Solución de problemas de escalabilidad automática de Azure Monitor
Gracias a la escalabilidad automática de Azure Monitor, puede ejecutar la cantidad correcta de recursos para administrar la carga de la aplicación. Permite agregar recursos para administrar el aumento de la carga y ahorrar dinero mediante la eliminación de recursos inactivos. Puede escalar en función de una programación, una fecha y hora fijas o la métrica de recursos que elija. Para obtener más información, consulte la información general sobre el escalado automático.
El servicio de escalabilidad automática proporciona métricas y registros para comprender las acciones de escalado que se han producido y la evaluación de las condiciones que llevaron a esas acciones. Puede encontrar respuesta a preguntas como las siguientes:
- ¿Por qué mi servicio se ha escalado o reducido horizontalmente?
- ¿Por qué no se ha escalado mi servicio?
- ¿Por qué se ha producido un error en una acción de escalabilidad automática?
- ¿Por qué una acción de escalabilidad automática tarda tiempo en escalar?
Conjuntos de escalado de máquinas virtuales flexibles
Las acciones de escalabilidad automática se retrasan hasta varias horas después de que se aplique una acción de escalabilidad manual a un recurso Flex Microsoft.Proceso/virtualMachineScaleSets (VMSS) para un conjunto específico de operaciones de Máquina Virtual.
Por ejemplo, Azure VM CLI Delete o Azure VM Rest API Delete cuando la operación se realiza en una máquina virtual individual.
En estos casos, el servicio de escalabilidad automática no es consciente de las operaciones individuales de las máquinas virtuales.
Para evitar este escenario, use la misma operación, pero a nivel del conjunto de escalado de máquinas virtuales. Por ejemplo, Azure VMSS CLI Delete instance o Azure VMSS Rest API Delete Instance. La escalabilidad automática detecta el cambio del recuento de instancias en el conjunto de escalado de máquinas virtuales y realiza las acciones de escalado apropiadas.
Métricas de escalabilidad automática
La escalabilidad automática le proporciona cuatro métricas para comprender su funcionamiento:
- Valor de métrica observado: el valor de la métrica sobre la que ha elegido llevar a cabo la acción de escalado, tal como lo ha detectado o calculado el motor de escalabilidad automática. Dado que una única configuración de escalabilidad automática puede tener varias reglas y, por lo tanto, varios orígenes de métricas, puede filtrar usando "origen de métrica" como dimensión.
- Umbral de métrica: el umbral establecido para realizar la acción de escalado. Como una única configuración de escalabilidad automática puede tener varias reglas y, por lo tanto, varios orígenes de métricas, puede filtrar usando "regla de métrica" como dimensión.
- Capacidad observada: el número activo de instancias del recurso de destino, tal como lo ha detectado el motor de escalabilidad automática.
- Acciones de escalado iniciadas: el número de acciones de escalabilidad horizontal y reducción horizontal iniciadas por el motor de escalabilidad automática. Puede filtrar por acciones de escalabilidad y reducción horizontales.
Puede usar el Explorador de métricas para representar todas las métricas anteriores en un único lugar. El gráfico debería mostrar:
- La métrica real.
- La métrica detectada o calculada por el motor de escalabilidad automática.
- El umbral de una acción de escalado.
- El cambio en la capacidad.
Ejemplo 1: Análisis de una regla de escalabilidad automática
Configuración de escalabilidad automática para un conjunto de escalado de máquinas virtuales:
- Se escala horizontalmente cuando el porcentaje medio de CPU de un conjunto es superior al 70 % durante 10 minutos.
- Se reduce horizontalmente cuando el porcentaje de CPU del conjunto es inferior al 5 % durante más de 10 minutos.
Vamos a revisar las métricas del servicio de escalabilidad automática.
En el gráfico siguiente se muestra una métrica Porcentaje de CPU para un conjunto de escalado de máquinas virtuales.

En el gráfico siguiente se muestra la métrica Valor de métrica observado para una configuración de escalabilidad automática.

En el gráfico final se muestran las métricas Umbral de métrica y Capacidad observada. La métrica Umbral de métrica de la parte superior de la regla de escalabilidad horizontal es 70. La métrica Capacidad observada de la parte inferior muestra el número de instancias activas, que actualmente es de 3.

Nota
Puede filtrar la métrica Umbral de métrica por la regla de escalabilidad horizontal de la dimensión de la regla del desencadenador de métricas (aumento) para ver el umbral de escalabilidad horizontal y por la regla de reducción horizontal (disminución).
Ejemplo 2: Escalabilidad automática avanzada para un conjunto de escalado de máquinas virtuales
Una configuración de escalabilidad automática permite escalar horizontalmente un recurso del conjunto de escalado de máquinas virtuales en función de su propia métrica Flujos salientes. La opción Dividir métrica por recuento de instancias del umbral de métrica está activada.
Si el valor de Flujo de salida por instancia es mayor que 10, el servicio de escalabilidad automática se debe escalar horizontalmente en 1 instancia.
En este caso, el valor de métrica observado del motor de escalabilidad automática se calcula como el valor de métrica real dividido por el número de instancias. Si el valor de métrica observado es inferior al umbral, no se inicia ninguna acción de escalabilidad horizontal.
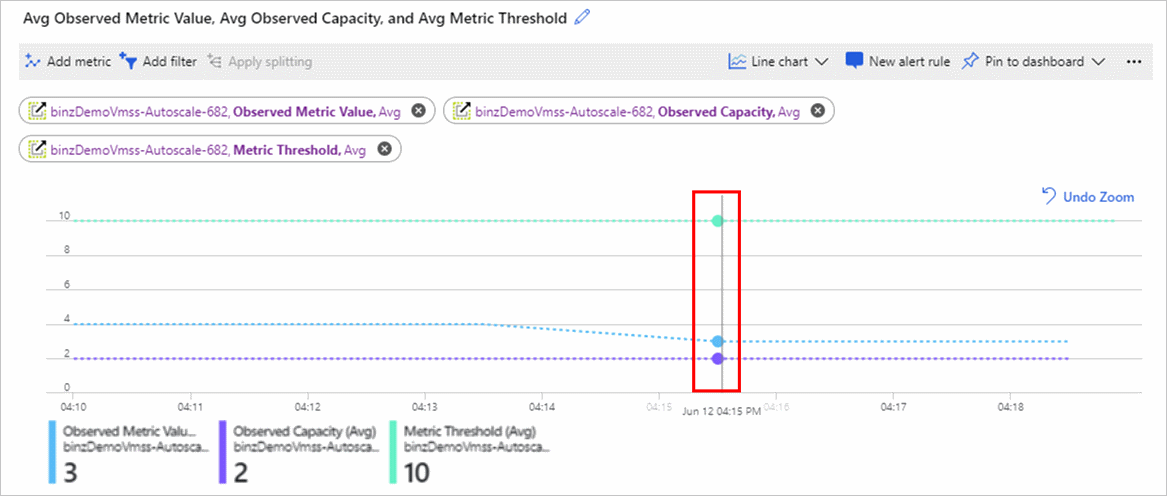
En las capturas de pantalla siguientes se muestran dos gráficos de métricas.
El gráfico Flujos de salida medios muestra el valor de la métrica Flujos de salida. El valor real es 6.

En el gráfico siguiente se muestran algunos valores:
- La métrica Valor de métrica observado del centro es 3 porque hay 2 instancias activas y 6 dividido entre 2 es 3.
- La métrica Capacidad observada en la parte inferior muestra el recuento de instancias visto por un motor de escalabilidad automática.
- La métrica Umbral de métrica de la parte superior se establece en 10.

Si hay varias reglas de acción de escalado, puede usar la división o la opción Agregar filtro en el gráfico del Explorador de métricas para ver la métrica de una regla o un origen específico. Para más información sobre cómo dividir un gráfico de métricas, consulte Características avanzadas de gráficos de métricas: división.
Ejemplo 3: Descripción de los eventos de escalabilidad automática
En la pantalla de configuración de escalabilidad automática, vaya a la pestaña Hist. de eje. para ver las acciones de escalado más recientes. En la pestaña también se muestra el cambio en la Capacidad observada a lo largo del tiempo. Para más información sobre todas las acciones de escalabilidad automática, incluidas las operaciones como actualizar o eliminar la configuración de escalabilidad automática, consulte el registro de actividad y filtre por las operaciones de escalabilidad automática.

Escalabilidad automática de registros de recursos
El servicio de escalabilidad automática proporciona registros de recursos. Existen dos categorías de registros:
- Evaluaciones de escalabilidad automática: el motor de escalabilidad automática anota las entradas de registro de cada evaluación de condición única cada vez que se realiza una comprobación. La entrada incluye detalles sobre los valores observados de las métricas, las reglas evaluadas y si la evaluación ha dado como resultado una acción de escalado o no.
- Acciones de escalabilidad automática: el motor registra los eventos de acción de escalado iniciados por el servicio de escalabilidad automática y los resultados de estas acciones de escalado (éxito, error y la cantidad de escalado que ha detectado el servicio de escalabilidad automática).
Al igual que con cualquier servicio compatible con Azure Monitor, puede usar configuración de diagnóstico para enrutar estos registros a los siguientes lugares:
- Área de trabajo de Log Analytics para analizarlos más a fondo.
- Azure Event Hubs y, luego, herramientas que no son de Azure.
- La cuenta de Azure Storage para archivarlos.

En la captura de pantalla anterior se muestra el panel Configuración de diagnóstico de escalabilidad automática de Azure Portal. Ahí puede seleccionar la pestaña Registros de diagnóstico o recursos y habilitar la recopilación y el enrutamiento de registros. También puede realizar la misma acción mediante la API REST, la CLI de Azure, PowerShell y las plantillas de Azure Resource Manager para la configuración de diagnóstico eligiendo el tipo de recurso como Microsoft.Insights/AutoscaleSettings.
Solución de problemas mediante registros de escalabilidad automática
Para una mejor experiencia de solución de problemas, se recomienda enrutar los registros a Registros de Azure Monitor (Log Analytics) mediante un área de trabajo cuando se crea la configuración de escalabilidad automática. Este proceso se muestra en la captura de pantalla de la sección anterior. Puede validar las acciones de evaluación y escalado mejor con Log Analytics.
Cuando haya configurado los registros de escalabilidad automática para enviarlos al área de trabajo de Log Analytics, puede ejecutar las siguientes consultas para comprobar los registros.
Para empezar, pruebe esta consulta para ver los registros de evaluación de escalabilidad automática más recientes:
AutoscaleEvaluationsLog
| limit 50
O bien, intente la siguiente consulta para ver los registros de acciones de escalado más recientes:
AutoscaleScaleActionsLog
| limit 50
Use las secciones siguientes para responder a estas preguntas.
Se ha producido una acción de escalado que no esperaba
En primer lugar, ejecute la consulta para que la acción de escalado encuentre aquella en la que está interesado. Si es la acción de escalado más reciente, use la siguiente consulta:
AutoscaleScaleActionsLog
| take 1
Seleccione el campo CorrelationId en el registro de acciones de escalado. Use el campo CorrelationId para buscar el registro de evaluación correcto. Al ejecutar la consulta siguiente se muestran todas las reglas y condiciones que se han evaluado y llevado a esa acción de escalado.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId>"
¿Qué perfil ha provocado una acción de escalado?
Se ha producido una acción de escalado, pero tiene reglas y perfiles que se superponen, y debe realizar un seguimiento de cuáles son los que han producido la acción.
Busque el objeto CorrelationId de la acción de escalado, como se explica en el ejemplo 1. A continuación, ejecute la consulta en los registros de evaluación para saber más sobre el perfil.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId_Guid>"
| where ProfileSelected == true
| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult
La evaluación de todo el perfil también se puede entender mejor con la siguiente consulta:
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName contains == "profileEvaluation"
| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult
No se ha producido una acción de escalado
Esperaba una acción de escalado y no se ha producido. Puede que no haya ningún registro o evento de acción de escalado.
Revise las métricas de escalabilidad automática si usa una regla de escalado basada en métricas. Es posible que el valor de Métrica observada o Capacidad observada no sea lo que esperaba y, por lo tanto, no se haya activado la regla de escalado. Aún seguirá viendo evaluaciones, pero no una regla de escalabilidad horizontal. También es posible que el tiempo de recuperación impida que se produzca una acción de escalado.
Revise los registros de evaluación de escalabilidad automática durante el período de tiempo en el que esperaba que se produjera la acción de escalado. Revise todas las evaluaciones que ha realizado y por qué decidió no desencadenar una acción de escalado.
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation"
| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult
Error durante la acción de escalado
Puede haber casos en los que el servicio de escalabilidad automática haya realizado la acción de escalado, pero el sistema haya decidido no escalar o no haya podido completar la acción de escalado. Use esta consulta para buscar las acciones de escalado con errores:
AutoscaleScaleActionsLog
| where ResultType == "Failed"
| project ResultDescription
Cree reglas de alertas para recibir notificaciones de errores o acciones de escalabilidad automática. También puede crear reglas de alertas para recibir notificaciones sobre los eventos de escalabilidad automática.
Esquema de registros de recursos de escalabilidad automática
Para más información, consulte los registros de recursos de escalabilidad automática.
Pasos siguientes
Lea información sobre Procedimientos recomendados de escalabilidad automática.