Solucionar problemas de recopilación de métricas de Prometheus en Azure Monitor
Siga los pasos de este artículo para determinar la causa por la que las métricas de Prometheus no se recopilan según lo previsto en Azure Monitor.
El pod de réplica extrae las métricas de kube-state-metrics, los destinos de extracción personalizados del mapa de configuración ama-metrics-prometheus-config y los destinos de extracción personalizados definidos en los recursos personalizados. Los pods DaemonSet extraen métricas de los siguientes objetivos en sus respectivos nodos: kubelet, cAdvisor, node-exporter y destinos de extracción personalizados en el mapa de configuración de ama-metrics-prometheus-config-node. El pod para el que desea ver los registros y la interfaz de usuario de Prometheus depende del objetivo de extracción que esté investigando.
Solución de problemas mediante el script de PowerShell
Si se ha producido un error al intentar habilitar la supervisión de su clúster AKS, siga las instrucciones que se mencionan aquí para ejecutar el script de solución de problemas. Este script está diseñado para realizar un diagnóstico básico de cualquier problema de configuración en su clúster y puede usar los archivos generados mientras crea una solicitud de soporte para una resolución más rápida de su caso de soporte técnico.
Métricas que faltan
Limitación de métricas
En Azure Portal, vaya al área de trabajo de Azure Monitor. Vaya a Metrics y compruebe que las métricas Active Time Series % Utilization y Events Per Minute Ingested % Utilization están por debajo de 100 %.

Si alguna de ellas es superior a 100 %, se está limitando la ingesta en este área de trabajo. En la misma área de trabajo, vaya a New Support Request para crear una solicitud para aumentar los límites. Seleccione el tipo de problema como Service and subscription limits (quotas) y el tipo de cuota como Managed Prometheus.
También puede supervisar y configurar una alerta sobre los límites de ingesta. Consulte Supervisión de los límites de ingesta para evitar la limitación de ingesta de métricas.
Brechas intermitentes en la recopilación de datos de métricas
Durante las actualizaciones de nodos, es posible que vea una brecha de 1 a 2 minutos en los datos de métricas para las métricas recopiladas de nuestro recopilador de nivel de clúster. Esta brecha se debe a que el nodo en el que se ejecuta se está actualizando como parte de un proceso de actualización normal. Afecta a los objetivos de todo el clúster como kube-state-metrics y a los objetivos de aplicación personalizados que se especifiquen. Ocurre cuando su clúster se actualiza manualmente o mediante una actualización automática. Este comportamiento es esperado y se produce debido a la actualización del nodo en el que se ejecuta. Ninguna de nuestras reglas de alerta recomendadas se ve afectada por este comportamiento.
Estado del pod
Compruebe el estado del pod con el siguiente comando:
kubectl get pods -n kube-system | grep ama-metrics
- Debe haber un pod de réplica
ama-metrics-xxxxxxxxxx-xxxxx, unama-metrics-operator-targets-*, un podama-metrics-ksm-*y un podama-metrics-node-*para cada nodo del clúster. - El estado de cada pod debe ser
Runningy debe tener un número de reinicios igual al número de cambios de mapa de configuración que se han aplicado. El pod ama-metrics-operator-targets-* puede tener un reinicio adicional al principio y se espera lo siguiente:

Si cada estado de pod es Running pero uno o varios pods tienen reinicios, ejecute el siguiente comando:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Este comando proporciona el motivo de los reinicios. Se espera que los pods se reinicien si se han realizado cambios en configmap. Si el motivo del reinicio es
OOMKilled, el pod no puede mantenerse actualizado con el volumen de métricas. Consulte las recomendaciones de escala para el volumen de métricas.
Si los pods se ejecutan según lo previsto, el siguiente lugar que se debe comprobar son los registros de contenedor.
Comprobación de las configuraciones de cambio de etiqueta
Si faltan métricas, también puede comprobar si ha vuelto a etiquetar las configuraciones. Con las configuraciones de reetiquetado, asegúrese de que la etiqueta no filtra los destinos y las etiquetas configuradas coinciden correctamente con los destinos. Consulte documentación de configuración de etiqueta de Prometheus para obtener más información.
Registros de contenedor
Vea los registros de contenedor con el siguiente comando:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
En el inicio, los errores iniciales se imprimen en rojo, mientras que las advertencias se imprimen en amarillo. (La visualización de los registros de colores requiere al menos la versión 7 de PowerShell o una distribución de Linux).
- Compruebe si hay una incidencia al obtener el token de autenticación:
- El mensaje No hay configuración presente para el recurso de AKS se registra cada 5 minutos.
- El pod se reinicia cada 15 minutos para intentarlo de nuevo con el error: No hay ninguna configuración presente para el recurso de AKS.
- Si es así, compruebe que la regla de recopilación de datos y el punto de conexión de recopilación de datos existen en el grupo de recursos.
- Compruebe también que el área de trabajo de Azure Monitor existe.
- Compruebe que no tiene un clúster de AKS privado y que no está vinculado a un ámbito de Private Link de Azure Monitor para ningún otro servicio. Actualmente no se admite este escenario.
Procesamiento de configuración
Vea los registros de contenedor con el siguiente comando:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Compruebe que no hay ningún error el análisis de la configuración de Prometheus, la combinación de los destinos de extracción predeterminados habilitados y la validación de la configuración completa.
- Si incluiste una configuración personalizada de Prometheus, verifica que se reconozca en los registros. Si no es así:
- Compruebe que el mapa de configuración tiene el nombre correcto:
ama-metrics-prometheus-configen el espacio de nombreskube-system. - Compruebe que, en el mapa de configuración, la configuración de Prometheus está en una sección denominada
prometheus-configendatacomo se muestra aquí:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Compruebe que el mapa de configuración tiene el nombre correcto:
- Si ha creado recursos personalizados, debería haber visto errores de validación durante la creación del pod o los monitores de servicio. Si todavía no ve las métricas de los destinos, asegúrese de que los registros no muestren errores.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Compruebe que no hay ningún error en
MetricsExtensioncon respecto a la autenticación con el área de trabajo de Azure Monitor. - Compruebe que no hay ningún error en el recopilador de
OpenTelemetry collectorsobre la extracción de los destinos.
Ejecute el siguiente comando:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Este comando muestra un error si hay un problema con la autenticación con el área de trabajo de Azure Monitor. El siguiente ejemplo muestra registros sin problemas:


Si no hay ningún error en los registros, se puede usar la interfaz de Prometheus para la depuración para comprobar la configuración esperada y los destinos que se van a extraer.
Interfaz de Prometheus
Cada pod ama-metrics-* tiene la interfaz de usuario del modo Agente de Prometheus disponible en el puerto 9090.
La configuración personalizada y los destinos de recursos personalizados los extrae el pod ama-metrics-* y los destino de nodo el pod ama-metrics-node-*.
Reenvía el puerto al pod de réplica o a uno de los pods del conjunto de demonios para verificar la configuración, el descubrimiento de servicios y los puntos finales de los objetivos como se describe aquí para verificar que las configuraciones personalizadas sean correctas, que se hayan descubierto los objetivos previstos para cada trabajo y que no haya errores al raspar objetivos específicos.
Ejecute el comando kubectl port-forward <ama-metrics pod> -n kube-system 9090.
Abra un explorador en la dirección
127.0.0.1:9090/config. Esta interfaz de usuario tiene la configuración de extracción completa. Compruebe que todos los trabajos se incluyen en la configuración.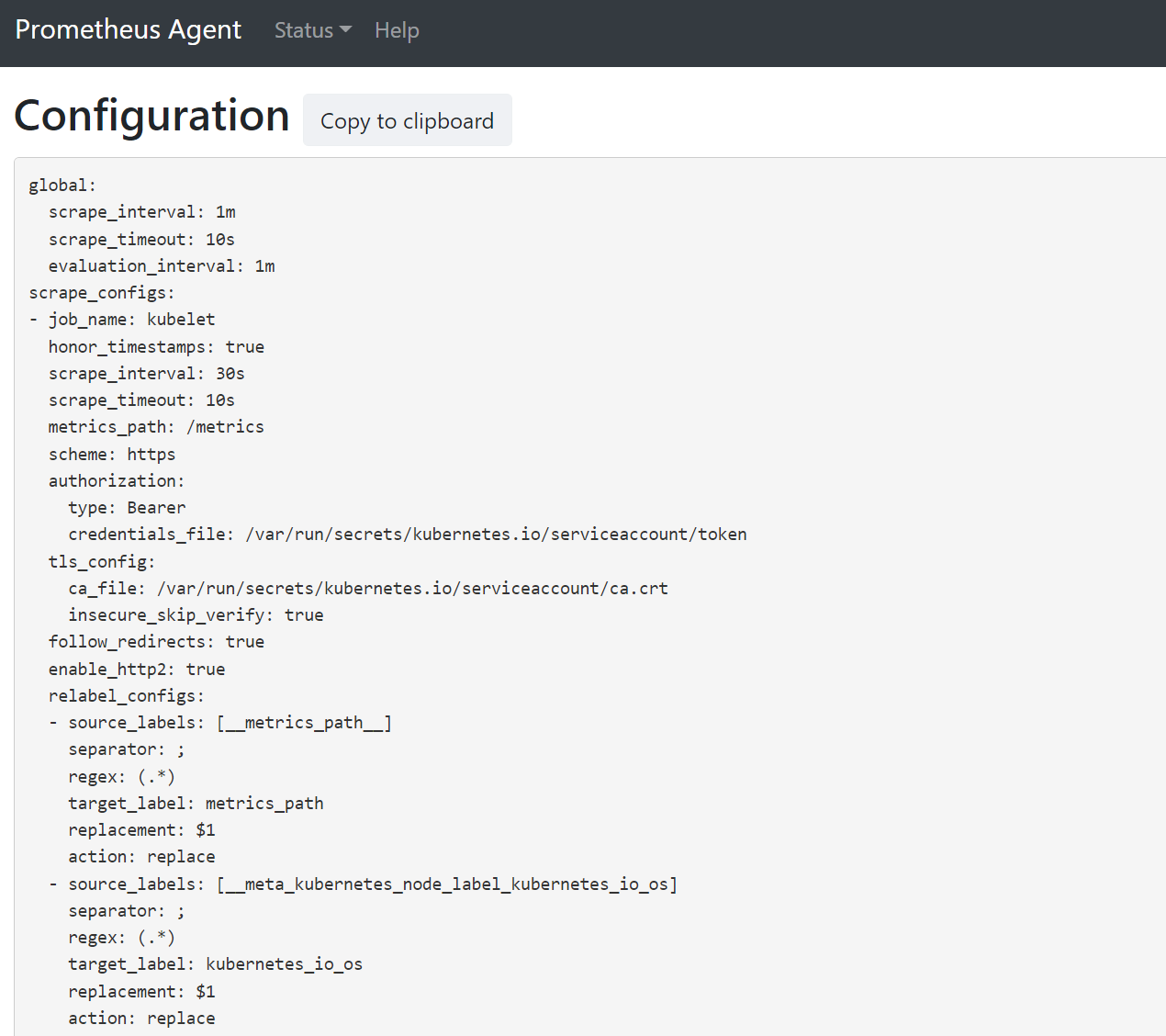
Vaya a para
127.0.0.1:9090/service-discoveryver los destinos detectados por el objeto de detección de servicios especificado y cuáles han sido los destinos filtrados por relabel_configs. Por ejemplo, cuando faltan métricas de un pod determinado, puede determinar si ese pod se detectó y cuál es su URI. Después, puede usar este URI al examinar los destinos para ver si hay algún error de extracción.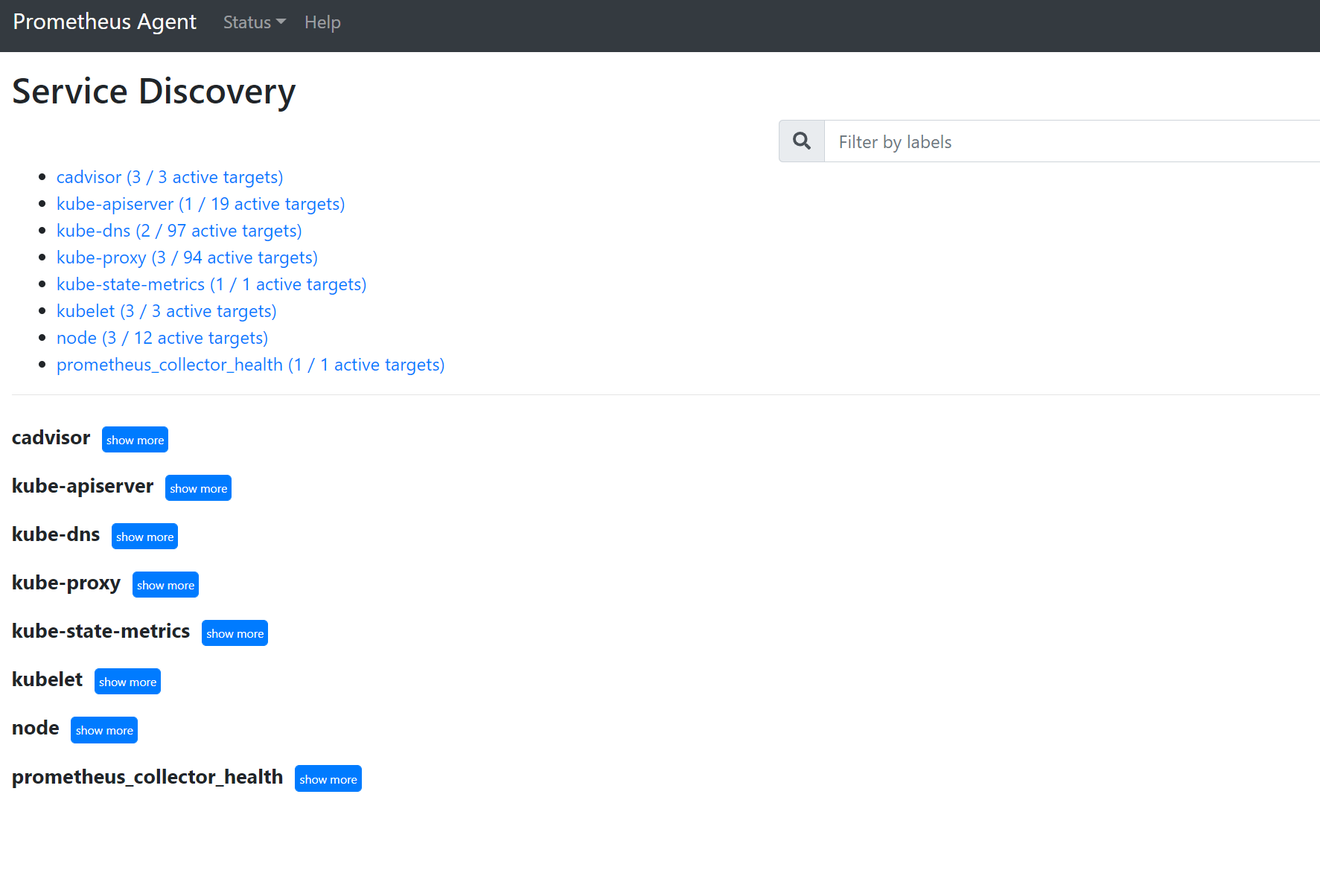
Vaya a
127.0.0.1:9090/targetspara ver todos los trabajos, la última vez que se extrajo el punto de conexión de ese trabajo y los errores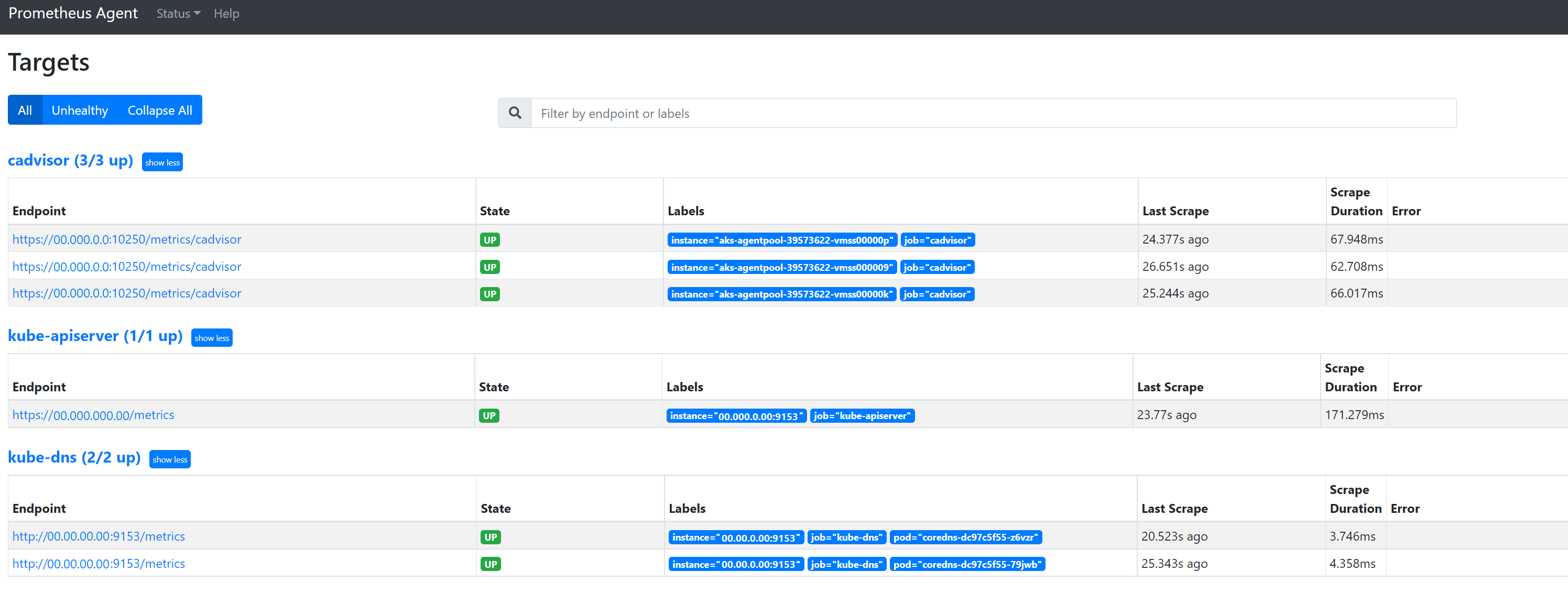



Recursos personalizados
- Si ha incluido recursos personalizados, asegúrese de que se muestren en la configuración, la detección de servicios y los destinos.
Configuración

Detección de servicios

Destinos

Si no hay incidencias y los destinos previstos se están extrayendo, puede ver las métricas exactas que se extraen habilitando el modo de depuración.
Modo de depuración
Advertencia
Este modo puede afectar al rendimiento y solo debe habilitarse durante un breve período de tiempo con fines de depuración.
El complemento de métricas se puede configurar para que se ejecute en modo de depuración cambiando la configuración de configmap enabled en debug-mode a true siguiendo las instrucciones que se indican aquí.
Cuando se habilita, todas las métricas de Prometheus que se extraen se hospedan en el puerto 9091. Ejecute el siguiente comando:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Vaya a 127.0.0.1:9091/metrics en un explorador para ver si el recopilador de OpenTelemetry extrajo las métricas. Se puede acceder a esta interfaz de usuario para cada pod ama-metrics-*. Si las métricas no están allí, podría haber una incidencia con las longitudes de nombre de las métricas o las etiquetas o el número de etiquetas. Compruebe también si se supera la cuota de ingesta para las métricas de Prometheus, tal y como se especifica en este artículo.
Nombres de métrica, nombres de etiqueta y valores de etiqueta
La extracción de métricas actualmente tiene las limitaciones de la tabla siguiente:
| Propiedad | Límite |
|---|---|
| Longitud del nombre de etiqueta | Inferior o igual a 511 caracteres. Cuando se supera este límite para cualquier serie temporal de un trabajo, se produce un error en todo el trabajo de extracción y las métricas de ese trabajo se quitan antes de la ingesta. Puede ver up=0 para ese trabajo y también Ux de destino muestra el motivo de up=0. |
| Longitud del valor de etiqueta | Inferior o igual a 1023 caracteres. Cuando se supera este límite para cualquier serie temporal de un trabajo, se produce un error en toda la extracción y las métricas de ese trabajo se quitan antes de la ingesta. Puede ver up=0 para ese trabajo y también Ux de destino muestra el motivo de up=0. |
| Número de etiquetas por serie temporal | Inferior o igual a 63. Cuando se supera este límite para cualquier serie temporal de un trabajo, se produce un error en todo el trabajo de extracción y las métricas de ese trabajo se quitan antes de la ingesta. Puede ver up=0 para ese trabajo y también Ux de destino muestra el motivo de up=0. |
| Longitud del nombre de métrica | Inferior o igual a 511 caracteres. Cuando se supera este límite para cualquier serie temporal de un trabajo, solo se quita esa serie determinada. MetricextensionConsoleDebugLog tiene seguimientos para la métrica quitada. |
| Nombres de etiqueta con uso de mayúsculas y minúsculas diferentes | Dos etiquetas dentro de la misma muestra métrica, con una carcasa diferente, se tratan como si tuvieran etiquetas duplicadas y se caen cuando se ingieren. Por ejemplo, la serie my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} temporal se quita debido a las etiquetas duplicadas, ya que ExampleLabel y examplelabel se ven como el mismo nombre de etiqueta. |
Comprobar la cuota de ingesta en el área de trabajo de Azure Monitor
Si ve que faltan métricas, puede comprobar primero si se superan los límites de ingesta para el área de trabajo de Azure Monitor. En Azure Portal, puede comprobar el uso actual de cualquier área de trabajo de Azure Monitor. Puede ver las métricas de uso actuales en el menú Metrics del área de trabajo de Azure Monitor. Las siguientes métricas de uso están disponibles como métricas estándar para cada área de trabajo de Azure Monitor.
- Series temporales activas: número de series temporales únicas ingeridas en el área de trabajo durante las últimas 12 horas
- Límite de serie temporal activa: el límite del número de series temporales únicas que se pueden ingerir activamente en el área de trabajo
- Porcentaje de uso de series temporales activas: porcentaje de series temporales activas actuales que se están utilizando
- Eventos por minuto ingeridos: el número de eventos (muestras) por minuto recibidos recientemente
- Límite ingerido de eventos por minuto: el número máximo de eventos por minuto que se pueden ingerir antes de que se limiten
- Porcentaje de uso de eventos por minuto ingerido: porcentaje del límite actual de la tasa de ingestión de métrica que se está utilizando
Para evitar la limitación de ingesta de métricas, puede supervisar y configurar una alerta sobre los límites de ingesta. Consulte Supervisión de límites de ingesta.
Consulte los límites y cuotas del servicio predeterminados para comprender lo que se puede aumentar en función del uso. Puede solicitar el aumento de cuota para las áreas de trabajo de Azure Monitor mediante el menú Support Request del área de trabajo de Azure Monitor. Asegúrese de incluir el id., el id. interno y la ubicación/región del área de trabajo de Azure Monitor en la solicitud de soporte técnico, que puede encontrar en el menú "Propiedades" del área de trabajo de Azure Monitor en Azure Portal.
La creación de Azure Monitor Workspace falló debido a la evaluación de Azure Policy
Si la creación de Azure Monitor Workspace falla con un error que dice "Recurso 'resource-name-xyz' fue desautorizado por la directiva", puede que haya una directiva de Azure que esté impidiendo que se cree el recurso. Si existe una directiva que impone una convención de nomenclatura para sus recursos o grupos de recursos de Azure, deberá crear una exención para la convención de nomenclatura para la creación de un Azure Monitor Workspace.
Al crear un área de trabajo de Azure Monitor, de manera predeterminada, se creará una regla de recopilación de datos y un punto de conexión de recopilación de datos con el formulario "azure-monitor-workspace-name" en un grupo de recursos con el formato "MA_azure-monitor-workspace-name_location_managed". Actualmente no hay manera de cambiar los nombres de estos recursos, y usted tendrá que establecer una exención en Azure Policy para eximir a los recursos anteriores de la evaluación de la directiva. Consulte Estructura de exención de Azure Policy.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de