Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, descubrirás cómo diseñar un clúster extendido de vSAN para una nube privada de Azure VMware Solution.
Antecedentes
La infraestructura global de Azure se divide en regiones. Cada región soporta los servicios de una geografía determinada. Dentro de cada región, Azure compila islas aisladas y redundantes de infraestructura denominadas zonas de disponibilidad (AZ). Una AZ actúa como límite para la administración de recursos. La computación y otros recursos disponibles en una AZ son finitos y las demandas de los clientes los pueden agotar. Se crea una AZ para ser resistente de forma independiente, lo que significa que los errores de una AZ no afectan a otras AZ.
Con Azure VMware Solution, los hosts ESXi implementados en un clúster de vSphere estándar residen tradicionalmente en una sola zona de disponibilidad de Azure (AZ) y están protegidos por alta disponibilidad (HA) de vSphere. Sin embargo, no protege las cargas de trabajo frente a un error de Azure AZ. Para protegerse frente a un error de AZ, se puede habilitar un único clúster de vSAN para abarcar dos zonas de disponibilidad independientes, denominada clúster extendido de vSAN.
Los clústeres extendidos permiten configurar dominios de error de vSAN entre dos AZ para notificar a vCenter Server que los hosts residen en cada zona de disponibilidad (AZ). Cada dominio de error recibe el nombre de la AZ en la que reside para aumentar la claridad. Cuando se extiende un clúster de vSAN en dos AZ dentro de una región, si una instancia de AZ se cae, se trata como un evento de alta disponibilidad de vSphere y la máquina virtual se reinicia en la otra AZ.
Ventajas de los clústeres extendidos:
- Mejoran la disponibilidad de las aplicaciones.
- Proporcionan una capacidad de objetivo de punto de recuperación (RPO) cero para las aplicaciones empresariales sin necesidad de rediseñarlas ni de implementar soluciones costosas de recuperación ante desastres (DR).
- Una nube privada con clústeres extendidos está diseñada para proporcionar disponibilidad del 99,99 % debido a su resistencia a errores de AZ.
- Permiten que los clientes se centren en los requisitos y características principales de la aplicación, en lugar de en la disponibilidad de la infraestructura.
Para protegerse frente a escenarios de cerebro dividido y ayudar a medir el estado del sitio web, se crea un testigo vSAN administrado en una tercera AZ. Con una copia de los datos en cada Zona de Disponibilidad (AZ), vSphere HA intenta recuperarse de cualquier fallo a través de un reinicio simple de la máquina virtual.
En el diagrama siguiente se muestra un clúster de vSAN extendido entre dos AZ.

En el siguiente diagrama se muestra el flujo normal del tráfico de red que hay en un clúster de vSAN que se encuentra entre dos zonas de disponibilidad.

En resumen, los clústeres extendidos simplifican las necesidades de protección al proporcionar los mismos controles y capacidades de confianza, además de la escala y flexibilidad de la infraestructura de Azure.
Es importante comprender que las nubes privadas de clúster extendido solo ofrecen una capa adicional de resistencia y no abordan todos los escenarios de error. Por ejemplo, nubes privadas de clúster extendido:
- No brindan protección contra fallos a nivel regional ni contra escenarios que resultan en la pérdida de datos causados por problemas de aplicación o directivas de almacenamiento mal planificadas.
- Proporcionan protección frente a un único error de zona, pero no están diseñados para proporcionar protección contra errores dobles o progresivos. Por ejemplo:
A pesar de las diversas capas de redundancia integradas en el tejido, si un error entre distintas AZ da lugar a la creación de particiones del sitio secundario, la alta disponibilidad de vSphere comienza a apagar las máquinas virtuales de carga de trabajo en el sitio secundario.
En el diagrama siguiente se muestra el escenario de particionamiento del sitio secundario.
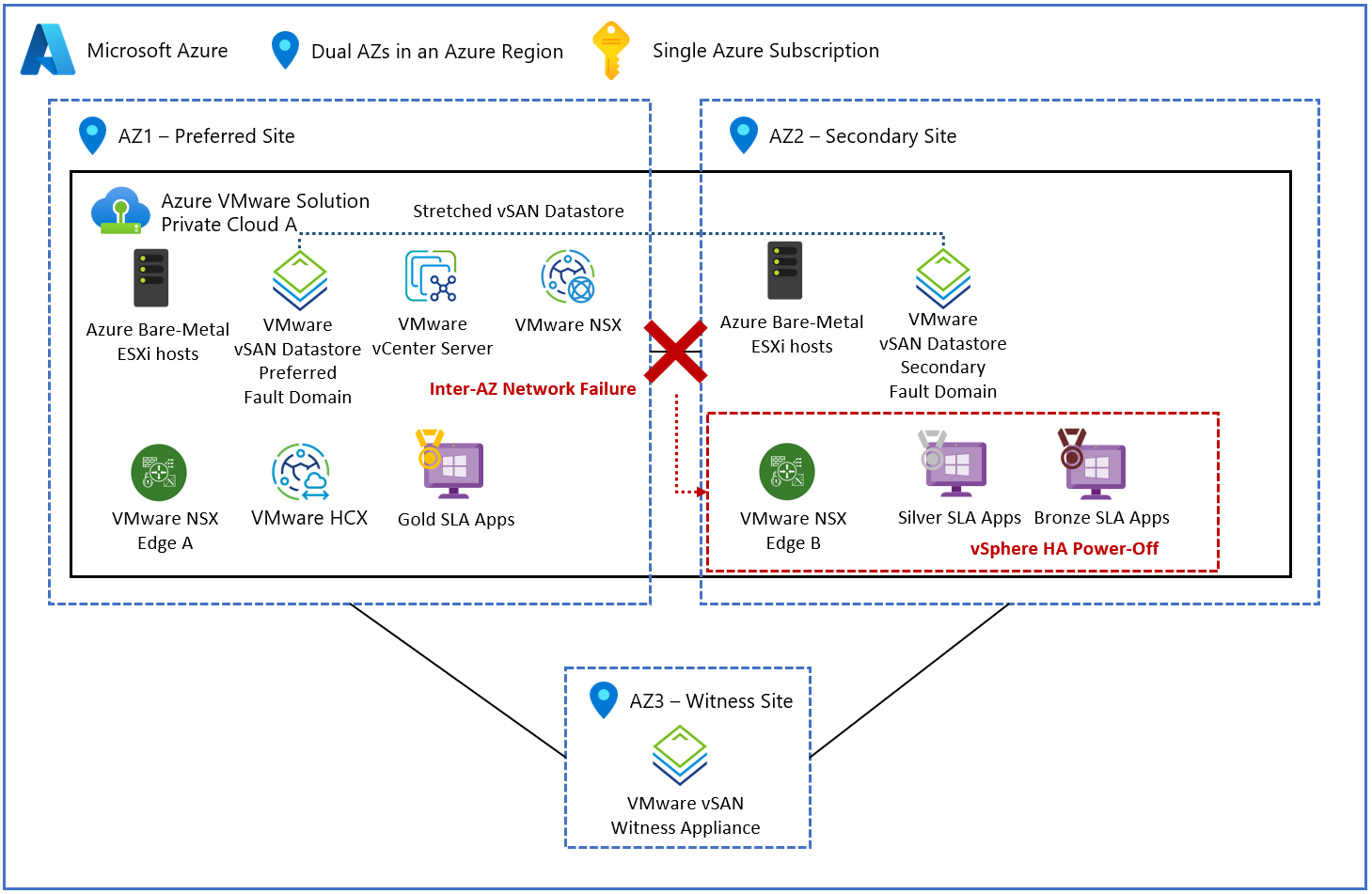
Si la creación de particiones del sitio secundario resultara en la falla del sitio primario o diera lugar a una partición completa, vSphere HA intentaría reiniciar las máquinas virtuales de carga de trabajo en el sitio secundario. Si la alta disponibilidad de vSphere intentara reiniciar las máquinas virtuales de carga de trabajo en el sitio secundario, colocaría las máquinas virtuales de carga de trabajo en un estado inestable.
En el diagrama siguiente se muestra el error de sitio preferido y escenarios de creación de particiones de red completas.
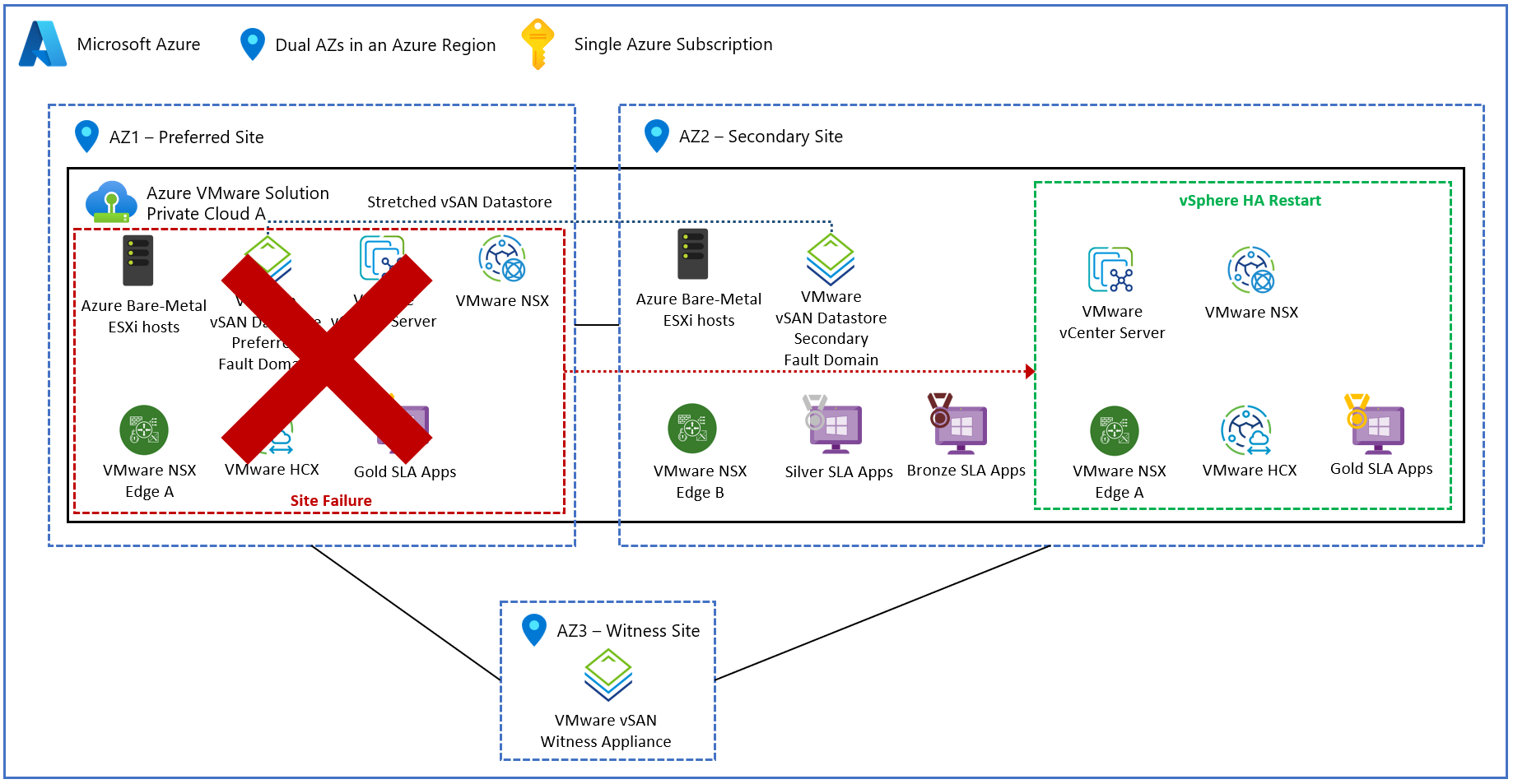
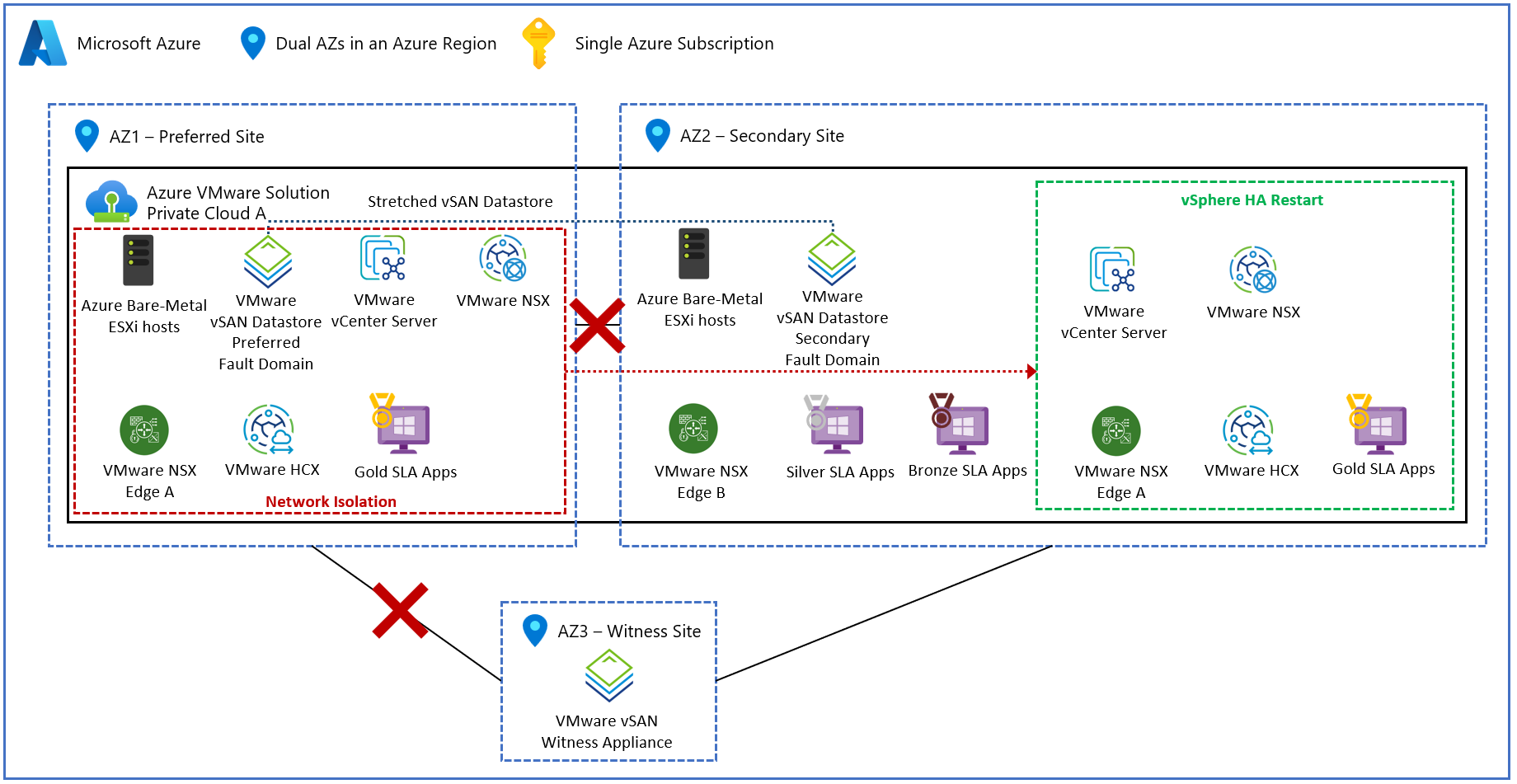
En el siguiente diagrama se muestra el flujo del tráfico de red dentro de un clúster de vSAN extendido durante un fallo total del sitio.
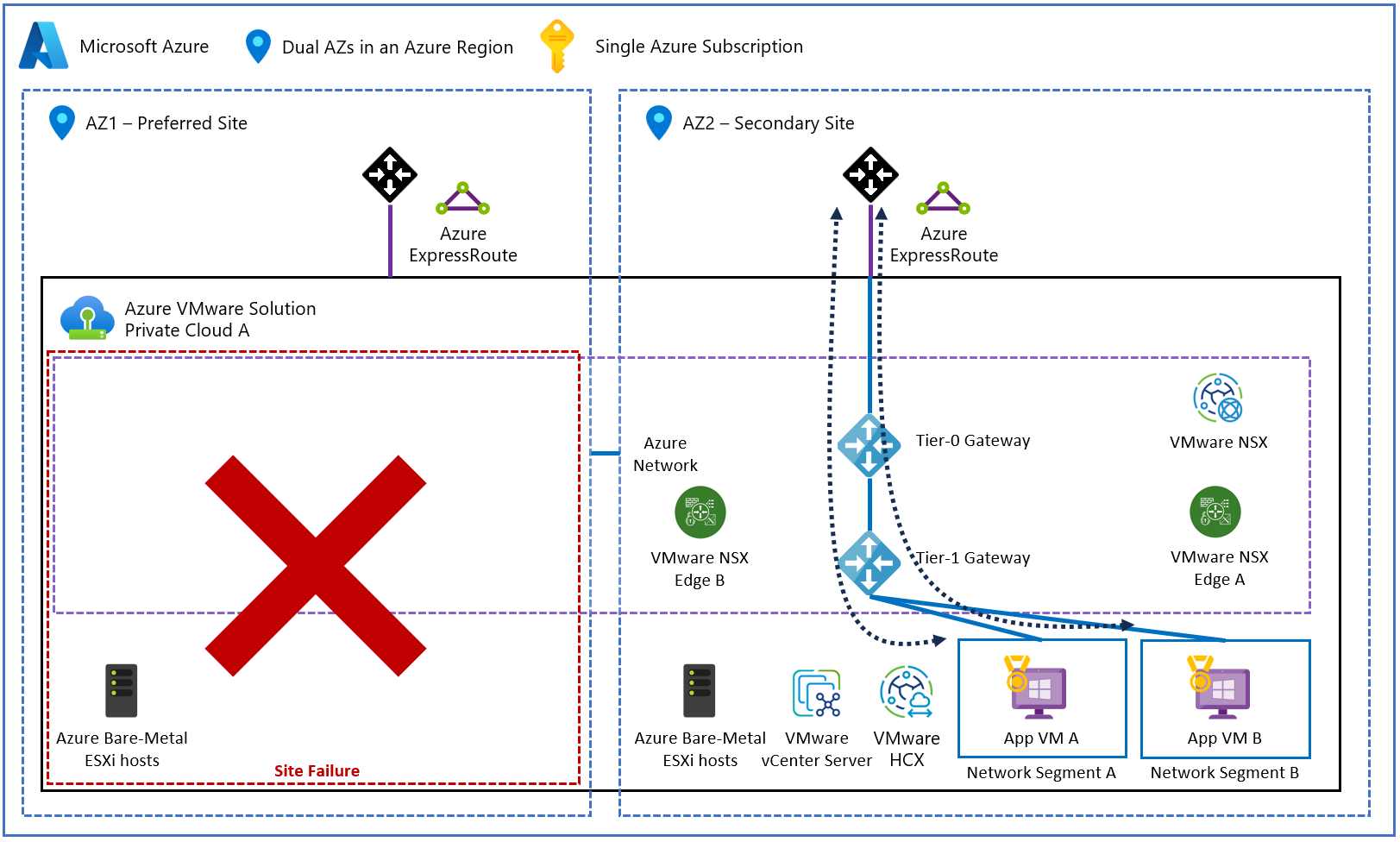




Debe tenerse en cuenta que estos tipos de errores, aunque poco frecuentes, se encuentran fuera del ámbito de la protección que ofrece una nube privada de clústeres extendidos. Debido a esos tipos de errores poco frecuentes, una solución de clúster extendido debe entenderse como una solución de alta disponibilidad multizona que se basa en vSphere HA. Es importante que comprenda que una solución de clústeres extendidos no está pensada para reemplazar una estrategia completa de recuperación ante desastres de varias regiones que se puede emplear para garantizar la disponibilidad de las aplicaciones. El motivo es que una solución de recuperación ante desastres normalmente tiene planos de administración y control independientes en regiones de Azure independientes. Los clústeres extendidos de Azure VMware Solution tienen un único plano de administración y control extendido en dos zonas de disponibilidad dentro de la misma región de Azure. Por ejemplo, un servidor vCenter Server, un clúster de NSX-T Manager, un par de máquinas virtuales NSX Edge.
Disponibilidad de regiones de clústeres extendidos
Los clústeres extendidos de Azure VMware Solution están disponibles en las siguientes regiones:
- Sur de Reino Unido (en AV36 y AV36P)
- Oeste de Europa (en AV36 y AV36P)
- Centro-oeste de Alemania (en AV36 y AV36P)
- Este de Australia (en AV36P)
- Este de EE. UU. (en AV36P)
Directivas de almacenamiento admitidas
Se admiten las siguientes directivas de SPBM, con un PFTT de "Creación de reflejo de sitio dual" y SFTT de "RAID 1 (creación de reflejo)" habilitadas como directivas predeterminadas para el clúster:
- Configuración de tolerancia a desastres del sitio (PFTT)
- Creación de reflejo de sitio dual
- Ninguno: mantener los datos en los preferidos
- Ninguno: mantener los datos en los no preferidos
- Errores locales para tolerar (SFTT):
- 1 error: RAID 1 (creación de reflejo)
- 1 error: RAID 5 (codificación de borrado), requiere un mínimo de 4 hosts en cada AZ
- 2 errores: RAID 1 (creación de reflejo)
- 2 errores: RAID 6 (codificación de borrado), requiere un mínimo de 6 hosts en cada AZ
- 3 errores: RAID 1 (creación de reflejo)
Preguntas más frecuentes
¿Hay otras regiones planeadas?
Actualmente, hay cinco regiones admitidas para clústeres extendidos.
¿Qué tipo de Acuerdo de Nivel de Servicio proporciona Azure VMware Solution con los clústeres extendidos?
Una nube privada creada con un clúster extendido de vSAN está diseñada para ofrecer un compromiso de disponibilidad de infraestructura del 99,99 % cuando existen las siguientes condiciones:
- Se implementan un mínimo de 6 nodos en el clúster (3 en cada zona de disponibilidad).
- Cuando una directiva de almacenamiento de máquina virtual de PFTT de "creación de reflejo de sitio dual" y una SFTT de 1 se usa en las máquinas virtuales de carga de trabajo.
- Se requiere el cumplimiento de los requisitos adicionales capturados en los detalles del Acuerdo de Nivel de Servicio de Azure VMware Solution para lograr los objetivos de disponibilidad.
¿Puedo elegir la zona de disponibilidad en la que se implementa una nube privada?
No. Se crea un clúster extendido entre dos zonas de disponibilidad, mientras que la tercera zona se usa para implementar el nodo testigo. Dado que todas las zonas se usan eficazmente para implementar un entorno de clúster extendido, no se proporciona una opción al cliente. En su lugar, el cliente decide implementar hosts en varias AZ en el momento de la creación de la nube privada.
¿Cuáles son las limitaciones que debo tener en cuenta?
- Una vez creada una nube privada con un clúster extendido, no se puede cambiar a una nube privada de clúster estándar. De forma similar, una nube privada de clústeres estándar no se puede cambiar a una nube privada de clústeres extendidos después de la creación.
- La ampliación y reducción de clústeres extendidos solo pueden realizarse en pares. Se admiten un mínimo de 6 nodos y un máximo de 16 en un entorno de clústeres extendidos. Para más información, consulte Límites, cuotas y restricciones de suscripción y servicios de Microsoft Azure.
- Las máquinas virtuales de carga de trabajo del cliente se reinician con una prioridad media de alta disponibilidad de vSphere. Las máquinas virtuales de administración tienen la prioridad de reinicio más alta.
- La solución se basa en vSphere HA y vSAN para reinicios y replicación. El objetivo de tiempo de recuperación (RTO) viene determinado por la cantidad de tiempo que tarda vSphere HA en reiniciar una máquina virtual en la región de disponibilidad superviviente tras el fallo de una sola región de disponibilidad.
- Actualmente no es compatible en un entorno de clúster extendido.
- Características publicadas recientemente, como IP pública hasta NSX Edge y almacenamiento externo, como almacenes de datos ANF.
- Complementos de recuperación ante desastres como VMware SRM, Zerto y JetStream.
- Abre una incidencia de soporte técnico en Azure Portal para los siguientes escenarios (asegúrate de seleccionar Clústeres extendidos como Tipo de problema):
- Conexión de una nube privada a una nube privada de clústeres extendidos.
- Conexión de dos nubes privadas de clústeres extendidos a una sola región.
¿Qué tipo de latencias debo esperar entre las zonas de disponibilidad (AZ)?
Los clústeres extendidos de vSAN funcionan dentro de un tiempo de recorrido de ida y vuelta de 5 milisegundos (RTT) y de un ancho de banda de 10 Gb/s o más entre las AZ que hospedan las máquinas virtuales de carga de trabajo. La implementación de clústeres extendidos de Azure VMware Solution sigue ese principio rector. Tenga en cuenta esa información al implementar aplicaciones (con SFTT de creación de reflejo de sitio dual, que usa escrituras sincrónicas) que tienen requisitos estrictos de latencia.
¿Puedo mezclar clústeres extendidos y estándar en mi nube privada?
No. No se admite una combinación de clústeres extendidos y estándar en la misma nube privada. Se selecciona un entorno de clúster extendido o estándar al crear la nube privada. Una vez que se ha creado una nube privada con un clúster extendido, se supone que todos los clústeres creados en esa nube privada son de naturaleza extendida.
¿Cuánto cuesta la solución?
A los clientes se les cobra en función del número de nodos implementados en la nube privada.
¿Se me cobra por el nodo testigo y por el tráfico entre AZ?
No. A los clientes no se les cobra por el nodo testigo y el tráfico entre AZ. El nodo testigo se administra por completo y Azure VMware Solution proporciona la administración del ciclo de vida necesario del nodo testigo. A medida que toda la solución está administrada por el servicio, el cliente solo debe identificar la directiva SPBM adecuada que se va a establecer para las máquinas virtuales de carga de trabajo. Microsoft administra el resto.