Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Use la búsqueda de vectores en Azure Cosmos DB con la biblioteca cliente de Python. Almacene y consulte los datos vectoriales de forma eficaz en las aplicaciones.
En este inicio rápido se usa un conjunto de datos de hotel de ejemplo en un archivo JSON con vectores del modelo text-embeding-3-small . El conjunto de datos incluye nombres de hotel, ubicaciones, descripciones e incrustaciones vectoriales.
Busque el código de ejemplo con el aprovisionamiento de recursos en GitHub.
Prerequisites
Una suscripción de Azure
- Si no tiene ninguna suscripción a Azure, cree una cuenta gratuita
Acceso a un plano de datos de recursos de Azure Cosmos DB existente
- Si no tiene un recurso, cree un nuevo recurso.
- Firewall configurado para permitir el acceso a la dirección IP del cliente
- Roles de control de acceso basado en roles (RBAC) asignados:
- Colaborador de datos integrado de Cosmos DB (plano de datos)
- Id. de rol:
00000000-0000-0000-0000-000000000002
-
- Dominio personalizado configurado
- Rol de control de acceso basado en roles (RBAC) asignado:
- Usuario de OpenAI de Cognitive Services
- Id. de rol:
5e0bd9bd-7b93-4f28-af87-19fc36ad61bd
-
text-embedding-3-smallmodelo implementado
Creación de un archivo de datos con vectores
Cree un directorio de datos para el archivo de datos de hoteles:
mkdir dataDescargue el archivo de datos raw con vectores en el directorio
data:curl -o data/HotelsData_toCosmosDB_Vector.json https://raw.githubusercontent.com/Azure-Samples/cosmos-db-vector-samples/refs/heads/main/data/HotelsData_toCosmosDB_Vector.json
Creación de un proyecto de Python
Cree un nuevo directorio relacionado para el proyecto, en el mismo nivel que el directorio de datos y ábralo en Visual Studio Code:
mkdir vector-search-quickstart code vector-search-quickstartEn el terminal, cree y active un entorno virtual Python:
python -m venv .venvsource .venv/bin/activateCree un
requirements.txtarchivo en la raíz del proyecto con el siguiente contenido:azure-cosmos>=4.7.0 azure-identity>=1.18.0 openai>=1.57.0 python-dotenv>=1.0.1Instale los paquetes necesarios:
pip install -r requirements.txt- azure-cosmos: biblioteca cliente de Azure Cosmos DB para las operaciones de base de datos
- azure-identity: biblioteca de autenticación de Azure para conexiones sin contraseña (identidad administrada)
- openai : SDK de OpenAI para generar incrustaciones con Azure OpenAI
-
python-dotenv : carga variables de entorno desde un
.envarchivo
Cree un
.envarchivo en la raíz del proyecto para las variables de entorno:# Identity for local developer authentication with Azure CLI AZURE_TOKEN_CREDENTIALS=AzureCliCredential # Azure OpenAI Embedding Settings AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small AZURE_OPENAI_EMBEDDING_API_VERSION=2024-08-01-preview AZURE_OPENAI_EMBEDDING_ENDPOINT= # Cosmos DB configuration AZURE_COSMOSDB_ENDPOINT= # Data file DATA_FILE_WITH_VECTORS=../data/HotelsData_toCosmosDB_Vector.json FIELD_TO_EMBED=Description EMBEDDED_FIELD=DescriptionVector EMBEDDING_DIMENSIONS=1536Reemplace los valores de marcador de posición del
.envarchivo por su propia información:-
AZURE_OPENAI_EMBEDDING_ENDPOINT: dirección URL del punto de conexión de recursos de Azure OpenAI -
AZURE_COSMOSDB_ENDPOINT: dirección URL del punto de conexión de Azure Cosmos DB
-
Descripción del esquema del documento
Antes de compilar la aplicación, comprenda cómo se almacenan los vectores en los documentos de Azure Cosmos DB. Cada documento de hotel contiene:
-
Campos estándar:
HotelId,HotelName,Description,Category, etc. -
Campo vectorial:
DescriptionVector: matriz de 1536 números de punto flotante que representa el significado semántico de la descripción del hotel.
Este es un ejemplo simplificado de una estructura de documento de hotel:
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "This classic hotel is fully-refurbished...",
"Rating": 3.6,
"DescriptionVector": [
-0.04886505,
-0.02030743,
0.01763356,
...
// 1536 dimensions total
]
}
Puntos clave sobre el almacenamiento de incrustaciones:
- Las matrices vectoriales se almacenan como matrices JSON estándar en los documentos
-
La directiva de vector define la ruta de acceso (
/DescriptionVector), el tipo de datos (float32), las dimensiones (1536) y la función de distancia (coseno) - La directiva de indexación crea un índice vectorial en el campo vectorial para una búsqueda eficaz de similitud
- El campo vectorial debe excluirse de la indexación estándar para optimizar el rendimiento de inserción.
Estas directivas se definen en las plantillas de Bicep para las métricas de distancia de este proyecto de ejemplo. Para más información sobre las directivas de vectores y la indexación, consulte Búsqueda de vectores en Azure Cosmos DB.
Creación de archivos de código para la búsqueda vectorial
Cree un directorio src para los archivos de Python. Agregue dos archivos: vector_search.py y utils.py para la implementación de búsqueda vectorial:
mkdir src
touch src/__init__.py
touch src/vector_search.py
touch src/utils.py
Creación de código para la búsqueda de vectores
Pegue el código siguiente en el vector_search.py archivo.
"""Azure Cosmos DB NoSQL Vector Search — main entry point.
Loads hotel data, bulk-inserts into the selected container (DiskANN or
QuantizedFlat), generates a query embedding via Azure OpenAI, and
executes a VectorDistance() similarity search.
"""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
sys.path.insert(0, str(Path(__file__).parent))
from utils import (
get_clients_passwordless,
get_clients,
insert_data,
print_search_results,
read_file_return_json,
validate_field_name,
get_query_activity_id,
)
# ---------------------------------------------------------------------------
# Load environment
# ---------------------------------------------------------------------------
load_dotenv()
ALGORITHM_CONFIGS: dict[str, dict[str, str]] = {
"diskann": {
"container_name": "hotels_diskann",
"algorithm_name": "DiskANN",
},
"quantizedflat": {
"container_name": "hotels_quantizedflat",
"algorithm_name": "QuantizedFlat",
},
}
def _build_config() -> dict[str, str | int]:
"""Build runtime configuration from environment variables."""
return {
"query": "quintessential lodging near running trails, eateries, retail",
"db_name": os.getenv("AZURE_COSMOSDB_DATABASENAME", "Hotels"),
"algorithm": os.getenv("VECTOR_ALGORITHM", "diskann").strip().lower(),
"data_file": os.getenv("DATA_FILE_WITH_VECTORS", "../data/HotelsData_toCosmosDB_Vector.json"),
"embedded_field": os.getenv("EMBEDDED_FIELD", "DescriptionVector"),
"embedding_dimensions": int(os.getenv("EMBEDDING_DIMENSIONS", "1536")),
"deployment": os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "text-embedding-3-small"),
"distance_function": os.getenv("VECTOR_DISTANCE_FUNCTION", "cosine"),
}
def main() -> None:
"""Run the vector search demonstration."""
config = _build_config()
# Try passwordless auth first, fall back to key-based
clients = get_clients_passwordless()
if not clients["ai_client"] or not clients["db_client"]:
clients = get_clients()
ai_client = clients["ai_client"]
db_client = clients["db_client"]
try:
algorithm = config["algorithm"]
if algorithm not in ALGORITHM_CONFIGS:
valid = ", ".join(ALGORITHM_CONFIGS)
raise ValueError(
f"Invalid algorithm '{algorithm}'. Must be one of: {valid}"
)
if not ai_client:
raise RuntimeError(
"Azure OpenAI client is not configured. "
"Please check your environment variables."
)
if not db_client:
raise RuntimeError(
"Cosmos DB client is not configured. "
"Please check your environment variables."
)
algo_cfg = ALGORITHM_CONFIGS[algorithm]
container_name = algo_cfg["container_name"]
database = db_client.get_database_client(config["db_name"])
print(f"Connected to database: {config['db_name']}")
container = database.get_container_client(container_name)
print(f"Connected to container: {container_name}")
print(f"\n📊 Vector Search Algorithm: {algo_cfg['algorithm_name']}")
print(f"📏 Distance Function: {config['distance_function']}")
# Verify the container exists
try:
container.read()
except Exception as e:
status_code = getattr(e, "status_code", None)
if status_code == 404:
raise RuntimeError(
f"Container or database not found. Ensure database "
f"'{config['db_name']}' and container '{container_name}' "
f"exist before running this script."
) from e
raise
data_path = Path(__file__).parent.parent / config["data_file"]
data = read_file_return_json(str(data_path))
insert_data(container, data)
embedding_response = ai_client.embeddings.create(
model=config["deployment"],
input=[config["query"]],
)
query_embedding = embedding_response.data[0].embedding
safe_field = validate_field_name(config["embedded_field"])
query_text = (
f"SELECT TOP 5 c.HotelName, c.Description, c.Rating, "
f"VectorDistance(c.{safe_field}, @embedding) AS SimilarityScore "
f"FROM c "
f"ORDER BY VectorDistance(c.{safe_field}, @embedding)"
)
print("\n--- Executing Vector Search Query ---")
print(f"Query: {query_text}")
print(
f"Parameters: @embedding (vector with {len(query_embedding)} dimensions)"
)
print("--------------------------------------\n")
results = list(
container.query_items(
query=query_text,
parameters=[{"name": "@embedding", "value": query_embedding}],
enable_cross_partition_query=True,
)
)
# Extract diagnostics
response_headers = container.client_connection.last_response_headers
activity_id = get_query_activity_id(response_headers)
if activity_id:
print(f"Query activity ID: {activity_id}")
request_charge_raw = response_headers.get("x-ms-request-charge", "0") if response_headers else "0"
try:
request_charge = float(request_charge_raw)
except (ValueError, TypeError):
request_charge = 0.0
print_search_results(results, request_charge)
except Exception as error:
print(f"App failed: {error}", file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
main()
Este código:
- Configura un algoritmo vectorial
DiskANNoquantizedFlata partir de variables de entorno. - Se conecta a Azure OpenAI y Azure Cosmos DB mediante la autenticación sin contraseña.
- Carga datos de hoteles pre vectorizados desde un archivo JSON.
- Inserta datos en el contenedor adecuado.
- Genera una inserción para una consulta de lenguaje natural (
quintessential lodging near running trails, eateries, retail). - Ejecuta una
VectorDistanceconsulta SQL para recuperar los 5 hoteles más semánticamente similares clasificados por puntuación de similitud. - Gestiona errores para clientes ausentes, selección de algoritmos inválida, y contenedores o bases de datos no existentes.
Descripción del código: Generación de incrustaciones con Azure OpenAI
El código crea incrustaciones para el texto de consulta:
embedding_response = ai_client.embeddings.create(
model=config["deployment"], # OpenAI embedding model, e.g. "text-embedding-3-small"
input=[config["query"]], # List of description strings to embed
)
query_embedding = embedding_response.data[0].embedding
Esta llamada API de OpenAI para client.embeddings.create convierte texto como "hospedaje quintessential cerca de senderos para correr" en un vector de 1536 dimensiones que captura su significado semántico. Para más información sobre cómo generar incrustaciones, consulte la documentación sobre incrustaciones de Azure OpenAI.
Descripción del código: Almacenamiento de vectores en Azure Cosmos DB
Todos los documentos con matrices vectoriales se insertan mediante la upsert_item función :
for item in data:
doc = {"id": item["HotelId"], **item}
response = container.upsert_item(body=doc)
Esto inserta los documentos del hotel, incluidas sus matrices DescriptionVector pregeneradas, en el contenedor. Cada documento obtiene un id campo asignado desde HotelIdy la función controla upserts para que los documentos se puedan volver a insertar de forma segura.
Descripción del código: Ejecutar búsqueda de similitud de vectores
El código realiza una búsqueda vectorial mediante la VectorDistance función :
query_text = (
f"SELECT TOP 5 c.HotelName, c.Description, c.Rating, "
f"VectorDistance(c.{safe_field}, @embedding) AS SimilarityScore "
f"FROM c "
f"ORDER BY VectorDistance(c.{safe_field}, @embedding)"
)
results = list(
container.query_items(
query=query_text,
parameters=[{"name": "@embedding", "value": query_embedding}],
enable_cross_partition_query=True,
)
)
Este código crea una consulta SQL parametrizada que usa la función VectorDistance para comparar el vector de inserción de la consulta (@embedding) con el campo de vector almacenado de cada documento (DescriptionVector), devolviendo los 5 hoteles principales con su nombre y puntuación de similitud, ordenados de la mayoría similares a los menos similares. El embedding de la consulta se pasa como un parámetro para evitar la inyección y procede de una llamada anterior a OpenAI embeddings.create en Azure.
Lo que devuelve esta consulta:
- Top 5 hoteles más similares basados en la distancia vectorial
- Propiedades del hotel:
HotelName,Description,Rating -
SimilarityScore: un valor numérico que indica la similitud de cada hotel con la consulta. - Resultados ordenados de la mayoría similares a los menos similares
Para obtener más información sobre la VectorDistance función, consulte la documentación de VectorDistance.
Creación de funciones de utilidad
Pegue el código siguiente en utils.py:
"""Shared utilities for Azure Cosmos DB NoSQL vector search.
Provides client initialization (passwordless and key-based), JSON I/O,
bulk insert with RU tracking, field validation, and result formatting.
"""
import json
import os
import re
import time
from typing import Any, Optional
def get_clients() -> dict[str, Any]:
"""Get Azure OpenAI and Cosmos DB clients using key-based authentication.
Returns dict with 'ai_client' and 'db_client' (either may be None if
the required environment variables are missing).
"""
from azure.cosmos import CosmosClient
from openai import AzureOpenAI
ai_client = None
db_client = None
api_key = os.getenv("AZURE_OPENAI_EMBEDDING_KEY", "")
api_version = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "")
endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT", "")
deployment = os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "")
if api_key and api_version and endpoint and deployment:
ai_client = AzureOpenAI(
api_key=api_key,
api_version=api_version,
azure_endpoint=endpoint,
azure_deployment=deployment,
)
cosmos_endpoint = os.getenv("AZURE_COSMOSDB_ENDPOINT", "")
cosmos_key = os.getenv("AZURE_COSMOSDB_KEY", "")
if cosmos_endpoint and cosmos_key:
db_client = CosmosClient(url=cosmos_endpoint, credential=cosmos_key)
return {"ai_client": ai_client, "db_client": db_client}
def get_clients_passwordless() -> dict[str, Any]:
"""Get Azure OpenAI and Cosmos DB clients using DefaultAzureCredential.
Uses managed identity / Azure CLI credentials for passwordless auth.
Returns dict with 'ai_client' and 'db_client' (either may be None).
"""
from azure.cosmos import CosmosClient
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from openai import AzureOpenAI
ai_client = None
db_client = None
api_version = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "")
endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT", "")
deployment = os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "")
if api_version and endpoint and deployment:
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
credential, "https://cognitiveservices.azure.com/.default"
)
ai_client = AzureOpenAI(
api_version=api_version,
azure_endpoint=endpoint,
azure_deployment=deployment,
azure_ad_token_provider=token_provider,
)
cosmos_endpoint = os.getenv("AZURE_COSMOSDB_ENDPOINT", "")
if cosmos_endpoint:
credential = DefaultAzureCredential()
db_client = CosmosClient(url=cosmos_endpoint, credential=credential)
return {"ai_client": ai_client, "db_client": db_client}
def read_file_return_json(file_path: str) -> list[dict[str, Any]]:
"""Read a JSON file and return its parsed contents."""
print(f"Reading JSON file from {file_path}")
try:
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
except FileNotFoundError:
print(f"Error: File '{file_path}' not found")
raise
except json.JSONDecodeError as e:
print(f"Error: Invalid JSON in file '{file_path}': {e}")
raise
def write_file_json(file_path: str, json_data: Any) -> None:
"""Serialize data to a JSON file."""
try:
with open(file_path, "w", encoding="utf-8") as f:
json.dump(json_data, f, indent=2, ensure_ascii=False)
print(f"Wrote JSON file to {file_path}")
except IOError as e:
print(f"Error writing to file '{file_path}': {e}")
raise
def _get_document_count(container: Any) -> int:
"""Return the number of documents in a Cosmos DB container."""
query = "SELECT VALUE COUNT(1) FROM c"
results = list(container.query_items(query=query, enable_cross_partition_query=True))
return results[0] if results else 0
def insert_data(
container: Any, data: list[dict[str, Any]]
) -> dict[str, Any]:
"""Bulk-insert documents into a Cosmos DB container.
Skips insertion if the container already has documents.
Each item gets an 'id' field mapped from 'HotelId'.
Returns a dict with total, inserted, failed, skipped, and requestCharge.
"""
existing_count = _get_document_count(container)
if existing_count > 0:
print(f"Container already has {existing_count} documents. Skipping insert.")
return {
"total": 0,
"inserted": 0,
"failed": 0,
"skipped": existing_count,
"requestCharge": 0.0,
}
print(f"Inserting {len(data)} items...")
inserted = 0
failed = 0
total_request_charge = 0.0
start_time = time.time()
for item in data:
doc = {"id": item["HotelId"], **item}
try:
response = container.upsert_item(body=doc)
inserted += 1
ru = _extract_ru_from_headers(container.client_connection.last_response_headers)
total_request_charge += ru
except Exception as e:
status_code = getattr(e, "status_code", None)
if status_code == 409:
inserted += 1
else:
failed += 1
print(f" Insert failed for item {item.get('HotelId', '?')}: {e}")
duration = time.time() - start_time
print(f"Bulk insert completed in {duration:.2f}s")
print(f"\nInsert Request Charge: {total_request_charge:.2f} RUs\n")
return {
"total": len(data),
"inserted": inserted,
"failed": failed,
"skipped": 0,
"requestCharge": total_request_charge,
}
def _extract_ru_from_headers(headers: Optional[dict[str, str]]) -> float:
"""Extract the request charge (RU) from Cosmos DB response headers."""
if not headers:
return 0.0
raw = headers.get("x-ms-request-charge", "0")
try:
return float(raw)
except (ValueError, TypeError):
return 0.0
def validate_field_name(field_name: str) -> str:
"""Validate a field name is a safe SQL identifier.
Prevents NoSQL injection when interpolating field names into queries.
Allows only letters, digits, and underscores; must start with a letter
or underscore.
Raises ValueError if the field name is invalid.
"""
pattern = re.compile(r"^[A-Za-z_][A-Za-z0-9_]*$")
if not pattern.match(field_name):
raise ValueError(
f'Invalid field name: "{field_name}". '
"Field names must start with a letter or underscore and "
"contain only letters, numbers, and underscores."
)
return field_name
def print_search_results(
search_results: list[dict[str, Any]],
request_charge: Optional[float] = None,
) -> None:
"""Print vector search results in a consistent format."""
print("\n--- Search Results ---")
if not search_results:
print("No results found.")
return
for i, result in enumerate(search_results, 1):
score = result.get("SimilarityScore", 0.0)
name = result.get("HotelName", "Unknown")
print(f"{i}. {name}, Score: {score:.4f}")
if request_charge is not None:
print(f"\nVector Search Request Charge: {request_charge:.2f} RUs")
print("")
def get_query_activity_id(response_headers: Optional[dict[str, str]]) -> Optional[str]:
"""Extract the activity ID from Cosmos DB query response headers."""
if not response_headers:
return None
return response_headers.get("x-ms-activity-id")
def get_bulk_operation_rus(headers: Optional[dict[str, str]]) -> float:
"""Extract total RU cost from Cosmos DB response headers."""
return _extract_ru_from_headers(headers)
Este módulo de utilidad proporciona estas funciones clave :
-
get_clients_passwordless: crea y devuelve clientes para Azure OpenAI y Azure Cosmos DB mediante la autenticación sin contraseña. Habilite RBAC en los recursos e inicie sesión en CLI de Azure -
insert_data: inserta datos en un contenedor de Azure Cosmos DB y realiza un seguimiento de unidades de solicitud (RU) para cada operación. -
print_search_results: imprime los resultados de una búsqueda vectorial, incluida la puntuación y el nombre del hotel. -
validate_field_name: valida que existe un nombre de campo en los datos. -
get_bulk_operation_rus: extrae el costo total de RU de los encabezados de respuesta de Azure Cosmos DB
Autenticación con la CLI de Azure
Inicie sesión en la CLI de Azure antes de ejecutar la aplicación para que la aplicación pueda acceder a los recursos de Azure de forma segura.
az login
El código utiliza tu autenticación de desarrollador local para acceder a Azure Cosmos DB y Azure OpenAI con la función get_clients_passwordless desde utils.py. Al establecer AZURE_TOKEN_CREDENTIALS=AzureCliCredential, se selecciona deterministamente qué credencial DefaultAzureCredential usa de su cadena de credenciales. La función se basa en DefaultAzureCredential de azure-identity, que recorre una cadena ordenada de proveedores de credenciales, pero respeta la variable de entorno para resolver primero CLI de Azure credenciales. Obtenga más información sobre cómo autenticar aplicaciones de Python en servicios de Azure mediante la biblioteca de identidades de Azure.
Ejecutar la aplicación
Use la variable de VECTOR_ALGORITHM entorno para seleccionar la implementación del índice vectorial que se va a ejecutar. La variable controla a qué Azure Cosmos DB contenedor se conecta la aplicación.
Linux/macOS:
VECTOR_ALGORITHM=diskann python -m src.vector_search
Windows:
$env:VECTOR_ALGORITHM="diskann"; python -m src.vector_search
El registro y la salida de la aplicación muestran:
- Estado de conexión del contenedor
- Estado de inserción de datos
- Resultados de búsqueda con nombres de hotel y puntuaciones de similitud
Connected to database: Hotels
Connected to container: hotels_diskann
📊 Vector Search Algorithm: DiskANN
📏 Distance Function: cosine
Reading JSON file from ..\data\HotelsData_toCosmosDB_Vector.json
Container already has 50 documents. Skipping insert.
--- Executing Vector Search Query ---
Query: SELECT TOP 5 c.HotelName, c.Description, c.Rating, VectorDistance(c.DescriptionVector, @embedding) AS SimilarityScore FROM c ORDER BY VectorDistance(c.DescriptionVector, @embedding)
Parameters: @embedding (vector with 1536 dimensions)
--------------------------------------
Query activity ID: <ACTIVITY_ID>
--- Search Results ---
1. Royal Cottage Resort, Score: 0.4991
2. Country Comfort Inn, Score: 0.4786
3. Nordick's Valley Motel, Score: 0.4635
4. Economy Universe Motel, Score: 0.4461
5. Roach Motel, Score: 0.4388
Vector Search Request Charge: 5.33 RUs
Métricas de distancia
Azure Cosmos DB admite tres funciones de distancia para la similitud vectorial:
| Función de Distancia | Intervalo de puntuación | Interpretación | Mejor para |
|---|---|---|---|
| Coseno (valor predeterminado) | De 0,0 a 1,0 | Las puntuaciones más altas (más cercanas a 1,0) indican una similitud mayor | Similitud de texto general, incrustaciones de Azure OpenAI (que se usan en este inicio rápido) |
| Euclidano (L2) | De 0,0 a ∞ | Cuanto menor, más similar | Datos espaciales, cuando importa la magnitud |
| Dot Product | -∞ a +∞ | Mayor = más similar | Cuando se normalizan las magnitudes vectoriales |
La función distance se establece en la directiva de inserción de vectores al crear el contenedor. Esto se proporciona en la infraestructura del repositorio de ejemplo. Se define como parte de la definición del contenedor.
{
name: 'hotels_diskann'
partitionKeyPaths: [
'/HotelId'
]
indexingPolicy: {
indexingMode: 'consistent'
automatic: true
includedPaths: [
{
path: '/*'
}
]
excludedPaths: [
{
path: '/_etag/?'
}
{
path: '/DescriptionVector/*'
}
]
vectorIndexes: [
{
path: '/DescriptionVector'
type: 'diskANN'
}
]
}
vectorEmbeddingPolicy: {
vectorEmbeddings: [
{
path: '/DescriptionVector'
dataType: 'float32'
dimensions: 1536
distanceFunction: 'cosine'
}
]
}
}
Este código de Bicep define una configuración de contenedor de Azure Cosmos DB para almacenar documentos de hotel con funcionalidades de búsqueda vectorial.
| Propiedad | Description |
|---|---|
partitionKeyPaths |
Particiona documentos por HotelId para el almacenamiento distribuido. |
indexingPolicy |
Configura la indexación automática en todas las propiedades del documento (/*), excepto en el campo del sistema _etag y la matriz DescriptionVector para optimizar el rendimiento de escritura. Los campos vectoriales no necesitan indexación estándar porque usan una configuración especializada vectorIndexes en su lugar. |
vectorIndexes |
Crea un índice DiskANN o quantizedFlat en la ruta /DescriptionVector para búsquedas de similitud eficaces. |
vectorEmbeddingPolicy |
Define las características del campo vectorial: float32 tipo de datos con 1536 dimensiones (que coinciden con la salida del text-embedding-3-small modelo) y coseno como función de distancia para medir la similitud entre vectores durante las consultas. |
Interpretación de puntuaciones de similitud
En la salida de ejemplo con similitud de coseno:
- 0.4991 (Royal Cottage Resort) - Similitud más alta, mejor coincidencia para "alojamiento cerca de senderos para correr, restaurantes, venta al por menor"
- 0.4388 (Roach Motel) - Similitud inferior, aún relevante pero menos coincidente
- Las puntuaciones más cercanas a 1,0 indican una similitud semántica más fuerte
- Las puntuaciones cercanas a 0 indican poca similitud
Notas importantes:
- Los valores de puntuación absoluta dependen del modelo de inserción y los datos
- Centrarse en la clasificación relativa en lugar de en umbrales absolutos
- Las embeddings de Azure OpenAI funcionan mejor con similitud de coseno
Para obtener información detallada sobre las funciones de distancia, consulte ¿Qué son las funciones de distancia?
Visualización y administración de datos en Visual Studio Code
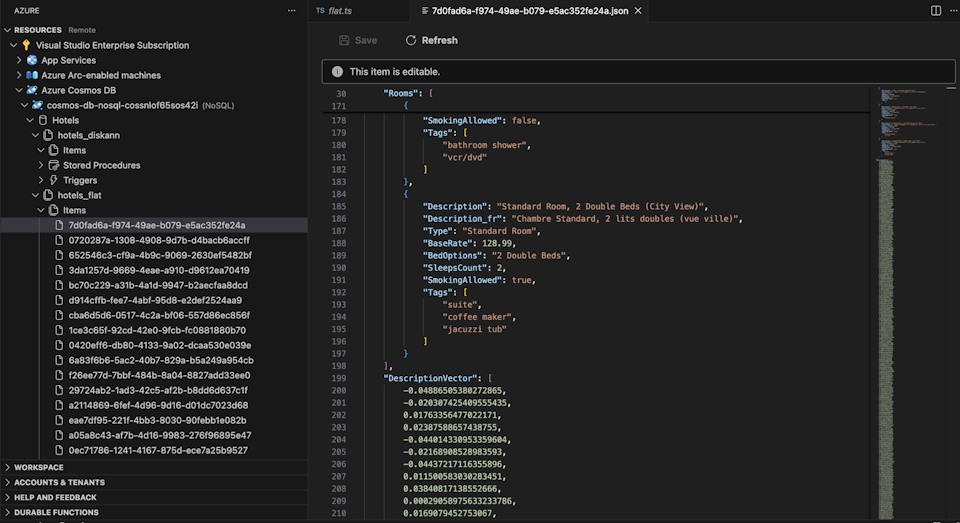
Seleccione la extensión Cosmos DB en Visual Studio Code para conectarse a la cuenta de Azure Cosmos DB.
Vea los datos e índices en la base de datos Hotels.

Limpieza de recursos
Cuando ya no necesite la API para la cuenta NoSQL, puede eliminar el grupo de recursos correspondiente.
Vaya al grupo de recursos que creó anteriormente en el portal de Azure.
Tip
En esta guía de inicio rápido, se recomienda el nombre
msdocs-cosmos-quickstart-rg.Seleccione Eliminar grupo de recursos.
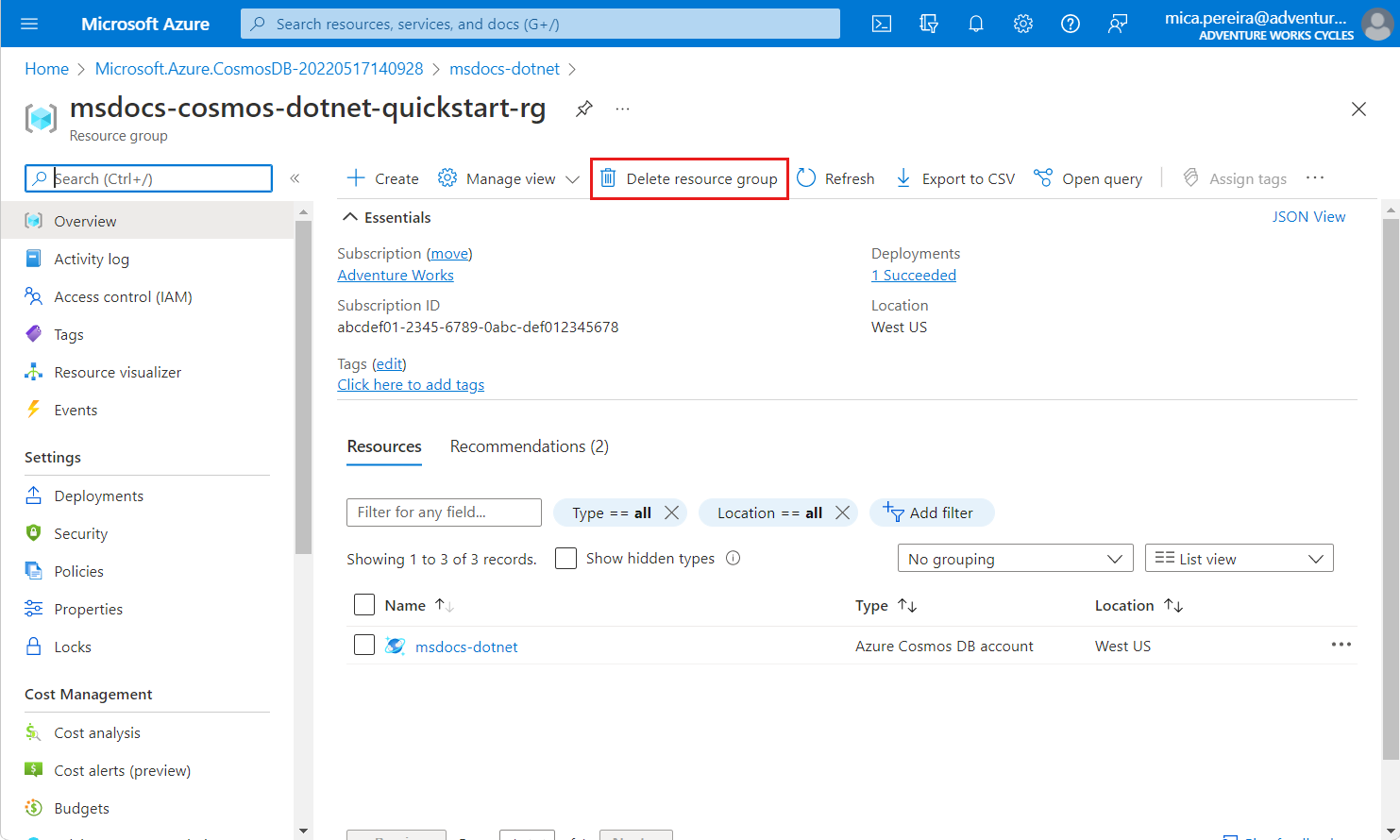
En el cuadro de diálogo ¿Está seguro de que desea eliminar ?, escriba el nombre del grupo de recursos y, a continuación, seleccione Eliminar.