Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Azure Cosmos DB para PostgreSQL ya no se admite para nuevos proyectos. No use este servicio para nuevos proyectos. En su lugar, use uno de estos dos servicios:
Utilice Azure Cosmos DB para NoSQL para una solución de base de datos distribuida diseñada para grandes escenarios con un contrato de nivel de servicio (SLA) de disponibilidad del 99,999%, escalabilidad automática instantánea y conmutación automática por error en varias regiones.
Utiliza la característica de Clústeres elásticos de Azure Database For PostgreSQL para PostgreSQL particionado utilizando la extensión Citus de código abierto.
Antes de investigar los pasos para crear una nueva aplicación, resulta útil ver una introducción rápida de los términos y conceptos implicados.
Introducción a la arquitectura
Azure Cosmos DB for PostgreSQL proporciona la capacidad de distribuir tablas y esquemas entre varias máquinas de un clúster y consultarlas de forma transparente de la misma forma que se consulta PostgreSQL sin formato:
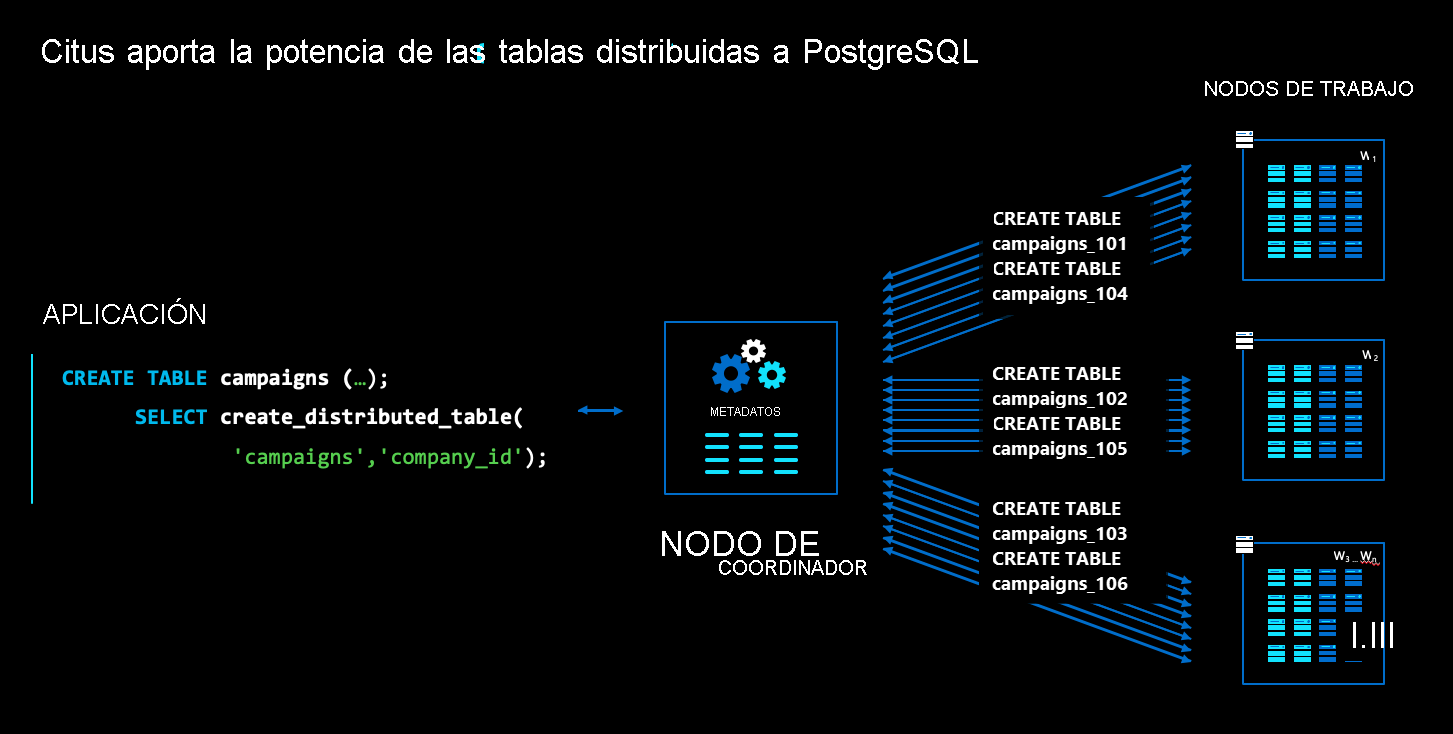
En la arquitectura de Azure Cosmos DB for PostgreSQL, hay varios tipos de nodos:
- El nodo de coordinación almacena los metadatos de la tabla distribuida y es responsable de la planificación distribuida.
- Por el contrario, los nodos de procesamiento almacenan los datos reales, los metadatos y realizan el cálculo.
- Tanto el coordinador como los trabajadores son bases de datos PostgreSQL estándar, con la extensión
cituscargada.
Para distribuir una tabla de PostgreSQL normal, como campaigns en el diagrama anterior, puede ejecutar un comando denominado create_distributed_table(). Una vez ejecutado este comando, Azure Cosmos DB for PostgreSQL crea particiones de forma transparente para la tabla entre nodos de trabajo. En el diagrama, las particiones se representan como recuadros azules.
Para distribuir un esquema de PostgreSQL normal, ejecute el comando citus_schema_distribute(). Una vez ejecutado este comando, Azure Cosmos DB for PostgreSQL convierte de forma transparente las tablas de dichos esquemas en tablas colocadas en una única partición que se puede mover como una unidad entre los nodos del clúster.
Nota:
En un clúster sin nodos de trabajo, las particiones de las tablas distribuidas se encuentran en el nodo de coordinación.
Las particiones son tablas de PostgreSQL sin formato (pero con un nombre especial) que contienen segmentos de los datos. En nuestro ejemplo, dado que distribuimos campaigns por company_id, las particiones contienen campañas y las campañas de empresas diferentes se asignan a particiones diferentes.
Columna de distribución (también conocida como clave de partición)
create_distributed_table() es la función mágica que proporciona Azure Cosmos DB for PostgreSQL, para distribuir tablas y usar recursos entre varias máquinas.
SELECT create_distributed_table(
'table_name',
'distribution_column');
El segundo argumento anterior elige una columna de la tabla como columna de distribución. Puede ser cualquier columna con un tipo de PostgreSQL nativo (entero y texto son los más habituales). El valor de la columna de distribución determina qué filas van a cada partición, por lo que la columna de distribución también se denomina clave de partición.
Azure Cosmos DB for PostgreSQL decide cómo ejecutar las consultas en función del uso de la clave de partición:
| La consulta implica | Dónde se ejecuta |
|---|---|
| solo una clave de partición | en el nodo de trabajo que contiene su partición |
| varias claves de partición | en paralelo entre varios nodos |
La elección de la clave de partición determina el rendimiento y la escalabilidad de las aplicaciones.
- La distribución de datos desigual por claves de partición (también conocida como asimetría de datos) no es óptima para el rendimiento. Por ejemplo, no elija una columna para la que un único valor represente el 50 % de los datos.
- Las claves de partición con una cardinalidad baja pueden afectar a la escalabilidad. Solo puede usar tantos fragmentos como haya valores de clave distintos. Elija una clave con cardinalidad en los cientos o miles.
- La combinación de dos tablas grandes con claves de partición diferentes puede ser lenta. Elija una clave de partición común en las tablas grandes. Obtenga más información en colocation.
Coubicación
Otro concepto estrechamente relacionado con la clave de partición es la coubicación. Las tablas particionadas por los mismos valores de columna de distribución se coubican: las particiones de las tablas coubicadas se almacenan juntas en los mismos trabajos.
A continuación se muestran dos tablas particionadas por la misma clave, site_id. Están coubicadas.
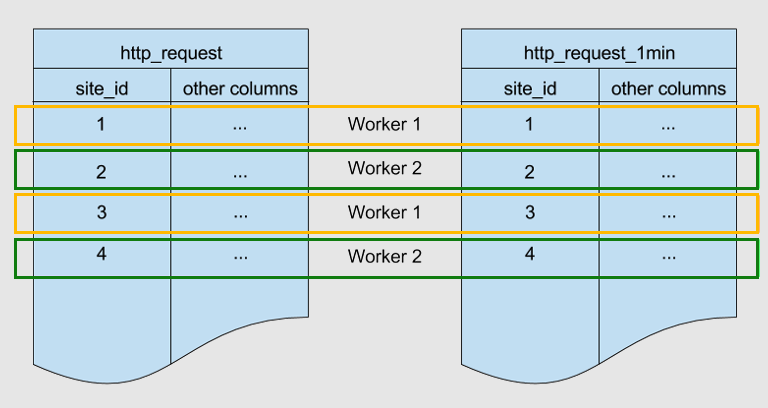
Azure Cosmos DB for PostgreSQL garantiza que las filas con un valor site_id coincidente en ambas tablas se almacenan en el mismo nodo de trabajo. Puede ver que, para ambas tablas, las filas con site_id=1 se almacenan en trabajador 1. Esto ocurre de forma similar para otros identificadores de sitio.
La coubicación ayuda a optimizar las operaciones JOIN entre estas tablas. Si combina las dos tablas en site_id, Azure Cosmos DB for PostgreSQL puede realizar la combinación localmente en los nodos de trabajo sin transferir los datos entre los nodos.
Las tablas dentro de un esquema distribuido siempre se colocan entre sí.