Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Los flujos de datos están disponibles tanto en canalizaciones de Azure Data Factory como en canalizaciones de Azure Synapse Analytics. Este artículo se aplica a los flujos de datos de mapeo. Si no está familiarizado con las transformaciones, consulte el artículo introductorio Transformación de datos mediante flujos de datos de asignación.
Sugerencia
Para obtener la transformación equivalente (referencia) en Dataflow Gen2, consulte Una guía de Dataflow Gen2 para asignar usuarios de flujo de datos.
La transformación División condicional enruta las filas de datos a diferentes flujos en función de las condiciones coincidentes. La transformación de división condicional es similar a una estructura de decisión CASE en un lenguaje de programación. La transformación evalúa las expresiones y, según los resultados, dirige la fila de datos a la secuencia especificada.
Configuración
El valor Dividir determina si la fila de datos fluye hacia el primer flujo coincidente o hacia todos los flujos que coincidan.
Utilice el generador de expresiones de flujo de datos para especificar una expresión como condición de división. Para agregar una nueva condición, haga clic en el icono del signo más en una fila existente. También se puede agregar un flujo predeterminado para las filas que no coinciden con ninguna condición.
Script de flujo de datos
Sintaxis
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Ejemplo
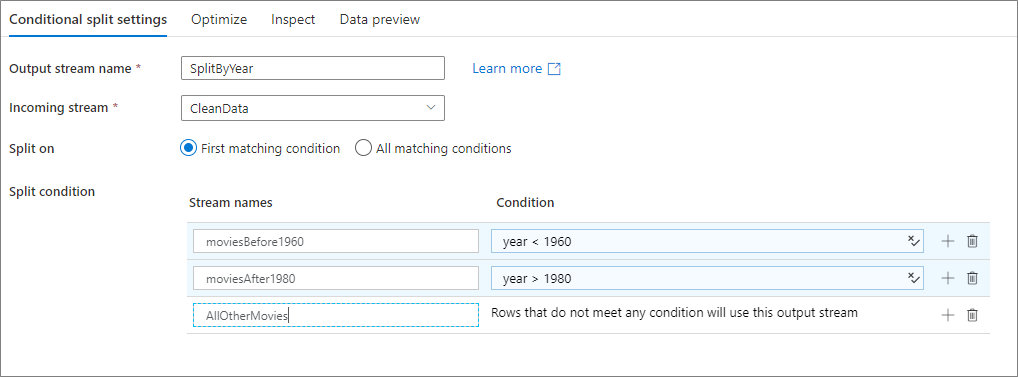
El siguiente ejemplo es una transformación de división condicional denominada SplitByYear que recibe el flujo entrante CleanData. Esta transformación tiene dos condiciones de división, year < 1960 y year > 1980.
disjoint es falso porque los datos van a la primera condición de coincidencia, en lugar de a todas ellas. Cada fila que coincide con la primera condición se dirige al flujo de salida moviesBefore1960. Todas las filas restantes que coinciden con la segunda condición se dirigen al flujo de salida moviesAFter1980. Todas las demás filas pasan a través del flujo predeterminado AllOtherMovies.
En la interfaz de usuario del servicio, esta transformación es similar a la siguiente imagen:
En el siguiente fragmento de código se muestra el script del flujo de datos para esta transformación:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Contenido relacionado
Las transformaciones de flujo de datos comunes que se usan con la división condicional son la transformación Combinación, la transformación Búsqueda y la transformación Selección