Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Azure Data Factory es el servicio ETL e integración de datos de Microsoft en la nube. En este documento se proporciona una guía para DataOps en la factoría de datos. No pretende ser un tutorial completo sobre CI/CD, Git o DevOps. En su lugar, encontrará la guía del equipo de factoría de datos para lograr DataOps en el servicio con referencias a vínculos de implementación detallados sobre procedimientos recomendados de implementación de factoría de datos, administración de factorías y gobernanza. Al final de este documento hay una sección de recursos con vínculos a tutoriales.
¿Qué es DataOps?
DataOps es un proceso que las organizaciones de datos practican para la administración de datos colaborativa con la finalidad de proporcionar un valor más rápido a los responsables de la toma de decisiones.
Gartner proporciona esta definición clara de DataOps:
DataOps es una práctica de administración de datos colaborativa centrada en mejorar la comunicación, la integración y la automatización de los flujos de datos entre los administradores y consumidores de datos en una organización. El objetivo de DataOps es ofrecer valor más rápidamente mediante la creación de una entrega predecible y la administración de los cambios de datos, modelos de datos y artefactos relacionados. DataOps utiliza la tecnología para automatizar el diseño, la implementación y la administración de la entrega de datos con los niveles adecuados de gobernanza y emplea metadatos para mejorar la usabilidad y el valor de los datos en un entorno dinámico.
¿Cómo logra DataOps en Azure Data Factory?
Azure Data Factory proporciona a los ingenieros de datos un paradigma de canalización de datos basado visualmente para crear fácilmente proyectos ETL e integración de datos a escala en la nube. Data Factory se basa en integraciones nativas con herramientas de control de versiones maduras, como GitHub y Azure DevOps, así como en el ecosistema de Azure más amplio, para proporcionar muchas características integradas para facilitar DataOps que incluyen una colaboración enriquecida, gobernanza y relaciones de artefactos.
En concreto, una vez que incorpore su propio repositorio de GitHub o Azure DevOps a Data Factory, el servicio proporciona opciones integradas e intuitivas de interfaz de usuario para comandos comunes, como commits, guardar artefactos y control de versiones. El servicio también ofrece la opción de proporcionar procedimientos recomendados de CI/CD y de inserción de código en el repositorio para proteger la integridad y el estado del entorno de producción.
"Código" en Azure Data Factory
Todos los artefactos de Azure Data Factory, tanto si son canalizaciones, servicios vinculados, desencadenadores, etc. tienen representaciones de "código" correspondientes en JSON detrás de la integración de la interfaz de usuario visual. Estos artefactos cumplen los estándares de las plantillas de Azure Resource Manager. Para encontrar el código, haga clic en el icono de corchete situado en la parte superior derecha del lienzo. El "código" JSON de ejemplo tendría el siguiente aspecto:
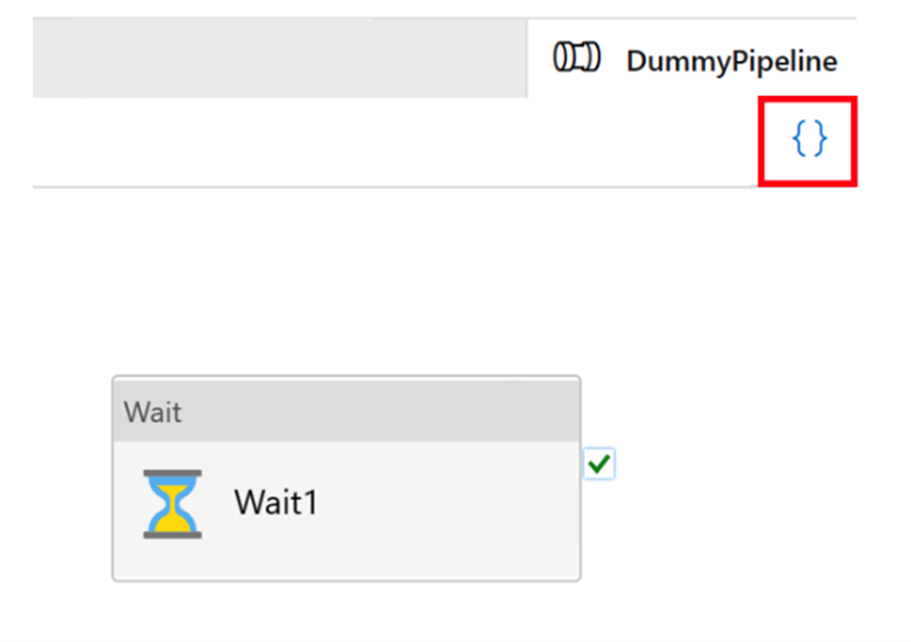

Modo activo y control de versiones de Git
Cada fábrica tiene una fuente única de verdad: canalizaciones, servicios vinculados y definiciones de desencadenadores almacenadas en el servicio. Este origen de verdad es lo que ejecuta la canalización y lo que determina los comportamientos de los desencadenadores. Si está en modo real, cada vez que haga alguna publicación, modificará directamente el origen único de verdad. En la imagen siguiente se muestra el aspecto del botón Publicar todo en modo real.

El modo real puede ser práctico para una sola persona que trabaja en proyectos paralelos, ya que permite a los desarrolladores ver efectos inmediatos de sus cambios en el código. Sin embargo, no se recomienda para equipos de desarrolladores que trabajan en proyectos a nivel de producción. Los peligros incluyen errores por dedos torpes, eliminación accidental de recursos críticos o publicación de códigos no probados, entre otros. Al trabajar en proyectos y plataformas críticos, considere la posibilidad de incorporar un repositorio de Git y usar el modo Git en la factoría de datos para simplificar el proceso de desarrollo. El control de versiones y las funcionalidades de inserción en el repositorio validadas del modo Git permite evitar prácticamente la mayoría de incidentes asociados a usar directamente el modo en directo.
Nota
En el modo Git, el botón Publicar o Publicar todo se reemplazará por Guardar o Guardar todo, y los cambios se confirmarán en sus propias ramas (sin cambiar directamente las bases de código activas).
Configuración de la integración de GitHub y Azure DevOps
En Azure Data Factory, se recomienda almacenar el repositorio en GitHub o Azure DevOps. El servicio es totalmente compatible con ambos métodos y la elección de qué repositorio usar depende de los estándares de cada organización. Hay dos métodos para configurar un nuevo repositorio o para conectarse a un repositorio existente: mediante el portal de Azure o la creación desde la interfaz de usuario de Azure Data Factory Studio
creación de la factoría del portal de Azure
Al crear una nueva fábrica de datos desde el portal de Azure, Azure DevOps es el repositorio de Git predeterminado. También puede seleccionar GitHub como repositorio y configurar la configuración del repositorio.
En el portal de Azure, seleccione el tipo de repositorio y escriba los nombres de repositorio y rama para crear una nueva factoría integrada de forma nativa con Git.
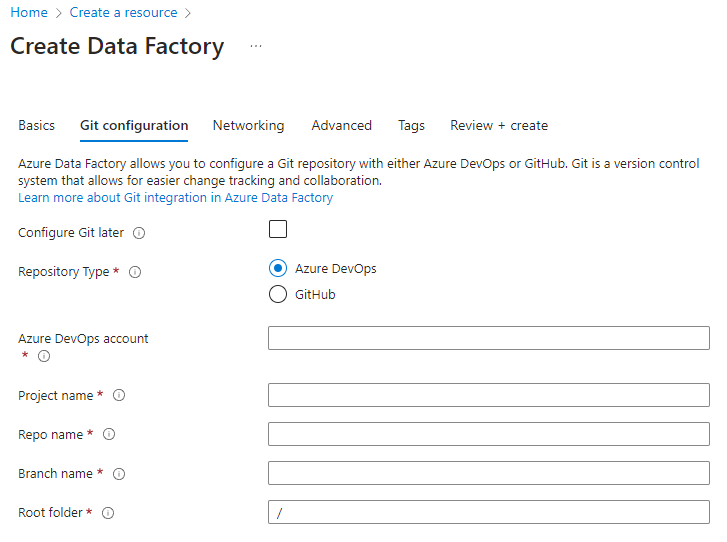
Aplicación del uso de Git con Azure Policy en la organización
El uso de Git en los proyectos de Azure Data Factory es un procedimiento recomendado. Incluso si no estás implementando un proceso completo de CI/CD, la integración de Git con ADF permite guardar tus artefactos de recursos en tu propio entorno aislado (rama de Git), donde puedes probar tus cambios de forma independiente al resto de las ramas de la fábrica. Puede usar Azure Policy para hacer cumplir el uso de Git en la fábrica de la organización.
Azure Data Factory Studio
Después de crear la factoría de datos, también puede conectarse al repositorio a través de Azure Data Factory Studio. En la pestaña Administrar, verá la opción de configurar el repositorio y sus opciones.

Mediante un proceso guiado, se le dirige a través de una serie de pasos para ayudarle a configurar y conectarse fácilmente al repositorio que prefiera. Una vez configurado completamente, puede empezar a trabajar de forma colaborativa y guardar ahí los recursos.

Integración continua y entrega continua (CI/CD)
CI/CD es un paradigma de desarrollo de código donde se inspeccionan y prueban los cambios a medida que pasan por varias fases: desarrollo, prueba, ensayo, etc. Después de revisarse y probarse en cada fase, se publican finalmente en bases de código reales de los entornos de producción.
La integración continua (CI) es la práctica de probar y validar automáticamente los cambios que realiza un desarrollador en el código base. La entrega continua (CD) significa que, después de que las pruebas de integración continua se realicen correctamente, los cambios se llevan a la siguiente fase de forma ininterrumpida.
Como se explicó anteriormente de forma breve, "código" en Azure Data Factory adopta la forma de JSON de las plantillas de Azure Resource Manager. Por lo tanto, los cambios que pasan por el proceso de integración y entrega continuas (CI/CD) comprenden adiciones, eliminaciones y ediciones de blobs JSON.
Ejecuciones de canalización en Azure Data Factory
Antes de hablar de CI/CD en Azure Data Factory, primero es necesario hacerlo de cómo el servicio ejecuta una canalización. Antes de que la fábrica de datos ejecute una canalización, hace lo siguiente:
- Extrae la definición publicada más reciente de la canalización y sus recursos asociados, como conjuntos de datos, servicios vinculados, etc.
- La compila en acciones: si la factoría de datos la ejecutó recientemente, recupera las acciones de las compilaciones almacenadas en caché.
- Ejecuta la canalización.
La ejecución de la canalización conlleva los pasos siguientes:
- El servicio toma la instantánea de un momento dado de la definición de canalización.
- A lo largo de la duración de la canalización, las definiciones no cambian.
- Incluso si las tuberías funcionan durante períodos prolongados, no se ven afectadas por los cambios subsiguientes realizados después de su inicio. Si durante la ejecución publica cambios en el servicio vinculado, las canalizaciones, etc., estos cambios no afectan a las ejecuciones en curso.
- Al publicar los cambios, las ejecuciones subsiguientes iniciadas después de la publicación usan las definiciones actualizadas.
Publicación en Azure Data Factory
Independientemente de si va a implementar canalizaciones con Azure Release Pipeline para automatizar la publicación, o con el despliegue manual de plantillas de Resource Manager, en el back-end, la publicación es una serie de operaciones de creación y actualización en conjuntos de datos, servicios vinculados, canalizaciones y desencadenadores, para cada uno de los artefactos. El efecto es el mismo que hacer llamadas directamente a las API REST subyacentes.
De las acciones se desprenden algunas cosas:
- Todas estas llamadas API son sincrónicas, lo que significa que la llamada solo se devuelve cuando la publicación se realiza correctamente o produce un error. No habrá un estado de implementación parcial para el artefacto.
- Las llamadas API son en gran medida secuenciales. Se intenta paralelizar las llamadas y, al mismo tiempo, mantener las dependencias referenciales de los artefactos. El orden de las implementaciones es: servicio vinculado -> conjunto de datos/entorno de ejecución de integración -> canalización -> desencadenador. Este orden garantiza que los artefactos dependientes puedan hacer referencia correctamente a sus dependencias. Por ejemplo, las canalizaciones dependen de los conjuntos de datos, por lo que la factoría de datos las implementa después de estos.
- La implementación de servicios vinculados, conjuntos de datos, etc., son independientes de las canalizaciones. Hay situaciones en las que la factoría de datos actualiza los servicios vinculados antes que una canalización. Se hablará de esta situación en la sección Cuándo detener un desencadenador.
- La implementación no eliminará los artefactos de las factorías. Debe llamar explícitamente a las API de eliminación de cada tipo de artefacto (canalización, conjunto de datos, servicio vinculado, etc.) para limpiar una factoría. Consulte el script de postimplementación de ejemplo de Azure Data Factory.
- Incluso si no ha tocado una canalización, un conjunto de datos o un servicio vinculado, se sigue invocando una llamada API de actualización rápida a la factoría.
Desencadenadores de publicación
- Los desencadenadores tienen los estados iniciado o detenido.
- No se pueden realizar cambios en un desencadenador en modo iniciado. Debe detener un desencadenador antes de publicar los cambios.
- Puede invocar la API para crear o actualizar un desencadenador en un desencadenador que está en modo iniciado.
- Si cambia la carga, se produce un error en la API.
- Si la carga permanece sin cambios, la API se ejecuta correctamente.
- Este comportamiento tiene un profundo efecto sobre cuándo detener un desencadenador.
Cuándo detener un desencadenador
Cuando se trata de la implementación en una factoría de datos de producción, donde desencadenadores activos inician las ejecuciones de canalización todo el tiempo, la pregunta es "¿Debemos detenerlos?".
La respuesta corta es que solo en los siguientes escenarios se debería considerar detener el desencadenador:
- Debe detener el desencadenador si va a actualizar las definiciones del desencadenador, incluidos campos como la fecha de finalización, la frecuencia y la asociación de canalización.
- Se recomienda detener el desencadenador si va a actualizar los conjuntos de datos o los servicios vinculados a los que se hace referencia en una canalización real. Por ejemplo, si va a rotar las credenciales para SQL Server.
- Puede optar por detener el desencadenador si la canalización asociada produce errores y está sobrecargando sus servidores.
Estos son algunos puntos que se deben tener en cuenta en relación con la detención de desencadenadores:
- Como se explica en la sección Pipeline Runs in Azure Data Factory, cuando un desencadenador inicia una ejecución de canalización, toma una instantánea de la canalización, el conjunto de datos, el entorno de ejecución de integración y las definiciones de servicio vinculados. Si la canalización se ejecuta antes de que los cambios se introduzcan en el back-end, el desencadenador inicia una ejecución con la versión anterior. En la mayoría de los casos, esta acción es correcta.
- Como se explica en la sección Desencadenantes de Publicación, cuando un desencadenador está en estado iniciado, no se puede actualizar. Por lo tanto, si necesita cambiar los detalles sobre la definición del desencadenador, detenga el desencadenador antes de publicar los cambios.
- Como se explica en la sección Publicación en Azure Data Factory, las modificaciones de los conjuntos de datos o de los servicios vinculados se publican antes de que cambie el pipeline. Para asegurarse de que las ejecuciones de canalización usan las credenciales correctas y se comunican con los servidores adecuados, se recomienda detener también el desencadenador asociado.
Preparación de los cambios de "código"
Se recomienda seguir estos procedimientos recomendados para las solicitudes de incorporación de cambios.
- Cada desarrollador debe trabajar en sus propias ramas individuales y, al final del día, crear pull requests en la rama principal del repositorio. Consulte tutoriales sobre solicitudes de incorporación de cambios en GitHub y DevOps.
- Cuando los encargados de proteger el código aprueban las solicitudes de incorporación de cambios y combinan los cambios en la rama principal, el proceso de CI/CD puede iniciarse. Hay dos métodos sugeridos para promover los cambios en todos los entornos: automatizado y manual.
- Cuando esté listo para iniciar las canalizaciones de CI/CD, puede hacerlo normalmente mediante la versión de Azure Pipeline o realizar implementaciones de canalizaciones individuales específicas mediante esta utilidad de código abierto de Azure Player.
Implementación automatizada de cambios
Para ayudar con las implementaciones automatizadas, se recomienda usar el paquete npm de utilidades de Azure Data Factory. El uso del paquete npm ayuda a validar todos los recursos de una canalización y a generar las plantillas de ARM para el usuario.
Para empezar a trabajar con el paquete npm de utilidades de Azure Data Factory, consulte Publicación automatizada para la integración y entrega continuas.
Implementación manual de cambios
Después de fusionar tu rama de nuevo con la rama de colaboración principal de tu repositorio de Git, puedes publicar manualmente los cambios en el servicio "live" de Azure Data Factory. El servicio proporciona control de la interfaz de usuario sobre la publicación desde factorías que no son de desarrollo con la opción Deshabilitar publicación (desde ADF Studio).
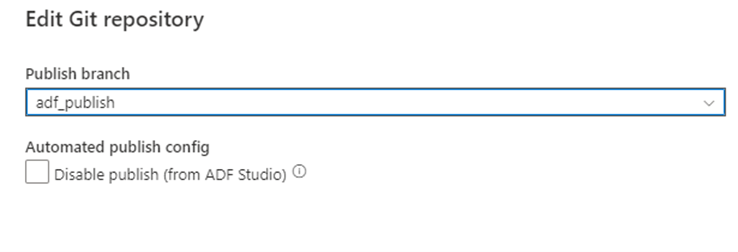
Implementación selectiva
La implementación selectiva se basa en una característica de GitHub y Azure DevOps, conocida como cherry picking. Esta característica le permite implementar solo determinados cambios, pero no otros. Por ejemplo, un desarrollador ha realizado cambios en varias canalizaciones, pero para la implementación actual, es posible que solo queramos implementar cambios en una.
Siga los tutoriales de Azure DevOps y GitHub para seleccionar los commits pertinentes para el pipeline que usted necesita. Asegúrese de que todos los cambios, incluidos los cambios pertinentes realizados en los desencadenadores, los servicios vinculados y las dependencias asociados a la canalización, se hayan seleccionado cuidadosamente.
Cuando se hayan elegido los cambios por conveniencia y se hayan combinado con la canalización de colaboración principal, puede iniciar el proceso de CI/CD para los cambios propuestos. En la sección Pruebas Automatizadas de este artículo, se proporciona información adicional sobre cómo corregir sobre la marcha, seleccionar cambios específicos, o utilizar frameworks externos para la implementación selectiva.
Pruebas unitarias
Las pruebas unitarias son una parte importante del proceso de desarrollo de nuevas canalizaciones o edición de artefactos de factoría de datos existentes, que se centra en probar los componentes del código. Data Factory permite realizar pruebas unitarias individuales a nivel de artefacto de flujo de datos y de canalización mediante la característica de depuración de la canalización.

Al desarrollar flujos de datos, podrá obtener información sobre cada transformación y cambio de código individual mediante la característica de vista previa de datos para lograr pruebas unitarias antes de implementar los cambios en producción.

El servicio proporciona comentarios reales e interactivos de las actividades de canalización en la interfaz de usuario al depurar y realizar pruebas unitarias en Azure Data Factory.
Pruebas automatizadas
Hay varias herramientas disponibles para las pruebas automatizadas que puede usar con Azure Data Factory. Dado que el servicio almacena objetos en el servicio como entidades JSON, puede ser conveniente usar el marco de pruebas unitarias de código abierto .NET NUnit con Visual Studio. Consulte esta publicación Configurar pruebas automatizadas para Azure Data Factory que proporciona una explicación detallada de cómo configurar un entorno de pruebas unitarias automatizadas para Azure Data Factory. (Un agradecimiento especial a Richard Swinbank por dejarnos usar este blog).
Como parte del proceso de CI/CD, los clientes también pueden ejecutar canalizaciones de PRUEBA con PowerShell o la CLI de AZ en los pasos previos y posteriores a la implementación.
Uno de los puntos fuertes de la factoría de datos se encuentra en su parametrización de conjuntos de datos. Esta característica permite a los clientes ejecutar las mismas canalizaciones con diferentes conjuntos de datos para asegurarse de que su nuevo desarrollo cumple todos los requisitos de origen y destino.
Otros marcos de CI/CD para Azure Data Factory
Como se ha descrito anteriormente, la integración integrada de Git está disponible de forma nativa a través de la interfaz de usuario de Azure Data Factory, incluida la combinación, la bifurcación, la comparación y la publicación. Sin embargo, hay otros marcos de CI/CD útiles que son populares en la comunidad de Azure, que proporcionan mecanismos alternativos para proporcionar funcionalidades similares. La metodología de Git de Azure Data Factory se basa en plantillas de ARM, mientras que los marcos como ADFTools de Kamil Nowinski toman un enfoque diferente al confiar en artefactos JSON individuales de la fábrica en su lugar. Los ingenieros de datos que son expertos en Azure DevOps y prefieren trabajar en ese entorno (en lugar del enfoque de interfaz de usuario basado en ARM que el servicio ofrece de forma predeterminada) pueden encontrar que este marco funciona bien para ellos y para escenarios comunes como implementaciones parciales. Este marco también puede simplificar el control de desencadenadores cuando la implementación se realiza en entornos que tienen estados de desencadenador en ejecución.
Gobernanza de datos en Azure Data Factory
Un aspecto importante de la eficacia de DataOps es la gobernanza de datos. En el caso de las herramientas ETL de integración de datos, proporcionar el linaje de los datos y las relaciones entre artefactos puede aportar información importante para que un ingeniero de datos comprenda el impacto de los cambios posteriores. Data Factory proporciona vistas de artefacto relacionadas integradas que constituyen la implementación de la factoría.

La integración nativa con Microsoft Purview proporciona más linaje, análisis de impacto y catalogación de datos.
Microsoft Purview proporciona una solución unificada de gobernanza de datos para ayudar a administrar y controlar los datos locales, multinube y software como servicio (SaaS). Le permite crear fácilmente un mapa holístico actualizado del panorama de sus datos con detección automatizada de datos, clasificación de datos confidenciales y linaje de datos de principio a fin. Estas características permiten que los consumidores de datos accedan a una administración de datos valiosa y confiable.

Con la integración nativa en el Catálogo de Datos de Purview, Data Factory permite una búsqueda y detección sencilla de activos de datos que se pueden usar en las canalizaciones de integración de datos a lo largo de todo el conjunto de datos de la organización.

Puede usar la barra de búsqueda principal de Azure Data Factory Studio para buscar recursos de datos en el catálogo de Purview.
