¿Qué es la voz neuronal personalizada?
Voz neuronal personalizada (CNV) es una característica de texto a voz que permite crear una voz sintética personalizada única para las aplicaciones. Con Voz neuronal personalizada, puede crear una voz que suene muy natural para su marca o personajes proporcionando muestras de voz humana como datos de entrenamiento.
Importante
El acceso a Voz neuronal personalizada está limitado en función de los criterios de idoneidad y uso. Solicitar acceso en el formulario de ingesta.
El acceso a Voz neuronal personalizada (CNV) Lite está disponible para que cualquier persona que quiera ver una demo y evaluar CNV antes de invertir en grabaciones profesionales para crear una voz de mayor calidad.
De fábrica, se puede usar texto a voz con voces neuronales pregeneradas para cada idioma compatible. Las voces neuronales pregeneradas funcionan bien en la mayoría de los escenarios de texto a voz si no se requiere una voz única.
Voz neuronal personalizada se basa en la tecnología neuronal de texto a voz y en el modelo universal multilingüe de varios hablantes. Puede crear voces sintéticas enriquecidas en estilos de habla o idiomas cruzados adaptables. La voz con sonido natural y realista de Voz neuronal personalizada puede representar marcas, personificar máquinas y permitir que los usuarios interactúen en conversaciones con las aplicaciones. Consulte los idiomas admitidos para la voz neuronal personalizada.
¿Cómo funciona?
Para crear una voz neuronal personalizada, use Speech Studio para cargar el audio grabado y los scripts correspondientes, entrenar el modelo e implementar la voz en un punto de conexión personalizado.
Sugerencia
Pruebe Voz neuronal personalizada (CNV) Lite para ver una demo y evaluar CNV antes de invertir en grabaciones profesionales a fin de crear una voz de mayor calidad.
La creación de una voz neuronal personalizada excelente requiere controlar la calidad con atención en cada paso, desde el diseño de voz y la preparación de datos hasta la implementación del modelo de voz en el sistema.
Antes de empezar a trabajar en Speech Studio, estas son algunas consideraciones que debe tener en cuenta:
- Diseñe un rol de la voz que represente su marca mediante un documento breve del rol. En este documento se definen elementos como las características de la voz y el carácter detrás de la voz. Esto le ayudará a guiar el proceso de creación de un modelo de voz neuronal personalizada, incluida la definición de los scripts, la selección del talento de voz, el entrenamiento y la optimización de voz.
- Seleccione el script de grabación a fin de representar los escenarios de usuario para su voz. Por ejemplo, puede usar las frases de las conversaciones del bot como script de grabación si va a crear un bot de servicio al cliente. Incluya diferentes tipos de oraciones en los scripts, como instrucciones, preguntas, exclamaciones, etc.
Esta es una introducción a los pasos que debe seguir para crear una voz neuronal personalizada en Speech Studio:
- Cree un proyecto para que incluya los datos, los modelos de voz, las pruebas y los puntos de conexión. Cada proyecto es específico de un país/región y un idioma. Si va a crear varias voces, se recomienda crear un proyecto para cada voz.
- Configure el actor de voz. Para poder entrenar una voz neuronal, debe enviar una grabación de la declaración de consentimiento del actor de voz. La declaración de actor de voz es una grabación del actor de voz en la que lee una declaración por la da su consentimiento al uso de sus datos de voz para entrenar un modelo de voz personalizado.
- Prepare los datos de entrenamiento en el formato correcto. Se recomienda grabar el audio en un estudio de grabación de calidad profesional para lograr una alta relación entre señal y ruido. La calidad del modelo de voz depende en gran medida de los datos de entrenamiento. Se necesita un volumen constante, velocidad de la conversación, tono y coherencia en las particularidades expresivas del habla.
- Entrene el modelo de voz. Para crear una voz neuronal personalizada, seleccione al menos 300 expresiones. Al cargarlas se realiza automáticamente una serie de comprobaciones de calidad de los datos. Para crear modelos de voz de alta calidad, debe corregir los errores y realizar de nuevo el envío.
- Pruebe la voz. Prepare scripts de prueba para el modelo de voz que cubran los distintos casos de uso de las aplicaciones. Se recomienda usar scripts del conjunto de datos de entrenamiento y otros para probar la calidad de forma más amplia con contenido diferente.
- Implemente y use el modelo de voz en las aplicaciones.
Puede afinar, ajustar y usar la voz personalizada, de forma similar a como usaría una voz neuronal pregenerada. Convierta texto en voz en tiempo real o genere contenido de audio sin conexión con entrada de texto. Use la API de REST, el SDK de Voz o Speech Studio.
Sugerencia
También puede usar el SDK de Voz y la API REST de voz personalizada para entrenar una voz neuronal personalizada.
Revise los ejemplos de código del Repositorio del SDK de Voz en GitHub para ver cómo usar la voz neuronal personalizada en la aplicación.
El estilo y las características del modelo de voz entrenado dependen del estilo y la calidad de las grabaciones del talento de voz del entrenamiento. Sin embargo, puede realizar varios ajustes mediante SSML (Lenguaje de marcado de síntesis de voz) al realizar llamadas API al modelo de voz para generar voz sintética. SSML es el lenguaje de marcado que se usa para la comunicación con el servicio de texto en voz con el fin de convertir texto en audio. Los ajustes que puede realizar incluyen el cambio de tono, la velocidad, la entonación y la corrección de la pronunciación. Si el modelo de voz se ha creado con varios estilos, SSML también se puede usar para cambiar los estilos.
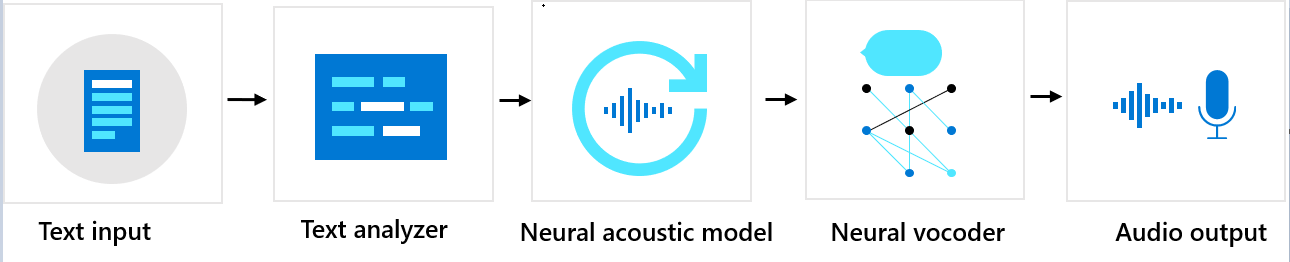
Secuencia de componentes
Voz neuronal personalizada consta de tres componentes principales: el analizador de texto, el modelo acústico neuronal y el vocoder neuronal. Para generar voz sintética natural a partir de texto, la primera entrada en el analizador de texto es el texto, cuya salida es una secuencia de fonemas. Un fonema es una unidad básica de sonido que distingue una palabra de otra en un idioma determinado. Una secuencia de fonemas define la pronunciación de las palabras proporcionadas en el texto.
A continuación, la secuencia de fonemas pasa al modelo acústico neuronal para predecir las características acústicas que definen las señales de voz. Las características acústicas incluyen el timbre, el estilo de habla, la velocidad, las entonaciones y los patrones de tensión. Por último, el vocoder neuronal convierte las características acústicas en ondas audibles para que se genere la voz sintética.
Los modelos de conversión de texto a voz neuronal se entrenan mediante redes neuronales profundas basadas en las muestras de grabaciones de voces humanas. Para más información, consulte esta entrada de blog de Microsoft. Para más información sobre cómo se entrena un vocoder neuronal, consulte esta entrada de blog de Microsoft.
Migración a Voz neuronal personalizada
Si usa la versión anterior de Voz personalizada (programada para retirarse en febrero de 2024), consulte Migración a Voz neuronal personalizada.
IA responsable
Los sistemas de inteligencia artificial no solo incluyen la tecnología, sino también las personas que la usan, las que se ven afectadas por ella y el entorno en el que se implementan. Lea las notas sobre transparencia para obtener información sobre el uso responsable de la inteligencia artificial y la implementación en los sistemas.
- Nota sobre transparencia y casos de uso de Voz neuronal personalizada
- Características y limitaciones de uso de Voz neuronal personalizada
- Acceso limitado a Voz neuronal personalizada
- Directrices para la implementación responsable de la tecnología de voz sintética
- Divulgación de talento de voz
- Directrices de diseño de divulgación de información
- Modelos de diseño de divulgación
- Código de conducta para las integraciones de texto a voz
- Datos, privacidad y seguridad de Voz neuronal personalizada