Introducción a la continuidad del negocio con Azure SQL Managed Instance
Se aplica a:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
En este artículo se proporciona información general sobre las funcionalidades de continuidad empresarial y recuperación ante desastres de Azure SQL Managed Instance, que describen las opciones y recomendaciones para recuperarse de eventos perjudiciales que podrían provocar la pérdida de datos o hacer que la instancia y la aplicación no estén disponibles. Aprende qué hacer en caso de que un error del usuario o la aplicación afecte a la integridad de los datos, se produzca una interrupción en una zona de disponibilidad o región de Azure o tu aplicación requiera mantenimiento.
Información general
La continuidad empresarial en Azure SQL Managed Instance hace referencia a los mecanismos, directivas y procedimientos que permiten a tu empresa seguir funcionando frente a la interrupción al proporcionar alta disponibilidad y recuperación ante desastres.
En la mayoría de los casos, SQL Managed Instance controla los eventos de interrupción que puedan ocurrir en un entorno en la nube y permite que se sigan ejecutando las aplicaciones y los procesos empresariales. Sin embargo, hay algunos eventos disruptivos en los que la mitigación puede tardar algún tiempo, como los siguientes:
- El usuario elimina o actualiza accidentalmente una fila de una tabla.
- Un atacante malintencionado consigue eliminar datos o quitar una base de datos.
- El evento de desastre natural catastrófico quita un centro de datos o una zona de disponibilidad o región.
- Un centro de datos poco frecuente, una zona de disponibilidad o una interrupción en toda la región causado por un cambio de configuración, un error de software o un error de componente de hardware.
Disponibilidad
Azure SQL Managed Instance incluye una promesa básica de resistencia y confiabilidad que lo protege frente a errores de software o hardware. Las copias de seguridad de bases de datos proporcionan una manera de proteger los datos de daños o eliminaciones accidentales. Al ser una plataforma como servicio (PaaS), el servicio Azure SQL Managed Instance proporciona disponibilidad como una característica fuera de la plataforma con un Acuerdo de Nivel de Servicio de disponibilidad líder del sector del 99,99 %.
Alta disponibilidad
Para lograr una alta disponibilidad en el entorno en la nube de Azure, habilita la redundancia de zona para que la instancia use zonas de disponibilidad para garantizar la resistencia a errores de zona. Muchas regiones de Azure proporcionan zonas de disponibilidad, que están separadas por grupos de centros de datos dentro de una región que tienen una infraestructura de red, refrigeración y alimentación independientes. Las zonas de disponibilidad están diseñadas para proporcionar servicios regionales, capacidad y alta disponibilidad en las zonas restantes si una zona experimenta una interrupción. Al habilitar la redundancia de zona, la instancia es resistente a errores de hardware y software zonales y la recuperación es transparente para las aplicaciones. Cuando la alta disponibilidad está habilitada, el servicio Azure SQL Managed Instance puede proporcionar un SLA de mayor disponibilidad del 99,995 %.
Recuperación ante desastres
Para lograr una mayor disponibilidad y redundancia entre regiones, puedes habilitar las funcionalidades de recuperación ante desastres para recuperar rápidamente la instancia de un error regional catastrófico. Las opciones de recuperación ante desastresde Azure SQL Managed Instance son las siguientes:
- Los grupos de conmutación por error permiten la sincronización continua entre una instancia principal y secundaria. Los grupos de conmutación por error proporcionan puntos de conexión de agente de escucha de solo lectura y de solo lectura que permanecen sin cambios, por lo que la actualización de cadenas de conexión de aplicaciones después de la conmutación por error no es necesaria.
- La restauración geográfica permite recuperarse de una interrupción regional mediante la restauración a partir de copias de seguridad con replicación geográfica, cuando no puedes acceder a la base de datos en la región primaria mediante la creación de una nueva base de datos en cualquier instancia existente de cualquier región de Azure.
Características que proporcionan continuidad empresarial
En el caso de una instancia, hay cuatro escenarios principales de posibles interrupciones. En la tabla siguiente se enumeran las características de continuidad empresarial de SQL Managed Instance que puede usar para mitigar un posible escenario de interrupción empresarial:
| Escenario de interrupción empresarial | Característica de continuidad del negocio |
|---|---|
| Errores de hardware o software locales que afectan al nodo de la base de datos. | Para mitigar los errores de hardware local y de software, SQL Managed Instance incluye una arquitectura de disponibilidad que garantiza una recuperación automática de estos errores con un Acuerdo de Nivel de Servicio de disponibilidad del 99,99 %. |
| Daños o eliminación de datos que suelen deberse a un error de la aplicación o a un error humano. Estos errores son específicos de la aplicación y el servicio no suele detectarlos. | Para proteger tu empresa de la pérdida de datos, SQL Managed Instance realiza automáticamente copias de seguridad completas semanales de la base de datos, copias de seguridad diferenciales de la base de datos cada 12 o 24 horas y copias de seguridad del registro de transacciones cada 5-10 minutos. De forma predeterminada, las copias de seguridad se almacenan en el almacenamiento con redundancia geográfica durante siete días para ambos niveles de servicio, con un período de retención de copia de seguridad configurable para la restauración a un momento dado de hasta 35 días. Puedes restaurar una base de datos eliminada al momento en que fue eliminada si la instancia no se ha eliminado o si has configurado la retención a largo plazo. |
| Interrupción poco común del centro de datos o la zona de disponibilidad, posiblemente causada por un evento de desastre natural, cambios en la configuración, errores de software o errores de componentes de hardware. | Para mitigar la interrupción del nivel de zona de disponibilidad o del centro de datos, habilita la redundancia de zona para que SQL Managed Instance use Azure Availability Zones y proporcione redundancia en varias zonas físicas dentro de una región de Azure. La habilitación de la redundancia de zona garantiza que la instancia administrada sea resistente a errores zonales con un acuerdo de nivel de servicio de alta disponibilidad hasta el 99,995 %. |
| Interrupción regional poco frecuente que afecta a todas las zonas de disponibilidad y los centros de datos que la componen, posiblemente causados por un desastre natural catastrófico. | Para mitigar una interrupción en toda la región, habilita la recuperación ante desastres mediante una de las siguientes opciones: - Sincronización continua de datos con grupos de conmutación por error a réplicas en una región secundaria que se usan para la conmutación por error. - Establece la opción de redundancia de almacenamiento de copia de seguridad en Almacenamiento de copia de seguridad con redundancia geográfica para usar la restauración geográfica. |
RTO y RPO
A medida que desarrolles el plan de continuidad empresarial, tendrás que saber el tiempo máximo aceptable para que la aplicación se recupere por completo tras un evento de interrupción. El tiempo necesario para que una aplicación se recupere totalmente se conoce como objetivo de tiempo de recuperación (RTO, por sus siglas en inglés). También debes conocer el período máximo de actualizaciones de datos recientes (intervalo de tiempo) que la aplicación puede tolerar perder al recuperarse de un evento de interrupción no planeado. La posible pérdida de datos se conoce como objetivo de punto de recuperación (RPO).
En la tabla siguiente se comparan el RPO y el RTO de cada opción de continuidad empresarial:
| Opciones de continuidad empresarial | RTO (sin tiempo de inactividad) | RPO (sin pérdida de datos) |
|---|---|---|
| Alta disponibilidad (habilitación de la redundancia de zona) |
Normalmente, menos de 30 segundos | 0 |
| Recuperación ante desastres (habilitación de grupos de conmutación por error) |
1 hora | 5 segundos (depende de los cambios de datos antes del evento disruptivo que no se ha replicado) |
| Recuperación ante desastres (mediante la restauración geográfica) |
12 horas | 1 hora |
Recuperación de una base de datos en la misma región de Azure
Puede usar copias de seguridad de la base de datos automáticas para restaurar una base de datos a un momento anterior. De este modo puede recuperarse de los daños en los datos causados por errores humanos. La restauración a un momento dado (PITR) te permite crear una base de datos en la misma instancia, o en otra diferente, que represente el estado de los datos antes del evento de daño. La operación de restauración tiene un tamaño de operación de datos que también depende de la carga de trabajo actual de la instancia de destino. La recuperación de una base de datos muy grande o muy activa puede tardar más tiempo. Para más información sobre el tiempo de recuperación, consulte el apartado sobre el tiempo de recuperación de bases de datos.
Si el período de retención de la restauración a un momento dado (PITR) máximo admitido no es suficiente para su aplicación, puede ampliarlo mediante la configuración de una directiva de retención a largo plazo (LTR) para las bases de datos. Para obtener más información, vea Retención de copias de seguridad a largo plazo.
Recuperación de una base de datos en una instancia existente
Aunque sea poco habitual, en un centro de datos de Azure se pueden producir interrupciones. Cuando esto ocurre, provoca también una interrupción en el negocio que podría extenderse solo unos pocos minutos o, incluso, horas.
- Una opción consiste en esperar a que la instancia vuelva a estar en línea cuando termine la interrupción del centro de datos. Esto puede hacerse con las aplicaciones que pueden permitirse que la base de datos esté desconectada. Por ejemplo, los proyectos de desarrollo o las pruebas gratuitas no tienen que estar en funcionamiento constantemente. Cuando se produce una interrupción en un centro de datos, no se sabe cuánto durará, por lo que esta opción solo es útil si no es necesario usar la base de datos durante un tiempo.
- Si usa almacenamiento con redundancia geográfica (GRS) o con redundancia de zona geográfica (GZRS), otra opción es restaurar una base de datos a cualquier instancia administrada de SQL de cualquier región de Azure mediante copias de seguridad de base de datos con redundancia geográfica (restauración geográfica). La funcionalidad de restauración geográfica utiliza una copia de seguridad con redundancia geográfica como origen y se puede usar para recuperar una base de datos al último momento disponible, aunque no se pueda acceder a dicha base de datos o al centro de datos debido a una interrupción. La copia de seguridad disponible se puede encontrar en la región emparejada.
- Por último, puedes recuperarte rápidamente de una interrupción si has configurado una base de datos secundaria geográfica mediante un grupo de conmutación por error para tu instancia, mediante la conmutación por error administrada por Microsoft. Aunque la conmutación por error tarda solo unos segundos, el servicio tarda al menos 1 hora en activar una conmutación por error geográfica administrada por Microsoft, si está configurada. Esto es necesario para asegurarse de que la conmutación por error está justificada por la escala de la interrupción. Además, la conmutación por error puede provocar la pérdida de datos modificados recientemente debido a la naturaleza de la replicación asincrónica entre las regiones emparejadas.
A medida que desarrolle el plan de continuidad empresarial, tendrá que saber el tiempo máximo aceptable para que la aplicación se recupere por completo tras un evento de interrupción. El tiempo necesario para que la aplicación se recupere totalmente se conoce como objetivo de tiempo de recuperación (RTO). También debe conocer el período máximo de actualizaciones de datos recientes (intervalo de tiempo) que la aplicación puede tolerar perder al recuperarse de un evento de interrupción no planeado. La posible pérdida de datos se conoce como objetivo de punto de recuperación (RPO).
Los diferentes métodos de recuperación ofrecen distintos niveles de RPO y RTO. Puede elegir un método de recuperación específico o usar una combinación de métodos para lograr la total recuperación de la aplicación.
Usa grupos de conmutación por error si tu aplicación cumple alguno de estos criterios:
- Es crítica.
- Tiene un SLA que no permite que se produzcan tiempos de inactividad de más de 12 horas.
- Es posible que el tiempo de inactividad incurra en responsabilidades financieras.
- Tiene una tasa de cambio de datos elevada y una hora de pérdida de datos no es aceptable.
- El costo adicional por utilizar la replicación geográfica activa es menor que el de la posible responsabilidad financiera y la pérdida de negocio asociada que habría que asumir.
Es posible que decidas usar una combinación de copias de seguridad de base de datos y grupos de conmutación por error según los requisitos de la aplicación.
En las siguientes secciones se ofrece información general de los pasos para realizar tareas de recuperación mediante copias de seguridad de bases de datos o grupos de conmutación por error.
Preparativos para interrupciones
Con independencia de la característica de continuidad empresarial que use, debe hacer lo siguiente:
- Identificar y preparar la instancia de destino, incluidas las reglas de firewall de IP de red, los inicios de sesión y los permisos de nivel de base de datos
master. - Determinar cómo se redirigirán los clientes y las aplicaciones cliente a la nueva instancia.
- Documentar otras dependencias, como las alertas y la configuración de auditoría
Si no se prepara correctamente, el proceso de conectar las aplicaciones después de una conmutación por error o una recuperación de base de datos llevará más tiempo y, probablemente, también haya que solucionar problemas en momentos de estrés, por lo que no es nada recomendable.
Conmutación por error de la instancia secundaria de replicación geográfica
Si usas grupos de conmutación por error como mecanismo de recuperación, puedes configurar una directiva de conmutación por error. Tras iniciar la conmutación por error, la instancia secundaria pasa a ser la principal y está lista para registrar nuevas transacciones y responder a consultas, con una pérdida mínima de los datos que aún no se han replicado.
Nota:
Cuando el centro de datos vuelve a estar en línea, las instancias principales anteriores se vuelven a conectar automáticamente con la nueva instancia principal y se convierten en instancias secundarias. Si necesita reubicar la base de datos principal de nuevo en la región original, puede iniciar una conmutación por error manual planificada (conmutación por recuperación).
Realización de restauraciones geográficas
Si usa copias de seguridad automatizadas con almacenamiento con redundancia geográfica (la opción de almacenamiento predeterminada al crear la instancia), puede recuperar la base de datos mediante la restauración geográfica. El proceso de recuperación empieza en un plazo de 12 horas como máximo y la pérdida de datos supone como mucho una hora, lo cual viene determinado por la última copia de seguridad y réplica de registros. Hasta que no se complete la recuperación, la base de datos no puede registrar transacciones ni responder a las consultas. Tenga en cuenta que con la restauración geográfica solo se restaura la base de datos al último momento disponible.
Nota:
Si el centro de datos vuelve a estar en línea antes de cambiar la aplicación a la base de datos recuperada, puede cancelar el proceso de recuperación.
Realización de tareas posteriores a la recuperación y conmutación por error
Cuando efectúe la recuperación con cualquiera de los mecanismos para llevarla a cabo, debe realizar las siguientes tareas adicionales antes de que los usuarios y las aplicaciones vuelvan a conectarse:
- Redirija los clientes y las aplicaciones cliente a la nueva instancia y a la base de datos restaurada.
- Asegúrese de aplicar reglas de firewall de red adecuadas para que se conecten los usuarios.
- Asegúrese de emplear los permisos de nivel de base de datos
mastere inicios de sesión apropiados (o bien, utilice usuarios contenidos). - Configure la auditoría según corresponda.
- Configure las alertas según corresponda.
Nota:
Si vas a usar un grupo de conmutación por error y te conectas a la instancia mediante el cliente de escucha de lectura y escritura, el redireccionamiento después de la conmutación por error se realizará de forma automática y transparente a la aplicación.
Réplicas de recuperación ante desastres sin licencia
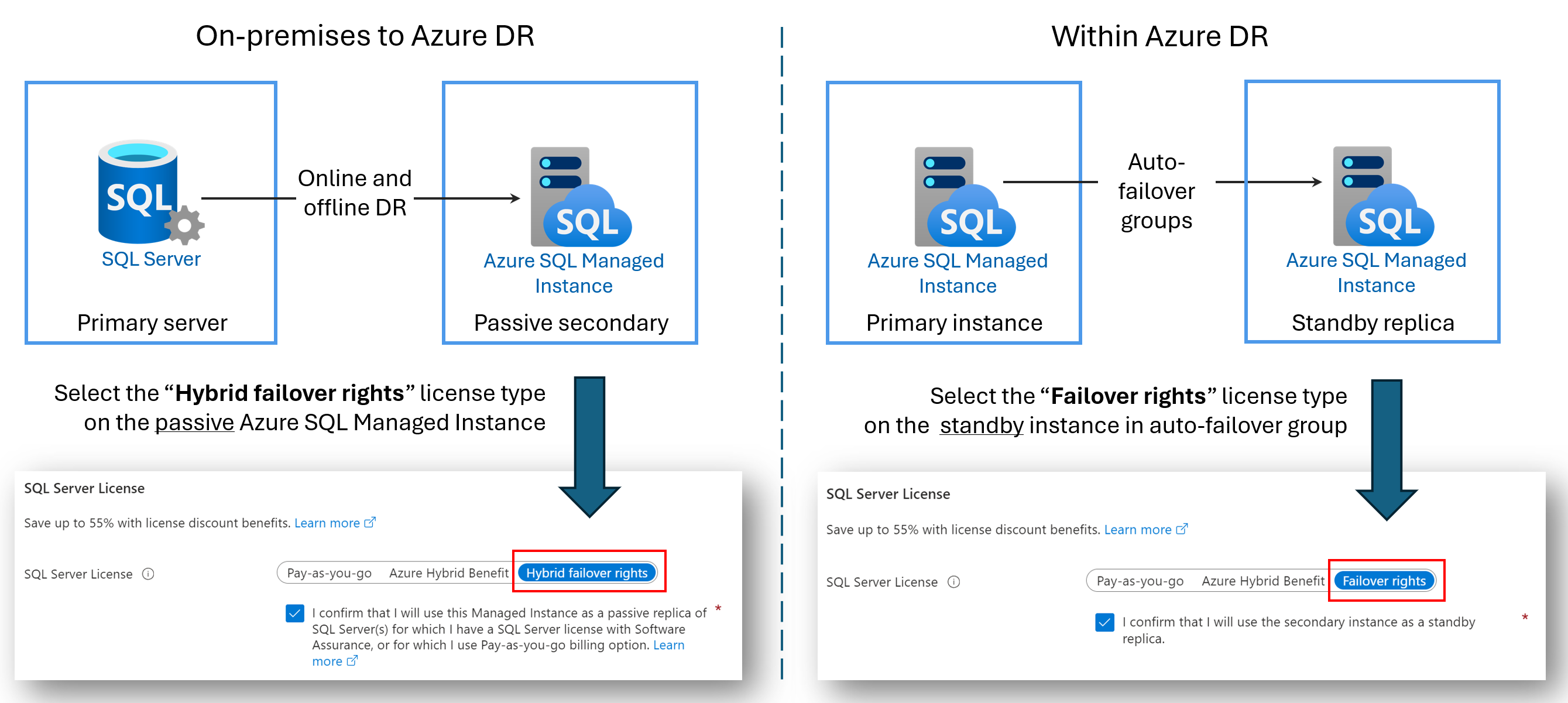
Puede ahorrar en los costos de licencia mediante la configuración de una instancia secundaria de Azure SQL Managed Instance solo para la recuperación ante desastres (DR). Esta ventaja está disponible si usas un grupo de conmutación por error entre dos instancias administradas de SQL, o bien si has configurado un vínculo híbrido entre SQL Server y Azure SQL Managed Instance. Siempre que la instancia secundaria no tenga ninguna carga de trabajo de lectura o escritura en ella y solo sea una espera pasiva de recuperación ante desastres, no se le cobrarán los costos de licencia de núcleo virtual utilizados por la instancia secundaria.
Cuando una instancia secundaria se designa solo para la recuperación ante desastres y no hay cargas de trabajo de lectura ni escritura en ejecución en ella, Microsoft le proporciona la cantidad de núcleos virtuales con licencia para la instancia principal sin cargo adicional en virtud de la ventaja de derechos de migración tras error. Se le seguirá facturando por el proceso y el almacenamiento que usa la instancia secundaria. Para conocer los términos y condiciones precisos de la ventaja de los derechos de migración tras error híbrida, consulte los términos de licencia de SQL Server en línea en la sección "SQL Server: Derechos de migración tras error".
El nombre de la ventaja depende del escenario:
- Derechos de conmutación por error híbrida para una réplica pasiva: al configurar un vínculo entre SQL Server y Azure SQL Managed Instance, puede usar la ventaja de derechos de conmutación por error híbrida para ahorrar en los costos de licencias de núcleo virtual para la réplica secundaria pasiva.
- Derechos de conmutación por error para una réplica en espera: al configurar un grupo de conmutación por error entre dos instancias administradas, puedes usar la ventaja derechos de conmutación por error para ahorrar en los costes de licencias de núcleo virtual para la réplica secundaria en espera.
En el diagrama siguiente se muestra la ventaja de cada escenario:
Pasos siguientes
Para más información sobre las características de continuidad empresarial, consulta Copias de seguridad automatizadas y grupos de conmutación por error. En caso de desastre, consulte Recuperación de una base de datos.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de