¿Qué es el almacén analítico de Azure Cosmos DB?
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Importante
La creación de reflejo de Azure Cosmos DB en Microsoft Fabric ya está disponible para la API de NoSql. Esta característica proporciona todas las funcionalidades de Azure Synapse Link con un mejor rendimiento analítico, la posibilidad de unificar el patrimonio de datos con Fabric OneLake y el acceso abierto a los datos en formato Delta Parquet. Si está considerando Azure Synapse Link, le recomendamos probar la creación de reflejo para evaluar si es la solución adecuada para su organización. Introducción a la creación de reflejos en Microsoft Fabric.
Para empezar a trabajar con Azure Synapse Link, visite “Introducción a Azure Synapse Link”
El almacén analítico de Azure Cosmos DB es un almacén de columnas completamente aislado para habilitar el análisis a gran escala en los datos operativos de su instancia de Azure Cosmos DB, sin que ello afecte a las cargas de trabajo transaccionales.
El almacén transaccional de Azure Cosmos DB es independiente del esquema y le permite iterar las aplicaciones transaccionales sin tener que encargarse de la administración de esquemas o índices. A diferencia de esto, el almacén analítico de Azure Cosmos DB está esquematizado para optimizar el rendimiento de las consultas analíticas. En este artículo se describe detalladamente el almacenamiento analítico.
Desafíos del análisis a gran escala de los datos operativos
Los datos operativos de varios modelos de un contenedor de Azure Cosmos DB se almacenan internamente en un "almacén transaccional" basado en filas indexado. El formato del almacén de filas está diseñado para permitir lecturas y escrituras transaccionales rápidas, con tiempos de respuesta en el orden de milisegundos, y consultas operativas. Si el conjunto de datos crece, las consultas analíticas complejas pueden ser costosas en términos de rendimiento aprovisionado en los datos almacenados en este formato. El alto consumo de rendimiento aprovisionado, a su vez, afecta al rendimiento de las cargas de trabajo transaccionales utilizadas por las aplicaciones y los servicios en tiempo real.
Tradicionalmente, para analizar grandes cantidades de datos, los datos operativos se extraen del almacén transaccional de Azure Cosmos DB y se almacenan en una capa de datos independiente. Por ejemplo, los datos se almacenan en un almacenamiento de datos o en un lago de datos con un formato adecuado. Más tarde, estos datos se usan para análisis a gran escala, y se analizan mediante un motor de proceso, como los clústeres de Apache Spark. La separación de los datos analíticos de los datos operativos da lugar a retrasos para los analistas que quieran usar los datos más recientes.
Las canalizaciones ETL también se vuelven complejas al administrar las actualizaciones de los datos operativos en comparación con cuando se administran únicamente los datos operativos recién ingeridos.
Almacén analítico orientado a columnas
El almacén analítico de Azure Cosmos DB aborda los desafíos de complejidad y latencia que se presentan con las canalizaciones ETL tradicionales. El almacén analítico de Azure Cosmos DB puede sincronizar automáticamente los datos operativos en un almacén de columnas independiente. El formato del almacén de columnas es adecuado para las consultas analíticas a gran escala que se van a realizar de forma optimizada, lo que aumenta la latencia de estas.
Con Azure Synapse Link, ahora puede compilar soluciones de HTAP sin ETL mediante la vinculación directa al almacén analítico de Azure Cosmos DB desde Azure Synapse Analytics. Esto le permite ejecutar análisis a gran escala casi en tiempo real con los datos operativos.
Características del almacén analítico
Cuando se habilita el almacén analítico en un contenedor de Azure Cosmos DB, se crea internamente un nuevo almacén de columnas en función de los datos operativos del contenedor. Este almacén de columnas se conserva por separado del almacén transaccional orientado a filas para ese contenedor, en una cuenta de almacenamiento totalmente administrada por Azure Cosmos DB, en una suscripción interna. No es necesario que los clientes dediquen tiempo a la administración del almacenamiento. Las inserciones, actualizaciones y eliminaciones de los datos operativos se sincronizan automáticamente con el almacén analítico. No necesita la fuente de cambios ni ETL para sincronizar los datos.
Almacén de columnas para cargas de trabajo analíticas en datos operativos
En general, las cargas de trabajo analíticas implican agregaciones y exámenes secuenciales de los campos seleccionados. El almacén analítico de datos se almacena en un orden principal de columna, lo que permite serializar juntos los valores de cada campo, cuando proceda. Este formato reduce las IOPS necesarias para examinar o procesar las estadísticas de los campos específicos. Esto mejora drásticamente los tiempos de respuesta de las consultas para los exámenes en grandes conjuntos de datos.
Por ejemplo, si las tablas operativas se encuentran en el formato siguiente:
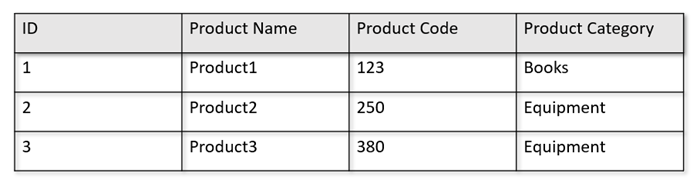
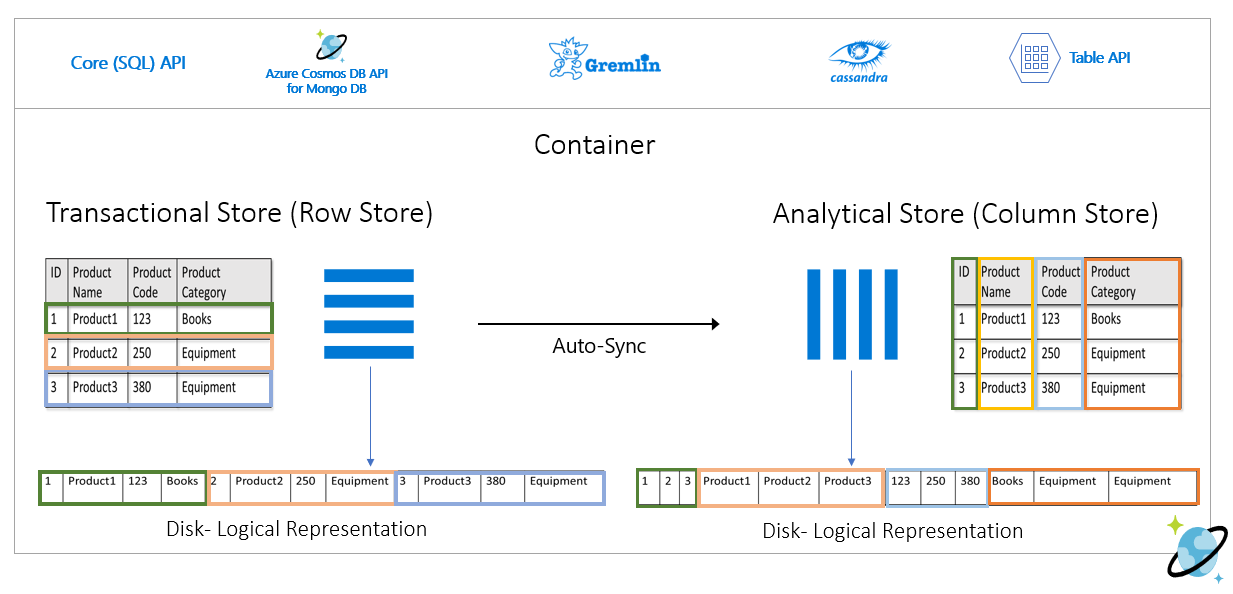
El almacén de filas conserva los datos anteriores en un formato serializado, por fila, en el disco. Este formato permite lecturas y escrituras transaccionales y consultas operativas más rápidas, como "Devolver información sobre Product 1". Sin embargo, a medida que el conjunto de datos crece en gran medida y si desea ejecutar consultas analíticas complejas con los datos, esto puede ser caro. Por ejemplo, si quiere obtener "las tendencias de ventas de un producto en la categoría denominada "Equipment" en diferentes unidades de negocio y meses", debe ejecutar una consulta compleja. Los análisis de gran tamaño de este conjunto de datos pueden resultar caros en cuanto al rendimiento aprovisionado, además de poder afectar al rendimiento de las cargas de trabajo transaccionales que potencian sus aplicaciones y servicios en tiempo real.
El almacén analítico, que es un almacén de columnas, es más adecuado para estas consultas, ya que serializa en conjunto los campos de datos similares y reduce las IOPS del disco.
En la imagen siguiente se muestra el almacén de filas transaccional frente el almacén de columnas analítico en Azure Cosmos DB:
Rendimiento desacoplado para cargas de trabajo analíticas
No hay ningún impacto en el rendimiento de las cargas de trabajo transaccionales debido a las consultas analíticas, ya que el almacén analítico es independiente del almacén transaccional. El almacén analítico no necesita que se asignen Unidades de solicitud (RU) independientes.
Sincronización automática
La sincronización automática hace referencia a la funcionalidad totalmente administrada de Azure Cosmos DB donde las inserciones, las actualizaciones y las eliminaciones de datos operativos se sincronizan automáticamente entre el almacén transaccional y el almacén analítico casi en tiempo real. La latencia de sincronización automática suele ser de menos de 2 minutos. En los casos en los que una base de datos de rendimiento compartida cuente con un gran número de contenedores, la latencia de sincronización automática de contenedores individuales puede ser mayor y tardar hasta 5 minutos.
Al final de cada ejecución del proceso de sincronización automática, los datos transaccionales estarán disponibles inmediatamente para los entornos de ejecución de Azure Synapse Analytics:
Los grupos de Spark de Azure Synapse Analytics pueden leer todos los datos, incluidas las actualizaciones más recientes, mediante tablas de Spark, que se actualizan automáticamente, o mediante el comando
spark.read, que siempre lee el último estado de los datos.Los grupos sin servidor SQL de Azure Synapse Analytics pueden leer todos los datos, incluidas las actualizaciones más recientes, mediante las vistas, que se actualizan automáticamente, o por medio del comando
SELECTjunto conOPENROWSET, que siempre lee el estado más reciente de los datos.
Nota
Los datos transaccionales se sincronizarán con el almacén analítico incluso si el período de vida (TTL) transaccional es inferior a 2 minutos.
Nota:
Tenga en cuenta que, si elimina el contenedor, también se eliminará el almacén analítico.
Escalabilidad y elasticidad
El almacén transaccional de Azure Cosmos DB usa la creación de partición horizontal para escalar elásticamente el almacenamiento y el rendimiento sin tiempo de inactividad. La creación de partición horizontal en el almacén transaccional proporciona escalabilidad y elasticidad en la sincronización automática para garantizar que los datos se sincronicen con el almacén analítico casi en tiempo real. La sincronización de datos se produce independientemente del rendimiento del tráfico transaccional, ya sean 1000 operaciones/s o 1 millón de operaciones/s, y no afecta al rendimiento aprovisionado en el almacén transaccional.
Control automático de las actualizaciones de esquema
El almacén transaccional de Azure Cosmos DB es independiente del esquema y le permite iterar las aplicaciones transaccionales sin tener que encargarse de la administración de esquemas o índices. A diferencia de esto, el almacén analítico de Azure Cosmos DB está esquematizado para optimizar el rendimiento de las consultas analíticas. Con la funcionalidad de sincronización automática, Azure Cosmos DB administra la inferencia de esquemas en las actualizaciones más recientes del almacén transaccional. También administra la representación del esquema en el almacén analítico de manera integrada, lo que incluye el control de los tipos de datos anidados.
A medida que evoluciona el esquema, y se agregan propiedades nuevas con el tiempo, el almacén analítico presenta automáticamente un esquema unificado de todos los esquemas históricos del almacén de transacciones.
Nota:
En el contexto del almacén analítico, consideramos las siguientes estructuras como propiedad:
- "Elementos" JSON" o "pares cadena-valor separados por
:". - Objetos JSON, delimitados por
{y}. - Matrices JSON, delimitadas por
[y].
Restricciones del esquema
Las restricciones siguientes se aplican a los datos operativos de Azure Cosmos DB al habilitar el almacén analítico para que realice la inferencia automáticamente y represente el esquema correctamente:
Puede tener un máximo de 1000 propiedades entre todos los niveles anidados en el esquema del documento y una profundidad de anidamiento máxima de 127.
- En el almacén analítico solo se representan las primeras 1000 propiedades.
- En el almacén analítico solo se representan los primeros 127 niveles anidados.
- El primer nivel de un documento JSON es su nivel raíz
/. - Las propiedades del primer nivel del documento se representarán como columnas.
Escenarios de ejemplo:
- Si el primer nivel del documento tiene 2000 propiedades, el proceso de sincronización representará los primeros 1000 de ellos.
- Si los documentos tienen cinco niveles con 200 propiedades cada uno, el proceso de sincronización representará todas las propiedades.
- Si los documentos tienen 10 niveles con 400 propiedades cada uno, el proceso de sincronización representará completamente los dos primeros niveles y solo la mitad del tercer nivel.
El documento hipotético siguiente contiene cuatro propiedades y tres niveles.
- Los niveles son
rootmyArrayy la estructura anidada dentro demyArray. - Las propiedades son
id,myArray,myArray.nested1ymyArray.nested2. - La representación del almacén analítico tendrá dos columnas,
idymyArray. Puede usar las funciones de Spark o T-SQL para exponer también las estructuras anidadas como columnas.
- Los niveles son
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Mientras que los documentos JSON (y las colecciones y contenedores de Azure Cosmos DB) distinguen mayúsculas de minúsculas desde una perspectiva de unicidad, el almacén analítico no lo hace.
- En el mismo documento: los nombres de propiedades del mismo nivel deben ser únicos cuando se comparan mayúsculas y minúsculas. Por ejemplo, el siguiente documento JSON tiene "Name" y "name" en el mismo nivel. Aunque es un documento JSON válido, no satisface la restricción de unicidad y, por lo tanto, no se representará por completo en el almacén analítico. En este ejemplo, "Name" y "name" son iguales al compararlos sin hacer distinción de mayúsculas y minúsculas. Solo se representará
"Name": "fred"en el almacén analítico, ya que es la primera aparición. Asimismo,"name": "john"no se representarán en absoluto.
{"id": 1, "Name": "fred", "name": "john"}- En documentos diferentes: las propiedades del mismo nivel y con el mismo nombre, pero en casos diferentes, se representarán dentro de la misma columna, con el formato de nombre de la primera aparición. Por ejemplo, los siguientes documentos JSON tienen
"Name"y"name"en el mismo nivel. Dado que el primer formato de documento es"Name", esto es lo que se usará para representar el nombre de la propiedad en el almacén analítico. En otras palabras, el nombre de columna del almacén analítico será"Name". Tanto"fred"como"john"se representarán en la columna"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- En el mismo documento: los nombres de propiedades del mismo nivel deben ser únicos cuando se comparan mayúsculas y minúsculas. Por ejemplo, el siguiente documento JSON tiene "Name" y "name" en el mismo nivel. Aunque es un documento JSON válido, no satisface la restricción de unicidad y, por lo tanto, no se representará por completo en el almacén analítico. En este ejemplo, "Name" y "name" son iguales al compararlos sin hacer distinción de mayúsculas y minúsculas. Solo se representará
El primer documento de la colección define el esquema de almacenamiento analítico inicial.
- Los documentos que tengan más propiedades que el esquema inicial generarán nuevas columnas en el almacén analítico.
- No se pueden quitar las columnas.
- La eliminación de todos los documentos de una colección no restablece el esquema del almacén analítico.
- No hay control de versiones del esquema. La última versión inferida a partir del almacén de transacciones es lo que verá en el almacén analítico.
Actualmente, Azure Synapse Spark no puede leer propiedades que contengan en su nombre determinados caracteres especiales, que se enumeran a continuación. Azure Synapse SQL sin servidor no se ve afectado.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Nota:
Los espacios en blanco también se muestran en el mensaje de error de Spark devuelto al alcanzar esta limitación. Pero se ha agregado un tratamiento especial para los espacios en blanco; puede consultar más detalles en los elementos siguientes.
- Si tiene nombres de propiedades con los caracteres enumerados anteriormente, las alternativas son:
- Cambie el modelo de datos de antemano para evitar estos caracteres.
- Dado que actualmente no se admite el restablecimiento del esquema, puede cambiar la aplicación para agregar una propiedad redundante con un nombre similar, evitando estos caracteres.
- Use la fuente de cambios para crear una vista materializada del contenedor sin estos caracteres en los nombres de propiedades.
- Use la opción de Spark
dropColumnpara ignorar las columnas afectadas y cargar todas las demás columnas en un elemento DataFrame. La sintaxis es:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Ahora Azure Synapse Spark admite propiedades con espacios en blanco en sus nombres. Para ello, debe usar la opción de Spark
allowWhiteSpaceInFieldNamespara cargar las columnas afectadas en un elemento DataFrame, y mantener el nombre original. La sintaxis es:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
No se admiten los siguientes tipos de datos BSON y no se representarán en el almacén analítico:
- Decimal128
- Expresión regular
- Puntero de base de datos
- JavaScript
- Símbolo
- MinKey/MaxKey
Cuando se usan cadenas DateTime que siguen el estándar UTC ISO 8601, se espera el comportamiento siguiente:
- Los grupos de Spark en Azure Synapse representarán estas columnas como
string. - Los grupos sin servidor de SQL en Azure Synapse representan estas columnas como
varchar(8000).
- Los grupos de Spark en Azure Synapse representarán estas columnas como
Las propiedades con tipos
UNIQUEIDENTIFIER (guid)se representan comostringen el almacén analítico y se deben convertirVARCHARen SQL ostringen Spark para una visualización correcta.Los grupos de SQL sin servidor de Azure Synapse admiten conjuntos de resultados con hasta 1000 columnas y exponer columnas anidadas también cuenta para ese límite. Se recomienda tener en cuenta esta información en la arquitectura y el modelado de datos transaccionales.
Si cambia el nombre de una propiedad, en uno o varios documentos, se considerará una columna nueva. Si ejecuta el mismo cambio de nombre en todos los documentos de la colección, todos los datos se migrarán a la nueva columna y la columna antigua se representará con valores
NULL.
Representación del esquema
Hay dos métodos de representación de esquema en el almacén analítico, válidos para todos los contenedores de la cuenta de base de datos. Estos modelos presentan algunas ventajas e inconvenientes: la simplicidad de la experiencia de consulta frente a la conveniencia de una representación en columnas más inclusiva para los esquemas polomórficos.
- Representación de esquema bien definida, opción predeterminada para las cuentas de API para NoSQL y Gremlin.
- Representación del esquema de fidelidad total, opción predeterminada para las cuentas de API para MongoDB.
Representación de esquemas bien definida
La representación de esquemas bien definida crea una representación tabular simple de los datos independientes del esquema en el almacén transaccional. La representación de esquemas bien definida tiene las siguientes características:
- El primer documento define el esquema base y las propiedades siempre deben tener el mismo tipo en todos los documentos. Las excepciones son estas:
- Desde
NULLa cualquier otro tipo de datos. La primera aparición no nula define el tipo de datos de la columna. Cualquier documento que no sigue el primer tipo de datos no NULL no se representará en el almacén analítico. - De
floatainteger. Todos los documentos están representados en el almacén analítico. - De
integerafloat. Todos los documentos están representados en el almacén analítico. Sin embargo, para leer estos datos con grupos sin servidor de Azure Synapse SQL, debe usar una cláusula WITH para convertir la columna envarchar. Y, después de esta conversión inicial, es posible convertirla de nuevo en un número. Consulte el siguiente ejemplo, donde el valor inicial num era un número entero y el segundo era un número flotante.
- Desde
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Las propiedades que no siguen el tipo de datos de esquema base no se representarán en el almacén analítico. Por ejemplo, considere los dos documentos siguientes: el primero ha definido el esquema base del almacén analítico. El segundo documento, donde
ides"2", no tiene un esquema bien definido ya que la propiedad"code"es una cadena y el primer documento tiene"code"como número. En este caso, el almacén analítico registra el tipo de datos de"code"comointegerdurante la vigencia del contenedor. El segundo documento todavía se incluirá en el almacén analítico, pero no su propiedad"code".{"id": "1", "code":123}{"id": "2", "code": "123"}
Nota:
La condición anterior no se aplica a las propiedades NULL. Por ejemplo, {"a":123} and {"a":NULL} sigue estando bien definido.
Nota:
La condición anterior no cambia si actualiza "code" de documento "1" a una cadena en el almacén transaccional. En el almacén analítico, "code" se mantendrá como integer, ya que actualmente no se admite el restablecimiento de esquema.
- Los tipos de las matrices deben contener un único tipo repetido. Por ejemplo,
{"a": ["str",12]}no es un esquema bien definido, porque la matriz contiene una mezcla de tipos enteros y de cadena.
Nota:
Si el almacén analítico de Azure Cosmos DB sigue la representación de esquema bien definido y no se cumplen las especificaciones anteriores en determinados elementos, estos no se incluirán en el almacén analítico.
Se espera un comportamiento diferente en lo que respecta a los diferentes tipos en el esquema bien definido:
- Los grupos de Spark en Azure Synapse representarán estos valores como
undefined. - Los grupos sin servidor de SQL en Azure Synapse representarán estos valores como
NULL.
- Los grupos de Spark en Azure Synapse representarán estos valores como
Se espera un comportamiento diferente con respecto a los valores explícitos
NULL:- Los grupos de Spark en Azure Synapse leen estos valores como
0(cero) yundefinedtan pronto como la columna tenga un valor distinto de NULL. - Los grupos sin servidor de SQL de Azure Synapse leen estos valores como
NULL.
- Los grupos de Spark en Azure Synapse leen estos valores como
Se espera un comportamiento diferente con respecto a las columnas que faltan:
- Los grupos de Spark en Azure Synapse representan estas columnas como
undefined. - Los grupos sin servidor de SQL en Azure Synapse representan estas columnas como
NULL.
- Los grupos de Spark en Azure Synapse representan estas columnas como
Soluciones alternativas de desafíos de representación
Es posible que se haya usado un documento antiguo, con un esquema incorrecto, para crear el esquema base del almacén analítico del contenedor. En función de todas las reglas presentadas anteriormente, es posible que reciba NULL para determinadas propiedades al consultar el almacén analítico mediante Azure Synapse Link. Para eliminar o actualizar los documentos problemáticos no ayudará porque actualmente no se admite el restablecimiento del esquema base. Las posibles soluciones son:
- Para migrar los datos a un nuevo contenedor, asegúrese de que todos los documentos tienen el esquema correcto.
- Abandonar la propiedad con el esquema incorrecto y agregar una nueva, con otro nombre, que tenga el esquema correcto en todos los documentos. Ejemplo: Tiene miles de millones de documentos en el contenedor Orders donde la propiedad status es una cadena. Pero el primer documento de ese contenedor tiene la propiedad status definida con entero. Por lo tanto, un documento tendrá el estado correctamente representado y todos los demás documentos tendrán
NULL. Puede agregar la propiedad status2 a todos los documentos y empezar a usarlo, en lugar de la propiedad original.
Representación de esquemas con fidelidad total
La representación de esquemas con fidelidad total está diseñada para administrar todos los esquemas polimórficos de los datos operativos independientes del esquema. En esta representación de esquemas no se quita ningún elemento del almacén analítico aunque no se cumplan las restricciones de los esquemas bien definidos (es decir, que no haya campos ni matrices de tipos de datos mixtos).
Esto se logra mediante la conversión de las propiedades hoja de los datos operativos en el almacén analítico como pares key-value de JSON, donde el tipo de datos es key y el contenido de la propiedad es value. Esta representación de objetos JSON permite consultas sin ambigüedad y hace posible analizar individualmente cada tipo de datos.
En otras palabras, en la representación del esquema de fidelidad completa, cada tipo de datos de cada propiedad de cada documento generará un par key-value en un objeto JSON para esa propiedad. Cada uno de ellos cuenta como una de las 1000 propiedades de límite máximo.
Por ejemplo, vamos a tomar el documento de ejemplo siguiente del almacén transaccional:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
El objeto anidado address es una propiedad en el nivel raíz del documento y se representará como una columna. Cada propiedad hoja del objeto address se representará como un objeto JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
A diferencia de la representación de esquema bien definido, el método de fidelidad completa permite la variación en los tipos de datos. Si el siguiente documento de esta colección del ejemplo anterior tiene streetNo como cadena, se representará en el almacén analítico como "streetNo":{"string":15850}. En el método de esquema bien definido, no se representaría.
Mapa de tipos de datos para el esquema de fidelidad completa
Aquí hay un mapa de los tipos de datos de MongoDB y sus representaciones en el almacén analítico en una representación de esquema de fidelidad total. El mapa siguiente no es válido para las cuentas de api de NoSQL.
| Tipo de datos original | Sufijo | Ejemplo |
|---|---|---|
| Doble | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| Binary | ".binary" | 0 |
| Boolean | ".bool" | Verdadero |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| Timestamp | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Documento | ".object" | {"a": "a"} |
Se espera un comportamiento diferente con respecto a los valores explícitos
NULL:- Los grupos de Spark en Azure Synapse leerán estos valores como
0(cero). - Los grupos sin servidor SQL de Azure Synapse leerán estos valores como
NULL.
- Los grupos de Spark en Azure Synapse leerán estos valores como
Se espera un comportamiento diferente con respecto a las columnas que faltan:
- Los grupos de Spark en Azure Synapse representarán estas columnas como
undefined. - Los grupos sin servidor de SQL en Azure Synapse representarán estas columnas como
NULL.
- Los grupos de Spark en Azure Synapse representarán estas columnas como
Se espera un comportamiento diferente con respecto a los valores
timestamp:- Los grupos de Spark en Azure Synapse leerán estos valores como
TimestampType,DateType, oFloat. Depende del intervalo y de cómo se generó la marca de tiempo. - Los grupos sin servidor SQL de Azure Synapse leerán estos valores como
DATETIME2, comprendido entre0001-01-01y9999-12-31. Los valores más allá de este intervalo no se admiten y provocarán un error de ejecución para las consultas. Si este es su caso, puede:- Quite la columna de la consulta. Para mantener la representación, puede crear una nueva creación de reflejo de la propiedad en esa columna, pero dentro del intervalo admitido. Y úselo en las consultas.
- Use la captura de datos modificados del almacén analítico, sin costo alguno, para transformar y cargar los datos en un nuevo formato, dentro de uno de los receptores admitidos.
- Los grupos de Spark en Azure Synapse leerán estos valores como
Uso del esquema de fidelidad completa con Spark
Spark administrará cada tipo de datos como una columna al cargarla en DataFrame. Supongamos que hay una colección con los documentos siguientes.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Mientras que el primer documento tiene rating como número y timestamp en formato utc, el segundo documento tiene rating y timestamp como cadenas. Suponiendo que esta colección se haya cargado en DataFrame sin ninguna transformación de datos, la salida de df.printSchema() es:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
En la representación de esquema bien definido, tanto rating como timestamp del segundo documento no se representarían. En el esquema de fidelidad completa, puede usar los ejemplos siguientes para acceder individualmente a cada valor de cada tipo de datos.
En el ejemplo siguiente, podemos usar PySpark para ejecutar una agregación:
df.groupBy(df.item.string).sum().show()
En el ejemplo siguiente, podemos usar PySQL para ejecutar otra agregación:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Uso del esquema de fidelidad completa con SQL
Puede usar la sintaxis siguiente de ejemplo, teniendo en cuenta los mismos documentos del ejemplo de Spark anterior:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Puede implementar transformaciones mediante cast, convert o cualquier otra función de T-SQL para manipular los datos. También puede ocultar estructuras complejas de tipos de datos mediante vistas.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Trabajar con el campo MongoDB _id
El campo MongoDB _id es fundamental para todas las colecciones de MongoDB y, originalmente, tiene una representación hexadecimal. Como se puede ver en la tabla anterior, el esquema de fidelidad completa conservará sus características, lo que dificulta su visualización en Azure Synapse Analytics. Para una visualización correcta, debe convertir el tipo de datos _id como se indica a continuación:
Uso del campo MongoDB _id en Spark
El ejemplo siguiente funciona en versiones 2.x y 3.x de Spark:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Uso del campo MongoDB _id en SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Trabajar con el campo MongoDB id
La propiedad id en contenedores de MongoDB se invalida automáticamente con la representación Base64 de la propiedad "_id" en el almacén analítico. El campo "id" está diseñado para uso interno de las aplicaciones de MongoDB. Actualmente, la única solución alternativa es cambiar el nombre de la propiedad "id" a algo distinto de "id".
Esquema de fidelidad total para las cuentas de API para NoSQL o Gremlin
Es posible usar el esquema de fidelidad total para las cuentas de API para NoSQL, en lugar de la opción predeterminada, si se establece el tipo de esquema al habilitar Synapse Link en una cuenta de Azure Cosmos DB por primera vez. Estas son las consideraciones sobre cómo cambiar el tipo de representación del esquema predeterminado:
- Actualmente, si habilita Synapse Link en la cuenta de API de NoSQL mediante Azure Portal, se habilitará como un esquema bien definido.
- Actualmente, si quiere usar el esquema de fidelidad total con cuentas de API de NoSQL o Gremlin, debe establecerlo en el nivel de cuenta en el mismo comando de la CLI o PowerShell que habilitará Synapse Link en el nivel de cuenta.
- Actualmente, Azure Cosmos DB for MongoDB no es compatible con esta posibilidad de cambiar la representación del esquema. Todas las cuentas de MongoDB siempre tendrán el tipo de representación del esquema de fidelidad total.
- La asignación de tipos de datos de esquema de fidelidad completa mencionada anteriormente no es válida para las cuentas de API de NoSQL, que usan tipos de datos JSON. Por ejemplo, los valores
floatyintegerse representan comonumen el almacén analítico. - No es posible restablecer el tipo de representación del esquema, de bien definido a fidelidad total o viceversa.
- Actualmente, el esquema de contenedores en el almacén analítico se define cuando se crea el contenedor, incluso si Synapse Link no se ha habilitado en la cuenta de la base de datos.
- Los contenedores o gráficos creados antes de habilitar Synapse Link con un esquema de fidelidad total en el nivel de cuenta tendrán un esquema bien definido.
- Los contenedores o gráficos creados después de habilitar Synapse Link con un esquema de fidelidad total en el nivel de cuenta tendrán un esquema de fidelidad total.
La decisión del tipo de representación del esquema se debe tomar al mismo tiempo que se habilita Synapse Link en la cuenta, mediante la CLI de Azure o PowerShell.
Con la CLI de Azure:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Nota:
En el comando anterior, reemplace create por update para las cuentas existentes.
Con PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Nota:
En el comando anterior, reemplace New-AzCosmosDBAccount por Update-AzCosmosDBAccount para las cuentas existentes.
Período de vida (TTL) analítico
El TTL analítico (ATTL) indica cuánto tiempo se deben conservar los datos en el almacén analítico para un contenedor.
El almacén analítico está habilitado cuando ATTL se establece con un valor distinto de NULL y 0. Cuando está habilitado, las inserciones, actualizaciones y eliminaciones de datos operativos se sincronizan automáticamente desde el almacén transaccional hacia el almacén analítico, independientemente de la configuración del TTL transaccional (TTTL). La propiedad AnalyticalStoreTimeToLiveInSeconds puede controlar la retención de estos datos transaccionales en el almacén analítico en el nivel de contenedor.
Las posibles configuraciones de ATTL son:
Si el valor se establece en
0: el almacén analítico está deshabilitado y no se replica ningún dato del almacén transaccional al almacén analítico. Abra un caso de soporte técnico para deshabilitar el almacén analítico en los contenedores.Si se omite el campo, no ocurre nada y se mantiene el valor anterior.
Si el valor se establece en
-1: el almacén analítico conserva todos los datos históricos, independientemente de la retención de los datos en el almacén transaccional. Este valor indica que el almacén analítico tiene una retención infinita de los datos operativos.Si el valor se establece en cualquier número entero positivo
n: los elementos expirarán del almacén analíticonsegundos después de la hora de la última modificación en el almacén transaccional. Este valor se puede aprovechar si desea conservar los datos operativos durante un período de tiempo limitado en el almacén analítico, independientemente de la retención de los datos en el almacén transaccional.
Algunos puntos que se deben tener en cuenta:
- Después de habilitar el almacén analítico con un valor de ATTL, se puede actualizar a otro valor válido más tarde.
- Aunque TTTL se puede establecer en el nivel de contenedor o de elemento, actualmente ATTL solo se puede establecer en el nivel de contenedor.
- Puede lograr una retención más prolongada de los datos operativos en el almacén analítico si establece un ATTL >= TTTL en el nivel de contenedor.
- Se puede hacer que el almacén analítico refleje el almacén transaccional si se establece ATTL = TTTL.
- Si tiene un valor de ATTL mayor que TTTL, en algún momento tendrá datos que solo existen en el almacén analítico. Estos datos son de solo lectura.
- Actualmente no se elimina ningún dato del almacén analítico. Si establece el valor de ATTL en un entero positivo, los datos no se incluirán en las consultas y no se le facturarán. Pero si cambia el valor de ATTL de nuevo a
-1, todos los datos se mostrarán de nuevo y se le empezará a facturar por todo el volumen de datos.
Cómo habilitar el almacén analítico en un contenedor:
En Azure Portal, la opción de ATTL, cuando está activada, se establece en el valor predeterminado de -1. Puede cambiar este valor a "n" segundos; para ello, vaya a la configuración del contenedor en el Explorador de datos.
Desde el SDK de administración de Azure, los SDK de Azure Cosmos DB, PowerShell o la CLI de Azure, la opción de ATTL se puede habilitar estableciendo su valor en -1 o "n" segundos.
Para obtener más información, consulte Configuración del TTL analítico en un contenedor.
Análisis rentable sobre datos históricos
La organización en capas de datos hace referencia a la separación de los datos entre las infraestructuras de almacenamiento optimizadas para los distintos escenarios. Con lo que se mejora el rendimiento general y la rentabilidad de la pila de datos de un extremo a otro. Con el almacén analítico, Azure Cosmos DB ahora admite la organización automática en capas de datos desde el almacén transaccional hacia el almacén analítico con diferentes diseños de datos. Con el almacén analítico optimizado en cuanto al costo de almacenamiento en comparación con el almacén transaccional, usted puede conservar un horizonte mucho más largo de datos operativos para el análisis histórico.
Una vez que el almacén analítico esté habilitado, en función de las necesidades de retención de datos de las cargas de trabajo transaccionales, puede configurar la propiedad transactional TTL para que los registros se eliminen automáticamente del almacén transaccional después de un período de tiempo determinado. Del mismo modo, analytical TTL le permite administrar el ciclo de vida de los datos retenidos en el almacén analítico de manera independiente del almacén transaccional. Al habilitar el almacén analítico y configurar las propiedades TTL transaccionales y analíticas, puede establecer fácilmente un nivel y definir el período de retención de los datos de los dos almacenes.
Nota:
Cuando analytical TTL se establece en un valor mayor que el valor transactional TTL, el contenedor tendrá datos que solo existen en el almacén analítico. Estos datos son de solo lectura, y actualmente no se admite el nivel de documento TTL en el almacén analítico. Si es posible que los datos del contenedor necesiten una actualización o una eliminación en algún momento en el tiempo, no use analytical TTL mayor que transactional TTL. Esta funcionalidad se recomienda para los datos que no necesitarán actualizaciones ni eliminaciones en el futuro.
Nota:
Si el escenario no exige eliminaciones físicas, puede adoptar un enfoque lógico de eliminación o actualización. Inserte en el almacén transaccional otra versión del mismo documento que solo exista en el almacén analítico, pero que necesite una eliminación o actualización lógicas. Puede usar una marca que indique que es una eliminación o una actualización de un documento expirado. Ambas versiones del mismo documento coexistirán en el almacén analítico y la aplicación solo debe tener en cuenta la última.
Resistencia
El almacén analítico se basa en Azure Storage y ofrece la protección siguiente frente a errores físicos:
- De manera predeterminada, las cuentas de base de datos de Azure Cosmos DB asignan un almacén analítico en cuentas de almacenamiento con redundancia local (LRS). LRS ofrece una durabilidad mínima del 99,999999999 % (once nueves) de los objetos en un año determinado.
- Si alguna región geográfica de la cuenta de base de datos está configurada para redundancia de zona, se asigna en cuentas de almacenamiento con redundancia de zona (ZRS). Debe habilitar Availability Zones en una región de su cuenta de base de datos de Azure Cosmos DB para tener datos analíticos de esa región almacenados con redundancia de zona. ZRS proporciona a los recursos de almacenamiento una durabilidad de al menos el 99,9999999999 % (doce nueves) durante un año determinado.
Para obtener más información sobre la durabilidad de Azure Storage, consulte este enlace.
Backup
Aunque el almacén analítico tiene protección integrada contra errores físicos, puede ser necesaria la copia de seguridad para eliminaciones accidentales o actualizaciones en el almacén transaccional. En esos casos, puede restaurar un contenedor y usar el contenedor restaurado para reponer los datos en el contenedor original o recompilar completamente el almacén analítico si es necesario.
Nota:
Actualmente no se realiza una copia de seguridad del almacén analítico, por lo que no se puede restaurar. En base a esto, no se puede planear la directiva de copia de seguridad.
Synapse Link, y el almacén analítico por consecuencia, tiene un nivel de compatibilidad diferente con los modos de copia de seguridad de Azure Cosmos DB:
- El modo copia de seguridad es totalmente compatible con Synapse Link y estas 2 funciones se pueden usar en la misma cuenta de base de datos.
- Synapse Link para las cuentas de base de datos que usan el modo de copia de seguridad continua es GA.
- El modo de copia de seguridad continua para las cuentas habilitadas para Synapse Link está en versión preliminar pública. Actualmente, no se puede migrar a la copia de seguridad continua si deshabilitó Synapse Link en cualquiera de las colecciones de una cuenta de Cosmos DB.
Directivas de copia de seguridad
Hay dos posibles directivas de copia de seguridad y para comprender cómo usarlas, los siguientes detalles sobre las copias de seguridad de Azure Cosmos DB son muy importantes:
- El contenedor original se restaura sin almacén analítico en ambos modos de copia de seguridad.
- Azure Cosmos DB no admite la sobrescritura de contenedores desde una restauración.
Ahora veamos cómo usar copias de seguridad y restauraciones desde la perspectiva del almacén analítico.
Restauración de un contenedor con TTTL >= ATTL
Cuando transactional TTL es igual o mayor que analytical TTL, todos los datos del almacén analítico siguen existiendo en el almacén transaccional. En el caso de una restauración, tiene dos situaciones posibles:
- Usar el contenedor restaurado como reemplazo del contenedor original. Para recompilar el almacén analítico, solo tiene que habilitar Synapse Link en el nivel de cuenta y en el nivel de contenedor.
- Usar el contenedor restaurado como origen de datos para reponer o actualizar los datos del contenedor original. En este caso, el almacén analítico reflejará automáticamente las operaciones de datos.
Restauración de un contenedor con TTTL < ATTL
Cuando transactional TTL es menor que analytical TTL, algunos datos solo existen en el almacén analítico y no estarán en el contenedor restaurado. De nuevo, tiene dos posibilidades:
- Usar el contenedor restaurado como reemplazo del contenedor original. En este caso, al habilitar Synapse Link en el nivel de contenedor, solo los datos que se encontraban en el almacén transaccional se incluirán en el nuevo almacén analítico. Sin embargo, tenga en cuenta que el almacén analítico del contenedor original permanece disponible para las consultas siempre y cuando exista el contenedor original. Es posible que quiera cambiar la aplicación para consultar ambos.
- Usar el contenedor restaurado como origen de datos para reponer o actualizar los datos del contenedor original:
- El almacén analítico reflejará automáticamente las operaciones de los datos que están en el almacén transaccional.
- Si vuelve a insertar datos que se quitaron anteriormente del almacén transaccional debido a
transactional TTL, estos datos se duplicarán en el almacén analítico.
Ejemplo:
- El contenedor
OnlineOrderstiene el valor de TTTL establecido en un mes y el de ATTL establecido en un año. - Cuando lo restaura en
OnlineOrdersNewy activa el almacén analítico para reconstruirlo, solo habrá un mes de datos en el almacén transaccional y analítico. - El contenedor
OnlineOrdersoriginal no se elimina y su almacén analítico sigue estando disponible. - Los nuevos datos solo se ingieren en
OnlineOrdersNew. - Las consultas analíticas realizarán un UNION ALL de los almacenes analíticos mientras los datos originales sigan siendo pertinentes.
Si desea eliminar el contenedor original pero no quiere perder los datos de su almacén analítico, puede conservar el almacén analítico del contenedor original en otro servicio de datos de Azure. Synapse Analytics tiene la funcionalidad de realizar combinaciones entre los datos almacenados en ubicaciones diferentes. Un ejemplo: una consulta de Synapse Analytics une los datos del almacén analítico con tablas externas ubicadas en Azure Blob Storage, Azure Data Lake Store, etc.
Es importante tener en cuenta que los datos del almacén analítico tienen un esquema diferente al que existe en el almacén transaccional. Aunque puede generar instantáneas de los datos del almacén analítico y exportarlas a cualquier servicio de datos de Azure, sin costos de RU, no se puede garantizar el uso de esta instantánea para volver a generar el almacén transaccional. No se admite este proceso.
Distribución global
Si tiene una cuenta de Azure Cosmos DB distribuida globalmente, después de habilitar el almacén analítico para un contenedor, estará disponible en todas las regiones de dicha cuenta. Los cambios en los datos operativos se replican globalmente en todas las regiones. Puede ejecutar consultas analíticas de forma eficaz en la copia regional más cercana de los datos en Azure Cosmos DB.
Creación de particiones
La creación de particiones del almacén analítico es independiente de la del almacén transaccional. De manera predeterminada, los datos del almacén analítico no tienen particiones. Si las consultas analíticas han usado filtros con frecuencia, tiene la opción de crear particiones en función de estos campos para mejorar el rendimiento de las consultas. Para más información, consulte los artículos de introducción a la creación de particiones personalizadas y sobre cómo configurar la creación de particiones personalizadas.
Seguridad
La autenticación con el almacén analítico es igual que en un almacén transaccional para una base de datos determinada.
Aislamiento de red con puntos de conexión privados: puede controlar el acceso de red a los datos de los almacenes transaccionales y analíticos de forma independiente. El aislamiento de red se realiza mediante puntos de conexión privados administrados distintos para cada almacén, dentro de redes virtuales administradas en áreas de trabajo de Azure Synapse. Para más información, consulte el artículo Configuración de puntos de conexión privados para almacenes analíticos.
Cifrado de datos en reposo: el cifrado del almacén analítico está habilitado de manera predeterminada.
Cifrado de datos con claves administradas por el cliente: puede cifrar completamente los datos de los almacenes transaccionales y analíticos con las mismas claves administradas por el cliente de manera automática y transparente. Azure Synapse Link solamente admite la configuración de claves administradas por el cliente mediante la identidad administrada de la cuenta de Azure Cosmos DB. Debe configurar la identidad administrada de la cuenta en la directiva de acceso de Azure Key Vault antes de habilitar Azure Synapse Link en la cuenta. Para más información, consulte el artículo Configuración de claves administradas por el cliente para una cuenta de Azure Cosmos con Azure Key Vault.
Nota:
Si cambia su cuenta de base de datos de Primera entidad a Sistema o Identidad asignada por el usuario, y habilita Azure Synapse Link en su cuenta de base de datos, no podrá volver a la identidad de Primera entidad, ya que no puede deshabilitar Synapse Link desde su cuenta de base de datos.
Compatibilidad con varios runtimes de Azure Synapse Analytics
El almacén analítico está optimizado para proporcionar escalabilidad, elasticidad y rendimiento para las cargas de trabajo analíticas sin depender de los runtimes de proceso. La tecnología de almacenamiento se administra automáticamente para optimizar las cargas de trabajo analíticas sin esfuerzo manual.
Los datos del almacén analítico de Azure Cosmos DB se pueden consultar simultáneamente desde los distintos entornos de ejecución de análisis admitidos por Azure Synapse Analytics. Azure Synapse Analytics admite Apache Spark y el grupo de SQL sin servidor con el almacén analítico de Azure Cosmos DB.
Nota:
Solo se puede leer del almacén analítico mediante los entornos de ejecución de Azure Synapse Analytics. Y al contrario, los entornos de ejecución de Azure Synapse Analytics solo pueden leer del almacén analítico. Solo el proceso de sincronización automática puede cambiar los datos en el almacén analítico. Puede volver a escribir datos en el almacén transaccional de Azure Cosmos DB mediante el grupo de Azure Synapse Analytics, por medio del SDK de OLPT integrado de Azure Cosmos DB.
Precios
El almacén analítico sigue un modelo de precios basado en el consumo, en el que se le cobra del modo siguiente:
Almacenamiento: el volumen de los datos retenidos en el almacén analítico cada mes, incluidos los datos históricos, tal como se define en el TTL analítico.
Operaciones de escritura analíticas: Sincronización totalmente administrada de las actualizaciones de datos operativos en el almacén analítico desde el almacén transaccional (sincronización automática).
Operaciones de lectura analíticas: operaciones de lectura realizadas en el almacén analítico desde los tiempos de ejecución del grupo de SQL sin servidor y el grupo de Spark de Azure Synapse Analytics.
Los precios del almacén analítico son independientes del modelo de precios del almacén transaccional. No hay un concepto de RU aprovisionadas en el almacén analítico. Consulte la página de precios de Azure Cosmos DB para obtener información completa sobre el modelo de precios del almacén analítico.
Solo se puede acceder a los datos del almacén de análisis a través de Azure Synapse Link, que se realiza en los entornos de ejecución de Azure Synapse Analytics: grupos de Apache Spark y grupos de SQL sin servidor de Azure Synapse. Consulte la página de precios de Azure Synapse Analytics para obtener todos los detalles sobre el modelo de precios para acceder a los datos de un almacén analítico.
Para obtener una estimación general del costo de habilitación del almacén analítico en un contenedor de Azure Cosmos DB, desde la perspectiva del almacén analítico, puede usar el planificador de capacidad de Azure Cosmos DB y obtener una estimación de los costos de almacenamiento analítico y de las operaciones de escritura.
Las estimaciones de operaciones de lectura del almacén analítico no se incluyen en la calculadora de costos de Azure Cosmos DB, ya que son una función de la carga de trabajo analítica. Como estimación general, el análisis de 1 TB de datos en el almacén analítico suele generar 130 000 operaciones de lectura analíticas, con un costo de 0,065 USD. Por ejemplo, si usa grupos de SQL sin servidor de Azure Synapse para realizar este examen de 1 TB, costará 5,00 USD según la página de precios de Azure Synapse Analytics. El costo total final de este examen de 1 TB sería de 5,065 USD.
Aunque la estimación anterior es para examinar 1 TB de datos en el almacén analítico, la aplicación de filtros reduce el volumen de datos analizados y esto determina el número exacto de operaciones de lectura analíticas según el modelo de precios de consumo. Una prueba de concepto en torno a la carga de trabajo analítica proporcionaría una estimación más fina de las operaciones de lectura analítica. Esta estimación no incluye el costo de Azure Synapse Analytics.
Pasos siguientes
Para obtener más información, consulte la siguiente documentación:
Consulte el módulo de entrenamiento sobre cómo Diseñar el procesamiento analítico y transaccional híbrido mediante Azure Synapse Analytics
Preguntas frecuentes sobre Synapse Link para Azure Cosmos DB