Mover datos al clúster de vFXT: ingesta paralela de datos
Cuando haya creado un nuevo clúster de vFXT, su primera tarea consistirá en mover los datos a un nuevo volumen de almacenamiento de Azure. Sin embargo, si su método habitual para mover datos es emitir un simple comando de copia desde un cliente, es probable que el rendimiento de copia se vea ralentizado. Tenga en cuenta que la copia uniproceso no es una buena opción para copiar datos en el almacenamiento de back-end del clúster de Avere vFXT.
Dado que el clúster de Avere vFXT for Azure es una caché multicliente escalable, la forma más rápida y eficiente de copiar datos en él es emplear varios clientes. En esta técnica paraleliza la ingesta de datos referentes a archivos y objetos.
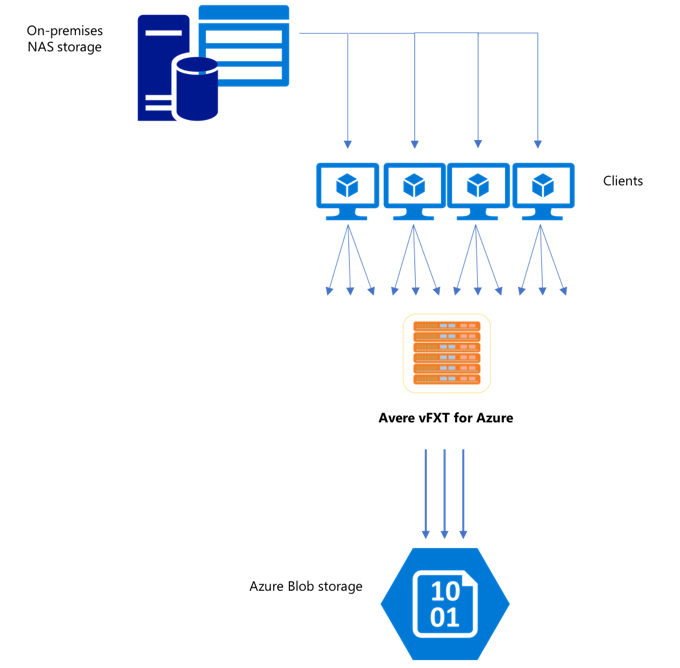
Los comandos cp o copy que se usan habitualmente para transferir datos de un sistema de almacenamiento a otro son comandos uniproceso que copian solo un archivo a la vez. Esto significa que el servidor de archivos solo puede ingerir un archivo a la vez, lo que es un desperdicio de los recursos del clúster.
En este artículo se explican las estrategias para crear un sistema para copiar archivos de varios clientes y subprocesos, para mover datos al clúster de Avere vFXT. Asimismo, se explican los conceptos de transferencia de archivos y los puntos de decisión que se pueden usar para copiar datos de manera eficiente mediante varios clientes y comandos de copia simples.
Por supuesto, también se explican algunas utilidades que pueden serle de ayuda. La utilidad msrsync se puede usar para automatizar parcialmente el proceso de dividir un conjunto de datos en cubos y usar los comandos rsync. El script parallelcp es otra utilidad que lee el directorio de origen y emite comandos de copia automáticamente. Además, la herramienta rsync se puede usar en dos fases para proporcionar una copia más rápida que aún proporcione coherencia de los datos.
Haga clic en el vínculo si quiere ir a la siguiente sección:
- Ejemplo de copia manual: explicación detallada para usar los comandos de copia
- Ejemplo de rsync de dos fases
- Ejemplo parcialmente automatizado (msrsync)
- Ejemplo de copia paralela
Plantilla de máquina virtual del agente de ingesta de datos
Tiene disponible en GitHub una plantilla de Resource Manager que le permitirá crear automáticamente una máquina virtual con las herramientas de ingesta de datos paralelas que se mencionaron en este artículo.
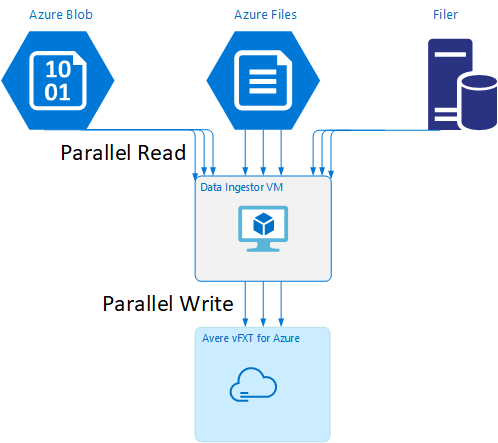
La máquina virtual del agente de ingesta de datos forma parte de un tutorial donde la máquina virtual recién creada monta el clúster de Avere vFXT y descarga su script de arranque desde el clúster. Lea Bootstrap a data ingestor VM (Arrancar la máquina virtual de un agente de ingesta de datos) para obtener más detalles.
Plan estratégico
Cuando diseñe una estrategia para copiar datos en paralelo, debe comprender las ventajas y desventajas que acarrea el tamaño del archivo, el número de archivos y la profundidad del directorio.
- Cuando los archivos son pequeños, la métrica de interés se basa en los archivos por segundo.
- Cuando los archivos son grandes (de 10 MiBi o más), la métrica de interés se mide en función de los bytes por segundo.
Cada proceso de copia tiene una tasa de rendimiento y una tasa de transferencia de archivos que puede medirse en función de la longitud del comando de copia y factorizando el tamaño y número de archivos. La explicación acerca de cómo se miden estas tasas no se encuentra en este documento, pero es importante que sepa si usará archivos pequeños o grandes.
Ejemplo de copia manual
Puede crear una copia de varios subprocesos de forma manual en un cliente; para ello, ejecute más de un comando de copia a la vez en segundo plano en los conjuntos predefinidos de archivos o rutas.
El comando cp de Linux/UNIX incluye el argumento -p que se usa para conservar la propiedad y los metadatos de tipo "mtime". Agregar este argumento a los comandos que tiene a continuación es opcional. (Recuerde que si agrega el argumento aumentará a su vez la cantidad de llamadas del sistema de archivos que se envían desde el cliente al sistema de archivos de destino para la modificación de metadatos).
En este simple ejemplo se copian dos archivos en paralelo:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Después de emitir este comando, el comando jobs mostrará que se están ejecutando dos subprocesos.
Estructura de nombres de archivo predecibles
Si los nombres de archivo son predecibles, puede usar expresiones para crear subprocesos de copia paralelos.
Por ejemplo, si su directorio contiene 1000 archivos que están numerados secuencialmente de 0001 a 1000, puede usar las siguientes expresiones para crear diez subprocesos paralelos para que cada uno copie 100 archivos:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Estructura de nombres de archivo desconocidos
Si la estructura de nomenclatura de archivos no es predecible, puede agrupar los archivos en función de los nombres de directorio.
En este ejemplo se recopilan los directorios completos que se enviarán a los comandos cp que se ejecutan como tareas en segundo plano:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Después de recopilar los archivos, puede ejecutar comandos de copia en paralelo para copiar de forma recursiva los subdirectorios y todo su contenido:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Cuándo agregar puntos de montaje
Una vez que haya suficientes subprocesos paralelos en un único punto de montaje del sistema de archivos de destino, llegará a un punto en el que el simple hecho de agregar más subprocesos no proporcionará más rendimiento. (El rendimiento se medirá en archivos/segundo o bytes/segundo, según el tipo de datos). O, lo que es peor, el exceso de subprocesos puede causar una degradación del rendimiento.
Si le sucede esto, puede agregar puntos de montaje del lado cliente a otras direcciones IP del clúster de vFXT; para ello, use la misma ruta de montaje remota del sistema de archivos:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Si decide agregar puntos de montaje del lado cliente, podrá bifurcar comandos de copia adicionales a los puntos de montaje /mnt/destination[1-3] adicionales; gracias a ello logrará un mayor paralelismo.
Por ejemplo, si sus archivos son muy grandes, puede definir los comandos de copia para usar distintas rutas de acceso de destino, y así poder enviar más comandos en paralelo desde el cliente que realiza la copia.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
En el ejemplo anterior, los tres procesos de copia de archivos del cliente se encargan de administrar los tres puntos de montaje de destino.
Cuándo agregar clientes
Por último, cuando haya alcanzado las capacidades del cliente, si decide agregar más subprocesos de copia o puntos de montaje adicionales no se producirá ningún aumento adicional de archivos/segundo o bytes/segundo. En esa situación, puede implementar otro cliente con el mismo conjunto de puntos de montaje; este ejecutará su propio conjuntos de procesos de copia de archivos.
Ejemplo:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Crear manifiestos de archivos
Después de comprender la información anterior (esto es, varios subprocesos de copia por destino, varios destinos por cliente, varios clientes por sistema de archivos de origen accesible a través de la red), tenga en cuenta esta recomendación: cree manifiestos de archivos y úselos con comandos de copia en varios clientes.
En este escenario se usa el comando UNIX find para crear manifiestos de archivos o directorios:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Redirija este resultado a un archivo find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo.
A continuación, puede iterar el manifiesto mediante comandos BASH para contar los archivos y determinar los tamaños de los subdirectorios:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Por último, debe crear los comandos de copia de archivos reales para los clientes.
Si tiene cuatro clientes, use este comando:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Si tiene cinco clientes, use algo como esto:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
Y para seis... Extrapole los datos según sea necesario.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Obtendrá N archivos resultantes, uno para cada uno de sus N clientes que tengan los nombres de ruta de acceso a los directorios de nivel cuatro y que se obtuvieron como parte de la salida del comando find.
Use cada archivo para construir el comando de copia:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
La información anterior le proporcionará N archivos, cada uno con un comando de copia por línea que se puede ejecutar como un script BASH en el cliente.
El objetivo es ejecutar varios subprocesos de estos scripts simultáneamente por cliente y en paralelo en varios clientes.
Uso de un proceso de rsync de dos fases
La utilidad de rsync estándar no funciona bien para rellenar el almacenamiento en la nube a través del sistema Avere vFXT for Azure porque genera un gran número de operaciones de creación y cambio de nombre de archivos con el fin de garantizar la integridad de datos. Sin embargo, se puede usar de forma segura la opción --inplace con rsync para omitir el procedimiento más prudente de copia, si a esto lo sigue una segunda ejecución que compruebe la integridad de los archivos.
Una operación de copia de rsync estándar crea un archivo temporal y lo rellena con datos. Si la transferencia de datos se completa correctamente, se cambia el nombre del archivo temporal al nombre de archivo original. Este método garantiza la coherencia incluso si se obtiene acceso a los archivos durante la copia. Pero este método genera más operaciones de escritura, lo que ralentiza el movimiento de archivos a través de la caché.
La opción --inplace escribe el archivo nuevo directamente en su ubicación final. No se garantiza que los archivos sean coherentes durante la transferencia, pero esto no es importante si se está preparando un sistema de almacenamiento para su uso posterior.
La segunda operación rsync actúa como comprobación de coherencia en la primera operación. Dado que los archivos ya se han copiado, la segunda fase consiste en un examen rápido para garantizar que los archivos del destino coinciden con los archivos del origen. Si los archivos no coinciden, se vuelven a copiar.
Puede emitir ambas fases juntas en un comando:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Este es un método sencillo y eficaz para los conjuntos de archivos que tengan como máximo el número de archivos que el administrador de directorios interno puede controlar. (Suele ser 200 millones de archivos para un clúster de 3 nodos, 500 millones de archivos para un clúster de seis nodos, etc.)
Uso de la utilidad msrsync
La herramienta msrsync también se puede usar para mover datos a un archivo central de back-end del clúster de Avere. Además, esta herramienta está diseñada para optimizar el uso del ancho de banda ejecutando varios procesos de tipo rsync en paralelo. Está disponible en GitHub en https://github.com/jbd/msrsync.
msrsync divide el directorio de origen en "cubos" separados y luego ejecuta procesos de tipo rsync individuales en cada cubo.
Las pruebas preliminares que se realizan con una máquina virtual de cuatro núcleos mostraron una eficacia mejor al usar 64 procesos. Use la opción de msrsync-p para establecer el número de procesos en 64.
También puede usar el argumento --inplace con los comandos msrsync. Si se utiliza esta opción, considere la posibilidad de ejecutar un segundo comando (como con rsync, descrito anteriormente) para garantizar la integridad de datos.
msrsync solo puede escribir en volúmenes locales y desde estos. El origen y el destino deben ser accesibles como montajes locales en la red virtual del clúster.
Para usar msrsync con el fin de rellenar un volumen en la nube de Azure con un clúster de Avere, siga estas instrucciones:
Instale
msrsyncy sus requisitos previos (rsync y Python 2.6 o una versión posterior).Determine el número total de archivos y directorios que se copiarán.
Por ejemplo, use la utilidad de Avere
prime.pycon los argumentosprime.py --directory /path/to/some/directory(disponible al descargar la dirección URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Si no usa
prime.py, puede calcular el número de elementos con la herramientafindde GNU, como se muestra a continuación:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Divida el número de elementos por 64 para determinar el número de elementos por proceso. Use este número con la opción
-fpara establecer el tamaño de los cubos cuando ejecute el comando.Ejecute el comando
msrsyncpara copiar los archivos:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Si se usa
--inplace, agregue una segunda ejecución sin la opción que comprueba que los datos se han copiado correctamente:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Por ejemplo, este comando está diseñado para mover 11 000 archivos en 64 procesos desde /test/source-repository hacia /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Usar el script de copia paralela
El script parallelcp también puede serle útil para mover datos al almacenamiento de back-end del clúster de vFXT.
El script siguiente agregará el archivo ejecutable parallelcp. (Este script está diseñado para Ubuntu; si usa otra distribución, debe instalar parallel por separado).
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Ejemplo de copia paralela
En este ejemplo se usa el script de copia paralela para compilar glibc mediante archivos de origen del clúster de Avere.
Los archivos de origen se almacenan en el punto de montaje del clúster de Avere y los archivos objeto se almacenan en el disco duro local.
Este script usa el script de copia paralelo que se detalló anteriormente. Asimismo, la opción -j se usa con parallelcp y make para obtener la paralelización.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de