Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() Azure SQL Database
Azure SQL Database
Sin servidor es un nivel de procesamiento para bases de datos individuales en Azure SQL Database que ajusta automáticamente la computación según la demanda de carga de trabajo y cobra por la cantidad de computación usada por segundo. El nivel de proceso sin servidor también detiene automáticamente las bases de datos durante períodos inactivos cuando solo se factura el almacenamiento y reanuda automáticamente las bases de datos cuando finaliza la actividad. El nivel de proceso sin servidor está disponible en el nivel de servicio De uso general y en el nivel de servicio Hiperescala.
Actualmente, la pausa automática y la reanudación automática solo se admiten actualmente en el nivel de servicio De uso general.
Información general
Un intervalo de escalado automático de proceso y un retraso de pausa automática son parámetros importantes para el nivel de proceso sin servidor. La configuración de estos parámetros da forma a la experiencia de rendimiento de la base de datos y el costo de proceso.
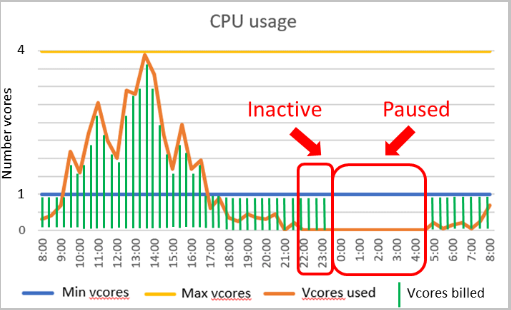 Diagrama que indica cuándo la facturación sin servidor dejará de incurrir en cargos por cálculo debido a la inactividad.
Diagrama que indica cuándo la facturación sin servidor dejará de incurrir en cargos por cálculo debido a la inactividad.
Configuración del rendimiento
- Los valores mínimos de núcleos virtuales y los valores máximos de núcleos virtuales son parámetros configurables que definen el intervalo de capacidad de proceso disponible para la base de datos. Los límites de memoria y E/S son proporcionales al intervalo de vCores especificado.
- La demora de pausa automática es un parámetro configurable que define el período de tiempo de que la base de datos debe estar inactiva antes de pausarse automáticamente. La base de datos se reanuda automáticamente cuando se produce el siguiente inicio de sesión u otra actividad. Como alternativa, se puede deshabilitar la pausa automática.
Coste
El coste de una base de datos sin servidor es la suma del coste de proceso y el coste de almacenamiento. El coste de almacenamiento se determina de la misma manera que el nivel de proceso aprovisionado.
- Cuando el uso de proceso se sitúa entre los límites mínimos y máximos configurados, el coste de proceso se basa en el núcleo virtual y la memoria utilizada.
- Cuando el uso de proceso está por debajo de los límites mínimos configurados, el coste de proceso se basa en los núcleos virtuales mínimos y la cantidad mínima de memoria configurada.
- Cuando se pausa la base de datos, el coste de proceso es cero y solo se incurre en costes de almacenamiento.
Para más detalles sobre costes, consulte Facturación.
Escenarios
Este nivel de proceso sin servidor ofrece una relación entre precio y rendimiento optimizada para bases de datos únicas con patrones de uso intermitentes e impredecibles, que pueden permitirse alguna demora en el calentamiento de los recursos de proceso después de períodos de inactividad. En cambio, el nivel de proceso aprovisionado ofrece una relación entre precio y rendimiento optimizada para bases de datos únicas o varias bases de datos en grupos elásticos con mayor uso medio que no pueden permitirse ninguna demora en el calentamiento de los recursos de proceso.
Escenarios adecuados para el proceso sin servidor
- Bases de datos únicas con patrones de uso impredecibles e intermitentes, intercalados con períodos de inactividad y menor uso promedio de proceso a lo largo del tiempo.
- Bases de datos individuales en el nivel de computación aprovisionado que se reescalan con frecuencia y clientes que prefieren delegar el reescalado de computación al servicio.
- Nuevas bases de datos únicas sin historial de uso donde el ajuste de tamaño de proceso es difícil o no es posible calcular antes de la implementación en un Azure SQL Database.
Escenarios adecuados para el proceso aprovisionado
- Bases de datos únicas con patrones de uso más regular y predecible y mayor uso promedio de proceso a lo largo del tiempo.
- Bases de datos que no pueden tolerar sacrificios de rendimiento debido a recortes de memoria más frecuentes o demoras al reanudar desde un estado de pausa.
- Varias bases de datos con patrones de uso impredecibles e intermitentes que se pueden consolidar en grupos elásticos para una mejor optimización de la relación precio-rendimiento.
Comparación de los niveles de proceso
La tabla siguiente resume las diferencias entre el nivel de proceso sin servidor y el nivel de proceso aprovisionado:
| Proceso sin servidor | Computación provisionada | |
|---|---|---|
| Patrones de uso de bases de datos | Uso intermitente e impredecible con menor uso promedio de proceso a lo largo del tiempo. | Patrones de uso más regulares con mayor uso promedio de proceso a lo largo del tiempo, o varias bases de datos que usen grupos elásticos. |
| Trabajo de administración del rendimiento | Inferior | Superior |
| Escalado de proceso | Automático | Guía |
| Capacidad de respuesta del cálculo | Menor después de períodos de inactividad | Inmediata |
| Granularidad de facturación | Por segundo | Por hora |
Modelo de compra y nivel de servicio
En la tabla siguiente se describe la compatibilidad sin servidor en función del modelo de compra, los niveles de servicio y el hardware:
| Categoría | Soportado | No soportado |
|---|---|---|
| Modelo de compra | vCore | DTU |
| Nivel de servicio | Uso general Hiperescala |
Crítico para la empresa |
| Hardware | Serie estándar (Gen5) | El resto de hardware |
Escalado automático
Escalado de la capacidad de respuesta
Las bases de datos sin servidor se ejecutan en la infraestructura con capacidad suficiente para satisfacer la demanda de recursos sin interrupciones para cualquier cantidad de proceso solicitada dentro de los límites establecidos por la configuración máxima de núcleo virtual. En general, la ampliación de la CPU hasta el número máximo de vCores configurados es casi instantánea y se produce sin ninguna interrupción de la conectividad. En ocasiones, el escalado vertical puede tardar más tiempo si es necesario reequilibrar los recursos de la máquina, lo que puede tardar hasta unos minutos. La base de datos permanece en línea durante el reequilibrio, excepto al final de la operación cuando se quitan brevemente las conexiones. Este tipo de reequilibrio es raro. En todos los casos, el escalado vertical de CPU es independiente del escalado vertical de memoria.
Administración de memoria
En los niveles de servicio De uso general e Hiperescala, la memoria de las bases de datos sin servidor se reclama con mayor frecuencia que la de las bases de datos de proceso aprovisionadas. Este comportamiento es importante para controlar costos en entornos sin servidor y puede afectar al rendimiento.
Reclamación de memoria caché
A diferencia de las bases de datos de proceso aprovisionadas, la memoria de la caché de SQL se recupera desde una base de datos sin servidor cuando el uso de CPU o de la memoria caché activa es bajo.
- El uso de la memoria caché activa se considera bajo cuando el tamaño total de las entradas de caché más recientes está por debajo de un determinado umbral durante un periodo de tiempo.
- Cuando se desencadena la reclamación de la memoria caché, el tamaño de la caché de destino se reduce de forma incremental a una fracción del tamaño anterior y la reclamación solo continúa si el uso sigue siendo bajo.
- Cuando se produce la recuperación de la caché, la directiva para seleccionar las entradas de la caché que se van a expulsar es la misma directiva de selección que para las bases de datos de proceso aprovisionadas cuando la presión de memoria es superior
- El tamaño de la memoria caché no se reduce nunca por debajo del límite de memoria mínimo definido por el número mínimo de núcleos virtuales.
En el caso de las bases de datos sin servidor y las de proceso aprovisionadas, se pueden expulsar entradas de la caché si se usa toda la memoria disponible.
Cuando el uso de la CPU es bajo, la utilización de la caché activa puede ser alta en función del patrón de uso e impedir la liberación de memoria. Además, puede haber otros retrasos después de que la actividad del usuario se detenga antes de que se produzca la reclamación de la memoria debido a los procesos en segundo plano periódicos que responden a la actividad anterior del usuario. Por ejemplo, las operaciones de eliminación y las tareas de limpieza del Almacén de consultas generan registros fantasma que están marcados para su eliminación, pero no se eliminan físicamente hasta que se realiza el proceso de limpieza de registros fantasma. La limpieza de registros fantasma puede suponer la lectura de páginas de datos en la caché.
Hidratación de la memoria caché
La memoria caché de SQL crece a medida que se capturan datos del disco de la misma manera y a la misma velocidad que para las bases de datos aprovisionadas. Cuando la base de datos está ocupada, la memoria caché puede crecer sin restricciones mientras haya memoria disponible.
Administración de la memoria caché de disco
En el nivel de servicio Hiperescala para los niveles de proceso aprovisionados y sin servidor, cada réplica de proceso usa una caché de la extensión del grupo de búferes resistentes (RBPEX), que almacena páginas de datos en el SSD local para mejorar el rendimiento de E/S. Sin embargo, en el nivel de proceso sin servidor para Hiperescala, la caché RBPEX para cada réplica de proceso crece y disminuye automáticamente en respuesta al aumento y la reducción de la demanda de la carga de trabajo. El tamaño máximo que puede alcanzar la caché RBPEX es tres veces la memoria máxima configurada para la base de datos. Para obtener más información sobre los límites de escalado automático de RBPEX y de memoria máximos si no hay servidor, consulte los límites de recursos de Hiperescala sin servidor.
Pausa automática y reanudación automática
Actualmente, la pausa y reanudación automáticas sin servidor solo se admiten en la capa de propósito general.
Pausa automática
La pausa automática se desencadena si todas las condiciones siguientes se cumplen durante la demora de pausa automática:
- Número de sesiones = 0
- CPU = 0 para la carga de trabajo de usuario que se ejecuta en el grupo de usuarios
Hay disponible una opción para deshabilitar la pausa automática si se desea.
Las características siguientes no admiten la pausa automática, pero admiten el escalado automático. Si se utiliza cualquiera de las siguientes características, la pausa automática debe estar desactivada y la base de datos permanece en línea, independientemente de la duración de la inactividad de la base de datos:
- Replicación geográfica (replicación geográfica activa y grupos de conmutación por error ).
- Retención de copia de seguridad a largo plazo (LTR).
- Base de datos de sincronización utilizada en SQL Data Sync. A diferencia de la base de datos de sincronización, las bases de datos centrales y de miembros admiten pausas automáticas.
- Alias DNS creado para el servidor lógico que contiene una base de datos sin servidor.
- Trabajos elásticos, la base de datos sin servidor habilitada para pausa automática no es compatible como Base de datos de trabajos. Las bases de datos sin servidor que son objeto de un trabajo elástico admiten la pausa automática. Las conexiones de trabajo reanudan una base de datos.
Se impide temporalmente la pausa automática durante la implementación de algunas actualizaciones de servicio, que requiere que la base de datos esté en línea. En tales casos, se vuelve a permitir la pausa automática una vez finalizada la actualización del servicio.
Solución de problemas de la pausa automática
Si la pausa automática está habilitada y las características que bloquean la pausa automática no se usan, pero una base de datos no se pausa automáticamente después del período de retraso, es posible que las sesiones de aplicación o usuario impidan la pausa automática.
Para ver si hay alguna aplicación o sesión de usuario conectada actualmente a la base de datos, conéctese a la base de datos mediante cualquier herramienta de cliente y ejecute la consulta siguiente:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Sugerencia
Después de ejecutar la consulta, asegúrese de desconectarse de la base de datos. De lo contrario, la sesión abierta usada por la consulta impide la pausa automática.
- Si el conjunto de resultados no está vacío, significa que hay sesiones que impiden la pausa automática.
- Si el conjunto de resultados está vacío, todavía es posible que las sesiones estuvieran abiertas, posiblemente durante un corto periodo de tiempo, en algún momento anterior durante el periodo de retraso de la pausa automática. Para comprobar la actividad durante el período de retraso, puede usar Auditing para Azure SQL Database y Azure Synapse Analytics y examinar los datos de auditoría durante el período correspondiente.
Importante
La presencia de sesiones abiertas, con o sin uso simultáneo de CPU en el grupo de recursos de usuario, es la razón más común de que una base de datos sin servidor no se pause automáticamente según lo previsto.
Reanudación automática
La reanudación automática se desencadena si se cumple cualquiera de las siguientes condiciones en cualquier momento:
| Característica | Desencadenador de reanudación automática |
|---|---|
| Autenticación y autorización | Intento de inicio de sesión |
| Detección de amenazas | Habilitación o deshabilitación de la configuración de detección de amenazas en el nivel de base de datos o servidor. Modificación de la configuración de detección de amenazas en el nivel de base de datos o servidor. |
| Clasificación y detección de datos | Adición, modificación, eliminación o visualización de las etiquetas de confidencialidad |
| Auditoría | Visualización de registros de auditoría Actualización o visualización de la directiva de auditoría. |
| Enmascaramiento de datos | Adición, modificación, eliminación o visualización de reglas de enmascaramiento de datos |
| Cifrado de datos transparente | Visualización del estado del cifrado de datos transparente |
| Evaluación de vulnerabilidades | Exámenes iniciados manualmente y exámenes periódicos si está habilitado |
| Almacén de datos de consulta (rendimiento) | Modificación o visualización de la configuración de Almacén de consultas |
| Recomendaciones de rendimiento | Visualización o aplicación de recomendaciones de rendimiento |
| Ajuste automático | Aplicación y comprobación de recomendaciones de ajuste automático, como la indexación automática |
| Copia de base de datos | Creación de base de datos como copia. Exportación a un archivo BACPAC. |
| Sincronización de datos SQL | Sincronización entre la base de datos central y las bases de datos miembro que se ejecutan según una programación configurable o bien de forma manual |
| Modificación de algunos metadatos de base de datos | Agregar o modificar etiquetas Azure en la base de datos. Cambio de núcleos virtuales máximos, núcleos virtuales mínimos o retraso de la pausa automática. |
| SQL Server Management Studio (SSMS) | Al usar las versiones de SSMS anteriores a 18.1 y abrir una nueva ventana de consulta para cualquier base de datos en el servidor, se reanuda cualquier base de datos en pausa automática en el mismo servidor. Este comportamiento no se produce si se usa SSMS versión 18.1 o posterior. |
La supervisión, la administración u otras soluciones que realizan cualquiera de estas operaciones desencadenan la reanudación automática. También se desencadena la reanudación automática durante la implementación de algunas actualizaciones de servicio que requieren que la base de datos esté en línea.
Identificación del activador de reanudación automática
Los desencadenadores de reanudación automática se muestran en el registro de actividad de Azure Monitor para las operaciones de Reanudar bases de datos en la propiedad Caller del JSON de los eventos Iniciado y Cumplido.
Conectividad
Si una base de datos sin servidor está en pausa, el primer intento de conexión reanuda la base de datos y devuelve un error con el código 40613 que indica que la base de datos no está disponible. Una vez reanudada la base de datos, vuelva a intentar la conexión. No será necesario modificar los clientes de la base de datos que sigan las recomendaciones de lógica de reintento de conexión. Para ver las opciones y recomendaciones de lógica de reintento de conexión, consulte:
- Lógica de reintento de conexión en SqlClient
- Lógica de reintento de conexión en SQL Database mediante Entity Framework Core
- Lógica de reintento de conexión en Base de Datos SQL mediante Entity Framework 6
- Lógica de reintento de conexión en SQL Database mediante ADO.NET
Latencia
La latencia suele estar en el orden de un minuto para reanudarse automáticamente y entre 1 y 10 minutos para pausar automáticamente. La latencia de cualquiera de las operaciones puede ser tan baja como el orden de un segundo.
Cifrado de datos transparente administrado por el cliente (BYOK)
Eliminación o revocación de claves
Si se usa el cifrado de datos transparente administrado por el cliente (BYOK) y la base de datos sin servidor se pausa automáticamente cuando se produce la eliminación o la revocación de claves, la base de datos permanece en estado de pausa automática. En este caso, después de que la base de datos se reanude la próxima vez, esta dejará de estar accesible en aproximadamente 10 minutos. Si la base de datos pasa a ser inaccesible, el proceso de recuperación es el mismo que para las bases de datos de proceso aprovisionadas. Si la base de datos sin servidor está en línea cuando se produce la eliminación o la revocación de claves, la base de datos también pasa a ser inaccesible en el plazo de unos 10 minutos, como sucede con las bases de datos de proceso aprovisionadas.
Rotación de claves
Si se usa cifrado de datos transparente administrado por el cliente (BYOK) y la pausa automática sin servidor está habilitada, la base de datos se reanuda automáticamente cada vez que se rotan las claves. La base de datos se pausará automáticamente cuando se cumplan las condiciones de pausa automática.
Creación de una base de datos sin servidor nueva
La creación de una nueva base de datos o el cambio de una base de datos existente a un nivel de proceso sin servidor siguen el mismo patrón que la creación de una nueva base de datos en el nivel de proceso aprovisionado y constan de los dos pasos siguientes:
Especifique el objetivo de servicio. El objetivo de servicio preceptúa el nivel de servicio, la configuración de hardware y el máximo de núcleos virtuales. Para las opciones de objetivo de servicio, vea Límites de recursos sin servidor
Opcionalmente, especifique el número mínimo de núcleos virtuales (vCores) y el retraso de la pausa automática para cambiar sus valores predeterminados. En la siguiente tabla se muestran los valores disponibles para estos parámetros.
Parámetro Opciones de valores Valor predeterminado Mínimo de núcleos virtuales Depende del número máximo de núcleos virtuales configurados, consulte los límites de recursos. 0,5 núcleos virtuales Retraso de la pausa automática Mínimo: 15 minutos
Máximo: 10 080 minutos (siete días)
Incrementos: 1 minuto
Deshabilitar la pausa automática: -160 minutos
En el siguiente ejemplo se crea una base de datos en el nivel de proceso sin servidor.
Uso del portal de Azure
Consulte Quickstart: Creación de una base de datos única en Azure SQL Database mediante el portal de Azure.
Uso de PowerShell
- Uso general
- Hiperescala
Cree una base de datos De uso general sin servidor nueva con el siguiente ejemplo de PowerShell:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Uso de CLI de Azure
- Uso general
- Hiperescala
Cree una nueva base de datos de uso general sin servidor con el siguiente ejemplo de CLI de Azure:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Uso de Transact-SQL (T-SQL)
Cuando usa T-SQL para crear una base de datos sin servidor, se aplican los valores por defecto para los vCores mínimos y para el retraso de pausa automática. Sus valores se pueden cambiar más adelante desde el portal de Azure o a través de la API, incluido PowerShell, CLI de Azure y REST.
Para obtener más información, consulte CREATE DATABASE.
- Uso general
- Hiperescala
Cree una base de datos sin servidor De uso general nueva con el siguiente ejemplo de T-SQL:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Movimiento de una base de datos entre niveles de proceso o niveles de servicio
Una base de datos se puede mover entre el nivel de proceso aprovisionado y el nivel de proceso sin servidor.
Una base de datos sin servidor también se puede mover del nivel de servicio De uso general al nivel de servicio Hiperescala. Para obtener más información, vea Convertir una base de datos existente en Hiperescala.
Al mover una base de datos entre niveles de proceso, especifique el modelo compute como parámetro Serverless o Provisioned al usar PowerShell o CLI de Azure, o el SERVICE_OBJECTIVE al usar T-SQL. Revise los límites de recursos para identificar el objetivo de servicio apropiado.
En los siguientes ejemplos se mueve una base de datos existente desde una computación aprovisionada a una computación sin servidor.
Uso de PowerShell
- Uso general
- Hiperescala
Mueva una base de datos de cálculo de propósito general aprovisionado al nivel de cálculo sin servidor con el siguiente ejemplo de PowerShell:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Uso de CLI de Azure
- Uso general
- Hiperescala
Mueva una base de datos de proceso general aprovisionada al nivel de proceso sin servidor con el siguiente ejemplo de CLI de Azure.
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Uso de Transact-SQL (T-SQL)
Cuando se utiliza T-SQL para mover una base de datos entre niveles de proceso, se aplican valores predeterminados para los núcleos virtuales mínimos y el retraso de pausa automática. Sus valores se pueden cambiar posteriormente desde el portal de Azure o a través de la API, incluidos PowerShell, CLI de Azure y REST. Para más información, consulte ALTER DATABASE.
- Uso general
- Hiperescala
Mueva una base de datos De uso general de proceso aprovisionada al nivel de proceso sin servidor con el siguiente ejemplo de T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Modificación de la configuración sin servidor
Uso de PowerShell
Utilice Set-AzSqlDatabase para modificar los núcleos virtuales máximos o mínimos y el retraso de la pausa automática. Use los argumentos MaxVcore, MinVcore y AutoPauseDelayInMinutes. La pausa automática sin servidor no se admite actualmente en el nivel Hiperescala, por lo que el argumento de demora de pausa automática solo se aplica al nivel De uso general.
Uso de CLI de Azure
Utilice az sql db update para modificar los núcleos virtuales máximos o mínimos y el retraso de la pausa automática. Use los argumentos capacity, min-capacity y auto-pause-delay. La pausa automática sin servidor no se admite actualmente en el nivel Hiperescala, por lo que el argumento de demora de pausa automática solo se aplica al nivel De uso general.
Supervisar
Recursos utilizados y facturados
Los recursos de una base de datos sin servidor contienen el paquete de la aplicación, la instancia de SQL y las entidades de grupo de recursos del usuario.
Paquete de aplicaciones
El paquete de aplicaciones es el límite de administración de recursos más externo de una base de datos, independientemente de si la base de datos se encuentra en un nivel de proceso sin servidor o aprovisionado. El paquete de la aplicación contiene la instancia de SQL y servicios externos (como la búsqueda de texto completo) que, en conjunto, abarcan todos los recursos de usuario y del sistema que utiliza una base de datos en SQL Database. Generalmente, la instancia de SQL domina el uso de recursos global en el paquete de aplicaciones.
Pool de recursos de usuario
El grupo de recursos de usuario es un límite interno de administración de recursos para una base de datos, independientemente de si la base de datos está en un nivel de proceso sin servidor o aprovisionado. El grupo de recursos de usuario asigna CPU y E/S a la carga de trabajo de usuario generada por consultas DDL (CREATE y ALTER) y DML (INSERT, UPDATE, DELETE, MERGE y SELECT). Por lo general, estas consultas representan la proporción de uso dentro del paquete de aplicaciones más importante.
Métricas
En la siguiente tabla se recogen las métricas para supervisar el uso de recursos del paquete de la aplicación y el grupo de recursos de usuario de una base de datos sin servidor, incluidas todas las réplicas geográficas:
| Entidad | Métrica | Descripción | Unidades |
|---|---|---|---|
| Paquete de aplicaciones | porcentaje_de_cpu_de_la_aplicación | Porcentaje de núcleos virtuales utilizado por la aplicación respecto al máximo de núcleos virtuales permitido para la aplicación. Para Hiperescala sin servidor, esta métrica se expone para todas las réplicas principales, con nombre y geográficas. | Porcentaje |
| Paquete de aplicaciones | app_cpu_billed | La cantidad de procesos que se facturan para la aplicación durante el período de informe. El importe pagado durante este período es el producto de esta métrica por el precio de la unidad de núcleo virtual. Los valores de esta métrica se determinan al agregar el máximo de CPU utilizada y la memoria usada por segundo. Si la cantidad utilizada es menor que la cantidad mínima aprovisionada definida por el mínimo de núcleos virtuales y la memoria mínima, se factura la cantidad mínima aprovisionada. Para comparar la CPU con la memoria para fines de facturación, la memoria se normaliza en unidades de núcleos virtuales reescaleando la cantidad de memoria en GB a 3 GB por cada núcleo virtual. Para la Hiperescala sin servidor, esta métrica se expone para la réplica principal y cualquier réplica con nombre. |
Segundos de núcleo virtual |
| Paquete de aplicaciones | app_cpu_billed_HA_replicas | Solo aplicable a Hyperscale sin servidor. Suma del proceso facturado en todas las aplicaciones para las réplicas de alta disponibilidad durante el período de notificación. Esta suma tiene como ámbito las réplicas de alta disponibilidad que pertenecen a la réplica principal o las réplicas de alta disponibilidad que pertenecen a una réplica con nombre determinada. Antes de calcular esta suma entre réplicas de alta disponibilidad, la cantidad de proceso facturada para una réplica de alta disponibilidad individual se determina de la misma manera que para la réplica principal o una réplica con nombre. Para Hiperescala sin servidor, esta métrica se expone para todas las réplicas principales, con nombre y geográficas. El importe pagado durante el período de notificación es el producto de esta métrica por el precio de la unidad de núcleo virtual. | Segundos de núcleo virtual |
| Paquete de aplicaciones | app_memory_percent | Porcentaje de memoria utilizada por la aplicación respecto a la memoria máxima permitida para la aplicación. Para Hiperescala sin servidor, esta métrica se expone para todas las réplicas principales, con nombre y geográficas. | Porcentaje |
| Pool de recursos de usuario | porcentaje_de_cpu | Porcentaje de vCores utilizado por la carga de trabajo de usuario respecto al máximo de vCores permitido para dicha carga. | Porcentaje |
| Pool de recursos de usuario | data_IO_percent | Porcentaje de IOPS de datos utilizado por la carga de trabajo de usuario respecto al máximo de IOPS de datos permitido para la carga de trabajo de usuario. | Porcentaje |
| Pool de recursos de usuario | log_IO_percent | Porcentaje de MB/s de registro utilizados por la carga de trabajo del usuario en relación con los MB/s de registro máximos permitidos para la carga de trabajo del usuario. | Porcentaje |
| Pool de recursos de usuario | workers_percent | Porcentaje de trabajadores utilizados por la carga de trabajo del usuario en relación con el máximo permitido para dicha carga. | Porcentaje |
| Pool de recursos de usuario | sessions_percent | Porcentaje de sesiones utilizado por la carga de trabajo de usuario respecto al máximo de sesiones permitido para la carga de trabajo de usuario. | Porcentaje |
Estado de pausa y reanudación
En el caso de una base de datos sin servidor con pausa automática habilitada, el estado que notifica incluye los siguientes valores:
| Estado | Descripción |
|---|---|
| En línea | La base de datos está en línea. |
| Pausando | La base de datos pasa de estar en línea a estar en pausa. |
| En pausa | La base de datos está en pausa. |
| Reanudando | La base de datos pasa de estar en pausa a estar en línea. |
Uso del portal de Azure
En el portal de Azure, el estado de la base de datos se muestra en la página de información general de la base de datos y en la página de información general de su servidor. También en el portal de Azure, el historial de eventos de pausa y reanudación de una base de datos sin servidor se puede ver en el registro de Activity.
Uso de PowerShell
Vea el estado de la base de datos actual mediante el siguiente ejemplo de PowerShell:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Uso de CLI de Azure
Vea el estado de la base de datos actual con el siguiente ejemplo de CLI de Azure:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Límites de recursos
Para conocer los límites de recursos, consulte el nivel de proceso sin servidor.
Facturación
La cantidad de proceso que se factura para una base de datos sin servidor es el máximo de CPU y memoria usado en cada segundo. Si la cantidad de CPU y memoria usadas es inferior a la cantidad mínima aprovisionada para cada recurso, se factura la cantidad aprovisionada. Para comparar la CPU con la memoria con fines de facturación, la memoria se normaliza en unidades de vCores redimensionando el número de GB a 3 GB por vCore.
- Recurso facturado: CPU y memoria
- Importe facturado: precio de la unidad de vCore * máximo (mínimo de vCores, vCores usados, memoria GB mínima * 1/3, memoria GB usada * 1/3)
- Frecuencia de facturación: Por segundo
El precio de unidad de núcleo virtual es el costo por núcleo virtual por segundo.
Consulte la página de precios Azure SQL Database para obtener precios unitarios específicos en una región determinada.
La cantidad de procesos facturados sin servidor para una base de datos de propósito general, o una réplica principal o con nombre de Hiperescala se expone mediante la siguiente métrica:
- Métrica: app_cpu_billed (segundos de núcleo virtual)
- Definición: máximo (mínimo de núcleos virtuales, núcleos virtuales usados, GB de memoria mínima * 1/3, GB de memoria usada * 1/3)
- Frecuencia de informes: por minuto, basada en mediciones por segundo agregadas a lo largo de 1 minuto.
La cantidad de proceso facturada si no hay servidor para las réplicas de alta disponibilidad de Hiperescala que pertenecen a la réplica principal o cualquier réplica con nombre se expone mediante la métrica siguiente:
- Métrica: app_cpu_billed_HA_replicas (segundos de núcleo virtual)
- Definición: suma del máximo (núcleos virtuales mínimos, núcleos virtuales utilizados, GB de memoria mínimos * 1/3, GB de memoria utilizados * 1/3) para cualquier réplica de alta disponibilidad que pertenezca a su recurso principal.
- Recurso principal y punto de conexión de la métrica: la réplica principal y cualquier réplica con nombre exponen cada una por separado esta métrica, que mide el proceso facturado para cualquier réplica de alta disponibilidad asociada.
- Frecuencia de informes: por minuto, basada en mediciones por segundo agregadas a lo largo de 1 minuto.
Factura de proceso mínimo
Si una base de datos sin servidor está en pausa, la factura de proceso es cero. Si una base de datos sin servidor no está en pausa, la factura mínima de procesos no es inferior a la cantidad de núcleos virtuales basada en el máximo (núcleos virtuales mínimos, GB de memoria mínimos * 1/3).
Ejemplos:
- Supongamos que una base de datos sin servidor en el nivel De uso general no está en pausa y está configurada con 8 núcleos virtuales como máximo y 1 núcleo virtual como mínimo, lo que corresponde a 3,0 GB de memoria mínima. Entonces la factura mínima de procesos se basa en un máximo de (1 núcleo virtual, 3.0 GB * 1 núcleo virtual / 3 GB) = 1 núcleo virtual.
- Supongamos que una base de datos sin servidor en el nivel De uso general no está en pausa y está configurada con 4 núcleos virtuales como máximo y 0,5 núcleos virtuales como mínimo, lo que corresponde a 2,1 GB de memoria mínima. Entonces la factura mínima de procesos se basa en un máximo de (0.5 núcleos virtuales, 2.1 GB * 1 núcleo virtual / 3 GB) = 0.7 núcleos virtuales.
- Supongamos que una base de datos sin servidor en el nivel Hiperescala tiene una réplica principal con una réplica de alta disponibilidad y una réplica con nombre sin réplicas de alta disponibilidad. Supongamos que cada réplica está configurada con 8 núcleos virtuales como máximo y 1 núcleo virtual como mínimo, lo que corresponde a 3 GB de memoria mínima. Entonces la factura mínima de proceso para la réplica principal, la réplica de alta disponibilidad y la réplica con nombre se basa cada una en un máximo de (1 núcleo virtual, 3 GB * 1 núcleo virtual / 3 GB) = 1 núcleo virtual.
La calculadora de precios Azure SQL Database para sin servidor se puede usar para determinar la memoria mínima configurable en función del número de núcleos virtuales máximos y mínimos configurados. Por norma general, si el número mínimo de núcleos virtuales configurado es superior a 0,5 núcleos virtuales, la factura de proceso mínimo es independiente de la memoria mínima configurada y solo se basa en el número mínimo de núcleos virtuales configurado.
Ejemplos de escenarios
- Uso general
- Hiperescala
Considere la posibilidad de una base de datos sin servidor en el nivel De uso general configurada con 1 núcleo virtual como mínimo y 4 como máximo. Esta configuración equivale aproximadamente a 3 GB de memoria como mínimo y a 12 GB de memoria como máximo. Supongamos que la demora de la pausa automática se establece en 6 horas y la carga de trabajo de la base de datos está activa durante las primeras 2 horas de un período de 24 horas e inactiva el resto del tiempo.
En este caso, la base de datos se factura por cómputo y almacenamiento durante las primeras 8 horas. Aunque la base de datos esté inactiva a partir de la segunda hora, se seguirá facturando por los recursos de cálculo durante las 6 horas siguientes, basándose en el mínimo de computación aprovisionado mientras la base de datos estaba activa. Solo se facturará por el almacenamiento el resto del período de 24 horas mientras la base de datos está en pausa.
Más concretamente, la facturación del proceso en este ejemplo se calcula como sigue:
| Intervalo de tiempo | Núcleos virtuales que se usan cada segundo | GB usados cada segundo | Dimensión del proceso facturado | Segundos facturados de vCore durante un intervalo de tiempo |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | Núcleos virtuales usados | 4 núcleos virtuales * 3600 segundos = 14 400 núcleos virtuales |
| 1:00-2:00 | 1 | 12 | Memoria usada | 12 GB * 1/3 * 3600 segundos = 14 400 núcleos virtuales |
| 2:00-8:00 | 0 | 0 | Memoria mínima aprovisionada | 3 GB * 1/3 * 21 600 segundos = 21 600 núcleos virtuales |
| 8:00-24:00 | 0 | 0 | No se factura ningún proceso mientras la base de datos está en pausa | 0 segundos de núcleo virtual |
| Total de segundos de vCore facturados durante 24 horas | 50 400 segundos de núcleo virtual |
Suponga que el precio de la unidad de cálculo es 0,000145 $/núcleo virtual/segundo. A continuación, el proceso facturado durante este período de 24 horas es el producto del precio unitario de proceso y los segundos de núcleo virtual facturados: $0,000145/núcleo virtual/segundo * 50,400 segundos de núcleo virtual ~ 7,31 USD.
Ventajas de Azure Híbrido y reservas
Ventaja híbrida de Azure (AHB) y descuentos de Reservas de Azure no se aplican a la capa de cálculo sin servidor.
Regiones disponibles
Para obtener disponibilidad regional, consulte disponibilidad Serverless por región para Azure SQL Database.
Contenido relacionado
- Para empezar, consulte Quickstart: Creación de una base de datos única: Azure SQL Database.
- Para conocer las opciones del nivel de servicio sin servidor, consulte De uso general y Hiperescala.