Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Los flujos de datos están disponibles tanto en canalizaciones de Azure Data Factory como en canalizaciones de Azure Synapse Analytics. Este artículo se aplica a los flujos de datos de mapeo. Si no está familiarizado con las transformaciones, consulte el artículo introductorio Transformación de datos mediante flujos de datos de asignación.
Use la transformación de análisis para analizar las columnas de texto de sus datos que son cadenas en el formulario. Los tipos de documentos insertados admitidos actualmente que se pueden analizar son JSON, XML y texto delimitado.
Configuración
En el panel de configuración de transformación de análisis, primero se selecciona el tipo de datos contenidos en las columnas que quiere analizar en línea. La transformación de análisis también contiene los siguientes valores de configuración.

Columna
De forma similar a las columnas derivadas y los agregados, es en la propiedad Column donde modifica una columna de salida, para lo cual debe seleccionarla en el selector desplegable. También puede escribir aquí el nombre de una nueva columna. ADF almacena los datos de origen analizados en esta columna. En la mayoría de los casos, será aconsejable definir una nueva columna que analice el campo de cadena de documento insertado de entrada.
Expresión
Use el generador de expresiones para establecer el origen del análisis. Establecer el origen puede ser tan sencillo como seleccionar la columna de origen con los datos independientes que desea analizar, o puede crear expresiones complejas para analizar.
Expresiones de ejemplo
Datos de la cadena de origen:
chrome|steel|plastic- Expresión:
(desc1 as string, desc2 as string, desc3 as string)
- Expresión:
Datos JSON de origen:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Expresión:
(level as string, registration as long)
- Expresión:
Datos JSON anidados de origen:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Expresión:
(car as (model as string, year as integer), color as string, transmission as string)
- Expresión:
Datos XML de origen:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Expresión:
(Customers as (Customer as integer, CompanyName as string))
- Expresión:
XML de origen con datos de atributo:
<cars><car model="camaro"><year>1989</year></car></cars>- Expresión:
(cars as (car as ({@model} as string, year as integer)))
- Expresión:
Expresiones con caracteres reservados:
{ "best-score": { "section 1": 1234 } }- La expresión anterior no funciona porque el carácter "-" de
best-scorese interpreta como una operación de resta. Use una variable con notación de corchetes en estos casos para indicar al motor JSON que interprete el texto literalmente:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- La expresión anterior no funciona porque el carácter "-" de
Nota: Si se producen errores al extraer atributos (en concreto, @model) desde un tipo complejo, una solución alternativa consiste en convertir el tipo complejo en una cadena, quitar el símbolo @ (en concreto, replace(toString(your_xml_string_parsed_column_name.cars.car),'@','')) y, luego, usar la actividad de transformación de análisis de JSON.
Tipo de columna de salida
Aquí es donde va a configurar el esquema de salida de destino a partir del análisis que se escribe en una sola columna. La manera más fácil de establecer un esquema para la salida del análisis es seleccionar el botón "Detectar tipo" en la parte superior derecha del generador de expresiones. ADF intenta detectar automáticamente el esquema del campo de cadena que estás analizando y lo configura para ti en la expresión de salida.
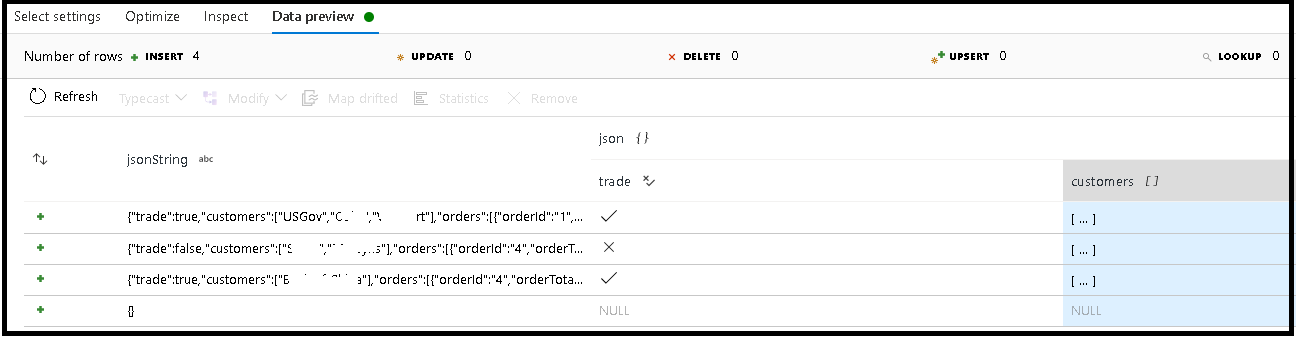
En este ejemplo, hemos definido el análisis del campo de entrada "jsonString", que es texto sin formato, pero con formato de estructura JSON. Vamos a almacenar los resultados analizados como JSON en una nueva columna denominada "json" con este esquema:
(trade as boolean, customers as string[])
Consulte la pestaña de inspección y la vista previa de los datos para comprobar que la salida se ha asignado correctamente.
Use la actividad Columna derivada para extraer datos jerárquicos (es decir, your_complex_column_name.car.model en el campo de expresión)
Ejemplos
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Script de flujo de datos
Sintaxis
Ejemplos
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Contenido relacionado
- Use la transformación Aplanar para dinamizar las filas en columnas.
- Use la Transformación de una columna derivada para transformar las columnas en filas.