Aceleración de análisis de macrodatos en tiempo real mediante el conector de Spark
Se aplica a: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Nota:
A partir de septiembre de 2020, este conector no se mantiene de forma activa. Sin embargo, el conector de Apache Spark para SQL Server y Azure SQL ya está disponible, con compatibilidad con enlaces de Python y R, una interfaz más fácil de usar para insertar datos de forma masiva y con muchas otras mejoras. Le recomendamos que evalúe y use el nuevo conector en lugar de este. La información sobre el conector anterior (esta página) solo se conservará con fines de archivo.
El conector de Spark permite a las bases de datos de Azure SQL Database, Azure SQL Managed Instance y SQL Server actuar como orígenes de datos de entrada o receptores de datos de salida para los trabajos de Spark. Permite usar datos transaccionales en tiempo real en análisis de macrodatos y conservar los resultados para informes o consultas ad hoc. En comparación con el conector JDBC integrado, este conector proporciona la capacidad para insertar datos de forma masiva en la base de datos. Puede mejorar el rendimiento de la inserción de fila en fila, ya que puede insertar datos entre 10 y 20 veces más rápido. El conector de Spark admite la autenticación con Microsoft Entra ID (anteriormente Azure Active Directory) para conectarse a Azure SQL Database y Azure SQL Managed Instance, lo que le permite conectar la base de datos desde Azure Databricks mediante la cuenta de Microsoft Entra. Proporciona interfaces similares con el conector JDBC integrado. Es fácil migrar los trabajos de Spark existentes para usar este nuevo conector.
Nota:
Microsoft Entra ID era conocido anteriormente como Azure Active Directory (Azure AD).
Descarga y compilación de un conector de Spark
El repositorio de GitHub para el conector antiguo al que se vinculaba anteriormente desde esta página no se mantendrá de forma activa. En su lugar, le recomendamos que evalúe y utilice el nuevo conector.
Versiones oficiales compatibles
| Componente | Versión |
|---|---|
| Spark de Apache | 2.0.2 o posterior |
| Scala | 2.10 o posterior |
| Microsoft JDBC Driver para SQL Server | 6.2 o posterior |
| Microsoft SQL Server | SQL Server 2008 o posterior |
| Azure SQL Database | Compatible |
| Instancia administrada de Azure SQL | Compatible |
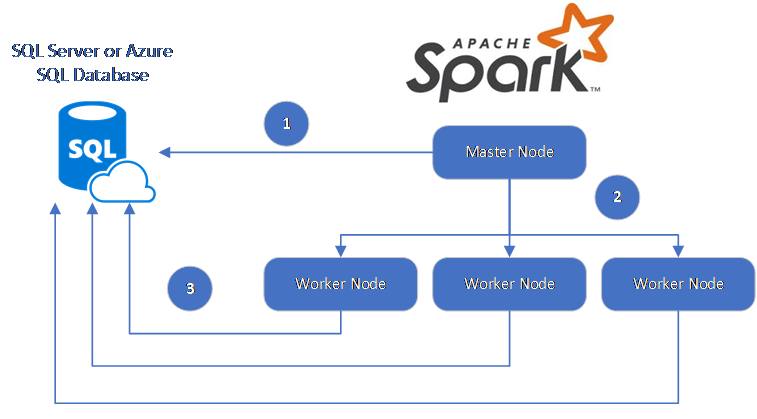
El conector de Spark usa Microsoft JDBC Driver para SQL Server para mover datos entre los nodos de trabajo de Spark y las bases de datos:
El flujo de datos es el siguiente:
- El nodo principal de Spark se conecta a bases de datos de SQL Database o SQL Server y carga los datos desde una tabla específica o mediante una consulta SQL específica.
- El nodo principal de Spark distribuye los datos a los nodos de trabajo para la transformación.
- El nodo de trabajo se conecta a bases de datos que se conectan a SQL Database y SQL Server y escribe los datos en la base de datos. El usuario puede optar por usar la inserción de fila en fila o la inserción de forma masiva.
En el siguiente diagrama se ilustra el flujo de datos.
Compilación del conector de Spark
Actualmente, el proyecto del conector usa Maven. Para crear el conector sin dependencias, puede ejecutar:
- mvn clean package
- Descargar las últimas versiones del archivo JAR desde la carpeta de versión
- Incluir el archivo JAR de Spark de SQL Database
Conexión y lectura de datos mediante el conector de Spark
Puede conectarse a bases de datos de SQL Database y SQL Server desde un trabajo de Spark para leer o escribir datos. También puede ejecutar una consulta DML o DDL en bases de datos de SQL Database y SQL Server.
Lectura de datos desde Azure SQL o SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Lectura de datos desde Azure SQL o SQL Server con la consulta SQL especificada
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Escritura de datos en Azure SQL o SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Ejecución de una consulta DML o DDL en Azure SQL o SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Conexión desde Spark mediante la autenticación de Microsoft Entra
Puede conectarse a SQL Database y SQL Managed Instance con la autenticación de Microsoft Entra. Use la autenticación de Microsoft Entra para administrar identidades de usuarios de base de datos de forma centralizada y como alternativa a la autenticación de SQL.
Conexión con el modo de autenticación ActiveDirectoryPassword
Requisito de instalación
Si usa el modo de autenticación ActiveDirectoryPassword, debe descargar microsoft-authentication-library-for-java y sus dependencias, e incluirlos en la ruta de compilación de Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Conexión mediante un token de acceso
Requisito de instalación
Si usa el modo de autenticación basado en token de acceso, debe descargar microsoft-authentication-library-for-java y sus dependencias, e incluirlos en la ruta de compilación de Java.
Vea Uso de la autenticación de Microsoft Entra para obtener información sobre cómo obtener un token de acceso para la base de datos en Azure SQL Database o Azure SQL Managed Instance.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Escritura de datos mediante inserción masiva
El conector JDBC tradicional escribe datos en la base de datos mediante la inserción de fila en fila. Puede usar el conector de Spark para escribir datos en Azure SQL y SQL Server mediante la inserción masiva. Mejora considerablemente el rendimiento de escritura al cargar grandes conjuntos de datos o cargar datos en tablas donde se usa un índice de almacenamiento de columnas.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Pasos siguientes
Si aún no lo ha hecho, descargue el conector de Spark del repositorio azure-sqldb-spark en GitHub y explore los recursos adicionales del repositorio:
Es posible que también quiera consultar Apache Spark SQL, DataFrames, and Datasets Guide (Guía de Apache Spark SQL, DataFrames y conjuntos de datos) y ladocumentación de Azure Databricks.