Diagnóstico y solución de problemas de las excepciones de tasa de solicitudes demasiado grande (429) en Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL
Este artículo contiene las causas conocidas y las soluciones de varios errores de código de estado 429 para la API para NoSQL. Si usa la API para MongoDB, consulte el artículo Solución de problemas comunes en API para MongoDB para obtener información sobre cómo depurar el código de estado 16500.
Una excepción de "tasa de solicitudes demasiado grande", también conocida como código de error 429, indica que se limita la tasa de las solicitudes en Azure Cosmos DB.
Cuando se usa el rendimiento aprovisionado, se establece el rendimiento medido en unidades de solicitud por segundo (RU/s) necesario para la carga de trabajo. Las operaciones de base de datos en el servicio, como lecturas, escrituras y consultas, consumen cierto número de unidades de solicitud (RU). Más información sobre las unidades de solicitud.
En un segundo determinado, si las operaciones consumen más que las unidades de solicitud aprovisionadas, Azure Cosmos DB devolverá una excepción 429. Cada segundo, se restablece el número de unidades de solicitud disponibles para su uso.
Antes de realizar una acción para cambiar las RU/s, es importante comprender la causa principal de la limitación de tasa y solucionar el problema subyacente.
Sugerencia
Las instrucciones de este artículo se aplican a las bases de datos y los contenedores que usan el rendimiento aprovisionado: escalado automático y rendimiento manual.
Hay diferentes mensajes de error que corresponden a diferentes tipos de excepciones 429:
- La tasa de solicitudes es alta. Es posible que se necesiten más unidades de solicitud, por lo que no se ha realizado ningún cambio.
- La solicitud no se ha completado debido a una alta tasa de solicitudes de metadatos.
- La solicitud no se ha completado debido a un error transitorio del servicio.
La tasa de solicitudes es grande
Se trata del escenario más habitual. Se produce cuando las unidades de solicitud consumidas por las operaciones en los datos superan el número aprovisionado de RU/s. Si usa el rendimiento manual, se produce cuando se han consumido más RU/s que el rendimiento manual aprovisionado. Si usa el escalado automático, se produce cuando se ha consumido más de la cantidad máxima de RU/s aprovisionadas. Por ejemplo, si tiene un recurso aprovisionado con un rendimiento manual de 400 RU/s, verá el error 429 cuando consuma más de 400 unidades de solicitud en un solo segundo. Si tiene un recurso aprovisionado con un máximo de RU/s de escalabilidad automática de 4000 RU/s (escala entre 400 RU/s y 4000 RU/s), verá 429 respuestas cuando consuma más de 429 unidades de solicitud en un solo segundo.
Sugerencia
Todas las operaciones se cobran en función del número de recursos que consumen. Estos cargos se miden en unidades de solicitud. Estos cargos incluyen solicitudes que no se completan correctamente debido a errores de aplicación como 400, 412, 449, etc. Al examinar la limitación o el uso, es recomendable investigar si algún patrón ha cambiado en su uso que provoque un aumento de estas operaciones. En concreto, compruebe si hay etiquetas 412 o 449 (conflicto real).
Para más información sobre el rendimiento aprovisionado, consulte Rendimiento aprovisionado en Azure Cosmos DB.
Paso 1: Comprobación de las métricas para determinar el porcentaje de solicitudes con el error 429
Consultar los mensajes del error 429 no significa necesariamente que haya un problema con la base de datos o el contenedor. Un pequeño porcentaje de respuestas 429es normal si usa el rendimiento manual o de escalado automático, y es una señal de que está maximizando las RU/s que ha aprovisionado.
Investigación
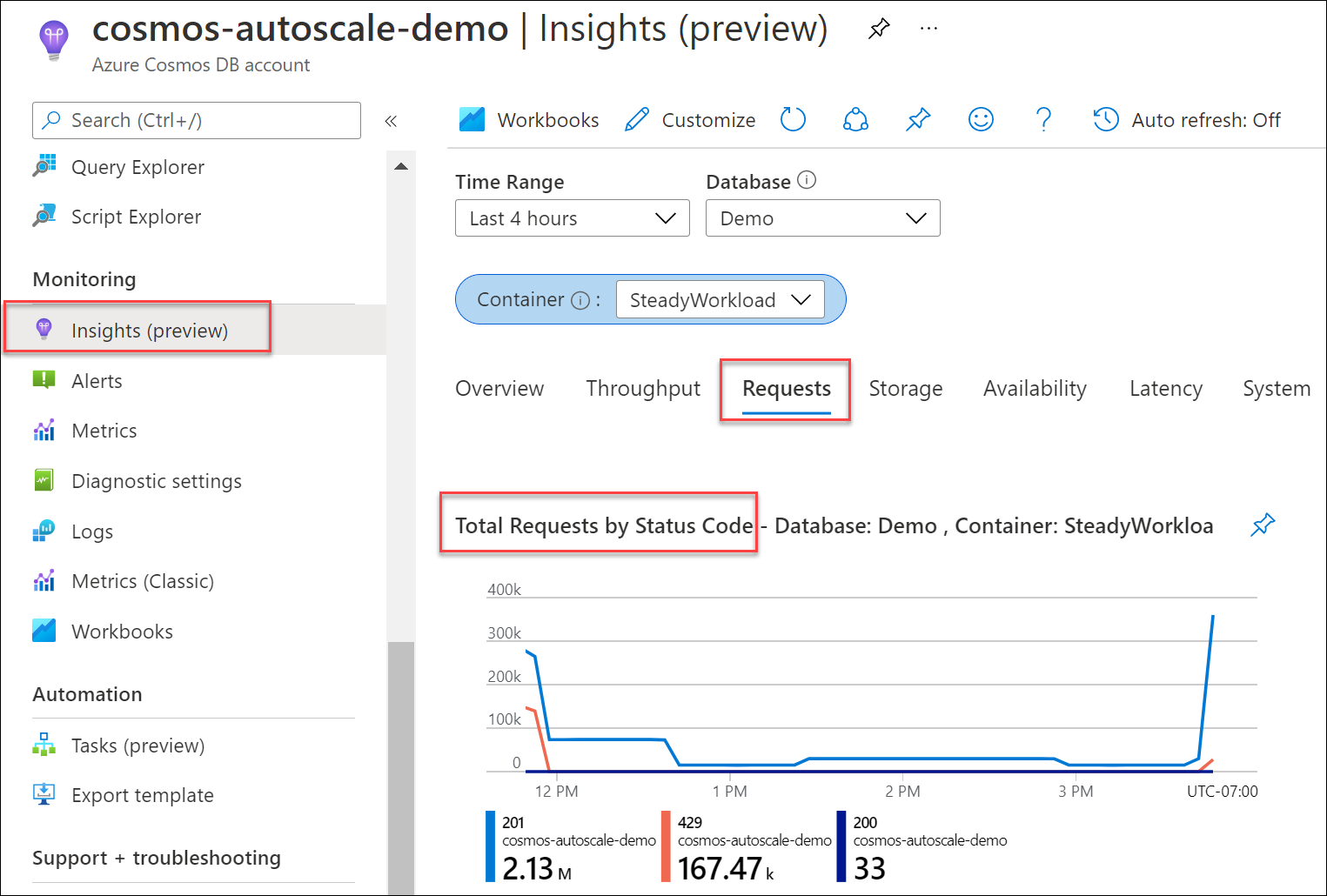
Determine qué porcentaje de las solicitudes para la base de datos o el contenedor ha resultado en respuestas 429, en comparación con el recuento total de solicitudes correctas. En la cuenta de Azure Cosmos DB, vaya a Insights>Solicitudes>Total Requests by Status Code (Total de solicitudes por código de estado). Filtre por una base de datos y un contenedor específicos.
De manera predeterminada, los SDK de cliente de Azure Cosmos DB y las herramientas de importación de datos, como Azure Data Factory y la biblioteca de Bulk Executor, reintentan automáticamente las solicitudes con errores 429. Normalmente, las reintentan hasta nueve veces. Como resultado, aunque pueda ver respuestas 429en las métricas, es posible que estos errores ni siquiera se hayan devuelto a la aplicación.
Solución recomendada
En general, para una carga de trabajo de producción, si ve entre el 1 y el 5 % de las solicitudes con respuestas 429 y la latencia de un extremo a otro es aceptable, se trata de una señal correcta de que las RU/s se están empleando completamente. No se requiere ninguna acción. De lo contrario, vaya a los siguientes pasos de solución de problemas.
Importante
Este rango del 1-5 % supone que las particiones de su cuenta están distribuidas de forma uniforme. Si las particiones no se distribuyen de forma uniforme, la partición del problema puede devolver una gran cantidad de errores 429, mientras que la tasa general puede ser baja.
Si usa el escalado automático, es posible ver respuestas 429 en la base de datos o el contenedor, incluso si las RU/s no se escalaron al máximo de RU/s. Consulte la sección La tasa de solicitudes es grande con el escalado automático para obtener una explicación.
Una pregunta común que surge es "¿Por qué veo respuestas 429 en las métricas de Azure Monitor, pero ninguno en mi propia supervisión de aplicaciones?". Si las métricas de Azure Monitor muestran que tiene errores 429, pero no ha visto ninguna en su propia aplicación, esto se debe a que, de manera predeterminada, los SDK de cliente de Azure Cosmos DB automatically retried internally on the 429 responses y la solicitud se ha hecho correctamente en reintentos posteriores. Como resultado, el código de estado 429 no se devuelve a la aplicación. En estos casos, la tasa general de respuestas 429 suele ser mínima y se puede omitir de forma segura, suponiendo que la tasa global esté entre el 429 y entre el 1 % i el 5 % y que la latencia de un extremo a otro sea aceptable para la aplicación.
Paso 2: Determinación de si hay una partición de nivel de acceso frecuente
Una partición de nivel de acceso frecuente surge cuando una o varias claves de partición lógica consumen una cantidad desproporcionada del total de RU/s debido a un mayor volumen de solicitudes. Esto puede deberse a un diseño de clave de partición que no distribuye uniformemente las solicitudes. Como resultado, muchas solicitudes se dirigen a un pequeño subconjunto de particiones lógicas (lo que implica a las físicas) que pasan a ser de "nivel de acceso frecuente". Dado que todos los datos de una partición lógica residen en una partición física y el total de RU/s se distribuye uniformemente entre las particiones físicas, una partición de nivel de acceso frecuente puede dar lugar a respuestas 429 y a un uso ineficaz del rendimiento.
Estos son algunos ejemplos de estrategias de creación de particiones que conducen a particiones de nivel de acceso frecuente:
- Tiene un contenedor que almacena datos de dispositivo IoT para una carga de trabajo con mucha escritura que se particiona por
date. Todos los datos de una sola fecha residirán en la misma partición lógica y física. Dado que todos los datos escritos cada día tienen la misma fecha, dará lugar a una partición de nivel de acceso frecuente todos los días.- En su lugar, para este escenario, una clave de partición como
id(ya sea un GUID o un id. de dispositivo), o una clave de partición sintética que combineidydateproduciría una mayor cardinalidad de valores y una mejor distribución del volumen de solicitudes.
- En su lugar, para este escenario, una clave de partición como
- Tiene un escenario multiinquilino con un contenedor particionado por
tenantId. Si un inquilino está mucho más activo que los demás, se produce una partición de nivel de acceso frecuente. Por ejemplo, si el inquilino más grande tiene 100 000 usuarios, pero la mayoría de los inquilinos tienen menos de 10 usuarios, tendrá una partición de nivel de acceso frecuente cuando se particione portenantID.- En el escenario anterior, considere la posibilidad de tener un contenedor dedicado para el inquilino más grande, particionado por una propiedad más granular, como
UserId.
- En el escenario anterior, considere la posibilidad de tener un contenedor dedicado para el inquilino más grande, particionado por una propiedad más granular, como
Identificación de la partición de nivel de acceso frecuente
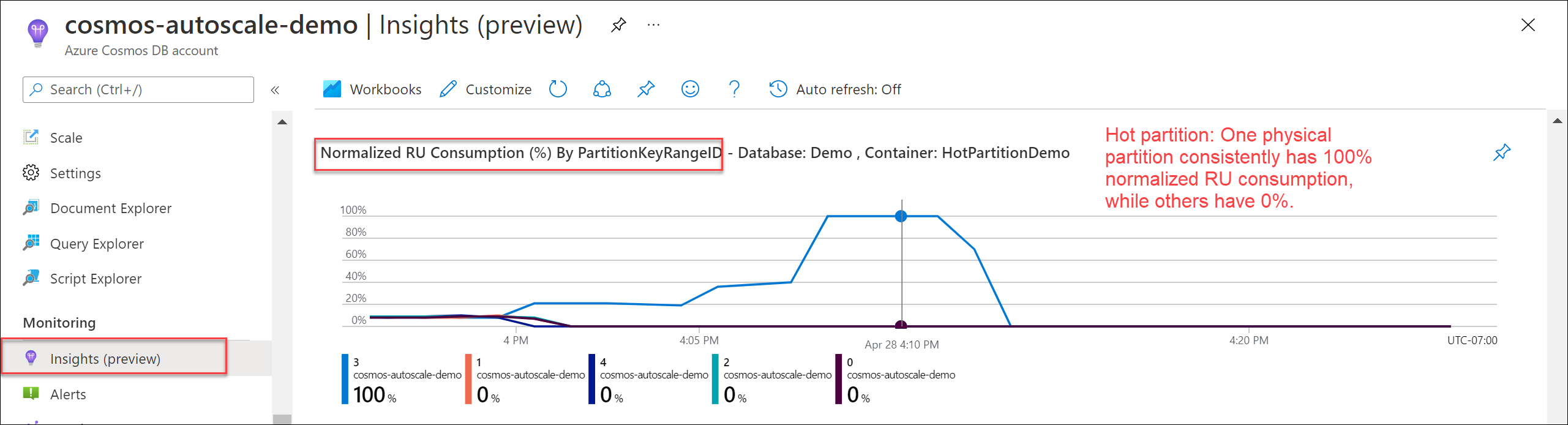
Para comprobar si hay una partición de nivel de acceso frecuente, vaya a Insights>Rendimiento>Normalized RU Consumption (%) By PartitionKeyRangeID (Consumo de RU normalizado [%] por PartitionKeyRangeID). Filtre por una base de datos y un contenedor específicos.
Cada objeto PartitionKeyRangeId se asigna a una partición física. Si hay un objeto PartitionKeyRangeId cuyo consumo de RU normalizado es mucho mayor que el de los demás (por ejemplo, es del 100 %, pero el de los demás es del 30 % o menos), puede ser un signo de que se trata de una partición de nivel de acceso frecuente. Obtenga más información sobre la métrica de consumo de RU normalizado.
Para ver qué claves de partición lógica consumen más RU/s, use Registros de diagnóstico de Azure. Esta consulta de ejemplo suma el total de unidades de solicitud consumidas por segundo en cada clave de partición lógica.
Importante
La habilitación de los registros de diagnóstico conlleva un cargo independiente para el servicio Log Analytics, que se factura en función del volumen de datos ingeridos. Se recomienda activar los registros de diagnóstico durante un período limitado de tiempo para la depuración y desactivarlos cuando ya no sean necesarios. Vea la página de precios para obtener más detalles.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
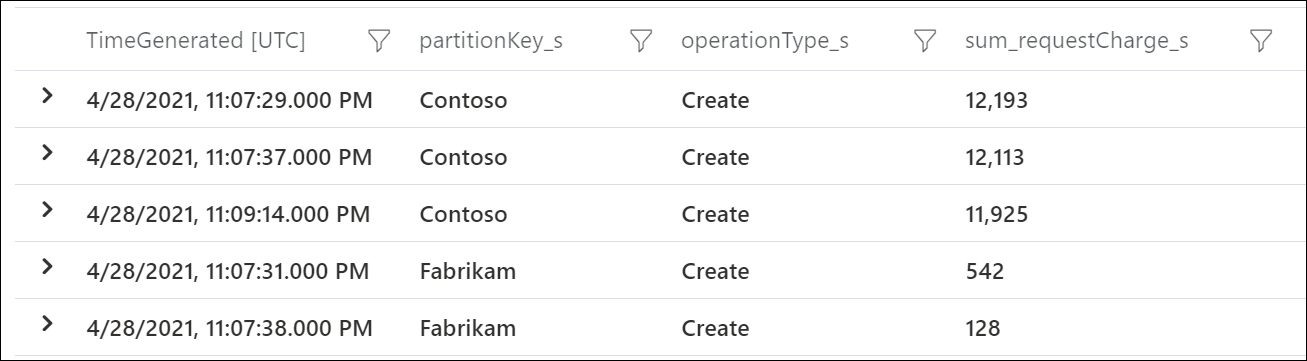
Esta salida de ejemplo muestra que, en un minuto determinado, la clave de partición lógica con el valor "Contoso" consumió aproximadamente 12 000 RU/s, mientras que la clave de partición lógica con el valor "Fabrikam" consumió menos de 600 RU/s. Si este patrón es continuo durante el período de tiempo en el que se produjo la limitación de tasa, indica una partición de nivel de acceso frecuente.
Sugerencia
En cualquier carga de trabajo, habrá una variación natural en el volumen de solicitudes entre particiones lógicas. Debe determinar si la partición de nivel de acceso frecuente se debe a un sesgo fundamental debido a la elección de la clave de partición (que puede requerir cambiar la clave) o a un pico temporal debido a una variación natural en los patrones de carga de trabajo.
Solución recomendada
Revise las instrucciones sobre cómo elegir una buena clave de partición.
Si hay un alto porcentaje de solicitudes con limitación de tasa y no hay ninguna partición de nivel de acceso frecuente:
- Puede aumentar las RU/s en la base de datos o el contenedor mediante los SDK de cliente, Azure Portal, PowerShell, la CLI o la plantilla de ARM. Siga los procedimientos recomendados para escalar el rendimiento aprovisionado (RU/s) a fin de determinar las RU/s adecuadas que se deben establecer.
Si hay un alto porcentaje de solicitudes con limitación de tasa y hay una partición de nivel de acceso frecuente subyacente:
- A largo plazo, para obtener el mejor costo y rendimiento, considere la posibilidad de cambiar la clave de partición. La clave de partición no se puede actualizar localmente, por lo que es necesario migrar los datos a un nuevo contenedor con una clave de partición diferente. Azure Cosmos DB admite una herramienta de migración de datos en directo para este propósito.
- A corto plazo, puede aumentar temporalmente las RU/s generales del recurso para permitir un mayor rendimiento de la partición de nivel de acceso frecuente. No se recomienda como una estrategia a largo plazo, ya que conduce a un aprovisionamiento excesivo de RU/s y un costo mayor.
- A corto plazo, puede usar la característica de redistribución del rendimiento entre particiones (versión preliminar) para asignar más RU/s a la partición física activa. Esto solo se recomienda cuando la partición física activa sea predecible y consistente.
Sugerencia
Al aumentar el rendimiento, la operación de escalado vertical se completará de forma instantánea o requerirá entre 5 y 6 horas para completarse, en función del número de RU/s a las que quiera escalar verticalmente. Si quiere conocer el mayor número de RU/s que puede establecer sin desencadenar la operación asincrónica de escalado vertical (que requiere Azure Cosmos DB para aprovisionar más particiones físicas), multiplique el número de objetos PartitionKeyRangeId distintos por 10 000 RU/s. Por ejemplo, si tiene 30 000 RU/s aprovisionadas y 5 particiones físicas (6000 RU/s asignadas por partición física), puede aumentar a 50 000 RU/s (10 000 RU/s por partición física) en una operación de escalado vertical instantánea. Aumentar a >50 000 RU/s requerirá una operación asincrónica de escalado vertical. Obtenga más información en el artículo Procedimientos recomendados para escalar el rendimiento aprovisionado (RU/s).
Paso 3: Determinación de qué solicitudes devuelven respuestas 429
Investigación de solicitudes con respuestas 429
Use Registros de diagnóstico de Azure para identificar qué solicitudes devuelven respuestas 429 y cuántas RU consumieron. Esta consulta de ejemplo se agrega en el nivel de minuto.
Importante
La habilitación de los registros de diagnóstico conlleva un cargo independiente para el servicio Log Analytics, que se factura en función del volumen de datos ingeridos. Se recomienda activar los registros de diagnóstico durante un período limitado de tiempo para la depuración y desactivarlos cuando ya no sean necesarios. Vea la página de precios para obtener más detalles.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
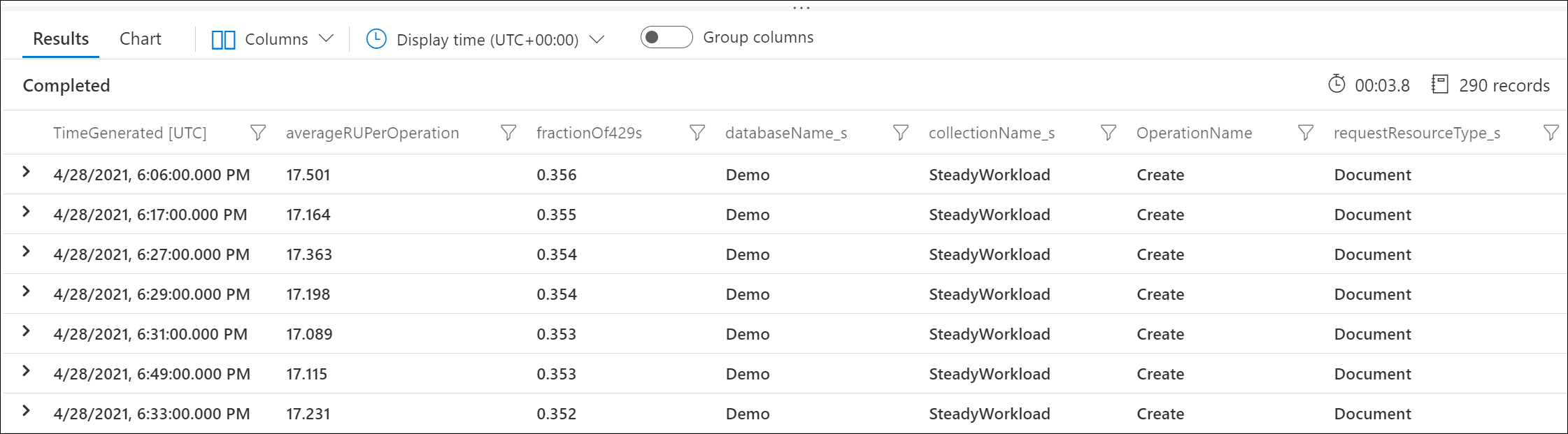
Por ejemplo, esta salida de ejemplo muestra que en cada minuto, el 30 % de las solicitudes de creación de documentos tenían una limitación de tasa y que cada solicitud consumía un promedio de 17 RU.
Solución recomendada
Uso de Azure Cosmos DB Capacity Planner
Puede usar la herramienta de planeamiento de capacidad de Azure Cosmos DB para comprender cuál es el mejor rendimiento aprovisionado en función de la carga de trabajo (volumen y tipo de operaciones y tamaño de los documentos). Puede personalizar aún más los cálculos proporcionando datos de ejemplo para obtener una estimación más precisa.
Respuestas 429 en las solicitudes de creación, reemplazo o upsert de documento
- De manera predeterminada, en la API para NoSQL, todas las propiedades se indexan de forma predeterminada. Ajuste la directiva de indexación para indexar solo las propiedades necesarias. Esto reducirá las unidades de solicitud necesarias por operación de creación de documento, lo que reducirá la probabilidad de ver respuestas 429 o le permitirá lograr más operaciones por segundo con la misma cantidad de RU/s aprovisionadas.
Respuestas 429 en solicitudes de consulta de documento
- Siga las instrucciones para solucionar problemas de consultas con cargos elevados de RU.
Respuestas 429 en la ejecución de procedimientos almacenados
- Los procedimientos almacenados están previstos para las operaciones que requieren transacciones de escritura en un valor de clave de partición. No se recomienda usar procedimientos almacenados para un gran número de operaciones de lectura o consulta. Para obtener el mejor rendimiento, estas operaciones de lectura o consulta deben realizarse en el lado cliente, mediante los SDK de Azure Cosmos DB.
La tasa de solicitudes es grande con el escalado automático
Todas las instrucciones de este artículo se aplican tanto al rendimiento manual como al de escalado automático.
Al usar el escalado automático, una pregunta común que surge es: "¿Todavía es posible ver respuestas 429 con el escalado automático?"
Sí. Hay dos escenarios principales donde esto puede pasar.
Escenario 1: cuando el total de las RU/s consumidas supera el número máximo de RU/s del contenedor o la base de datos, el servicio limitará las solicitudes en consecuencia. Esto es análogo a superar el rendimiento general aprovisionado manual de una base de datos o contenedor.
Escenario 2: si hay una partición frecuente, es decir, un valor de clave de partición lógica que tiene una cantidad de solicitudes desproporcionada en comparación con otros valores de la clave de partición, es posible que la partición física subyacente supere el presupuesto de las RU por segundo. Como procedimiento recomendado, para evitar las particiones frecuentes, elija una buena clave de partición que dé lugar a una distribución uniforme tanto del almacenamiento como del rendimiento. Esto es similar a cuando hay una partición frecuente cuando se usa el rendimiento manual.
Por ejemplo, si selecciona la opción de rendimiento de 20 000 RU por segundo máximas y tiene 200 GB de almacenamiento, con cuatro particiones físicas, cada partición física se puede escalar automáticamente hasta 5000 RU por segundo. Si había una partición frecuente en una clave de partición lógica determinada, verá varios códigos de estado de respuestas 429 cuando la partición física subyacente en la que reside supera las 5000 RU por segundo, es decir, supera el 100 % de la utilización normalizada.
Siga las instrucciones del Paso 1, Paso 2 y Paso 3 para depurar estos escenarios.
Otra pregunta común que surge es: ¿Por qué se normaliza el consumo de RU al 100 %, pero el escalado automático no se escaló al máximo de RU/s?
Esto suele ocurrir para cargas de trabajo que tienen picos de uso temporales o intermitentes. Cuando se usa el escalado automático, Azure Cosmos DB solo escala las RU/s al rendimiento máximo cuando el consumo de RU normalizado es del 100 % durante un período de tiempo continuo y sostenido en un intervalo de 5 segundos. Esto se hace para garantizar que la lógica de escalado sea rentable para el usuario, ya que garantiza que los picos únicos e momentáneos no conducen a un escalado innecesario y un costo mayor. Cuando hay picos momentáneos, el sistema normalmente se escala verticalmente hasta un valor mayor que el escalado anterior a RU/s, pero menor que el número máximo de RU/s. Obtenga más información sobre cómo interpretar la métrica de consumo normalizado de RU con escalado automático.
Limitación de tasa en las solicitudes de metadatos
La limitación de la tasa de metadatos puede producirse cuando se realizan un gran volumen de operaciones de metadatos en bases de datos o contenedores. Las operaciones de metadatos incluyen:
- Crear, leer, actualizar o eliminar un contenedor o una base de datos
- Enumeración de bases de datos o contenedores en una cuenta de Azure Cosmos DB
- Consultar las ofertas para ver el rendimiento aprovisionado actual
Hay un límite de RU reservado por el sistema para estas operaciones, por lo que aumentar las RU/s aprovisionadas de la base de datos o el contenedor no tendrá ningún impacto y no se recomienda. Consulte Límites del servicio del plano de control.
Investigación
Vaya a Insights>Sistema>Metadata Requests By Status Code (Solicitudes de metadatos por código de estado). Filtre por una base de datos y un contenedor específicos, si lo desea.
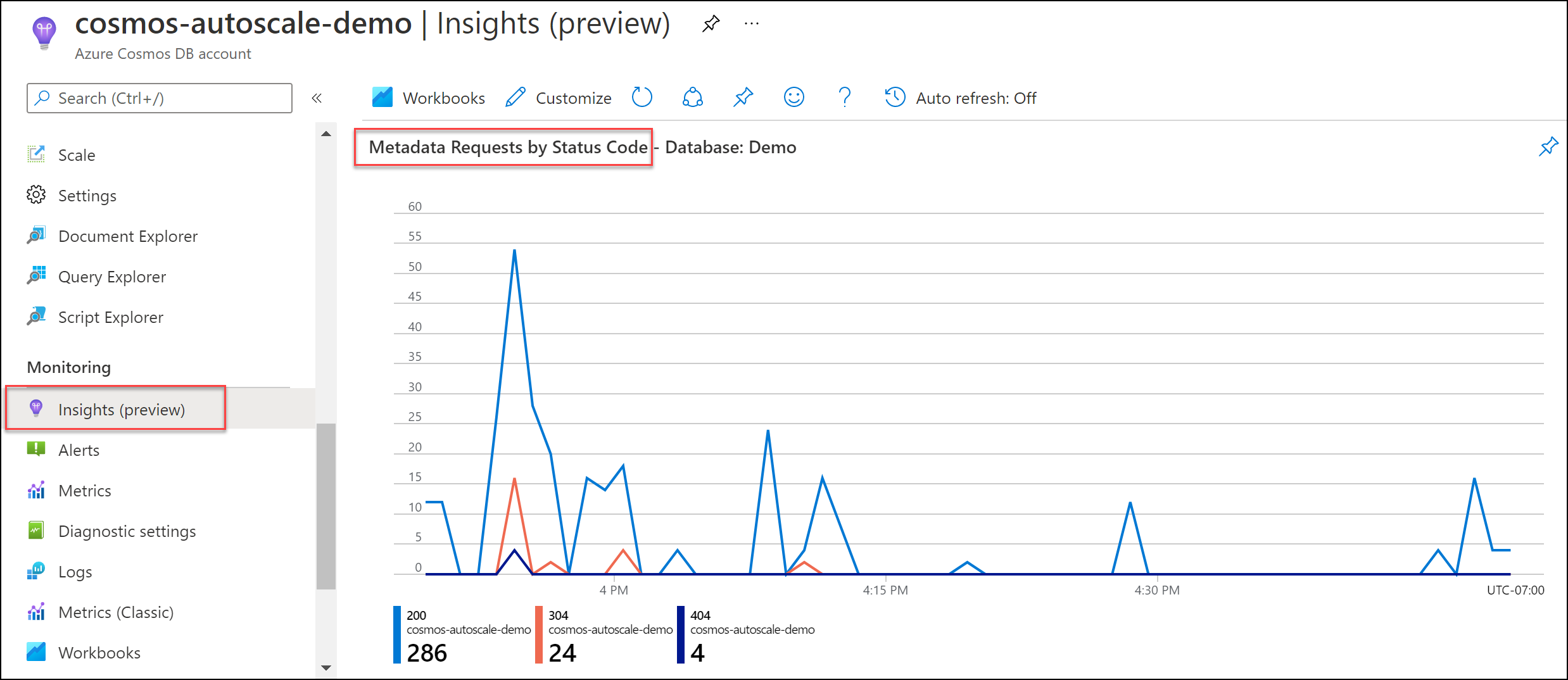
Solución recomendada
Si la aplicación necesita realizar operaciones de metadatos, considere la posibilidad de implementar una directiva de retroceso para enviar estas solicitudes con una tasa menor.
Utilice instancias de cliente estáticas de Azure Cosmos DB. Cuando se inicializa DocumentClient o CosmosClient, el SDK de Azure Cosmos DB captura los metadatos sobre la cuenta, incluida la información sobre el nivel de coherencia, las bases de datos, los contenedores, las particiones y las ofertas. Esta inicialización puede consumir un gran número de RU y debe realizarse con poca frecuencia. Use una única instancia de DocumentClient y úsela durante toda la vigencia de la aplicación.
Almacene en caché los nombres de las bases de datos y los contenedores. Durante el inicio, recupere los nombres de las bases de datos y los contenedores de la configuración o almacénelos en memoria caché. Llamadas como ReadDatabaseAsync/ReadDocumentCollectionAsync o CreateDatabaseQuery/CreateDocumentCollectionQuery producirán llamadas de metadatos al servicio, lo que consume el límite de RU reservadas por el sistema. Estas operaciones deben realizarse raramente.
Limitación de tasa debido a un error transitorio del servicio
Este error 429 se devuelve cuando la solicitud encuentra un error de servicio transitorio. El aumento de las RU/s de la base de datos o contenedor no tendrá ningún impacto y no se recomienda.
Solución recomendada
Vuelva a intentarlo. Si el error persiste durante varios minutos, abra una incidencia de soporte técnico desde Azure Portal.
Pasos siguientes
- Supervisión del consumo normalizado de RU/s de la base de datos o el contenedor.
- Diagnóstico y solución de problemas al utilizar el SDK de Azure Cosmos DB para .NET.
- Más información sobre las directrices de rendimiento de .NET v3 y .NET v2.
- Diagnóstico y solución de problemas al utilizar el SDK de Azure Cosmos DB para Java v4.
- Obtenga información sobre las instrucciones de rendimiento del SDK para Java v4.