Puntuación de confianza de una respuesta
Cuando una consulta de usuario se compara con una base de conocimientos (KB), QnA Maker devuelve respuestas pertinentes, junto con una puntuación de confianza. Esta puntuación indica el grado de confianza que se tiene en que la respuesta sea la coincidencia correcta para la consulta de usuario en cuestión.
La puntuación de confianza es un número entre 0 y 100. Una puntuación de 100 es probablemente una coincidencia exacta, mientras que una puntuación de 0 significa que no se ha encontrado ninguna respuesta coincidente. Cuanto mayor sea la puntuación, mayor será la confianza en la respuesta. Para una consulta determinada, podrían devolverse varias respuestas. En ese caso, las respuestas se devuelven en orden de mayor a menor puntuación de confianza.
En el ejemplo siguiente, puede ver una entidad QnA con dos preguntas.

En el ejemplo anterior, se pueden esperar puntuaciones como el intervalo de puntuación que se muestra a continuación para los distintos tipos de consultas de usuario:
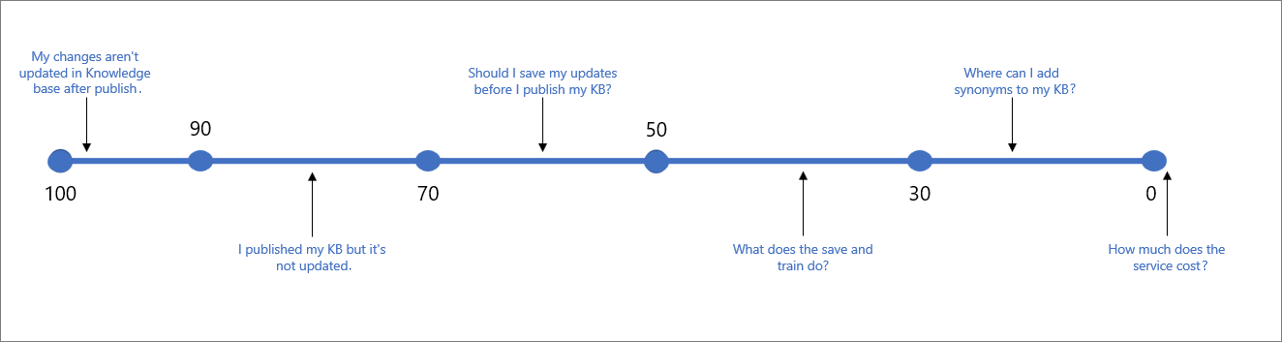
En la tabla siguiente se indica la confianza típico asociada a un resultado determinado.
| Valor de la puntuación | Significado de la puntuación | Consulta de ejemplo |
|---|---|---|
| 90-100 | Coincidencia casi exacta de la consulta del usuario y una pregunta de KB. | "Mis cambios no se actualizan en KB después de la publicación". |
| > 70 | Confianza alta. Normalmente, una buena respuesta que responde por completo a la consulta del usuario. | "He publicado mi KB pero no se actualiza". |
| 50-70 | Confianza media. Normalmente, una respuesta bastante buena que debería responder el propósito principal de la consulta del usuario. | "¿Debo guardar mis actualizaciones antes de publicar mi KB?" |
| 30-50 | Confianza baja. Normalmente, una respuesta relacionada que responde en parte a la intención del usuario. | "¿Qué hace Guardar y entrenar?" |
| < 30 | Confianza muy baja. Normalmente, no responde a la consulta del usuario, pero contiene algunas palabras o frases coincidentes. | "¿Donde puedo agregar sinónimos a mi KB?" |
| 0 | Ninguna coincidencia, por lo que no se devuelve una respuesta. | "¿Cuánto cuesta el servicio?" |
Seleccionar un umbral de puntuación
En la tabla anterior se muestran las puntuaciones que se pueden esperar en la mayoría de KB. Aun así, como cada KB es diferente y contiene tipos de palabras, intenciones y objetivos distintos, se recomienda que pruebe y seleccione el umbral que mejor funcione en su caso. De forma predeterminada, el umbral se establece en 0, por lo que se devuelven todas las respuestas posibles. El umbral recomendado que debe funcionar para la mayoría de bases de conocimiento es 50.
Al elegir el umbral, tenga en cuenta el equilibrio entre los valores de Precisión y Cobertura, y ajuste el umbral según sus requisitos.
Si la Precisión es más importante en su caso, aumente el umbral. De este modo, cada vez que se devuelva una respuesta, el resultado será mucho más confiable y probablemente responderá a lo que buscan los usuarios. En este caso, podrían quedar más preguntas sin responder. Por ejemplo: si establece el umbral en 70, podría perder la oportunidad de responder a algunos ejemplos ambiguos, como "¿Qué es Guardar y entrenar?".
Si la Cobertura (o coincidencia) es más importante y quiere responder a tantas preguntas como sea posible, incluso aunque solo haya una relación parcial con la pregunta del usuario, reduzca el umbral. Esto significa que podría haber más casos en los que el resultado no responde a la consulta en sí del usuario, pero proporciona otra respuesta en cierto modo relacionada. Por ejemplo: si crea el umbral 30, podría dar respuestas a consultas del tipo "¿Dónde puedo editar mi KB?"
Nota
Las versiones más recientes de QnA Maker incluyen mejoras en la lógica de puntuación, lo que podría afectar al umbral. Siempre que actualice el servicio, no olvide probar y ajustar el umbral, en caso necesario. Puede comprobar la versión del servicio QnA aquíy obtener información acerca de cómo obtener las actualizaciones más recientes aquí.
Establecimiento del umbral
Establezca la puntuación del umbral como una propiedad del cuerpo JSON GenerateAnswer API. Esto significa que se configura para cada llamada en GenerateAnswer.
En la plataforma de bots, establezca la puntuación como parte del objeto de opciones con C# o Node.js.
Mejorar las puntuaciones de confianza
Para mejorar la puntuación de confianza de una respuesta concreta a una consulta de usuario, puede agregar la consulta del usuario a la base de conocimiento como una pregunta alternativa en la respuesta. También puede usar alteraciones de palabras que no distinguen mayúsculas de minúsculas para agregar sinónimos a las palabras clave en la KB.
Puntuaciones de confianza similares
Si varias respuestas tienen una puntuación de confianza similar, es probable que la consulta fuera demasiado genérica y, por tanto, coincidiera con la misma probabilidad con varias respuestas. Intente estructurar mejor sus preguntas y respuestas para que todas las entidades QnA tengan una intención distinta.
Diferencias de puntuación de confianza entre prueba y producción
La puntuación de confianza de una respuesta puede cambiar de manera apenas perceptible entre la prueba y la versión publicada de la base de conocimiento, aunque el contenido sea el mismo. Esto se debe a que el contenido de la prueba y la base de conocimiento publicada se encuentran en distintos índices de Azure AI Search.
El índice de prueba contiene todos los pares de QnA de las bases de conocimiento. Al consultar el índice de prueba, la consulta se aplica a todo el índice y los resultados se restringen a la partición de esa base de conocimiento específica. Si los resultados de la consulta de prueba afectan negativamente a la capacidad de validar la base de conocimiento, puede:
- Organizar la base de conocimiento mediante una de las siguientes opciones:
- Un recurso restringido a 1 KB: restrinja el único recurso de QnA (y el índice de prueba de Azure AI Search resultante) a una única base de conocimiento.
- Dos recursos, uno para pruebas y otro para producción: dos recursos de QnA Maker, uno se usa para las pruebas (con sus propios índices de prueba y producción) y otro para el producto (también tiene sus propios índices de prueba y producción)
- Y siempre utilizan los mismos parámetros, como top al consultar la base de conocimiento de producción y de prueba.
Cuando se publica una base de conocimiento, el contenido de preguntas y respuestas de la base de conocimiento se mueve desde el índice de prueba a un índice de producción en Azure Search. Vea cómo se lleva a cabo la operación de publicación.
Si tiene una base de conocimiento en regiones diferentes, cada región usa su propio índice de Azure AI Search. Dado que se usan distintos índices, las puntuaciones no serán las mismas exactamente.
No se encontraron coincidencias
Si el clasificador no encuentra ninguna buena coincidencia, se devuelve una puntuación de confianza de 0,0 o "None" (Ninguna) y la respuesta predeterminada no es "No good match found in the KB" (No se encontró ninguna buena coincidencia en KB)". Puede invalidar esta respuesta predeterminada en el código de aplicación o bot mediante una llamada al punto de conexión. Como alternativa, también puede establecer la respuesta de invalidación en Azure, lo que cambiará el valor predeterminado para todas las knowledge base implementada en un determinado servicio QnA Maker.