Administración de la indexación en Azure Cosmos DB for MongoDB
SE APLICA A: ![]() MongoDB
MongoDB
Azure Cosmos DB for MongoDB aprovecha las funcionalidades de administración de índices principales de Azure Cosmos DB. Este artículo se centra en cómo agregar índices mediante Azure Cosmos DB for MongoDB. Los índices son estructuras de datos especializadas que hacen que la consulta de los datos sea aproximadamente una orden de magnitud más rápida.
Indexación del servidor de MongoDB versión 3.6 y superiores
Azure Cosmos DB para el servidor de MongoDB versión 3.6 y superiores indexa automáticamente el campo _id y la clave de partición (solo en colecciones particionadas). La API aplica automáticamente la unicidad del campo _id por clave de partición.
La API para MongoDB se comporta de forma diferente a Azure Cosmos DB for NoSQL, que indexa todos los campos de manera predeterminada.
Edición de la directiva de indexación
Se recomienda editar la directiva de indexación en Data Explorer en Azure Portal. Puede agregar índices de campo único y comodín desde el editor de directivas de indexación en Data Explorer:
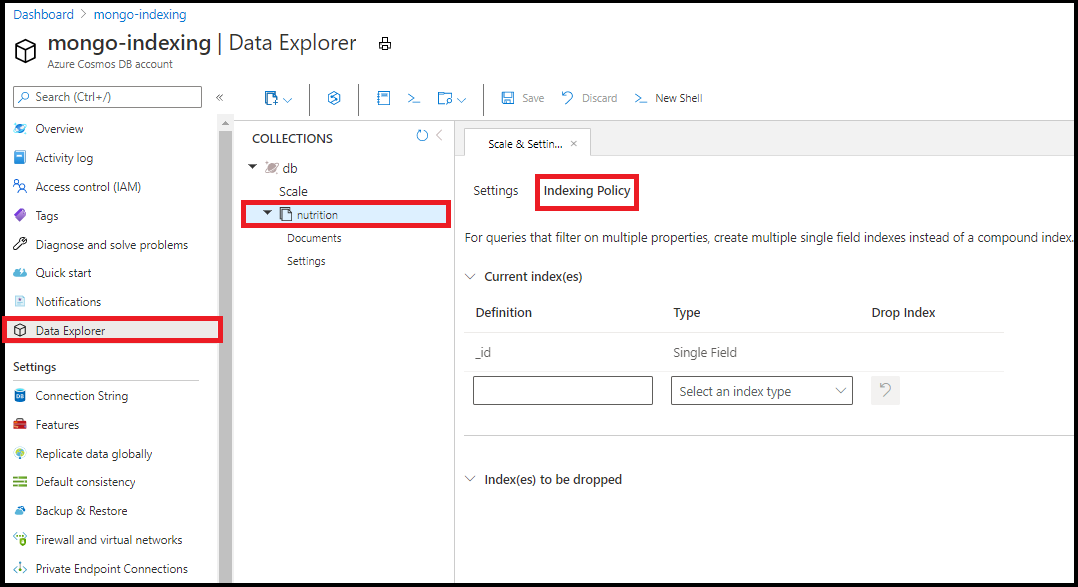
Nota:
No se pueden crear índices compuestos mediante el editor de directivas de indexación en Data Explorer.
Tipos de índice
Campo único
Puede crear índices en cualquier campo único. El criterio de ordenación del índice de campo único no es importante. El comando siguiente crea un índice en el campo name:
db.coll.createIndex({name:1})
Puede crear el mismo índice de campo único en name en Azure Portal:
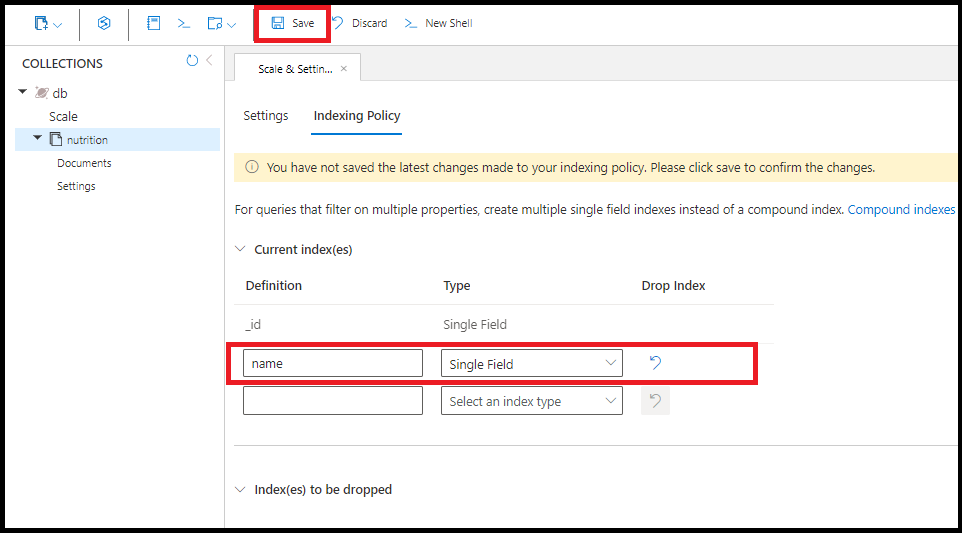
Una consulta utiliza varios índices de campo único, siempre que estén disponibles. Puede crear hasta 500 índices de un solo campo por colección.
Índices compuestos (servidor de MongoDB versión 3.6 y superiores)
En la API para MongoDB, los índices compuestos son obligatorios si su consulta necesita la capacidad de ordenar varios campos a la vez. En el caso de las consultas con varios filtros que no es necesario ordenar, cree varios índices de campo único en lugar de un índice compuesto para ahorrar en costes de indexación.
Tanto un índice compuesto como los índices de campo único para cada campo del índice compuesto producen el mismo rendimiento con vistas al filtrado en consultas.
Los índices compuestos en campos anidados no se admiten de manera predeterminada debido a limitaciones con matrices. Si el campo anidado no contiene una matriz, el índice funcionará según lo previsto. Si el campo anidado contiene una matriz (en cualquier lugar de la ruta de acceso), ese valor se omitirá en el índice.
Por ejemplo, un índice compuesto que contenga people.dylan.age funcionará en este caso, ya que no hay ninguna matriz en la ruta de acceso:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Este mismo índice compuesto no funciona en este caso, ya que hay una matriz en la ruta de acceso:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Esta característica se puede habilitar para la cuenta de base de datos habilitando la funcionalidad "EnableUniqueCompoundNestedDocs".
Nota
No se pueden crear índices compuestos en matrices.
El comando siguiente crea un índice compuesto en los campos name y age:
db.coll.createIndex({name:1,age:1})
Puede utilizar índices compuestos para ordenar de forma eficaz en varios campos a la vez, tal como se muestra en el ejemplo siguiente:
db.coll.find().sort({name:1,age:1})
También se puede usar el índice compuesto anterior para una ordenación eficaz en una consulta con el criterio de ordenación opuesto en todos los campos. Este es un ejemplo:
db.coll.find().sort({name:-1,age:-1})
Sin embargo, la secuencia de las rutas de acceso en el índice compuesto debe coincidir exactamente con la consulta. A continuación se muestra un ejemplo de una consulta que requeriría un índice compuesto adicional:
db.coll.find().sort({age:1,name:1})
Índice de varias claves
Azure Cosmos DB crea índices de varias claves para indexar el contenido almacenado en matrices. Si indexa un campo con un valor de matriz, Azure Cosmos DB indexa automáticamente todos los elementos de la matriz.
Índices geoespaciales
Muchos operadores geoespaciales se beneficiarán de los índices geoespaciales. Actualmente, Azure Cosmos DB for MongoDB admite índices 2dsphere. La API no admite aún índices 2d.
A continuación, se muestra un ejemplo para crear un índice geoespacial en el campo location:
db.coll.createIndex({ location : "2dsphere" })
Índices de texto
Actualmente Azure Cosmos DB for MongoDB no admite los índices de texto. En el caso de las consultas de búsqueda de texto en cadenas, debe usar la integración de Azure AI Search con Azure Cosmos DB.
Índices de caracteres comodín
Puede utilizar índices de caracteres comodín para admitir consultas en campos desconocidos. Supongamos que tiene una colección que contiene datos sobre familias.
A continuación figura una parte de un documento de ejemplo de esa colección:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
A continuación figura otro ejemplo, esta vez con un conjunto de propiedades ligeramente diferente en children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
En esta colección, los documentos pueden tener muchas propiedades posibles diferentes. Si desea indexar todos los datos de la matriz children, tiene dos opciones: crear índices independientes para cada propiedad individual o crear un índice de caracteres comodín para toda la matriz children.
Creación de un índice de caracteres comodín
El siguiente comando crea un índice de caracteres comodín en cualquier propiedad dentro de children:
db.coll.createIndex({"children.$**" : 1})
A diferencia de MongoDB, los índices de caracteres comodín pueden admitir varios campos en predicados de consulta. No habrá ninguna diferencia en el rendimiento de las consultas si se usa un solo índice de caracteres comodín en lugar de crear un índice independiente para cada propiedad.
Puede crear los siguientes tipos de índice mediante la sintaxis de caracteres comodín:
- Campo único
- Geoespaciales
Indexación de todas las propiedades
A continuación se muestra cómo puede crear un índice de caracteres comodín en todos los campos:
db.coll.createIndex( { "$**" : 1 } )
También puede crear índices de caracteres comodín mediante Data Explorer en Azure Portal:
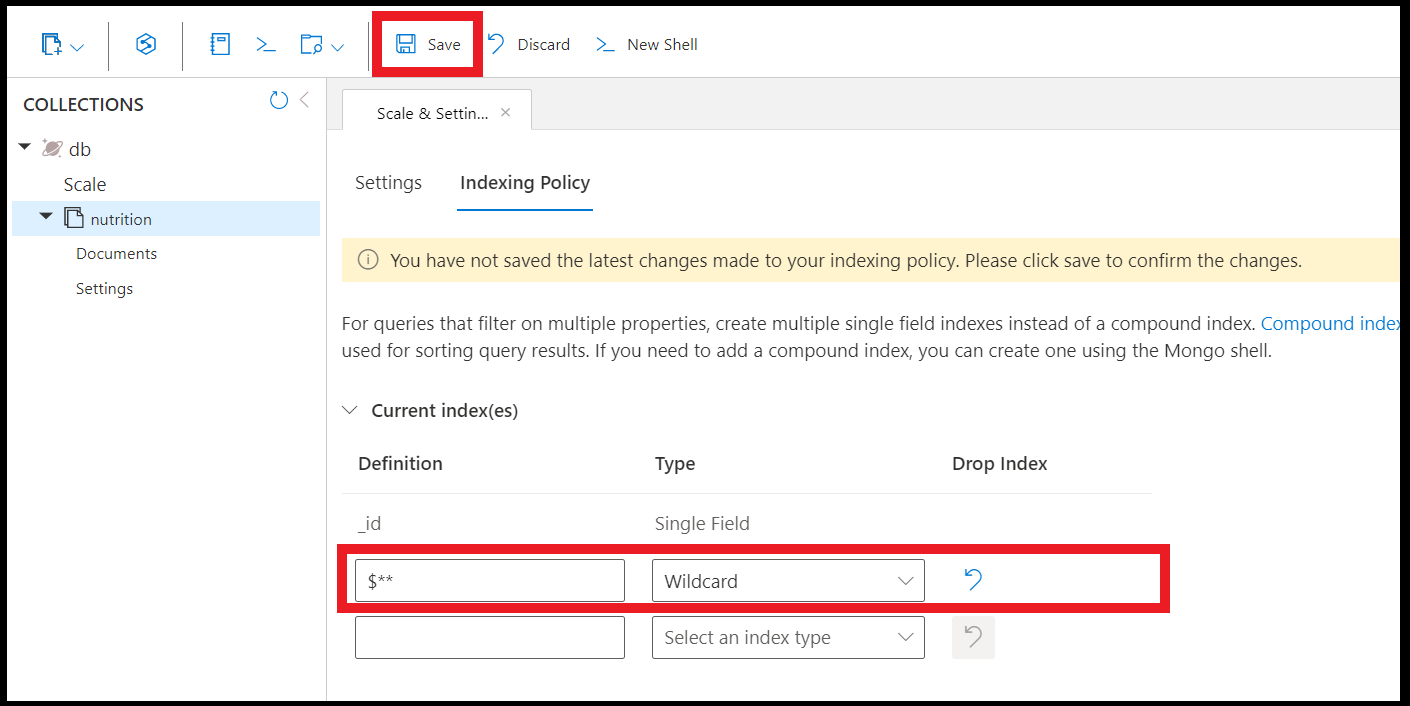
Nota:
Si acaba de empezar a desarrollar, se recomienda encarecidamente empezar con un índice comodín en todos los campos. Esto puede simplificar el desarrollo y facilitar la optimización de las consultas.
Los documentos con muchos campos pueden tener un cargo de unidad de solicitud (RU) elevado para las escrituras y las actualizaciones. Por lo tanto, si tiene una carga de trabajo con muchas operaciones de escritura, debería optar por indexar individualmente las rutas de acceso en lugar de utilizar índices de caracteres comodín.
Nota
La compatibilidad con índices únicos en colecciones existentes con datos está disponible en versión preliminar. Esta característica puede habilitarse para su cuenta de base de datos habilitando la capacidad 'EnableUniqueIndexReIndex'.
Limitaciones
Los índices de caracteres comodín no admiten ninguno de los siguientes tipos o propiedades de índice:
- Compuestos
- TTL
- Único
A diferencia de MongoDB, en Azure Cosmos DB for MongoDB, no puede usar índices de caracteres comodín para:
Crear un índice de caracteres comodín que incluya varios campos específicos
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Crear un índice de caracteres comodín que excluya varios campos específicos
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Como alternativa, puede crear varios índices de caracteres comodín.
Propiedades de índice
Las siguientes operaciones son comunes para las cuentas que atienden la versión 4.0 del protocolo de conexión y para las cuentas que atienden a las versiones anteriores. Puede obtener más información sobre los índices compatibles y las propiedades indexadas.
Índices únicos
Los índices únicos son útiles para exigir que dos o más documentos no contengan el mismo valor para campos indexados.
El comando siguiente crea un índice único en el campo student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
En el caso de colecciones particionadas, debe proporcionar la clave de partición para crear un índice único. En otras palabras, todos los índices únicos de una colección particionada son índices compuestos donde uno de los campos es la clave de partición. El primer campo del orden debe ser la clave de partición.
Los siguientes comandos crean una colección particionada coll (la clave de partición es university) con un índice único en los campos student_id y university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
En el ejemplo anterior, si se omite la cláusula "university":1, se devuelve un error con el mensaje siguiente:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Limitaciones
Los índices únicos deben crearse cuando la colección está vacía.
Los índices únicos en campos anidados no se admiten de manera predeterminada debido a limitaciones con las matrices. Si el campo anidado no contiene una matriz, el índice funcionará según lo previsto. Si su campo anidado contiene una matriz (en cualquier parte de la ruta), ese valor será ignorado en el índice único y la unicidad no será preservada para ese valor.
Por ejemplo, un índice único que en people.tom.age funcionará en este caso, ya que no hay ninguna matriz en la ruta de acceso:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
pero no funcionará en este caso ya que hay una matriz en la ruta:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Esta característica se puede habilitar para la cuenta de base de datos habilitando la funcionalidad "EnableUniqueCompoundNestedDocs".
Índices TTL
Para habilitar la caducidad de documentos en una colección determinada, se debe crear un índice de período de vida (TTL). Un índice TTL es un índice del campo _ts con un valor expireAfterSeconds.
Ejemplo:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
El comando anterior elimina los documentos de la colección db.coll que no se han modificado en los últimos 10 segundos.
Nota:
El campo _ts es específico de Azure Cosmos DB y no es accesible desde los clientes de MongoDB. Es una propiedad reservada (sistema) que contiene la marca de tiempo de la última modificación del documento.
Seguimiento del progreso del índice
La versión 3.6 y posteriores de Azure Cosmos DB for MongoDB admite el comando currentOp() para hacer un seguimiento del progreso del índice en una instancia de base de datos. Este comando devuelve un documento que contiene información sobre las operaciones en curso en una instancia de base de datos. Se usa el comando currentOp para realizar el seguimiento de todas las operaciones en curso en MongoDB nativo. En Azure Cosmos DB for MongoDB, este comando solo admite hacer un seguimiento de la operación de índice.
A continuación, se incluyen algunos ejemplos que muestran cómo usar el comando currentOp para realizar un seguimiento del progreso del índice:
Obtener el progreso del índice de una colección:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Obtener el progreso del índice de todas las colecciones de una base de datos:
db.currentOp({"command.$db": <databaseName>})Obtener el progreso del índice de todas las bases de datos y colecciones de una cuenta de Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Ejemplos de salida del progreso del índice
Los detalles del progreso del índice muestran el porcentaje del progreso de la operación de índice actual. Este es un ejemplo en el que se muestra el formato del documento de salida de las diferentes fases de progreso del índice:
Una operación de índice en una colección "foo" y una base de datos "bar" que está un 60 por ciento completada tendrá el siguiente documento de salida. En el campo
Inprog[0].progress.totalse muestra 100 como el porcentaje de finalización de destino.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Si una operación de índice se acaba de iniciar en una colección "foo" y una base de datos "bar", el documento de salida puede mostrar un 0 por ciento de progreso hasta que llegue a un nivel medible.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Cuando se completa la operación de índice en curso, el documento de salida muestra operaciones
inprogvacías.{ "inprog" : [], "ok" : 1 }
Actualizaciones de índices en segundo plano
Independientemente del valor especificado para la propiedad Background del índice, las actualizaciones de los índices siempre se hacen en segundo plano. Dado que las actualizaciones de índice consumen unidades de solicitud (RU) con una prioridad más baja que otras operaciones de base de datos, los cambios de índice no darán lugar a tiempo de inactividad para las escrituras, actualizaciones o eliminaciones.
No afecta a la disponibilidad de lectura al agregar un índice nuevo. Las consultas solo utilizarán nuevos índices una vez completada la transformación del índice. Durante la transformación del índice, el motor de consulta seguirá usando los índices existentes, por lo que observará un rendimiento de lectura similar durante la transformación de indexación al que observó antes de iniciar el cambio de indexación. Al agregar índices nuevos, tampoco hay riesgo de resultados de consulta incompletos o incoherentes.
Al quitar índices y ejecutar consultas de inmediato que tienen filtros en los índices quitados, es posible que los resultados sean incoherentes e incompletos hasta que finalice la transformación del índice. Si quita los índices, el motor de consultas no proporciona resultados coherentes o completos cuando las consultas filtran los índices recién quitados. La mayoría de los desarrolladores no coloca los índices e intenta ejecutar consultas que los usan de inmediato, por lo que, en la práctica, esta situación es poco probable.
Nota:
Comando ReIndex
El comando reIndex volverá a crear todos los índices de una colección. En algunos casos excepcionales, el rendimiento de las consultas u otros problemas de índice de la colección pueden resolverse ejecutando el comando reIndex. Si tiene problemas con la indexación, se recomienda volver a crear los índices con el comando reIndex.
Puede ejecutar el comando reIndex con la siguiente sintaxis:
db.runCommand({ reIndex: <collection> })
Puede usar la sintaxis siguiente para comprobar si la ejecución del comando reIndex mejoraría el rendimiento de las consultas en la colección:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Resultados del ejemplo:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Si reIndex mejorará el rendimiento de las consultas, requiresReIndex será true. Si reIndex no mejora el rendimiento de las consultas, se omitirá esta propiedad.
Migración de colecciones con índices
Actualmente, solo se pueden crear índices únicos cuando la colección no contiene documentos. Las herramientas de migración de MongoDB más populares intentan crear los índices únicos después de importar los datos. Para sortear este problema, puede crear manualmente las colecciones y los índices únicos correspondientes en lugar de permitir que la herramienta de migración lo intente. (Puede lograr este comportamiento para mongorestore mediante el uso de la marca --noIndexRestore en la línea de comandos).
Indexación de MongoDB versión 3.2
Las características de indexación disponibles y los valores predeterminados son diferentes para las cuentas de Azure Cosmos DB que son compatibles con la versión 3.2 del protocolo de conexión de MongoDB. Puede comprobar la versión de la cuenta y actualizar a la versión 3.6.
Si usa la versión 3.2, en esta sección se describen las diferencias principales que tiene con la versión 3.6 y posteriores.
Eliminación de índices predeterminados (versión 3.2)
A diferencia de las versiones 3.6 y posteriores de Azure Cosmos DB for MongoDB, la versión 3.2 indexa todas las propiedades de manera predeterminada. Puede usar el comando siguiente para eliminar estos índices predeterminados de una colección (coll):
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Después de colocar los índices predeterminados, puede agregar más índices, tal como se hace en la versión 3.6 y posteriores.
Índices compuestos (versión 3.2)
Los índices compuestos contienen referencias a varios campos de un documento. Si quiere crear un índice compuesto, actualice a la versión 3.6 o 4.0.
Índices de caracteres comodín (versión 3.2)
Si quiere crear un índice de caracteres comodín, actualice a la versión 4.0 o 3.6.
Pasos siguientes
- Indexación en Azure Cosmos DB
- Expiración automática de los datos de Azure Cosmos DB con período de vida
- Para información sobre la relación entre las particiones y la indexación, consulte el artículo Consulta de un contenedor de Azure Cosmos DB.
- ¿Intenta planear la capacidad de una migración a Azure Cosmos DB? Para ello, puede usar información sobre el clúster de bases de datos existente.
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, consulte la información sobre el cálculo de unidades de solicitud mediante núcleos virtuales o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de