, una carga de trabajo se considera una aplicación única sin servidor o una red virtual. El objetivo del aislamiento de las cargas de trabajo es asociar los recursos a un equipo, de modo que el equipo de DevOps pueda administrar de forma independiente todos los aspectos de esos recursos y realizar las operaciones de CI/CD.
A medida que implemente los servicios, deberá supervisarlos. Considere la posibilidad de usar Application Insights para que los desarrolladores puedan supervisar el rendimiento y detectar problemas.
Recuperación ante desastres
La implementación que se muestra aquí reside en una sola región de Azure. Para un enfoque más resistente a la recuperación ante desastres, aproveche las ventajas de las características de distribución geográfica de los distintos servicios:
Event Hubs. Cree dos espacios de nombres de Event Hubs, un espacio de nombres principal (activo) y un espacio de nombres secundario (pasivo). Los mensajes se enrutan automáticamente al espacio de nombres activo a menos que realice una conmutación por error al espacio de nombres secundario. Para más información, consulte Recuperación ante desastres con localización geográfica de Azure Event Hubs.
Aplicación de función. Implemente una segunda aplicación de función que está a la espera para leer desde el espacio de nombres secundario de Event Hubs. Esta función escribe en una cuenta de almacenamiento secundaria para la cola de mensajes fallidos.
Azure Cosmos DB. Azure Cosmos DB admite varias regiones de escritura, lo que permite escribir en cualquier región que se agregue a la cuenta de Azure Cosmos DB. Si no habilita la funcionalidad de escritura múltiple, todavía puede conmutar por error a la región de escritura principal. Los SDK de cliente de Azure Cosmos DB y los enlaces de la función de Azure controlan automáticamente la conmutación por error, por lo que no es necesario actualizar los parámetros de configuración de la aplicación.
Azure Storage. Use almacenamiento con redundancia geográfica con acceso de lectura para la cola de mensajes fallidos. Esto crea una réplica de solo lectura en otra región. Si la región primaria deja de estar disponible, puede leer los elementos que hay actualmente en la cola. Además, aprovisione otra cuenta de almacenamiento en la región secundaria en la que la función pueda escribir después de una conmutación por error.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Puede usar la calculadora de precios de Azure para calcular los costos. A continuación, se incluyen algunas otras consideraciones sobre Azure Functions y Azure Cosmos DB.
Azure Functions
Azure Functions admite dos modelos de hospedaje:
- Plan de consumo. La potencia de proceso se asigna automáticamente cuando se ejecuta el código.
- Plan de App Service. Se asigna un conjunto de máquinas virtuales al código. El plan de App Service define el número de máquinas virtuales y el tamaño de máquina virtual.
En esta arquitectura, cada evento que llega a Event Hubs desencadena una función que procesa ese evento. Respecto al costo, la recomendación es usar el plan de consumo, porque solo se paga por los recursos de proceso que se usen.
Azure Cosmos DB
Con Azure Cosmos DB, paga por las operaciones que realiza en la base de datos y por el almacenamiento consumido por los datos.
- Operaciones de la base de datos. La forma en que se le cobran las operaciones de base de datos depende del tipo de cuenta de Azure Cosmos DB que use.
- En el modo sin servidor, no tiene que aprovisionar ningún rendimiento al crear recursos en la cuenta de Azure Cosmos DB. Al final del período de facturación se le factura el número de unidades de solicitud consumidas por las operaciones de base de datos.
- En el modo de rendimiento aprovisionado, especifique el rendimiento que necesita en unidades de solicitud por segundo (RU/s) y se le facturará por hora para el rendimiento máximo aprovisionado durante una hora determinada. Nota: Dado que el modelo de rendimiento aprovisionado dedica recursos al contenedor o la base de datos, se le cobrará por el rendimiento aprovisionado, aunque no ejecute ninguna carga de trabajo.
- Almacenamiento. Se le cobra una tarifa plana por la cantidad total de almacenamiento (GB) usada por los datos y los índices en una hora concreta.
En esta arquitectura de referencia, la función almacena exactamente un documento por cada dispositivo que envía datos. La función actualiza continuamente los documentos con el estado del dispositivo más reciente mediante una operación de actualización e inserción de datos, que es económica en términos de almacenamiento consumido. Para más información, consulte el modelo de precios de Azure Cosmos DB.
Use la calculadora de capacidad de Azure Cosmos DB para obtener una estimación rápida del costo de la carga de trabajo.
Implementación de este escenario
 Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Pasos siguientes
- Introducción a Azure Functions
- Bienvenido a Azure Cosmos DB
- ¿Qué es Azure Queue Storage?
- Introducción a Azure Monitor
- Documentación de Azure Pipelines