Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Casandra
Casandra ![]() Gremlin
Gremlin ![]() Tabla
Tabla
Azure Cosmos DB es una base de datos independiente del esquema que le permite iterar en su aplicación sin tener que gestionar esquemas o índices. De forma predeterminada, Azure Cosmos DB indexa automáticamente todas las propiedades de todos los elementos de su contenedor sin tener que definir ningún esquema ni configurar índices secundarios.
El objetivo de este artículo es explicar cómo Azure Cosmos DB indexa datos y cómo usa índices para mejorar el rendimiento de las consultas. Se recomienda revisar esta sección antes de explorar cómo personalizar las directivas de indexación.
De elementos a árboles
Cada vez que un elemento se almacena en un contenedor, su contenido se proyecta como un documento JSON y luego se convierte en una representación de árbol. Esta conversión significa que todas las propiedades de ese elemento se representan como nodos de un árbol. Para todas las propiedades de primer nivel del elemento, se crea un pseudonodo raíz como elemento primario. Los nodos hoja contienen los valores escalares reales pertenecientes a un elemento.
Por ejemplo, considere este elemento:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Este árbol representa el elemento JSON de ejemplo:
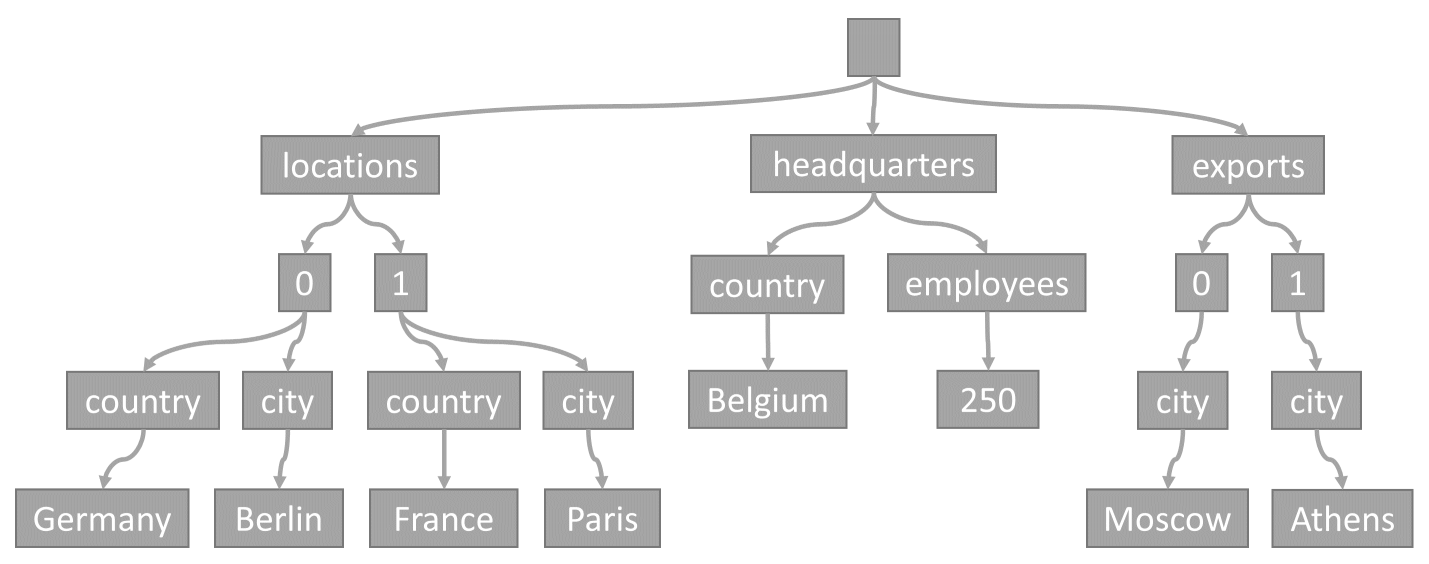
Observe cómo se codifican las matrices en el árbol: cada entrada de una matriz obtiene un nodo intermedio etiquetado con el índice de esa entrada dentro de la matriz (0, 1, etc.).
De árboles a rutas de acceso de propiedades
El motivo por el que Azure Cosmos DB transforma los elementos en árboles es porque permite que el sistema haga referencia a las propiedades mediante sus rutas de acceso dentro de esos árboles. Para obtener la ruta de acceso de una propiedad, podemos recorrer el árbol desde el nodo raíz hasta esa propiedad y concatenar las etiquetas de cada nodo recorrido.
Estas son las rutas de acceso de cada propiedad del elemento de ejemplo descrito anteriormente:
/locations/0/country: "Alemania"/locations/0/city: "Berlín"/locations/1/country: "Francia"/locations/1/city: "París"/headquarters/country: "Bélgica"/headquarters/employees: 250/exports/0/city: "Moscú"/exports/1/city: "Atenas"
Azure Cosmos DB indexa eficazmente la ruta de acceso de cada propiedad y su valor correspondiente cuando se escribe un elemento.
Tipos de índice
Actualmente, Azure Cosmos DB admite tres tipos de índices. Puede configurar estos tipos de índice al definir la directiva de indexación.
Índice de rangos
Los índices de Rango se basan en una estructura ordenada en forma de árbol. El tipo de índice de rango se usa para:
Consultas de igualdad:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Coincidencia de igualdad en un elemento de matriz
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Consultas por rango:
SELECT * FROM container c WHERE c.property > 'value'Nota
(funciona para
>,<,>=,<=,!=).Comprobación de la presencia de una propiedad:
SELECT * FROM c WHERE IS_DEFINED(c.property)Funciones del sistema de cadena:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYconsultas:SELECT * FROM container c ORDER BY c.propertyJOINconsultas:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Los índices de rango se pueden usar en valores escalares (cadena o número). La directiva de indexación predeterminada para los contenedores recién creados exige que se usen índices de intervalo para todas las cadenas o números. Para obtener información sobre cómo configurar los índices de rango, consulte los ejemplos de la directiva de indexación de rangos.
Nota
Una cláusula ORDER BY que ordena por una sola propiedad siempre necesita un índice de rango y dará error si la ruta de acceso a la que hace referencia no tiene uno. Del mismo modo, una consulta ORDER BY que se ordena por varias propiedades siempre necesita un índice compuesto.
Índice espacial
Los índices espaciales permiten realizar consultas eficaces en objetos geoespaciales como puntos, líneas, polígonos y multipolígonos. Estas consultas usan las palabras clave ST_DISTANCE, ST_WITHIN, ST_INTERSECTS. A continuación se muestran algunos ejemplos que usan el tipo de índice espacial:
Consultas de distancia geoespacial
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Información geoespacial dentro de consultas:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Consultas de intersección geoespacial:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Los índices espaciales pueden usarse en objetos GeoJSON con un formato correcto. Actualmente, se admiten Points, LineStrings, Polygons y MultiPolygons. Para obtener información sobre cómo configurar los índices espaciales, vea ejemplos de la directiva de indexación espacial.
Índices compuestos
Los índices compuestos aumentan la eficacia al realizar operaciones en varios campos. El tipo de índice compuesto se usa con:
ORDER BYconsultas en varias propiedades:SELECT * FROM container c ORDER BY c.property1, c.property2Consultas con un filtro y
ORDER BY. Estas consultas pueden emplear un índice compuesto si la propiedad de filtro se agrega a la cláusulaORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Consultas con un filtro en dos o más propiedades en las que al menos una propiedad es un filtro de igualdad
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Siempre y cuando un predicado de filtro use un tipo de índice, el motor de consultas evalúa ese primero antes de examinar el resto. Por ejemplo, si tiene una consulta SQL como SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
La consulta anterior primero filtrará las entradas en las que firstName = "Andrew" mediante el índice. A continuación, pasa todas las entradas firstName = "Andrew" a través de una canalización posterior para evaluar el predicado de filtro CONTAINS.
Puede acelerar las consultas y evitar exámenes completos de contenedores al usar funciones que realizan un examen completo como CONTAINS. Puede agregar más predicados de filtro que usen el índice para acelerar estas consultas. El orden de las cláusulas de filtro no es importante. El motor de consultas averigua qué predicados son más selectivos y ejecuta la consulta en consecuencia.
Para obtener información sobre cómo configurar los índices compuestos, consulte los ejemplos de la directiva de indexación compuesta.
Índices vectoriales
Los índices vectoriales aumentan la eficacia al realizar búsquedas vectoriales mediante la función del sistema VectorDistance. Las búsquedas de vectores tendrán una latencia significativamente menor, un mayor rendimiento y un menor consumo de RU al aprovechar un índice vectorial. Azure Cosmos DB for NoSQL admite cualquier inserción de vectores (texto, imagen, subred, etc.) con un tamaño de 4096 dimensiones.
Para obtener información sobre cómo configurar los índices vectoriales, consulte los ejemplos de la directiva de indexación de vectores.
ORDER BYconsultas de búsqueda vectorial:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Proyección de la puntuación de similitud en las consultas del vector de búsqueda:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filtros de rango en la puntuación de similitud.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Importante
Actualmente, las directivas de vectores y los índices vectoriales son inmutables después de la creación. Para realizar cambios, cree una nueva colección.
Uso de índices
El motor de consultas tiene cinco maneras de evaluar los filtros de consulta, ordenados del más eficaz al menos eficaz:
- Búsqueda de índice
- Escaneo preciso del índice
- Examen expandido del índice
- Examen completo del índice
- Escaneo completo
Al indexar las rutas de acceso de propiedad, el motor de consultas usa automáticamente el índice de la manera más eficaz posible. Además de indexar nuevas rutas de acceso de propiedades, no es necesario configurar nada para optimizar la forma en que las consultas usan el índice. El cargo de RU de una consulta es una combinación del cargo de RU desde el uso del índice y el cargo de RU desde la carga de elementos.
En esta tabla se resumen las distintas formas en que se usan los índices en Azure Cosmos DB:
| Tipo de búsqueda de índice | Descripción | Ejemplos comunes | Cargo de RU del uso del índice | Cargos de RU por la carga de elementos desde el almacén de datos transaccional |
|---|---|---|---|---|
| Búsqueda de índice | Leer solo los valores indexados necesarios y cargar solo los elementos coincidentes del almacén de datos transaccionales | Filtros de igualdad, IN | Constante por filtro de igualdad | Aumenta en función de la cantidad de elementos en los resultados de la consulta |
| Escaneo preciso del índice | Búsqueda binaria de valores indexados y carga solo de los elementos coincidentes desde el almacén de datos transaccional. | Comparaciones de rangos (>, <, <= o >=), StartsWith | Comparable a la búsqueda de índice, aumenta ligeramente en función de la cardinalidad de las propiedades indexadas | Aumenta en función de la cantidad de elementos en los resultados de la consulta |
| Examen expandido del índice | Búsqueda optimizada (pero menos eficaz que una búsqueda binaria) de valores indexados y carga solo de los elementos coincidentes desde el almacén de datos transaccionales | StartsWith (sin distinción entre mayúsculas y minúsculas), StringEquals (sin distinción entre mayúsculas y minúsculas) | Aumenta ligeramente en función de la cardinalidad de las propiedades indexadas | Aumenta en función de la cantidad de elementos en los resultados de la consulta |
| Examen completo del índice | Lectura de un conjunto distinto de valores indexados y carga solo de los elementos coincidentes desde el almacén de datos transaccionales | Contains, EndsWith, RegexMatch, LIKE | Aumenta de manera lineal en función de la cardinalidad de las propiedades indexadas | Aumenta en función de la cantidad de elementos en los resultados de la consulta |
| Escaneo completo | Carga de todos los elementos del almacén de datos transaccionales | Upper, Lower | N/D | Aumenta en función de la cantidad de elementos del contenedor |
Al escribir consultas, debe usar predicados de filtro que usen el índice de la manera más eficaz posible. Por ejemplo, si en su caso de uso funcionaría StartsWith o Contains, debería optar por StartsWith, porque realiza un examen preciso del índice en lugar de un examen completo del índice.
Detalles de uso del índice
En esta sección, se tratan más detalles sobre cómo las consultas usan los índices. Este nivel de detalle no es necesario para aprender a empezar a trabajar con Azure Cosmos DB, pero se documenta en detalle para satisfacer la curiosidad de los usuarios. Hacemos referencia al elemento de ejemplo que ya se compartió en este documento:
Elementos de ejemplo:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB usa un índice invertido. El índice funciona asignando cada ruta de acceso JSON al conjunto de elementos que contienen ese valor. La asignación de identificadores de elemento se representa en muchas páginas de índice diferentes para el contenedor. Este es un diagrama de ejemplo de un índice invertido para un contenedor que incluye los dos elementos de ejemplo:
| Ruta | Valor | Lista de identificadores de elementos |
|---|---|---|
| /localizaciones/0/país | Alemania | 1 |
| /localizaciones/0/país | Irlanda | 2 |
| /ubicaciones/0/ciudad | Berlín | 1 |
| /locations/0/city | Dublín | 2 |
| /locations/1/país | Francia | 1 |
| /locations/1/ciudad | París | 1 |
| /headquarters/country | Bélgica | 1, 2 |
| /sede/empleados | 200 | 2 |
| /sede/empleados | 250 | 1 |
El índice invertido tiene dos atributos importantes:
- Para una ruta de acceso determinada, los valores se ordenan de manera ascendente. Por lo tanto, el motor de consultas puede procesar
ORDER BYfácilmente desde el índice. - Para una ruta de acceso determinada, el motor de consultas puede examinar el conjunto distinto de valores posibles para identificar las páginas de índice donde hay resultados.
El motor de consultas puede utilizar el índice invertido de cuatro maneras distintas:
Búsqueda de índice
Considere la consulta siguiente:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
El predicado de consulta (filtrado por elementos, donde cualquier ubicación tiene "Francia" como país o región) coincidiría con la ruta resaltada en este diagrama.
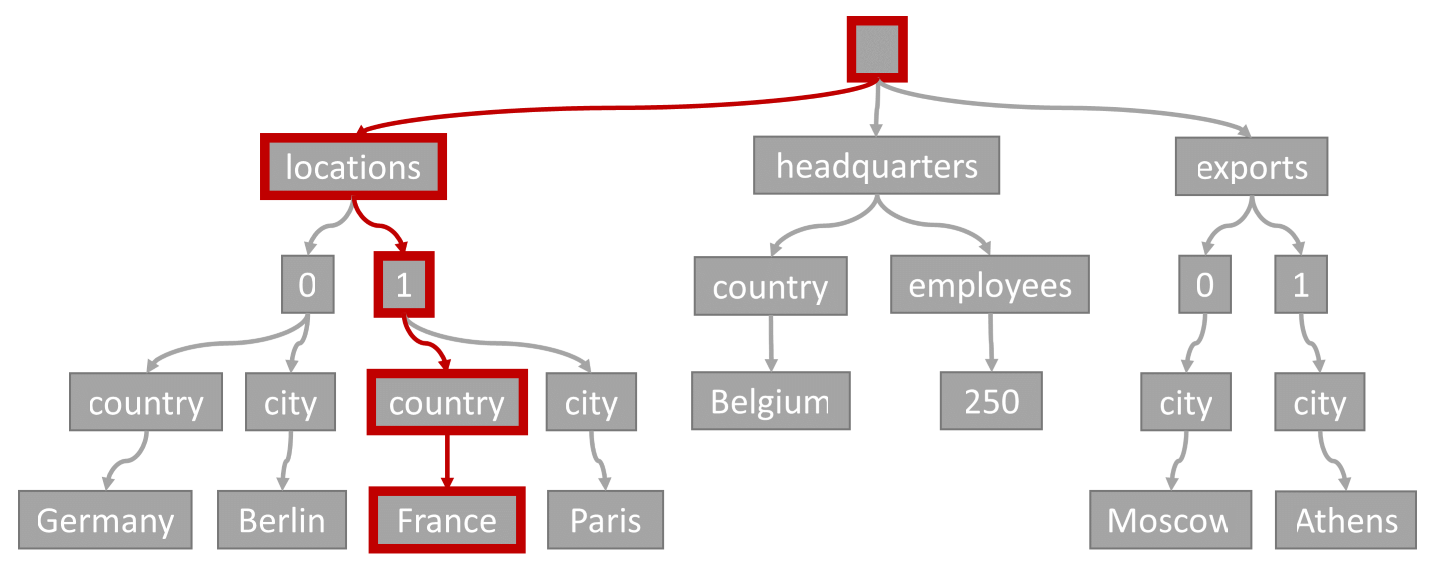
Puesto que esta consulta tiene un filtro de igualdad, después de recorrer este árbol, podemos identificar rápidamente las páginas de índice que contienen los resultados de la consulta. En este caso, el motor de consultas leería las páginas de índice que contienen el elemento 1. Una búsqueda de índice es la manera más eficaz de usar el índice. Con una búsqueda de índice solo se leen las páginas de índice necesarias y solo se cargan los elementos de los resultados de la consulta. Por lo tanto, el tiempo de búsqueda de índice y el cargo por RU de la búsqueda de índice son increíblemente bajos, independientemente del volumen total de los datos.
Escaneo preciso del índice
Considere la consulta siguiente:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
El predicado de consulta (filtrado por elementos en los que hay más de 200 empleados) se puede evaluar con un examen preciso del índice de la ruta de acceso headquarters/employees. Al realizar un examen preciso del índice, el motor de consultas comienza al realizar una búsqueda binaria del conjunto distinto de valores posibles para encontrar la ubicación del valor 200 de la ruta de acceso headquarters/employees. Como los valores de cada ruta de acceso se ordenan de manera ascendente, resulta fácil para el motor de consultas realizar una búsqueda binaria. Una vez que el motor de consultas encuentra el valor 200, comienza a leer todas las páginas de índice restantes (en dirección ascendente).
Debido a que el motor de consultas puede realizar una búsqueda binaria para evitar examinar páginas de índice innecesarias, los exámenes precisos del índice tienden a tener una latencia comparable y cargos por RU para las operaciones de búsqueda de índice.
Examen expandido del índice
Considere la consulta siguiente:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
El predicado de consulta (filtrado por elementos que tienen oficinas centrales en una ubicación que comienza con "United" y que no distingue mayúsculas de minúsculas) se puede evaluar con un examen expandido del índice de la ruta de acceso headquarters/country. Las operaciones que realizan un examen expandido del índice cuentan con optimizaciones que pueden ayudar a evitar la necesidad de examinar cada página de índice, pero son ligeramente más costosas que la búsqueda binaria de un examen preciso del índice.
Por ejemplo, al evaluar StartsWithsin distinción entre mayúsculas y minúsculas, el motor de consultas comprueba el índice para ver diferentes combinaciones posibles de valores en mayúsculas y minúsculas. Esta optimización permite al motor de consultas evitar leer la mayoría de las páginas de índice. Las distintas funciones del sistema tienen optimizaciones diferentes que pueden usar para evitar leer cada página de índice, por lo que las clasificamos ampliamente como un examen expandido del índice.
Examen completo del índice
Considere la consulta siguiente:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
El predicado de consulta (filtrando elementos que tienen sede en una ubicación que incluye "United") se puede evaluar con un análisis de índice de la ruta headquarters/country. A diferencia de un examen preciso del índice, un examen completo del índice siempre examina el conjunto distinto de valores posibles para identificar las páginas de índice donde hay resultados. En este caso, Contains se ejecuta en el índice. El tiempo de búsqueda de índice y el cargo por RU para los exámenes del índice aumentan a medida que aumenta la cardinalidad de la ruta de acceso. En otras palabras, cuanto más valores distintos necesite examinar el motor de consultas, mayores serán la latencia y el cargo por RU implicados en realizar un examen completo del índice.
Por ejemplo, considere dos propiedades: town y country. La cardinalidad de ciudad es 5000 y la de country es 200. A continuación, se muestran dos consultas de ejemplo que tienen una función del sistema Contains que realiza un examen completo del índice en la propiedad town. La primera consulta usa más RUs que la segunda consulta porque la cardinalidad de la ciudad es mayor que country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Escaneo completo
En algunos casos, es posible que el motor de consultas no pueda evaluar un filtro de consulta mediante el índice. En este caso, el motor de consultas debe cargar todos los elementos del almacén transaccional para evaluar el filtro de consulta. Los exámenes completos no usan el índice y tienen un cargo por RU que aumenta linealmente con el tamaño total de los datos. Afortunadamente, las operaciones que requieren exámenes completos son poco frecuentes.
Consultas de búsqueda vectorial sin un índice vectorial definido
Si no define una directiva de índice vectorial y usa la función del sistema VectorDistance en una cláusula ORDER BY, esto dará como resultado un examen completo y tendrá un cargo de RU mayor que si define una directiva de índice vectorial. De forma similar, si usa VectorDistance con el valor booleano de fuerza bruta establecido en true y no tiene un índice flat definido para la ruta vectorial, se realizará un examen completo.
Consultas con expresiones de filtro complejas
En los ejemplos anteriores, solo se tenían en cuenta las consultas que tenían expresiones de filtro simples (por ejemplo, consultas con un solo filtro de igualdad o rango). En realidad, la mayoría de las consultas tienen expresiones de filtro mucho más complejas.
Considere la consulta siguiente:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Para ejecutar esta consulta, el motor de consultas debe realizar una búsqueda de índice en headquarters/employees y un examen completo del índice en headquarters/country. El motor de consultas cuenta con heurística interna que usa para evaluar la expresión de filtro de consulta de la manera más eficaz posible. En este caso, el motor de consultas evitaría tener que leer páginas de índice innecesarias al realizar primero la búsqueda de índice. Por ejemplo, si solo 50 elementos coincidían con el filtro de igualdad, el motor de consultas solo necesitaría evaluar Contains en las páginas de índice que contenían esos 50 elementos. No sería necesario realizar un examen de índice completo de todo el contenedor.
Uso del índice para funciones de agregado escalares
Las consultas con funciones de agregado deben basarse exclusivamente en el índice para poder usarlo.
En algunos casos, el índice puede devolver falsos positivos. Por ejemplo, al evaluar Contains en el índice,el número de coincidencias en el índice puede superar el número de resultados de la consulta. El motor de consultas carga todas las coincidencias de índice, evalúa el filtro en los elementos cargados y devuelve solo los resultados correctos.
Para la mayoría de las consultas, la carga de coincidencias falsas positivas del índice no tiene efecto perceptible en el uso del índice.
Por ejemplo, considere la siguiente consulta:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
La función Contains del sistema puede devolver algunos falsos positivos, por lo que el motor de consultas debe comprobar si cada elemento cargado coincide con la expresión del filtro. En este ejemplo, es posible que el motor de consultas solo necesite cargar algunos elementos adicionales, por lo que el efecto en el uso del índice y el cargo por RU es mínimo.
Sin embargo, las consultas con funciones de agregado deben basarse exclusivamente en el índice para poder usarlo. Por ejemplo, considere la consulta siguiente con un agregado Count:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Al igual que en el primer ejemplo, la función del sistema Contains puede devolver algunas coincidencias de falsos positivos. Sin embargo, a diferencia de la consulta SELECT *, la consulta Count no puede evaluar la expresión de filtro en los elementos cargados para comprobar todas las coincidencias del índice. La consulta Count debe basarse exclusivamente en el índice, por lo que si hay alguna posibilidad de que una expresión de filtro devuelva coincidencias de falsos positivos, el motor de consultas recurre a un examen completo.
Las consultas con las funciones de agregado siguientes deben basarse exclusivamente en el índice, por lo que la evaluación de algunas funciones del sistema requiere un examen completo.
Pasos siguientes
Obtenga más información acerca de la indexación en los siguientes artículos: