Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El aprovisionamiento automatizado es un proceso para implementar y configurar rápidamente los recursos que necesita para ejecutar el clúster de Azure Data Explorer. Es una parte fundamental de un flujo de trabajo DevOps o DataOps. El proceso de aprovisionamiento no requiere que configure manualmente el clúster, no requiere intervención humana y es fácil de configurar.
Puede usar el aprovisionamiento automatizado para implementar un clúster preconfigurado con datos, como parte de una canalización de integración continua y entrega continua (CI/CD). Algunas de las principales ventajas de hacerlo incluyen la posibilidad de:
- Definir y mantener varios entornos.
- Realizar un seguimiento de las implementaciones en el control de código fuente.
- Revertir más fácilmente a versiones anteriores.
- Facilitar las pruebas automatizadas mediante el aprovisionamiento de entornos de prueba dedicados.
En este artículo se proporciona información general sobre los diferentes mecanismos para automatizar el aprovisionamiento de entornos de Azure Data Explorer, incluida la infraestructura, las entidades de esquema y la ingesta de datos. También proporciona referencias a las distintas herramientas y técnicas que se usan para automatizar el proceso de aprovisionamiento.

Implementación de la infraestructura
La implementación de la infraestructura pertenece a la implementación de recursos de Azure, entre los cuales se incluyen los clústeres, bases de datos y conexiones de datos. Hay varios tipos diferentes de implementaciones de infraestructura, entre los que se incluyen:
- Implementación de la plantilla de Azure Resource Manager (ARM)
- Implementación de Terraform
- Implementación imperativa
Las plantillas de ARM y los scripts de Terraform son las dos formas declarativas principales de implementar la infraestructura de Azure Data Explorer.
Implementación de la plantilla de ARM
Las plantillas de ARM son archivos JSON o Bicep que definen la infraestructura y la configuración de una implementación. Puede usar las plantillas para implementar clústeres, bases de datos, conexiones de datos y muchos otros componentes de infraestructura. Para más información, consulte Creación de un clúster y una base de datos de Azure Data Explorer mediante una plantilla de Azure Resource Manager.
También puede usar plantillas de ARM para implementar scripts de comandos que le ayudarán a crear un esquema de base de datos y definir directivas. Para más información, consulte Configuración de una base de datos mediante un script del lenguaje de consulta Kusto.
Puede encontrar más plantillas de ejemplo en el sitio Plantillas de inicio rápido de Azure.
Implementación de Terraform
Terraform es una herramienta de código abierto de software de infraestructura como código. Proporciona un flujo de trabajo coherente de la CLI para administrar los servicios en la nube. Terraform codifica las API en la nube en archivos de configuración declarativos.
Terraform ofrece las mismas funcionalidades que las plantillas de ARM. Puede usar Terraform para implementar clústeres, bases de datos, conexiones de datos y otros componentes de infraestructura.
También puede usar Terraform para implementar scripts de comandos que le ayudarán a crear un esquema de base de datos y definir directivas.
Implementación imperativa
La infraestructura también se puede implementar de forma imperativa mediante cualquiera de las plataformas admitidas:
Implementación de entidades de esquema
El aprovisionamiento de entidades de esquema pertenece a la implementación de tablas, funciones, directivas y permisos. Puede crear o actualizar entidades mediante la ejecución de scripts que constan de comandos de administración.
Puede automatizar la implementación de entidades de esquema mediante los métodos siguientes:
- Plantillas de ARM
- Scripts de Terraform
- CLI de Kusto
- SDK
- Herramientas
- Sync Kusto. Use esta herramienta interactiva para desarrolladores para extraer el esquema de base de datos o el script de comandos de administración. Puede utilizar el script de comandos de contenido extraído para la implementación automática.
- Delta Kusto: invoque esta herramienta en una canalización de CI/CD. Puede comparar dos orígenes, como el esquema de base de datos o el script de comandos de administración, y calcular un script de comandos de administración delta. Puede utilizar el script de comandos de contenido extraído para la implementación automática.
- Tarea de Azure DevOps para Azure Data Explorer.
Ingerir datos
A veces desea ingerir datos en el clúster. Por ejemplo, puede que quiera ingerir datos para ejecutar pruebas o volver a crear un entorno. Puede usar los métodos siguientes para ingerir datos:
- SDK
- Herramienta de la CLI LightIngest
- Desencadenar una canalización de Azure Data Factory
Ejemplo de implementación mediante una canalización de CI/CD
En el ejemplo siguiente, usará una canalización de CI/CD de Azure DevOps que ejecuta herramientas para automatizar la implementación de infraestructura, entidades de esquema y datos. Este es un ejemplo de una canalización que usa un conjunto determinado de herramientas, pero puede usar otras herramientas y pasos. Por ejemplo, en un entorno de producción puede crear una canalización que no ingiera datos. También puede agregar más pasos a la canalización, como la ejecución de pruebas automatizadas en el clúster creado.
Aquí, usará las siguientes herramientas:
| Tipo de implementación | Herramienta | Tarea |
|---|---|---|
| Infraestructura | Plantillas de ARM | Creación de un clúster y una base de datos |
| Entidades de esquema | CLI de Kusto | Creación de tablas en la base de datos |
| Data | LightIngest | Ingesta de datos en una tabla |

Siga estos pasos para crear una canalización.
Paso1: Creación de una conexión de servicio
Defina una conexión de servicio del tipo Azure Resource Manager. Apunte la conexión a la suscripción y al grupo de recursos en los que desea implementar el clúster. Se crea una entidad de servicio de Azure y la usará para implementar la plantilla de ARM. Puede usar la misma entidad para implementar las entidades de esquema e ingerir los datos. Debe pasar explícitamente las credenciales a la CLI de Kusto y a las herramientas de LightIngest.
Paso 2: Creación de una canalización
Defina la canalización (deploy-environ) que se va a usar para implementar el clúster, crear entidades de esquema e ingerir datos.
Para poder usar la canalización, debe crear las siguientes variables secretas:
| Nombre de la variable | Descripción |
|---|---|
clusterName |
El nombre del clúster de Azure Data Explorer. |
serviceConnection |
Nombre de la conexión de Azure DevOps usada para implementar la plantilla de ARM. |
appId |
Identificador de cliente de la entidad de servicio usada para interactuar con el clúster |
appSecret |
Secreto de la entidad de servicio. |
appTenantId |
El id. de inquilino de la entidad de servicio. |
location |
La región de Azure en la que va a implementar el clúster. Por ejemplo, eastus. |
resources:
- repo: self
stages:
- stage: deploy_cluster
displayName: Deploy cluster
variables: []
clusterName: specifyClusterName
serviceConnection: specifyServiceConnection
appId: specifyAppId
appSecret: specifyAppSecret
appTenantId: specifyAppTenantId
location: specifyLocation
jobs:
- job: e2e_deploy
pool:
vmImage: windows-latest
variables: []
steps:
- bash: |
nuget install Microsoft.Azure.Kusto.Tools -Version 5.3.1
# Rename the folder (including the most recent version)
mv Microsoft.Azure.Kusto.Tools.* kusto.tools
displayName: Download required Kusto.Tools Nuget package
- task: AzureResourceManagerTemplateDeployment@3
displayName: Deploy Infrastructure
inputs:
deploymentScope: 'Resource Group'
# subscriptionId and resourceGroupName are specified in the serviceConnection
azureResourceManagerConnection: $(serviceConnection)
action: 'Create Or Update Resource Group'
location: $(location)
templateLocation: 'Linked artifact'
csmFile: deploy-infra.json
overrideParameters: "-clusterName $(clusterName)"
deploymentMode: 'Incremental'
- bash: |
# Define connection string to cluster's database, including service principal's credentials
connectionString="https://$(clusterName).$(location).kusto.windows.net/myDatabase;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
# Execute a KQL script against the database
kusto.tools/tools/Kusto.Cli $connectionString -script:MyDatabase.kql
displayName: Create Schema Entities
- bash: |
connectionString="https://ingest-$(CLUSTERNAME).$(location).kusto.windows.net/;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
kusto.tools/tools/LightIngest $connectionString -table:Customer -sourcePath:customers.csv -db:myDatabase -format:csv -ignoreFirst:true
displayName: Ingest Data
Paso 3: Creación de una plantilla de ARM para implementar el clúster
Defina la plantilla de ARM (deploy-infra.json) que se va a usar para implementar el clúster en la suscripción y el grupo de recursos.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"clusterName": {
"type": "string",
"minLength": 5
}
},
"variables": {
},
"resources": [
{
"name": "[parameters('clusterName')]",
"type": "Microsoft.Kusto/clusters",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"sku": {
"name": "Dev(No SLA)_Standard_E2a_v4",
"tier": "Basic",
"capacity": 1
},
"resources": [
{
"name": "myDatabase",
"type": "databases",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Kusto/clusters', parameters('clusterName'))]"
],
"kind": "ReadWrite",
"properties": {
"softDeletePeriodInDays": 365,
"hotCachePeriodInDays": 31
}
}
]
}
]
}
Paso 4: Creación de un script de KQL para crear las entidades de esquema
Defina el script de KQL (MyDatabase.kql) que se va a usar para crear las tablas de las bases de datos.
.create table Customer(CustomerName:string, CustomerAddress:string)
// Set the ingestion batching policy to trigger ingestion quickly
// This is to speedup reaction time for the sample
// Do not do this in production
.alter table Customer policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
.create table CustomerLogs(CustomerName:string, Log:string)
Paso 5: Creación de un script de KQL para ingerir datos
Cree el archivo de datos CSV (customer.csv) para ingerir.
customerName,customerAddress
Contoso Ltd,Paris
Datum Corporation,Seattle
Fabrikam,NYC
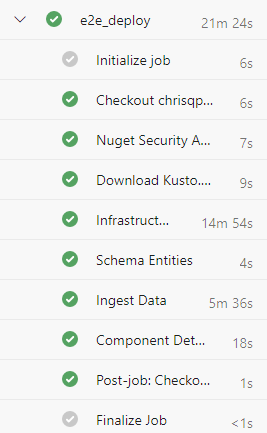
Puede crear el clúster con las credenciales de entidad de servicio que especificó en la canalización. Siga los pasos que se indican en Administración de permisos de base de datos del Explorador de datos de Azure para conceder permisos a los usuarios.
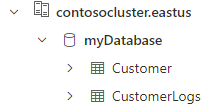
Para comprobar la implementación, ejecute una consulta en la tabla Customer. Debería ver los tres registros que se importaron desde el archivo CSV.
Contenido relacionado
- Creación de un clúster y una base de datos de Azure Data Explorer mediante una plantilla de Azure Resource Manager.
- Configuración de una base de datos mediante un script KQL