Escalado elástico de una cuenta de Azure Cosmos DB for Apache Cassandra
SE APLICA A: ![]() Cassandra
Cassandra
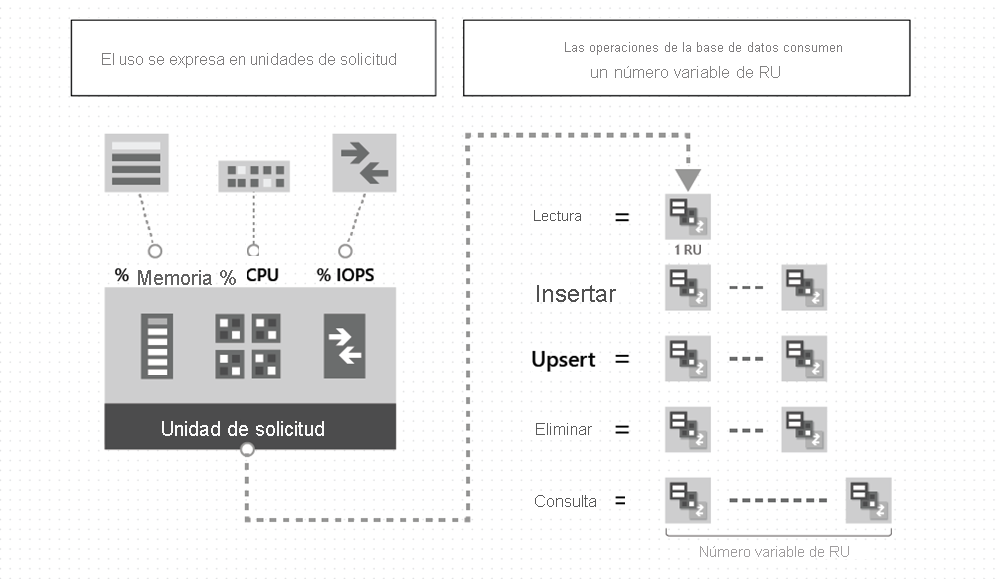
Hay varias opciones para explorar la naturaleza elástica de Azure Cosmos DB for Apache Cassandra. Para comprender cómo realizar un escalado eficaz en Azure Cosmos DB, es importante comprender cómo aprovisionar la cantidad correcta de unidades de solicitud (RU/s) para tener en cuenta las demandas de rendimiento del sistema. Para más información sobre las unidades de solicitud, consulte el artículo Unidades de solicitud.
En el caso de la API de Cassandra, puede recuperar el cargo de la unidad de solicitud en consultas individuales mediante los SDK de .NET y Java. Esto resulta útil para determinar la cantidad de RU/s que deberá aprovisionar en el servicio.
Administración de la limitación de frecuencia (errores 429)
Azure Cosmos DB devolverá errores de frecuencia limitada (429) si los clientes consumen más recursos (RU/s) que la cantidad que se ha aprovisionado. La API de Cassandra de Azure Cosmos DB traslada estas excepciones como errores sobrecargados en el protocolo nativo de Cassandra.
Si el sistema no es sensible a la latencia, puede que baste con administrar la limitación de frecuencia del rendimiento mediante reintentos. Consulte ejemplos de código de Java para la versión 3 y la versión 4 de los controladores de Java de Apache Cassandra para obtener información sobre cómo controlar la limitación de velocidad de forma transparente. Estos ejemplos implementan una versión personalizada de la directiva de reintentos de Cassandra predeterminada en Java. También puede usar la extensión de Spark para administrar la limitación de frecuencia. Al usar Spark, asegúrese de seguir las instrucciones que se indican en Optimización de la configuración del rendimiento del conector de Spark.
Administración del escalado
Si necesita reducir la latencia, existe un espectro de opciones para administrar la escala y aprovisionar el rendimiento (RU) en la API de Cassandra:
- Manualmente mediante Azure Portal
- Mediante programación con las características del plano de control
- Mediante programación con comandos de CQL con un SDK específico
- Dinámicamente con escalabilidad automática
En las siguientes secciones se explican las ventajas y desventajas de cada enfoque. Luego, puede decidir cuál es la mejor estrategia para equilibrar las necesidades de escalado del sistema, el costo general y las necesidades de eficiencia de la solución.
Uso de Azure Portal
Puede escalar los recursos en la cuenta de Azure Cosmos DB for Apache Cassandra mediante Azure Portal. Para más información, consulte el artículo sobre el aprovisionamiento del rendimiento en contenedores y bases de datos. En este artículo se explican las ventajas relativas de configurar el rendimiento en el nivel de base de datos o contenedor en Azure Portal. Los términos "base de datos" y "contenedor" que se mencionan en estos artículos se asignan a "espacio" y "tabla", respectivamente, en la API de Cassandra.
La ventaja de este método es que es una forma sencilla de administrar la capacidad de rendimiento de la base de datos. Sin embargo, el inconveniente es que, en muchos casos, el enfoque de escalado puede requerir que ciertos niveles de automatización sean tanto económicos como de alto rendimiento. En las secciones siguientes se explican los escenarios y métodos pertinentes.
Uso del plano de control
La API de Azure Cosmos DB para Cassandra ofrece la posibilidad de ajustar el rendimiento mediante programación con nuestras diversas características de plano de control. Puede encontrar instrucciones y ejemplos en los artículos sobre Azure Resource Manager, PowerShell y la CLI de Azure.
La ventaja de este método es que se puede automatizar el escalado o la reducción vertical de los recursos en función de un temporizador para tener en cuenta la actividad máxima o los períodos de baja actividad. Consulte aquí un ejemplo sobre cómo hacerlo con Azure Functions y PowerShell.
Uno de los inconvenientes de este enfoque podría ser que no puede responder a las necesidades cambiantes e imprevisibles de escalado en tiempo real. En su lugar, es posible que tenga que recurrir al contexto de la aplicación dentro del sistema o en el nivel de cliente o SDK, o bien utilizar Escalabilidad automática.
Uso de consultas de CQL con un SDK específico
Puede escalar el sistema de forma dinámica con código mediante la ejecución de los comandos CQL ALTER para la base de datos o el contenedor dados.
La ventaja de este enfoque es que permite responder a las necesidades de escalado de forma dinámica y de una manera personalizada que se adapte a su aplicación. Con este enfoque, todavía puede aprovechar los cargos y tarifas estándar de RU/s. Si las necesidades de escalado del sistema son en su mayoría predecibles (alrededor del 70 % o más), el uso del SDK con CQL puede ser un método más rentable de escalado automático que utilizar la escalabilidad automática. El inconveniente de este enfoque es que puede ser bastante complejo implementar los reintentos, al tiempo que la limitación de frecuencia puede aumentar la latencia.
Uso del rendimiento aprovisionado de escalabilidad automática
Además de aprovisionar el rendimiento de forma estándar (manual) o mediante programación, puede configurar contenedores de Azure Cosmos DB en el rendimiento aprovisionado de escalabilidad automática. La escalabilidad automática escalará el sistema de forma automática e instantánea en función de las necesidades de consumo dentro de los intervalos de RU especificados sin poner en peligro los Acuerdos de Nivel de Servicio. Para más información, consulte este artículo sobre la creación de contenedores y bases de datos de Azure Cosmos DB en escalabilidad automática.
La ventaja de este enfoque es que es la forma más fácil de administrar las necesidades de escalado del sistema. No se aplicará la limitación de velocidad dentro de los intervalos de RU configurados. El inconveniente es que, si las necesidades de escalado del sistema son predecibles, la escalabilidad automática puede resultar menos rentable a la hora de administrar las necesidades de escalado que el uso del plano de control o el nivel de SDK mencionados anteriormente.
Para establecer o modificar el rendimiento máximo (RU) para el escalado automático con CQL, use lo siguiente (reemplazando el nombre de Keyspace o tabla según corresponda):
# to set max throughput (RUs) for autoscale at keyspace level:
create keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at keyspace level:
alter keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=4000;
# to set max throughput (RUs) for autoscale at table level:
create table <keyspace name>.<table name> (pk int PRIMARY KEY, ck int) WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at table level:
alter table <keyspace name>.<table name> WITH cosmosdb_autoscale_max_throughput=4000;
Pasos siguientes
- Introducción a la creación de una cuenta de la API para Cassandra, una base de datos y una tabla mediante una aplicación de Java