Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Información general
Azure Data Factory y el modo de depuración de los flujos de datos de mapeo de Synapse Analytics le permiten observar de manera interactiva la transformación de la estructura de datos mientras crea y depura sus flujos de datos. La sesión de depuración se puede usar tanto en sesiones de diseño de Data Flow como durante la depuración de la canalización de los flujos de datos. Para activar el modo de depuración, use el botón Depuración de Flujo de Datos en la barra superior del lienzo de flujo de datos o del lienzo de canalización cuando tenga actividades de flujo de datos.
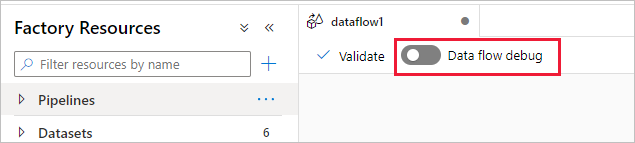

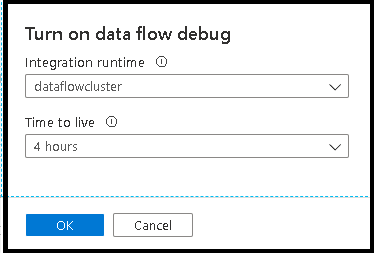
Al activar el control deslizante, se le pide que seleccione la configuración del entorno de ejecución de integración que quiere usar. Si se elige AutoResolveIntegrationRuntime, se desarrollará un clúster con ocho núcleos de proceso general con un período de vida predeterminado de 60 minutos. Si desea permitir un equipo más inactivo antes de que se agote el tiempo de espera de la sesión, puede elegir un valor de TTL superior. Para obtener más información sobre los entornos de ejecución de integración de flujo de datos, vea Rendimiento de Microsoft Integration Runtime.
Cuando el modo de depuración está activado, interactuarás construyendo el flujo de datos con un clúster activo de Spark. La sesión se cierra una vez desactivada la depuración. Debe tener en cuenta los gastos por hora que genera Data Factory durante el tiempo que tiene la sesión de depuración activa.
En la mayoría de los casos, se recomienda crear instancias de Data Flow en modo de depuración para poder validar la lógica de negocios y ver las transformaciones de datos antes de publicar el trabajo. Use el botón "Depurar" del panel de la canalización para probar el flujo de datos en una canalización.
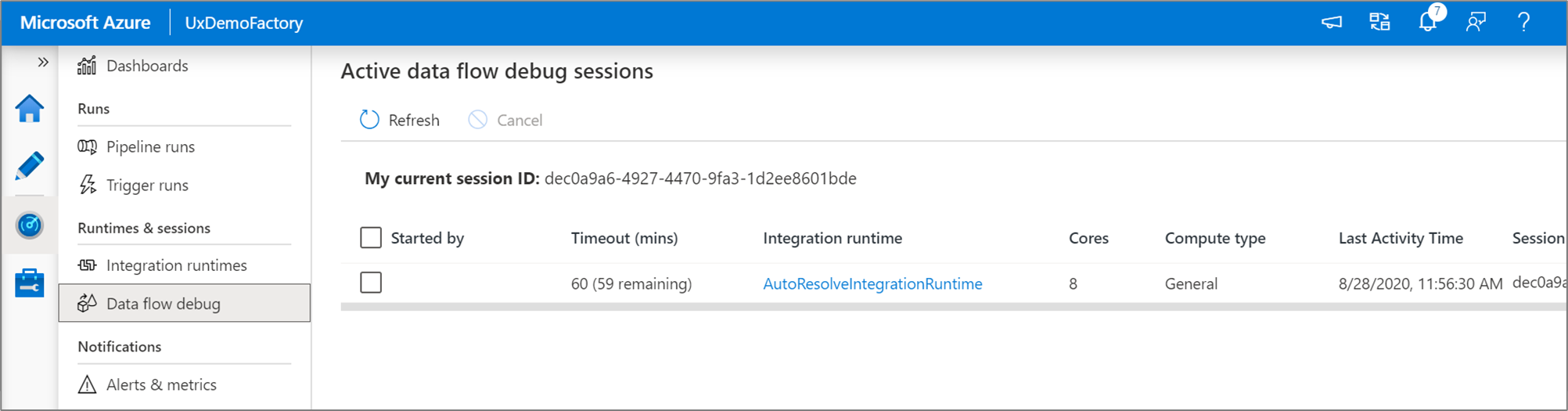
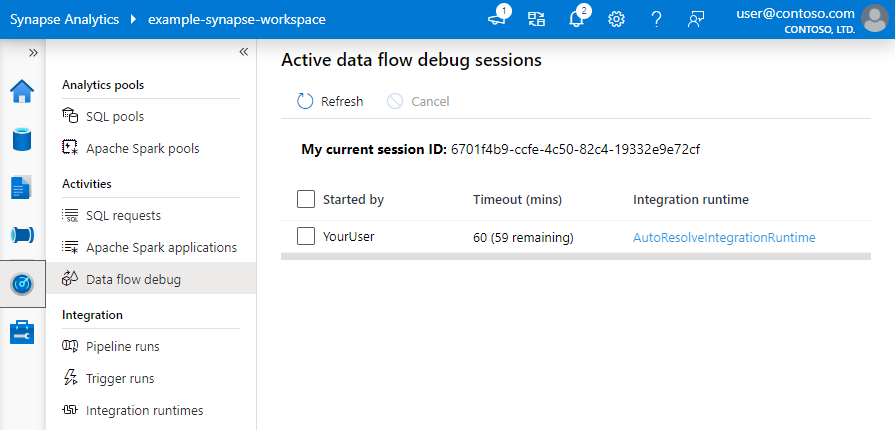
Nota
Cada sesión de depuración que un usuario inicia desde su interfaz de usuario del explorador es una sesión nueva con su propio clúster de Spark. Puede usar la vista de supervisión para sesiones de depuración mostradas en las imágenes anteriores para visualizar y gestionar las sesiones de depuración. Se le cobra por cada hora de ejecución de cada sesión de depuración, incluida la hora de TTL.
Este clip de vídeo habla sobre sugerencias, trucos y procedimientos recomendados para el modo de depuración de flujos de datos.
Estado del clúster
El indicador de estado del clúster en la parte superior de la superficie de diseño se pone de color verde cuando el clúster esté listo para realizar la depuración. Si el clúster ya está caliente, el indicador verde aparece casi al instante. Si el clúster no estaba en ejecución cuando entró en el modo de depuración, el clúster de Spark lleva a cabo un arranque en frío. El indicador gira hasta que el entorno está listo para la depuración interactiva.
Cuando hayas terminado con la depuración, apaga el interruptor de depuración para que el clúster de Spark pueda apagarse y así evitarás que te cobren por la actividad de depuración.
Configuración de depuración
Una vez activado el modo de depuración, puede editar la forma en que un flujo de datos obtiene una vista previa de los datos. Para editar la configuración de depuración, haga clic en "Configuración de depuración" en la barra de herramientas del lienzo de Data Flow. Puede seleccionar los límites de fila o el origen de archivos que se usarán en cada transformación de origen. Los límites de fila de esta configuración solo son para la sesión de depuración actual. También puede seleccionar el servicio vinculado de almacenamiento provisional que se va a usar como origen de Azure Synapse Analytics.
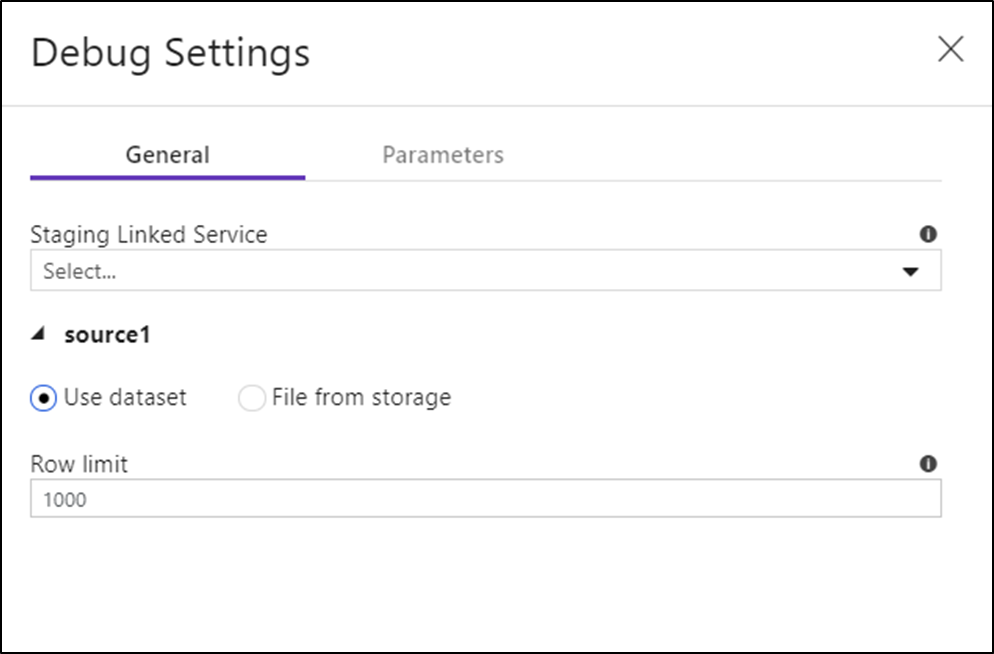
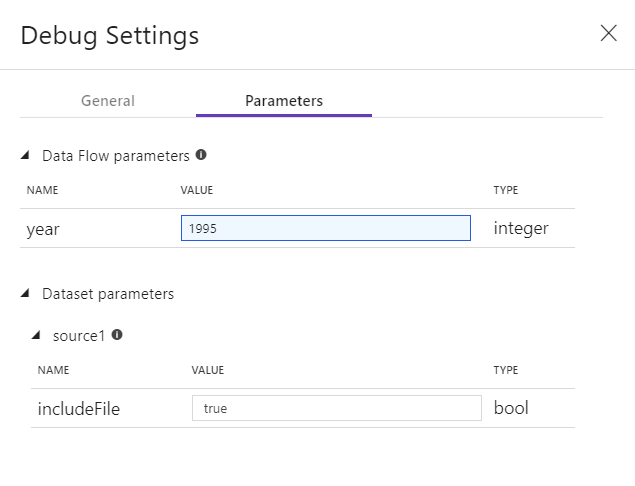
Si tiene parámetros en el Data Flow o en cualquiera de sus conjuntos de datos a los que se hace referencia, puede especificar qué valores usar durante la depuración seleccionando la pestaña Parameters.
Use la configuración de ejemplo que se proporciona aquí para apuntar a archivos o tablas de datos de ejemplo, de modo que no tenga que cambiar los conjuntos de datos de origen. Mediante el uso de un archivo o una tabla de ejemplo aquí, puede mantener la misma lógica y los mismos valores de propiedades en el flujo de datos al realizar pruebas en un subconjunto de datos.
El valor predeterminado de IR usado para el modo de depuración en los flujos de datos es un único nodo de trabajo de 4 núcleos pequeño con un nodo de un solo controlador de 4 núcleos. Este valor funciona bien con ejemplos más pequeños de datos al probar la lógica del flujo de datos. Si expande los límites de fila en la configuración de depuración durante la versión preliminar de datos o establece un mayor número de filas muestreadas en el origen durante la depuración de la canalización, es posible que desee considerar la posibilidad de establecer un entorno de proceso mayor en una nueva Azure Integration Runtime. Después, puede reiniciar la sesión de depuración utilizando el entorno de cómputo más grande.
Vista previa de datos
Con la depuración activada, la pestaña Vista previa de datos se enciende en el panel inferior. Sin el modo de depuración activado, Data Flow muestra solo los metadatos actuales dentro y fuera de cada una de las transformaciones de la pestaña Inspeccionar. La vista previa de datos solo consultará el número de filas que ha establecido como límite en la configuración de depuración. Seleccione Actualizar para actualizar la vista previa de los datos en función de las transformaciones actuales. Si los datos de origen han cambiado, seleccione Actualizar > Volver a capturar desde el origen.
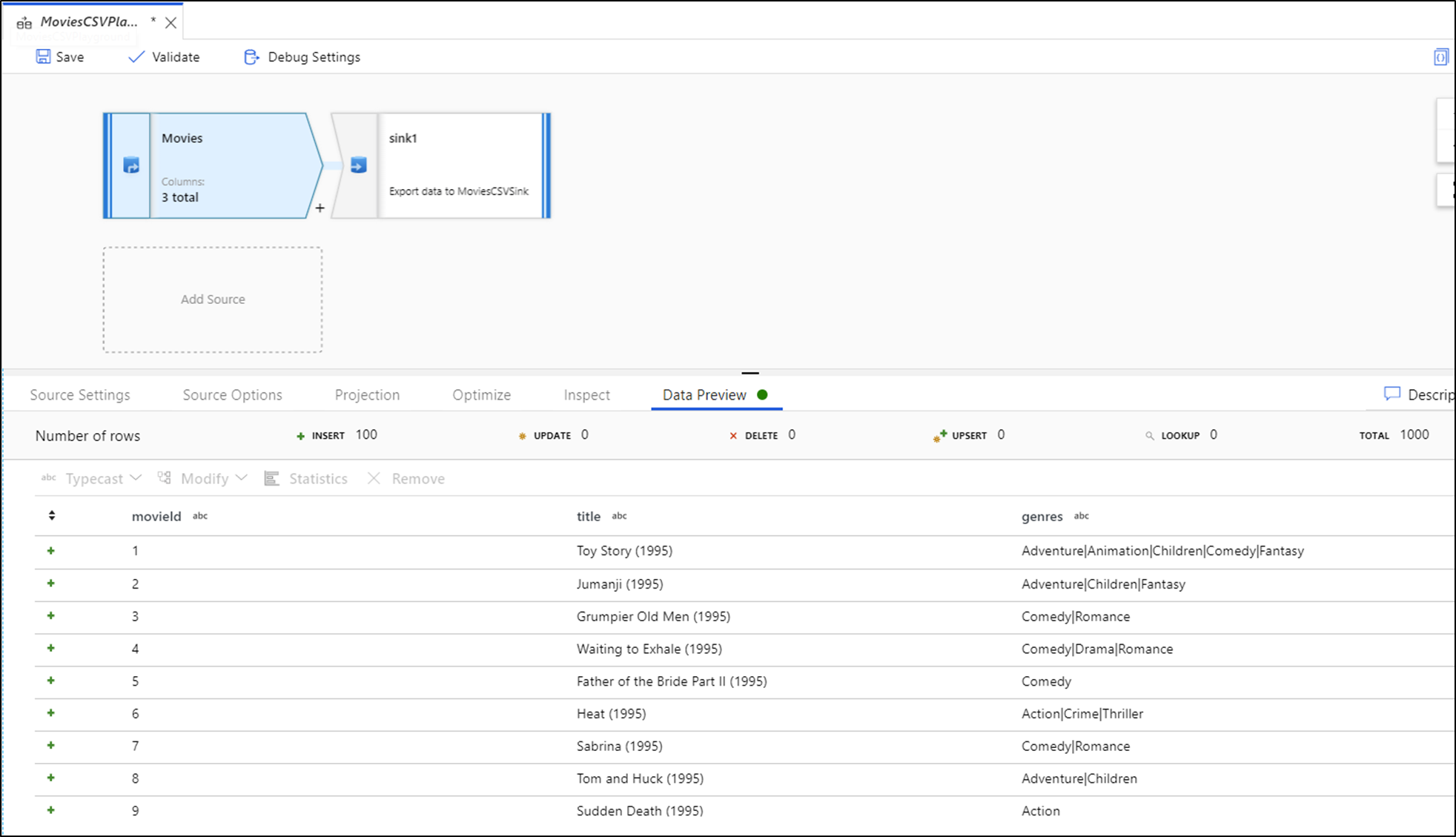
Puede ordenar columnas por versión preliminar de datos y reorganizar columnas mediante arrastrar y colocar. Además, hay un botón de exportación en la parte superior del panel de vista previa de los datos que puede usar para exportar los datos de vista previa a un archivo .csv para explorar los datos sin conexión. Puede usar esta característica para exportar hasta 1000 filas de datos de versión preliminar.
Nota
Las fuentes de archivo solo limitan las filas que ves, no las filas que se están leyendo. Para conjuntos de datos muy grandes, se recomienda tomar una pequeña parte de ese archivo y usarlo para las pruebas. Puede seleccionar un archivo temporal en Configuración de depuración para cada origen que sea un tipo de conjunto de datos de archivo.
Cuando se ejecuta Data Flow en el modo de depuración, no se escribirán los datos en el transformación de destino (receptor). Una sesión de depuración está diseñada para que funcione como una herramienta de ejecución de pruebas para las transformaciones. Los receptores no son necesarios durante la depuración y se omiten en el flujo de datos. Si quiere probar a escribir los datos en el receptor, ejecute la instancia de Data Flow desde una canalización y use la ejecución de la depuración desde una canalización.
La vista previa de los datos es una instantánea de los datos transformados mediante los límites de fila y el muestreo de datos de las tramas de datos en la memoria de Spark. Por tanto, no se usan ni se prueban controladores de receptor en este escenario.
Nota
La vista previa de datos muestra la hora según la configuración regional del explorador.
Pruebas de condiciones de combinación
Cuando se realicen pruebas unitarias en las transformaciones Joins, Exists o Lookup, asegúrese de usar un pequeño conjunto de datos conocidos para las pruebas. Puede usar la opción Configuración de depuración anterior para establecer un archivo temporal que se usará para las pruebas. Esto es necesario porque al limitar o muestrear filas de un conjunto de datos grande, no se puede predecir qué filas y qué claves se leen en el flujo de las pruebas. El resultado no es determinista, es decir, se pueden producir errores en las condiciones de combinación.
Acciones rápidas
Una vez obtenida la vista previa de los datos, puede generar una transformación rápida para quitar una columna o realizar en ella una conversión de tipo o una modificación. Seleccione el encabezado de la columna y elija una de las opciones de la barra de herramientas de vista previa de datos.
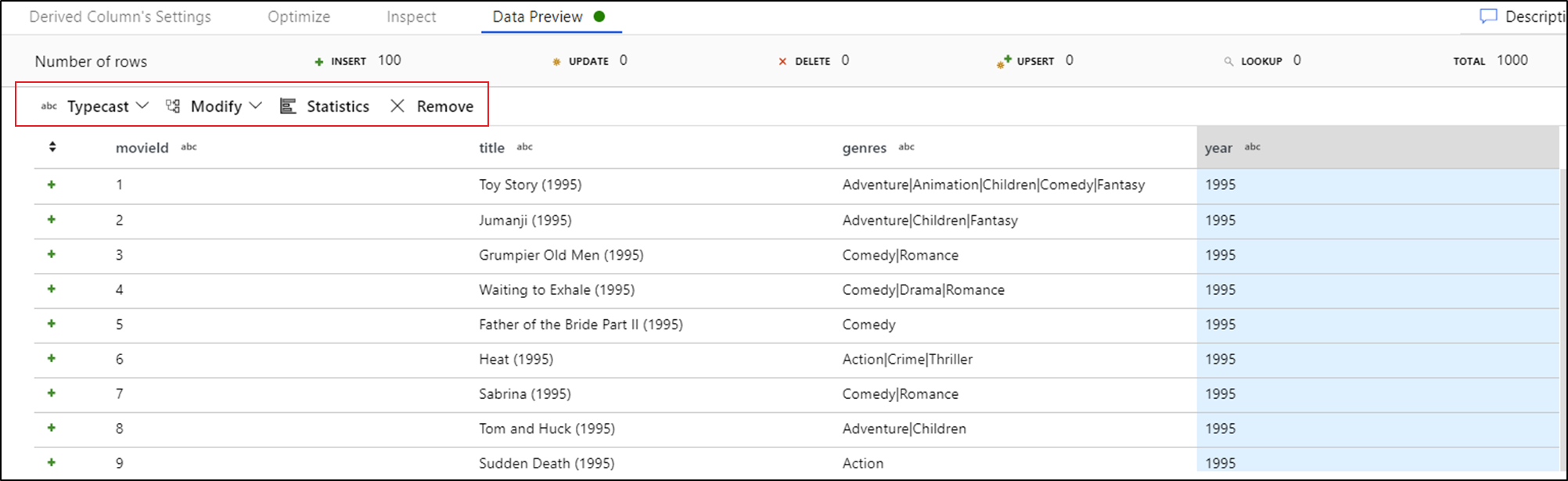
Una vez que seleccione una modificación, la vista previa de los datos se actualizará inmediatamente. Seleccione Confirmar en la esquina superior derecha para generar una nueva transformación.
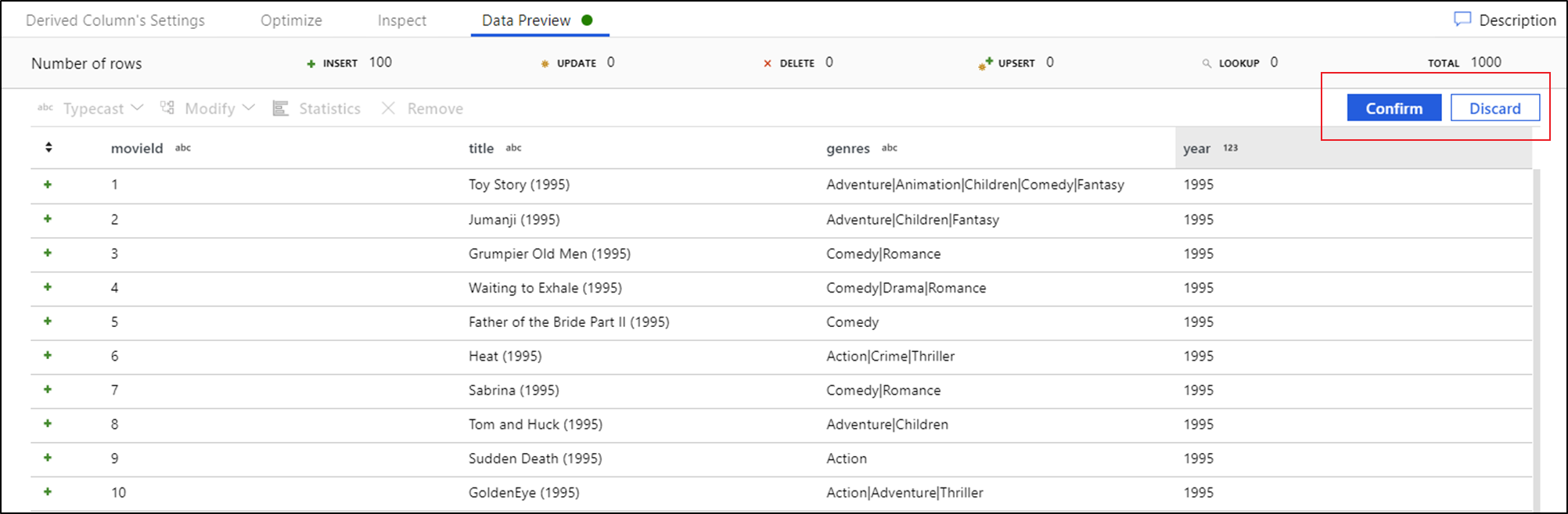
Las opciones Conversión de tipo y Modificar generan una transformación de Columna Derivada, mientras que la opción Quitar genera una transformación de Seleccionar.
Nota
Si edita el Data Flow, debe volver a capturar la vista previa de datos antes de agregar una transformación rápida.
Generación de perfiles de los datos
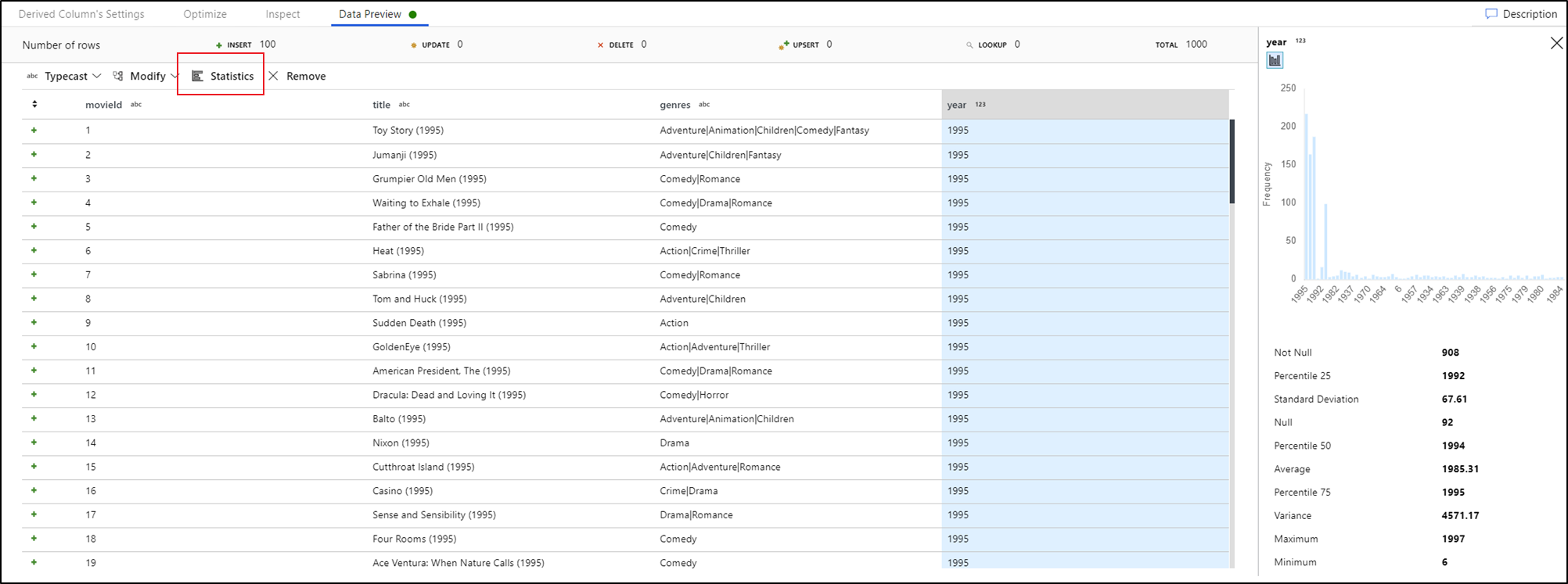
Si selecciona una columna en la pestaña de vista previa de datos y hace clic en Estadísticas en la barra de herramientas de la vista previa de datos, aparece un gráfico en el extremo derecho de la cuadrícula de datos con estadísticas detalladas sobre cada campo. El servicio se basa en el muestreo de datos para decidir qué tipo de gráfico se mostrará. Los campos de alta cardinalidad establecen como valor predeterminado los gráficos de tipo NULL/NOT NULL, mientras que los datos categóricos y numéricos que tienen una cardinalidad baja muestran gráficos de barras con la frecuencia de valor de los datos. También se muestra la longitud máxima y mínima de los campos de cadena, los valores máximos y mínimos de los campos numéricos, la desviación estándar, los percentiles, los recuentos y el promedio.
Contenido relacionado
- Una vez que haya terminado de compilar y depurar el flujo de datos, ejecútelo desde una canalización.
- Al probar la canalización con un flujo de datos, use la opción de ejecución de depuración de la canalización.