Escalado horizontal con Azure SQL Database
Se aplica a: ![]() Azure SQL Database
Azure SQL Database
Es muy fácil escalar horizontalmente bases de datos de Azure SQL Database mediante las herramientas de Base de datos elástica. Estas herramientas y características permiten usar los recursos de bases de datos de Azure SQL Database con el fin de crear soluciones para cargas de trabajo transaccionales y, especialmente, aplicaciones de software como servicio (SaaS). Las características de Elastic Database se componen de lo siguiente:
- Biblioteca de cliente de Elastic Database: la biblioteca de cliente es una característica que permite crear y mantener bases de datos particionadas. Consulte Introducción a las herramientas de Elastic Database.
- Mover datos entre bases de datos en la nube escaladas horizontalmente: mueve datos entre bases de datos particionadas. Esta herramienta es útil para mover datos de una base de datos de varios inquilinos a una de un solo inquilino (o viceversa). Consulte Implementación de un servicio de división y combinación para mover datos entre bases de datos particionadas.
- Trabajos elásticos para Azure SQL Database: use trabajos para administrar un gran número de bases de datos en Azure SQL Database. Realice fácilmente operaciones administrativas, como cambios de esquema, administración de credenciales, actualizaciones de datos de referencia, recopilación de datos de rendimiento o de trabajos de recolección de telemetría de inquilinos (cliente).
- Información general sobre las consultas elásticas de Azure SQL Database (versión preliminar): le permite ejecutar una consulta Transact-SQL que abarca varias bases de datos. Esto permite la conexión con herramientas de informes, como Excel, Power BI, Tableau, etc.
- Transacciones distribuidas en bases de datos en la nube: esta característica permite ejecutar transacciones que abarcan varias bases de datos. Las transacciones de bases de datos elásticas están disponibles para aplicaciones .NET mediante ADO .NET y se integran con la conocida experiencia de programación en la que se emplean las clases System.Transaction.
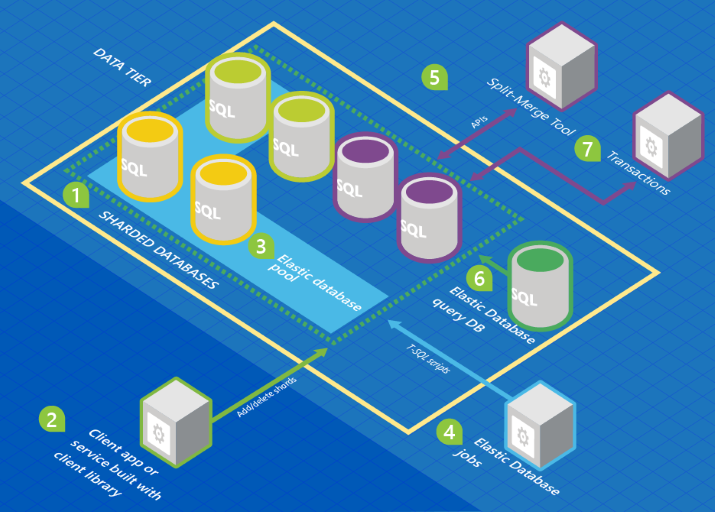
El siguiente gráfico muestra una arquitectura que incluye las características de Elastic Database en relación con una colección de bases de datos.
En este gráfico, los colores de la base de datos representan esquemas. Las bases de datos con el mismo color comparten el mismo esquema.
- Un conjunto de bases de datos SQL se hospeda en Azure con la arquitectura de particionamiento.
- La biblioteca de cliente de Elastic Database se usa para administrar un conjunto de particiones.
- Un subconjunto de las bases de datos se coloca en un grupo elástico.
- Un trabajo de Elastic Database ejecuta scripts de T-SQL en todas las bases de datos.
- La herramienta de división y combinación se usa para mover datos de una partición a otra.
- La consulta de Elastic Database le permite escribir una consulta que abarque todas las bases de datos del conjunto de particiones.
- Las transacciones elásticas le permiten ejecutar transacciones que abarcan varias bases de datos.
¿Por qué hay que usar las herramientas?
Dotar de elasticidad y escalabilidad a las aplicaciones en la nube es sencillo para el almacenamiento de blobs y las máquinas virtuales; basta con sumar o restar unidades, o bien con aumentar la potencia. Pero sigue siendo un desafío para el procesamiento de datos con estado en bases de datos relacionales. Estos son los desafíos que han surgido en estos escenarios:
- Aumento y disminución de la capacidad de la parte de la base de datos relacional de la carga de trabajo.
- La administración de las zonas activas puede afectar a un subconjunto específico de datos, como un usuario final (inquilino) ocupado.
Tradicionalmente, escenarios similares se han abordado a través de la inversión en servidores a gran escala para admitir la aplicación. Sin embargo, esta opción está limitada en la nube donde todo el procesamiento ocurre en hardware estándar predefinido. En su lugar, la distribución de datos y el procesamiento a través de muchas bases de datos con una estructura idéntica (un patrón de escalado horizontal conocido como "particionamiento") proporciona una alternativa a los enfoques de escalado vertical tradicionales, tanto en términos de costo como de elasticidad.
Escalado horizontal y vertical
En la siguiente ilustración se muestran las dimensiones horizontales y verticales de escalado, que son las formas básicas en que se pueden escalar las bases de datos elásticas.

El escalado horizontal se refiere a la adición o eliminación de bases de datos con el fin de ajustar la capacidad o el rendimiento global, también llamado "scaling out". El particionamiento, en la que los datos se dividen en un conjunto de bases de datos de estructura idéntica, es una forma habitual de aplicar el escalado horizontal.
Escalar verticalmente es aumentar o disminuir el tamaño de proceso de una base de datos individual; también se conoce como "escalado vertical".
La mayoría de las aplicaciones de bases de datos a escala de la nube usan una combinación de estas dos estrategias. Por ejemplo, una aplicación de software como servicio podría utilizar el escalado horizontal para aprovisionar usuarios finales nuevos y el escalado vertical para permitir que la base de datos de cada cliente final aumente o disminuya los recursos, según lo requiera la carga de trabajo.
- El escalado horizontal se administra mediante la biblioteca de cliente de Elastic Database.
- El escalado vertical se logra utilizando cmdlets de Azure PowerShell para cambiar el nivel de servicio o colocando bases de datos en un grupo elástico.
Particionamiento
El particionamiento es una técnica para distribuir grandes cantidades de datos estructurados de manera idéntica entre muchas bases de datos independientes. Su uso se ha extendido entre los desarrolladores de nube que crean ofertas de software como servicio (SAAS) para empresas o clientes finales. Estos clientes finales a menudo se conocen como "inquilinos". El particionamiento puede ser necesario por muchos motivos:
- La cantidad total de datos es demasiado grande para caber dentro de las restricciones de una base de datos individual
- El rendimiento de transacciones de la carga de trabajo total supera la capacidad de una base de datos individual
- Los inquilinos pueden requerir el aislamiento físico entre sí, por lo que se necesitan bases de datos independientes para cada inquilino
- Es posible que distintas secciones de una base de datos tengan que residir en diferentes geografías por motivos de cumplimiento, rendimiento o geopolíticos.
En otros escenarios, como la recopilación de datos desde dispositivos distribuidos, el particionamiento se puede usar para llenar un conjunto de bases de datos organizadas de manera temporal. Por ejemplo, puede dedicarse una base de datos independiente a cada día o semana. En ese caso, la clave de particionamiento puede ser un entero que representa la fecha (presente en todas las filas de las tablas particionadas) y la aplicación debe enrutar las consultas que recuperan información de un intervalo de fechas al subconjunto de bases de datos que abarca el intervalo en cuestión.
El particionamiento funciona mejor cuando todas las transacciones de una aplicación pueden restringirse a un único valor de una clave de particionamiento. De este modo se garantiza que todas las transacciones sean locales con respecto a una base de datos.
Multiinquilino e inquilino único
Algunas aplicaciones usan el enfoque más simple de crear una base de datos independiente para cada inquilino. Este enfoque es el patrón de particionamiento de un solo inquilino que proporciona aislamiento, capacidad de copia de seguridad y restauración, y ajuste de escala de recursos en la granularidad del inquilino. Con el particionamiento de un solo inquilino, cada base de datos se asocia a un determinado valor de identificador de inquilino (o valor de clave de cliente), pero no es necesario que esa clave esté presente en los propios datos. Es responsabilidad de la aplicación enrutar cada solicitud a la base de datos adecuada y la biblioteca de cliente puede simplificar esta tarea.

Otros escenarios empaquetan varios inquilinos juntos en bases de datos, en lugar de aislarlos en bases de datos independientes. Este es un patrón de particionamiento multiinquilino típico y puede estar impulsado por el hecho de que una aplicación administra grandes cantidades de pequeños inquilinos. En el particionamiento de varios inquilinos, las filas de las tablas de bases de datos están diseñadas para contener una clave que identifique la clave de particionamiento o el identificador del inquilino. De nuevo, la capa de aplicación es la responsable de enrutar la solicitud de un inquilino a la base de datos adecuada, y esto puede admitirlo la biblioteca de cliente de bases de datos elásticas. Además, es posible usar seguridad en el nivel de fila para filtrar las filas a las que puede tener acceso cada inquilino; si desea obtener detalles, consulte Aplicaciones multiinquilinos con herramientas de bases de datos elásticas y seguridad de nivel de fila. La redistribución de datos entre las bases de datos puede ser necesaria con el patrón de particionamiento multiinquilino, lo que se ve facilitado por la herramienta de división y combinación de bases de datos elásticas. Para obtener más información acerca de los modelos de diseño de las aplicaciones SaaS que usan grupos elásticos, consulte Patrones de inquilinato de base de datos SaaS multiinquilino.
Mover datos de bases de datos de multinIiquilino a inquilino único
Al crear una aplicación SaaS, es típico ofrecer a los clientes potenciales una versión de prueba del software. En este caso, resulta más rentable usar una base de datos multiinquilino para los datos. Sin embargo, cuando un cliente potencial se convierte en un cliente, una base de datos de inquilino único es mejor, puesto que ofrece un mejor rendimiento. Si el cliente crea datos durante el período de prueba, use la herramienta de división y combinación para mover los datos de la base de datos multiinquilino a la nueva base de datos de inquilino único.
Nota:
No se pueden restaurar bases de datos multiinquilino en un solo inquilino.
Ejemplos y tutoriales
Para ver una aplicación de ejemplo que demuestra la biblioteca de cliente, consulte Introducción a las herramientas de Elastic Database.
Para convertir las bases de datos existentes con el fin de emplear las herramientas, consulte Migración de bases de datos existentes de escalado horizontal.
Para ver los detalles del grupo elástico, consulte Consideraciones de precio y rendimiento para un grupo elástico o cree un nuevo grupo con grupos elásticos.
Contenido relacionado
¿Aún no ha usado las herramientas de base de datos elástica? Consulte la Guía de introducción. Si tiene alguna pregunta, póngase en contacto con nosotros en la Página de preguntas y respuestas de Microsoft sobre SQL Database y, para efectuar solicitudes de características, agregue nuevas ideas o vote por las ideas existentes en el foro de comentarios sobre SQL Database.