Configuración de un grupo de conmutación por error para Azure SQL Database
Se aplica a:![]() Azure SQL Database
Azure SQL Database
Este artículo te enseña a configurar un grupo de conmutación por error para bases de datos agrupadas en Azure SQL Database mediante Azure Portal, Azure PowerShell y la CLI de Azure.
Para los scripts de un extremo a otro, consulta cómo agregar una base de datos única a un grupo de conmutación por error con Azure PowerShell o la CLI de Azure.
Requisitos previos
Tenga en cuenta los siguientes requisitos previos para crear el grupo de conmutación por error para una base de datos única:
- La base de datos principal ya debe estar creada. Cree una base de datos única para empezar.
- Si el servidor secundario ya existe en una región diferente al servidor principal, la configuración de inicio de sesión y firewall del servidor debe coincidir con la del servidor principal.
Creación de un grupo de conmutación por error
Puede crear el grupo de migración tras error y añadir una base de datos única mediante Azure Portal, PowerShell y la CLI de Azure.
Importante
Si tiene que eliminar la base de datos secundaria después de agregar a un grupo de migración tras error, quítela del grupo de migración tras error antes de eliminarla. Eliminar una base de datos secundaria antes de quitarla del grupo de conmutación por error puede provocar un comportamiento impredecible.
Para crear el grupo de conmutación por error y añadir la base de datos única mediante Azure Portal, siga estos pasos:
Si conoce el servidor lógico que aloja la base de datos, vaya directamente a ella en Azure Portal. Si tiene que buscar el servidor, siga estos pasos:
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
Azure SQLen el cuadro de búsqueda. (Opcional) Seleccione la estrella junto a Azure SQL para marcarlo como favorito y agréguelo como un elemento del menú de servicios. - En la página de Azure SQL, busque la base de datos que desea añadir a un grupo de migración tras error y selecciónela para abrir el panel Base de datos de SQL.
- En el panel Información general de Base de datos de SQL, seleccione el nombre del servidor en Nombre del servidor para abrir el panel de SQL Server.
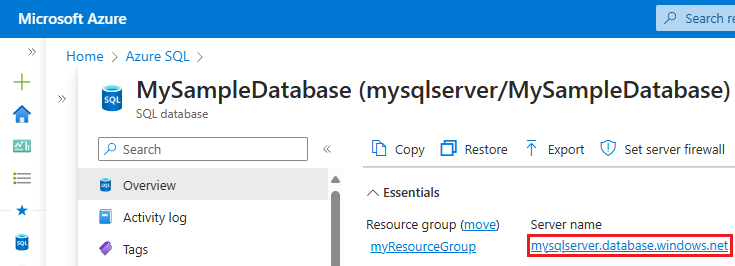
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
En el menú de recursos de SQL Server, seleccione Grupos de migración tras error en Administración de datos. Seleccione + Añadir grupo para abrir la página Grupo de migración tras error, donde puede crear un nuevo grupo de migración tras error.
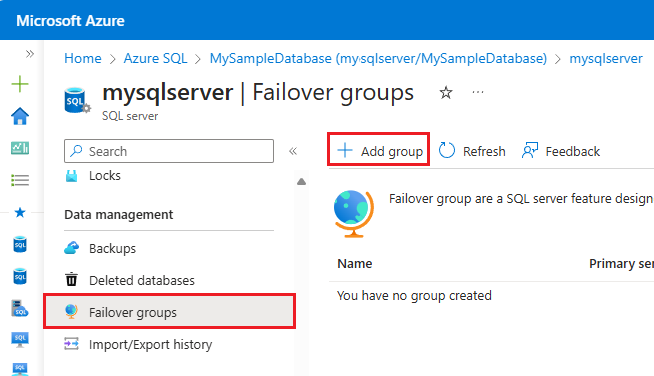
En la página Grupo de migración tras error:
- Proporcione un nombre de grupo de migración tras error.
- Elija un servidor secundario existente o cree un nuevo servidor seleccionando Crear nuevo en Servidor. El servidor secundario del grupo de conmutación por error debe estar en una región diferente que el servidor principal.
- Seleccione Configurar base de datos para abrir la página Bases de datos del grupo de migración tras error.
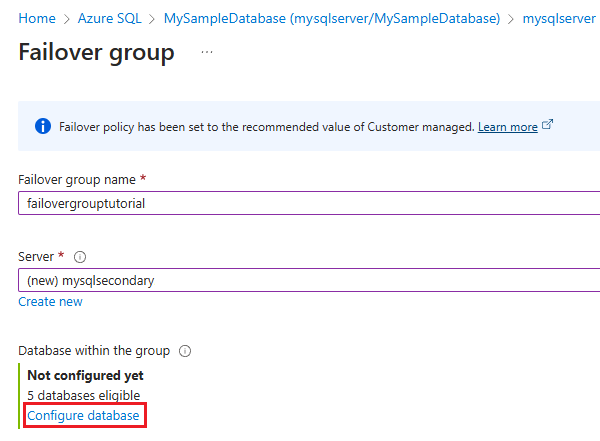
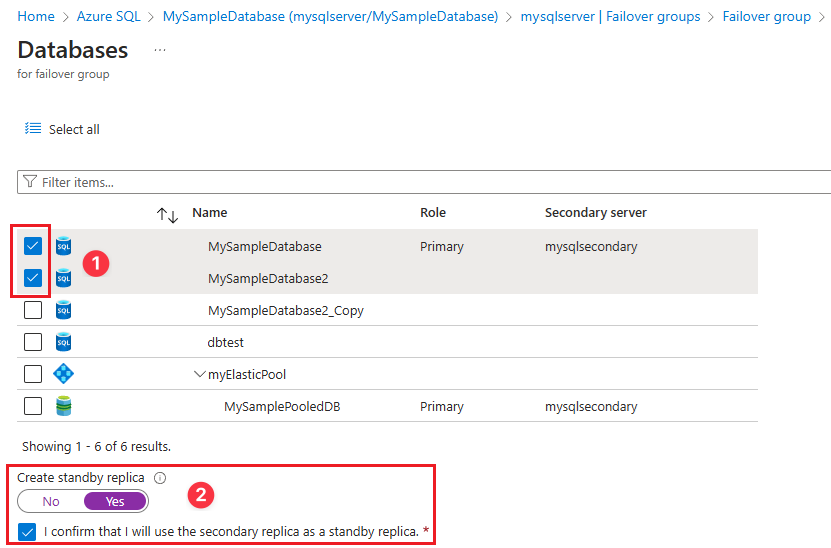
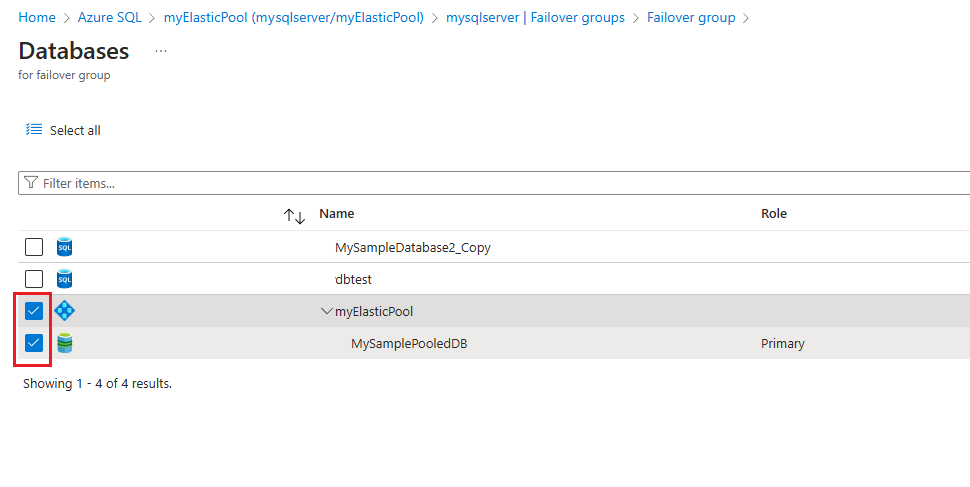
En la página Bases de datos del grupo de migración tras error:
- Seleccione las bases de datos que quiere añadir al grupo de migración tras error (n.º 1 en la captura de pantalla).
- (Opcional) Elija Sí si piensa designar estas bases de datos como réplicas en espera para usarlas solo para la recuperación ante desastres (n.º 2 en la captura de pantalla). Active la casilla para confirmar que usará la réplica para el modo de espera.
- Use Seleccionar para guardar la selección de la base de datos y volver a la página Grupo de migración tras error (no visible en la captura de pantalla).
Use Crear en la página Grupo de migración tras error para crear un grupo de migración tras error.
Prueba de conmutación por error planeada
Prueba la conmutación por error de tu grupo de conmutación por error sin pérdida de datos mediante Azure Portal o PowerShell.
Para probar la migración tras error de su grupo de migración tras error mediante Azure Portal, siga estos pasos:
Si conoce el servidor lógico que aloja la base de datos, vaya directamente a ella en Azure Portal. Si tiene que buscar el servidor, siga estos pasos:
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
Azure SQLen el cuadro de búsqueda. (Opcional) Seleccione la estrella junto a Azure SQL para marcarlo como favorito y agréguelo como un elemento del menú de servicios. - En la página de Azure SQL, busque la base de datos para la que desea probar la migración tras error y selecciónela para abrir el panel Base de datos de SQL.
- En el panel Información general de Base de datos de SQL, seleccione el nombre del servidor en Nombre del servidor para abrir el panel de SQL Server.
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
En el menú de recursos de SQL Server, seleccione Grupos de migración tras error en Administración de datos y, a continuación, elija un grupo de migración tras error existente para abrir la página Grupo de migración tras error.
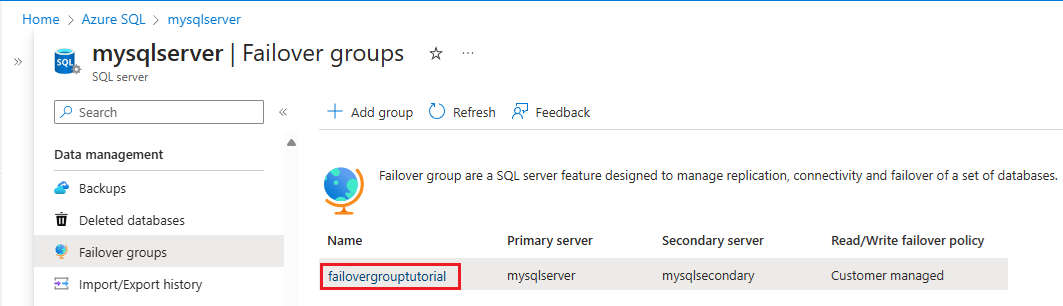
En la página Grupo de migración tras error:
- Revise cuál es el servidor principal y cuál es el secundario.
- Seleccione Migración tras error en la barra de comandos para conmutar por error el grupo de migración tras error que contiene la base de datos.
- Seleccione Sí en la advertencia que le notifica que las sesiones de TDS se desconectarán.
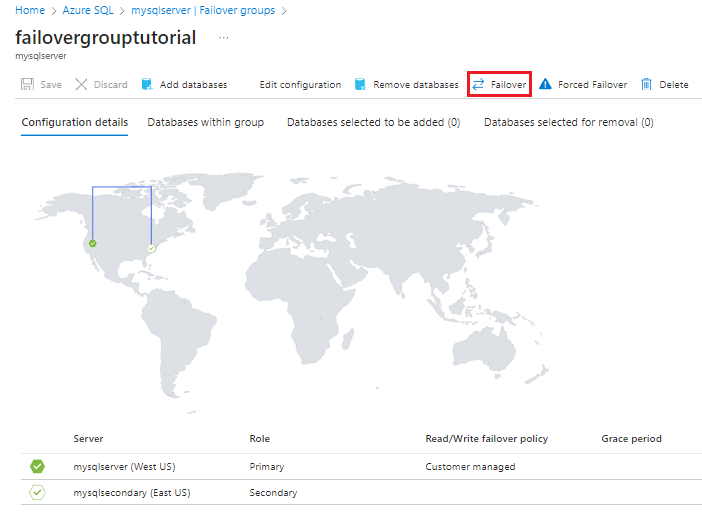
Revise qué servidor es ahora el principal y cuál el secundario. Una vez que la migración tras error se realice correctamente, los dos servidores intercambian roles, de modo que la que había sido la principal se convierte en la secundaria.
(Opcional) Vuelva a seleccionar Migración tras error para devolver los servidores a sus roles originales.
Para los scripts de un extremo a otro, consulta cómo agregar un grupo elástico a un grupo de conmutación por error con Azure PowerShell o la CLI de Azure.
Requisitos previos
Tenga en cuenta los siguientes requisitos previos para crear el grupo de conmutación por error para una base de datos agrupada:
- El grupo elástico principal ya debería existir. Cree un grupo elástico para comenzar.
- Si el servidor secundario ya existe, la configuración del firewall y de inicio de sesión del servidor debe coincidir con la del servidor principal.
Creación de un grupo de conmutación por error
Cree el grupo de migración tras error para su grupo elástico mediante Azure Portal, PowerShell o la CLI de Azure.
Importante
Si tiene que eliminar la base de datos secundaria después de añadirla a un grupo de migración tras error, quítela del grupo de migración tras error antes de eliminarla. Eliminar una base de datos secundaria antes de quitarla del grupo de conmutación por error puede provocar un comportamiento impredecible.
Para crear el grupo de migración tras error y añadir el grupo elástico mediante Azure Portal, siga estos pasos:
Vaya a la página Crear grupo elástico de SQL en Azure Portal. Cree un grupo elástico que:
- Tenga el mismo nombre que el grupo elástico del servidor principal.
- Use un servidor secundario que pretenda usar para el grupo de migración tras error. El servidor secundario debe estar en una región diferente al servidor principal, y la configuración de inicio de sesión y firewall del servidor debe coincidir con la del servidor principal. Cree un nuevo servidor si el servidor secundario aún no existe.
Si conoce el servidor lógico que aloja el grupo elástico principal, vaya directamente a él en Azure Portal. Si tiene que buscar el servidor, siga estos pasos:
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
Azure SQLen el cuadro de búsqueda. (Opcional) Seleccione la estrella junto a Azure SQL para marcarlo como favorito y agréguelo como un elemento del menú de servicios. - En la página de Azure SQL, busque el grupo elástico que desea añadir a un grupo de migración tras error y selecciónelo para abrir el panel Grupo elástico de SQL.
- En el panel Información general del grupo elástico de SQL, seleccione el nombre del servidor en Nombre del servidor para abrir el panel de SQL Server.
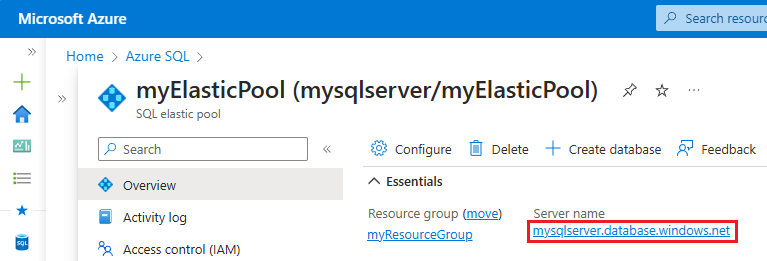
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
En el menú de recursos de SQL Server, seleccione Grupos de migración tras error en Administración de datos. Seleccione + Añadir grupo para abrir la página Grupo de migración tras error, donde puede crear un nuevo grupo de migración tras error.

En la página Grupo de migración tras error:
- Proporcione un nombre de grupo de migración tras error.
- Elija un servidor secundario existente. El servidor secundario del grupo de migración tras error debe estar en una región diferente que el servidor principal, y debe contener un grupo elástico con el mismo nombre que el servidor principal.
- Seleccione Configurar base de datos para abrir la página Bases de datos del grupo de migración tras error.
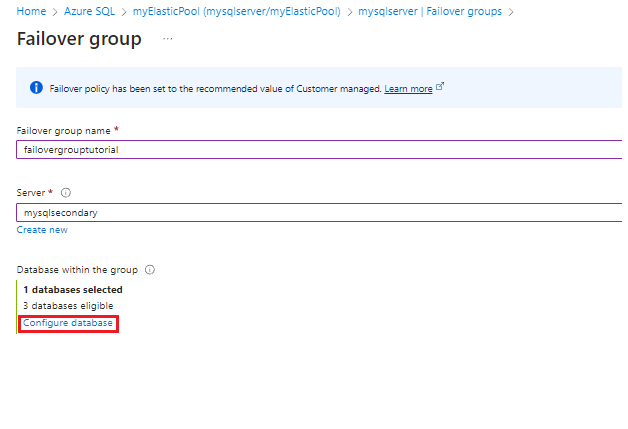
En la página Bases de datos del grupo de migración tras error, seleccione las bases de datos agrupadas que desea añadir al grupo de migración tras error. Use Seleccionar para guardar la selección de la base de datos y volver a la página Grupo de migración tras error.
Seleccione Crear en la página Grupo de migración tras error para crear el grupo de migración tras error. Al añadir el grupo elástico al grupo de migración tras error, se inicia automáticamente el proceso de replicación geográfica.
Prueba de conmutación por error planeada
Pruebe la migración tras error del grupo elástico sin pérdida de datos mediante Azure Portal, PowerShell o la CLI de Azure.
Se producirá un error en el grupo de conmutación por error en el servidor secundario y, a continuación, se realizará la conmutación por recuperación mediante Azure Portal.
Si conoce el servidor lógico que aloja el grupo elástico principal, vaya directamente a él en Azure Portal. Si tiene que buscar el servidor, siga estos pasos:
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
Azure SQLen el cuadro de búsqueda. (Opcional) Seleccione la estrella junto a Azure SQL para marcarlo como favorito y agréguelo como un elemento del menú de servicios. - En la página de Azure SQL, busque el grupo elástico que desea añadir a un grupo de migración tras error y selecciónelo para abrir el panel Grupo elástico de SQL.
- En el panel Información general del grupo elástico de SQL, seleccione el nombre del servidor en Nombre del servidor para abrir el panel de SQL Server.
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
En el menú de recursos de SQL Server, seleccione Grupos de migración tras error en Administración de datos y, a continuación, elija un grupo de migración tras error existente para abrir la página Grupo de migración tras error.
En la página Grupo de migración tras error:
- Revise cuál es el servidor principal y cuál es el secundario.
- Seleccione Migración tras error en la barra de comandos para conmutar por error el grupo de migración tras error que contiene la base de datos.
- Seleccione Sí en la advertencia que le notifica que las sesiones de TDS se desconectarán.
Revise qué servidor es ahora el principal y cuál el secundario. Una vez que la migración tras error se realice correctamente, los dos servidores intercambian roles, de modo que la que había sido la principal se convierte en la secundaria.
(Opcional) Vuelva a seleccionar Migración tras error para devolver los servidores a sus roles originales.
Modificar un grupo de migración tras error existente
Puede añadir o quitar bases de datos de un grupo de migración tras error existente o editar la configuración del grupo de migración tras error mediante Azure Portal, PowerShell y la CLI de Azure.
Para realizar cambios en un grupo de migración tras error existente mediante Azure Portal, siga estos pasos:
Si conoce el servidor lógico que aloja la base de datos o el grupo elástico, vaya directamente a él en Azure Portal. Si tiene que buscar el servidor, siga estos pasos:
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
Azure SQLen el cuadro de búsqueda. (Opcional) Seleccione la estrella junto a Azure SQL para marcarlo como favorito y agréguelo como un elemento del menú de servicios. - En la página Azure SQL, busque la base de datos o el grupo elástico que desea modificar y selecciónela para abrir el Base de datos de SQL o Grupo elástico de SQL.
- En el panel Información general de Base de datos de SQL o Grupo elástico de SQL, seleccione el nombre del servidor en Nombre del servidor para abrir el panel de SQL Server.
- Seleccione Azure SQL en el menú del servicio. Si Azure SQL no está en la lista, seleccione Todos los servicios y, a continuación, escriba
En el menú de recursos de SQL Server, seleccione Grupos de migración tras error en Administración de datos y, a continuación, elija un grupo de migración tras error existente para abrir la página Grupo de migración tras error.
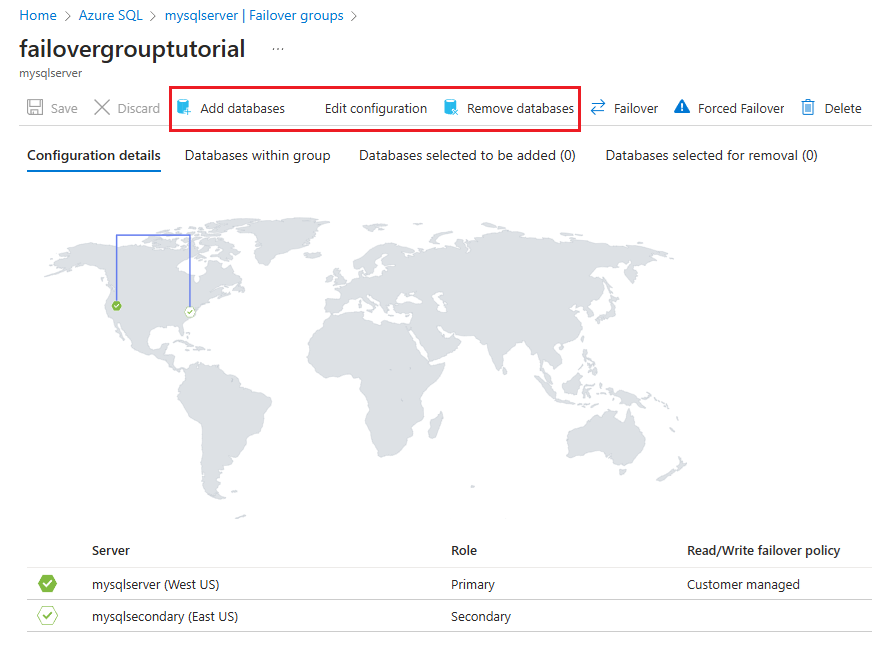
En la página Grupo de migración tras error, use la barra de comandos:
- Para añadir una base de datos, seleccione Añadir bases de datos para abrir el panel Añadir bases de datos al grupo de migración tras error y, a continuación, expanda #Databases para mostrar la lista de bases de datos en el servidor principal. Active la casilla situada junto a las bases de datos que desea añadir al grupo de migración tras error y, a continuación, use Seleccionar para guardar los cambios y añadir las bases de datos.
- Para eliminar una base de datos, seleccione Eliminar bases de datos para abrir el panel Eliminar bases de datos del grupo de migración tras error y, a continuación, expanda #Databases para enumerar las bases de datos del grupo de migración tras error. Active la casilla situada junto a las bases de datos que desea eliminar del grupo de migración tras error y, a continuación, use Seleccionar para guardar los cambios y eliminar las bases de datos.
- Para editar la directiva de migración tras error o configurar un período de gracia, seleccione Editar configuración para abrir el panel Editar configuraciones de los grupos de migración tras error y modificar la configuración. Use Seleccionar para guardar los cambios.
Uso de Private Link
El uso de un vínculo privado permite asociar un servidor lógico a una dirección IP privada específica dentro de la red virtual y la subred.
Para usar un vínculo privado con el grupo de conmutación por error, haga lo siguiente:
- Asegúrese de que el servidor principal y el secundarios se encuentran en una región emparejada.
- Crea la red virtual y la subred en cada región para hospedar puntos de conexión privados para el servidor principal y el secundario, de modo que tengan espacios de direcciones IP que no se superpongan. Por ejemplo, el intervalo de direcciones de la red virtual principal de 10.0.0.0/16 y el intervalo de direcciones de la red virtual secundaria de 10.0.0.1/16 se superpone. Para obtener más información sobre los intervalos de direcciones de la red virtual, consulte el blog Diseño de redes virtuales de Azure.
- Cree un punto de conexión privado y una zona DNS privada de Azure para el servidor principal.
- Cree también un punto de conexión privado para el servidor secundario, pero esta vez vuelva a usar la misma zona DNS privada que se creó para el servidor principal.
- Una vez establecido el vínculo privado, puede crear el grupo de conmutación por error siguiendo los pasos descritos anteriormente en este artículo.
Búsqueda del punto de conexión del cliente de escucha
Una vez que se configure su grupo de conmutación por error, actualice la cadena de conexión para su aplicación al punto de conexión del cliente de escucha. Esto mantiene tu aplicación conectada al cliente de escucha del grupo de conmutación por error, en lugar de la base de datos principal o el grupo elástico. De esa forma, no tendrá que actualizar manualmente la cadena de conexión cada vez que su entidad de base de datos conmute por error y el tráfico se enrute a la entidad que actualmente sea la principal.
El punto de conexión del cliente de escucha tiene el formato fog-name.database.windows.net y es visible en Azure Portal, al ver el grupo de conmutación por error:

Escalado de una base de datos en un grupo de conmutación por error
Puede escalar verticalmente o reducir verticalmente la base de datos principal a un tamaño de proceso diferente (en el mismo nivel de servicio) sin desconectar las secundarias. Cuando se escala verticalmente, se recomienda escalar verticalmente primero la secundaria geográfica y, después, escalar verticalmente la principal. Al reducir verticalmente, invierta el orden: primero escale verticalmente la principal y, a continuación, escale verticalmente la secundaria. Cuando se escala la base de datos a un nivel de servicio diferente, se aplica esta recomendación.
Esta secuencia se recomienda específicamente para evitar que la base de datos secundaria de una SKU inferior se sobrecargue y deba propagarse durante un proceso de actualización o degradación. También puede evitar este problema si hace que la base de datos principal sea de solo lectura, a costa de afectar a todas las cargas de trabajo de lectura y escritura en la réplica principal.
Nota:
Si creó una base de datos secundaria geográfica como parte de la configuración del grupo de conmutación por error, no se recomienda reducir verticalmente la base de datos secundaria geográfica. De este modo, se garantiza que la capa de datos tiene la capacidad suficiente para procesar la carga de trabajo habitual después de una conmutación por error. Es posible que no puedas escalar una SKU geográfica secundaria después de una conmutación por error manual no planeada cuando la SKU geográfica principal anterior no está disponible debido a una interrupción. Es una limitación conocida.
Evitación la pérdida de datos críticos
Debido a la elevada latencia de las redes de área extensa, la replicación geográfica usa un mecanismo de replicación asincrónica. La replicación asincrónica hace que la posibilidad de perder datos sea inevitable si se produce un error en la principal. Para proteger las transacciones críticas contra la pérdida de datos, un desarrollador de aplicaciones puede llamar al procedimiento almacenado sp_wait_for_database_copy_sync inmediatamente después de confirmar la transacción. La llamada a sp_wait_for_database_copy_sync bloquea el subproceso de llamada hasta que se transmite y protege la última transacción confirmada en el registro de transacciones de la base de datos secundaria. Pero no espera a que las transacciones transmitidas se reproduzcan (vuelvan a hacerse) en la secundaria. sp_wait_for_database_copy_sync está limitado a un vínculo de replicación geográfica específico. Cualquier usuario con derechos de conexión para la base de datos principal puede llamar a este procedimiento.
Nota:
sp_wait_for_database_copy_sync evita la pérdida de datos después de la conmutación por error geográfica para transacciones específicas, pero no garantiza la sincronización completa para el acceso de lectura. El retraso provocado por una llamada al procedimiento sp_wait_for_database_copy_sync puede ser considerable y depende del tamaño del registro de transacciones que todavía no se transmiten en la principal en el momento de la llamada.
Cambio de la región secundaria
Para ilustrar la secuencia de cambios, supondremos que el servidor A es el principal, el servidor B es el servidor secundario existente y el servidor C es la nueva instancia secundaria de la tercera región. Para realizar la transición, siga estos pasos:
- Cree instancias secundarias adicionales de cada base de datos del servidor A en el servidor C mediante la replicación geográfica activa. Cada base de datos del servidor A tendrá dos secundarios, uno en el servidor B y otro en el servidor C. Esto garantiza que las bases de datos principales permanezcan protegidas durante la transición.
- Elimine el grupo de conmutación por error. En este momento, se produce un error en los intentos de inicio de sesión que usan los puntos de conexión del grupo de conmutación por error.
- Vuelva a crear el grupo de conmutación por error con el mismo nombre entre los servidores A y C.
- Agregue todas las bases de datos principales del servidor A al nuevo grupo de conmutación por error. En este momento, se dejan de producir errores en los intentos de inicio de sesión.
- Elimine el servidor B. Todas las bases de datos de dicho servidor se eliminarán automáticamente.
Cambio de la región primaria
Para ilustrar la secuencia de cambios, supondremos que el servidor A es el servidor principal, el servidor B es el servidor secundario existente y el servidor C es la nueva instancia principal de la tercera región. Para realizar la transición, siga estos pasos:
- Haz una conmutación por error geográfica planeada para cambiar el servidor principal al B. El servidor A se convierte en el nuevo servidor secundario. La conmutación por error puede producir varios minutos de tiempo de inactividad. El tiempo real depende del tamaño del grupo de conmutación por error.
- Cree instancias secundarias adicionales de cada base de datos del servidor B en el servidor C mediante la replicación geográfica activa. Cada base de datos del servidor B tendrá dos secundarios, uno en el servidor A y otro en el servidor C. Esto garantiza que las bases de datos principales permanezcan protegidas durante la transición.
- Elimine el grupo de conmutación por error. En este momento, se produce un error en los intentos de inicio de sesión que usan los puntos de conexión del grupo de conmutación por error.
- Vuelva a crear el grupo de conmutación por error con el mismo nombre entre los servidores B y C.
- Agregue todas las bases de datos principales del servidor B al nuevo grupo de conmutación por error. En este momento, se dejan de producir errores en los intentos de inicio de sesión.
- Haz una conmutación por error geográfica planeada del grupo de conmutación por error para cambiar los servidores B y C. Ahora, el servidor C es el principal y el B es el secundario. Todas las bases de datos secundarias del servidor A se vincularán automáticamente a las instancias principales de C. Como en el paso 1, la conmutación por error puede producir varios minutos de tiempo de inactividad.
- Elimine el servidor A. Todas las bases de datos de dicho servidor se eliminarán automáticamente.
Importante
Cuando se elimina el grupo de conmutación por error, también se eliminan los registros de DNS de los puntos de conexión del agente de escucha. En ese momento, existe una probabilidad distinta de cero de que otra persona cree un grupo de conmutación por error o un alias DNS de servidor con el mismo nombre. Dado que los nombres de grupo de conmutación por error y los alias DNS deben ser únicos globalmente, esto impedirá que vuelva a usar el mismo nombre. Para minimizar este riesgo, no utilice nombres de grupo de conmutación por error genéricos.
Grupos de conmutación por error y la seguridad de red
En el caso de algunas aplicaciones, las reglas de seguridad requieren que el acceso de red a la capa de datos esté restringido a un componente o componentes específicos, como una máquina virtual, un servicio web, etc. Este requisito presenta algunos desafíos para el diseño de la continuidad empresarial y el uso de los grupos de conmutación por error. Considere las siguientes opciones al implementar dicho acceso restringido.
Uso de los grupos de conmutación por error y los puntos de conexión de servicio de red virtual
Si usas reglas y puntos de conexión de servicio Virtual Network para restringir el acceso a la base de datos, ten en cuenta que cada punto de conexión de servicio de red virtual solo se aplica a una región de Azure. El punto de conexión no permite que otras regiones acepten la comunicación de la subred. Por lo tanto, solo las aplicaciones de cliente implementadas en la misma región pueden conectarse a la base de datos principal. Puesto que una conmutación por error geográfica provoca que las sesiones de cliente de SQL Database se vuelvan a enrutar al servidor en una región diferente (secundaria), puede producirse un error en las sesiones si se originaron desde un cliente de fuera de esa región. Por ese motivo, la directiva de conmutación por error de Microsoft no se puede habilitar si se incluyen los servidores implicados en las reglas de red virtual. Para admitir la directiva de conmutación por error manual, sigue estos pasos:
- Aprovisiona las copias redundantes de los componentes frontend de la aplicación (servicio web, máquinas virtuales, etc.) en la región secundaria.
- Configura las reglas de red virtual individualmente para el servidor principal y secundario.
- Habilita la conmutación por error frontend con una configuración de Traffic Manager.
- Inicia una conmutación por error geográfica manualmente cuando se detecte la interrupción. Esta opción está optimizada para las aplicaciones que requieren una latencia coherente entre el nivel de datos y de frontend, y admite la recuperación cuando se ven afectadas por la interrupción la capa de datos, la capa frontend o ambas.
Nota:
Si usas el agente de escucha de solo lectura para equilibrar una carga de trabajo de solo lectura, asegúrate de que esta carga de trabajo se ejecuta en una máquina virtual o en otro recurso en la región secundaria de modo que pueda conectarse a la base de datos secundaria.
Uso de grupos de conmutación por error y reglas de firewall
Si el plan de continuidad empresarial requiere un proceso de conmutación por error mediante el uso de grupos con conmutación por error, puedes restringir el acceso a SQL Database con las reglas de firewall de IP públicas. Esta configuración garantiza que una conmutación por error geográfica no bloquee las conexiones desde los componentes frontend y da por supuesto que la aplicación tolera la mayor latencia entre la capa de datos y el frontend.
Para admitir la conmutación por error de grupos de conmutación por error, sigue estos pasos:
- Cree una dirección IP pública.
- Cree un equilibrador de carga público y asígnele la dirección IP pública.
- Cree una red virtual y las máquinas virtuales para los componentes front-end.
- Cree un grupo de seguridad de red y configure las conexiones entrantes.
- Asegúrese de que las conexiones salientes estén abiertas para Azure SQL Database en una región mediante el uso de una
Sql.<Region>Sql.<Region>. - Cree una regla de firewall de SQL Database para permitir el tráfico entrante desde la dirección IP pública que creó en el paso 1.
Para más información acerca de cómo configurar el acceso de salida y qué dirección IP usar en las reglas de firewall, consulte Conexiones salientes del equilibrador de carga.
Importante
Para garantizar la continuidad empresarial durante las interrupciones regionales, debes garantizar la redundancia geográfica tanto para los componentes front-end como para las bases de datos.
Permisos
Los permisos para un grupo de conmutación por error se administran a través del control de acceso basado en rol de Azure (Azure RBAC).
El acceso de escritura de RBAC de Azure es necesario para crear y administrar grupos de conmutación por error. El rol Colaborador de SQL Server tiene todos los permisos necesarios para administrar grupos de conmutación por error.
En la tabla siguiente se enumeran los ámbitos de permiso específicos para Azure SQL Database:
| Acción | Permiso | Ámbito |
|---|---|---|
| Creación de un grupo de conmutación por error | Acceso de escritura de RBAC de Azure | Servidor principal Servidor secundario Todas las bases de datos del grupo de migración tras error |
| Actualización de grupo de conmutación por error | Acceso de escritura de RBAC de Azure | Grupo de conmutación por error Todas las bases de datos del servidor principal actual |
| Conmutación por error de un grupo de conmutación por error | Acceso de escritura de RBAC de Azure | Grupo de conmutación por error en el nuevo servidor |
Limitaciones
Tenga en cuenta las siguientes limitaciones:
- No se pueden crear grupos de conmutación por error entre dos servidores en la misma región de Azure.
- Los grupos de conmutación por error admiten la replicación geográfica de todas las bases de datos en el grupo solo a un servidor lógico secundario en otra región.
- No se puede cambiar el nombre de los grupos de conmutación por error. Tendrá que eliminar el grupo y volver a crearlo con otro nombre.
- No se admiten los cambios de nombre de la base de datos para las bases de datos de un grupo de conmutación por error. Tendrás que eliminar temporalmente el grupo de conmutación por error para poder cambiar el nombre de una base de datos o quitar la base de datos del grupo de conmutación por error.
- La eliminación de un grupo de conmutación por error de una base de datos única o agrupada no detiene la replicación y no elimina la base de datos replicada. Tendrás que detener manualmente la replicación geográfica y eliminar la base de datos del servidor secundario si querías volver a agregar una base de datos única o agrupada a un grupo de conmutación por error una vez que se haya quitado. Si no hace nada de esto, es posible que se produzca un error similar a
The operation cannot be performed due to multiple errorsal intentar agregar la base de datos al grupo de conmutación por error. - El nombre del grupo de conmutación por error está sujeto a restricciones de nomenclatura.
- Al crear un nuevo grupo de migración tras error o al añadir bases de datos a un grupo de migración tras error existente, solo puede designar las bases de datos como réplicas en esperaal usar Azure Portal: Azure PowerShell y la CLI de Azure no están disponibles actualmente.
Administración mediante programación de grupos de conmutación por error
Los grupos de migración tras error también se pueden administrar mediante programación con Azure PowerShell, la CLI de Azure y la API de REST. En las tablas siguientes se describe el conjunto de comandos disponibles. Los grupos de conmutación por error incluyen un conjunto de API de Azure Resource Manager para la administración, en el que se incluyen la API de REST de Azure SQL Database y los cmdlets de Azure PowerShell. Estas API requieren que se usen grupos de recursos y admiten el control de acceso basado en rol de Azure (Azure RBAC). Para más información sobre cómo implementar los roles de acceso, consulte Control de acceso basado en roles de Azure (Azure RBAC).
| Cmdlet | Descripción |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Este comando crea un grupo de conmutación por error y lo registra en el servidor principal y el servidor secundario |
| Add-AzSqlDatabaseToFailoverGroup | Agrega una o varias bases de datos a un grupo de conmutación por error. |
| Remove-AzSqlDatabaseFromFailoverGroup | Elimina una o varias bases de datos de un grupo de migración tras error. |
| Remove-AzSqlDatabaseFailoverGroup | Quita un grupo de conmutación por error del servidor. |
| Get-AzSqlDatabaseFailoverGroup | Recupera la configuración de un grupo de conmutación por error. |
| Set-AzSqlDatabaseFailoverGroup | Modifica la configuración de un grupo de conmutación por error. |
| Switch-AzSqlDatabaseFailoverGroup | Desencadena la conmutación por error de un grupo de conmutación por error en el servidor secundario. |
Nota:
Es posible implementar el grupo de conmutación por error entre suscripciones mediante el -PartnerSubscriptionId parámetro de Azure PowerShell a partir de Az.SQL 3.11.0. Para más información, consulte el siguiente ejemplo.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de