Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Azure Cosmos DB para PostgreSQL se encuentra en una ruta de retirada y ya no se recomienda para los nuevos proyectos. En su lugar, use uno de estos dos servicios:
Para cargas de trabajo de PostgreSQL: use la función Clústeres elásticos de Azure Database for PostgreSQL para aprovechar las características de PostgreSQL distribuidas y de escalabilidad horizontal contenidas en la extensión Citus de código abierto. Para obtener instrucciones sobre la migración, consulte migrar a Azure Database for PostgreSQL con Elastic Cluster.
En el caso de las cargas de trabajo NoSQL, use Azure Cosmos DB para NoSQL para una solución de base de datos distribuida que incluya un acuerdo de nivel de servicio (SLA) de disponibilidad del 99.999%, autoescalado instantáneo y conmutación automática por error en varias regiones.
En este tutorial, usará Azure Cosmos DB for PostgreSQL como back-end de almacenamiento para varios microservicios, mostrando una configuración de ejemplo y una operación básica de este clúster. Obtenga información sobre cómo:
- Crear un clúster
- Creación de roles para los microservicios
- Uso de la utilidad psql para crear roles y esquemas distribuidos
- Creación de tablas para los servicios de ejemplo
- Configurar servicios
- Ejecución de servicios
- Exploración de la base de datos
Prerequisites
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Crear un clúster
Inicie sesión en Azure Portal y siga estos pasos para crear un clúster de Azure Cosmos DB for PostgreSQL:
Vaya a Crear un clúster de Azure Cosmos DB for PostgreSQL en Azure Portal.
En el formulario Crear un clúster de Azure Cosmos DB for PostgreSQL:
Rellene la información de la pestaña Aspectos básicos.
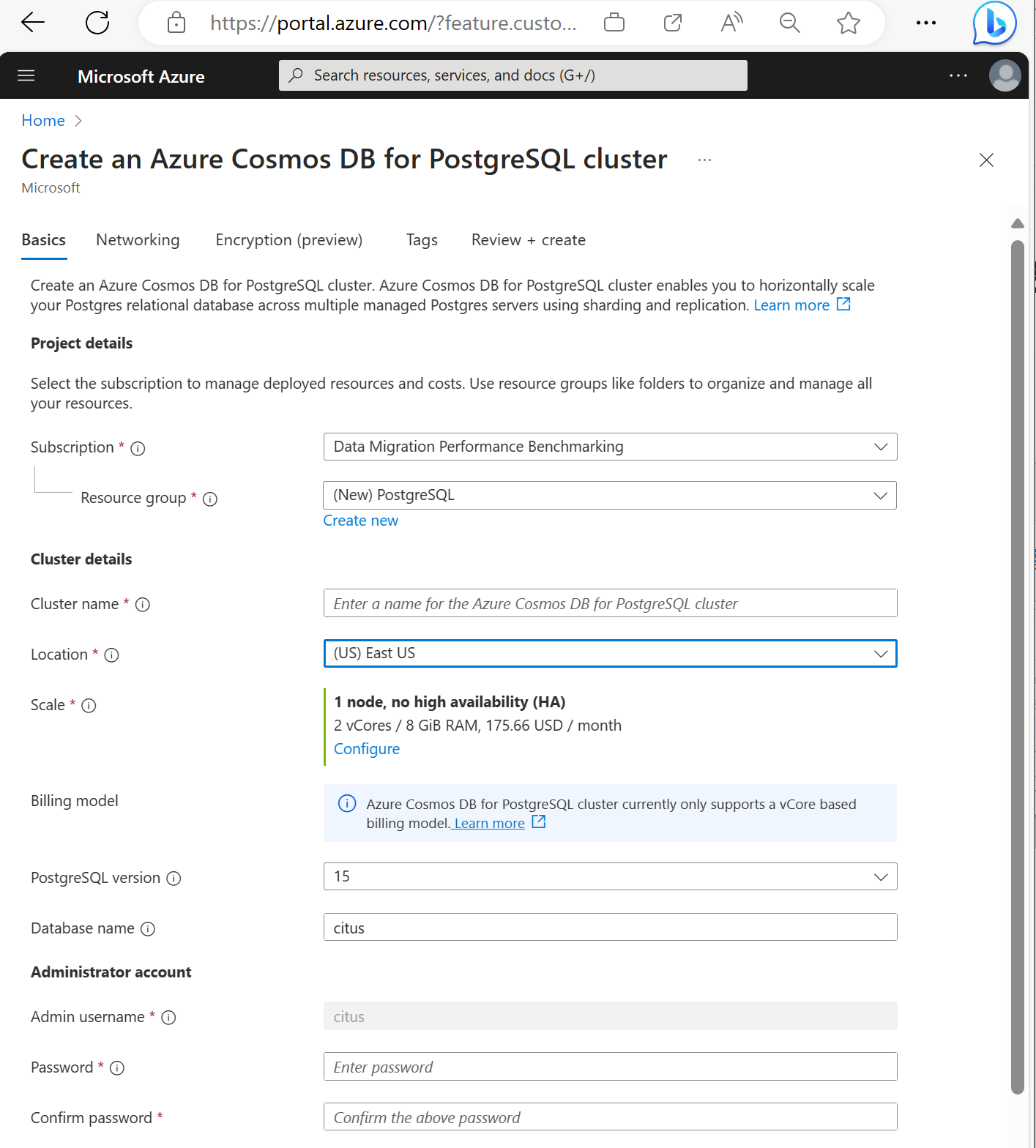
La mayoría de las opciones son autoexplicativas, pero tenga en cuenta lo siguiente:
- El nombre del clúster determina el nombre DNS que usan las aplicaciones para conectarse, con el formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Puede elegir una versión principal de PostgreSQL, como la 15. Azure Cosmos DB for PostgreSQL siempre admite la versión más reciente de Citus para la versión principal de Postgres seleccionada.
- Es necesario que el nombre de usuario administrador sea el valor
citus. - Puede dejar el nombre de la base de datos en su valor predeterminado "citus" o definir el único nombre de la base de datos. No se puede cambiar el nombre de la base de datos después del aprovisionamiento del clúster.
- El nombre del clúster determina el nombre DNS que usan las aplicaciones para conectarse, con el formato
Seleccione Siguiente: Redes en la parte inferior de la pantalla.
En la pantalla Redes, seleccione Permitir el acceso público desde los servicios y recursos de Azure dentro de Azure a este clúster.
Seleccione Revisar y crear y, cuando se supere la validación, elija Crear para crear el clúster.
El aprovisionamiento tarda unos minutos. La página redirige a la implementación de supervisión. Cuando el estado cambie de Implementación en curso a Se completó la implementación, seleccione Ir al recurso.
Creación de roles para los microservicios
Los esquemas distribuidos se pueden reasignar dentro de un clúster de Azure Cosmos DB for PostgreSQL. El sistema puede reequilibrarlos como una unidad completa en los nodos disponibles, lo que permite compartir recursos de forma eficaz sin asignación manual.
Por diseño, los microservicios poseen su capa de almacenamiento, no realizamos ninguna suposición sobre el tipo de tablas y datos que crean y almacenan. Proporcionamos un esquema para cada servicio y suponemos que usan un rol distinto para conectarse a la base de datos. Cuando un usuario se conecta, el nombre de su rol se coloca al principio del search_path, por lo que si el rol coincide con el nombre de esquema, no necesita ningún cambio en la aplicación para establecer el search_path correcto.
Usamos tres servicios en nuestro ejemplo:
- user
- time
- ping
Siga los pasos que describen cómo crear roles de usuario y crear los siguientes roles para cada servicio:
userservicetimeservicepingservice
Uso de la utilidad psql para crear esquemas distribuidos
Una vez conectado a Azure Cosmos DB for PostgreSQL mediante psql, puede completar algunas tareas básicas.
Hay dos maneras de distribuir un esquema en Azure Cosmos DB for PostgreSQL:
Manualmente llamando a la función citus_schema_distribute(schema_name):
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
Este método también permite convertir esquemas normales existentes en esquemas distribuidos.
Note
Solo puede distribuir esquemas que no contengan tablas distribuidas y de referencia.
El enfoque alternativo consiste en habilitar la variable de configuración citus.enable_schema_based_sharding:
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
La variable se puede cambiar para la sesión actual o permanentemente en los parámetros del nodo de coordinación. Con el parámetro establecido en ON, todos los esquemas creados se distribuyen de forma predeterminada.
Puede enumerar los esquemas distribuidos actualmente mediante la ejecución de:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
Creación de tablas para los servicios de ejemplo
Ahora debe conectarse a Azure Cosmos DB for PostgreSQL para cada microservicio. Puede usar el comando \c para intercambiar el usuario dentro de una instancia de psql existente.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
Configurar servicios
En este tutorial, usamos un conjunto sencillo de servicios. Puede obtenerlos mediante la clonación de este repositorio público:
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
Antes de ejecutar los servicios, edite los archivos user/app.py, ping/app.py y time/app.pyque proporcionan la configuración de conexión para el clúster de Azure Cosmos DB for PostgreSQL:
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
Después de realizar los cambios, guarde todos los archivos modificados y continúe con el siguiente paso de ejecución de los servicios.
Ejecución de servicios
Cambie a cada directorio de la aplicación y ejecútelos en su propio entorno de Python.
cd user
pipenv install
pipenv shell
python app.py
Repita los comandos para el servicio de hora y ping, después de lo cual puede usar la API.
Cree algunos usuarios:
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
Enumere los usuarios creados:
curl http://localhost:5000/users
Obtenga la hora actual:
Get current time:
Ejecute el ping en example.com:
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
Exploración de la base de datos
Ahora que ha llamado a algunas funciones de API, los datos se han almacenado y puede comprobar si citus_schemas refleja lo que se espera:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
Al crear los esquemas, no se le dijo a Azure Cosmos DB for PostgreSQL en qué máquinas crear los esquemas. Esto se realiza de forma automática. Puede ver dónde reside cada esquema con la siguiente consulta:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
Para mayor brevedad de la salida de ejemplo en esta página, en lugar de usar nodename tal como se muestra en Azure Cosmos DB for PostgreSQL, lo reemplazamos por localhost. Supongamos que localhost:9701 es el trabajo uno y localhost:9702 es el trabajo dos. Los nombres de nodo del servicio administrado son más largos y contienen elementos aleatorios.
Puede ver que el servicio de hora ha llegado al nodo localhost:9701 mientras el usuario y el servicio ping comparten espacio en el segundo trabajo localhost:9702. Las aplicaciones de ejemplo son simplistas y los tamaños de datos aquí son insignificantes, pero supongamos que está molesto por el uso desigual del espacio de almacenamiento entre los nodos. Tendría más sentido tener los dos servicios de ping y tiempo más pequeños residiendo en una máquina mientras que el servicio de usuario grande reside solo.
Puede reequilibrar fácilmente el clúster por tamaño de disco:
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
Cuando haya terminado, puede comprobar cómo se ve nuestro nuevo diseño:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
Según las expectativas, los esquemas se han movido y tenemos un clúster más equilibrado. Esta operación ha sido transparente para las aplicaciones. Ni siquiera necesita reiniciarlas, seguirán atendiendo consultas.
Pasos siguientes
En este tutorial, ha aprendido a crear esquemas distribuidos y a ejecutar microservicios usándolos como almacenamiento. También ha aprendido a explorar y administrar particiones basadas en esquemas de Azure Cosmos DB for PostgreSQL.
- Más información sobre los tipos de nodo de clúster