Creación de un desencadenador que ejecuta una canalización en respuesta a un evento de almacenamiento
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describen los desencadenadores de eventos de almacenamiento que puede crear en las canalizaciones de Azure Data Factory o Azure Synapse Analytics.
La arquitectura dirigida por eventos es un patrón de integración de datos común que implica la producción, detección, consumo y reacción a los eventos. Los escenarios de integración de datos suelen requerir que los clientes desencadenen canalizaciones que se desencadenen desde eventos en una cuenta de Azure Storage, como la llegada o eliminación de un archivo en la cuenta de Azure Blob Storage. Las canalizaciones de Data Factory y Azure Synapse Analytics se integran de forma nativa con Azure Event Grid, lo que le permite desencadenar canalizaciones en estos eventos.
Consideraciones sobre desencadenadores de eventos de almacenamiento
Tenga en cuenta los siguientes puntos al usar desencadenadores de eventos de almacenamiento:
- La integración descrita en este artículo depende de Azure Event Grid. Asegúrese de que el proveedor de la suscripción se registra con el proveedor de recursos de Event Grid. Para más información, consulte Tipos y proveedores de recursos. Debe poder realizar la acción
Microsoft.EventGrid/eventSubscriptions/. Esta acción forma parte del rol integradoEventGrid EventSubscription Contributor. - Si usa esta característica en Azure Synapse Analytics, asegúrese de registrar también la suscripción con el proveedor de recursos de Data Factory. De lo contrario, recibirá un mensaje que indica que se produjo un error en la creación de una suscripción de eventos."
- Si la cuenta de Blob Storage reside detrás de un punto de conexión privado y bloquea el acceso a la red pública, debe configurar reglas de red para permitir las comunicaciones de Blob Storage a Event Grid. Puede conceder acceso de almacenamiento a servicios de Azure de confianza, como Event Grid, siguiendo Documentación de Storage, o configurar puntos de conexión privados para Event Grid que se asignan a un espacio de direcciones de red virtual, siguiendo Documentación de Event Grid.
- Actualmente, el desencadenador de eventos de almacenamiento solo admite cuentas de almacenamiento de Azure Data Lake Storage Gen2 y de uso general versión 2. Si está trabajando con eventos de almacenamiento del Protocolo de transferencia de archivos seguros (SFTP), también debe especificar la API de datos SFTP en la sección de filtrado. Debido a una limitación de Event Grid, Data Factory solo admite un máximo de 500 desencadenadores de eventos de almacenamiento por cuenta de almacenamiento.
- Para crear un nuevo desencadenador de eventos de almacenamiento o modificar uno existente, la cuenta de Azure que usa para iniciar sesión en el servicio y publicar el desencadenador de eventos de almacenamiento debe tener el permiso de control de acceso basado en rol (RBAC de Azure) adecuado en la cuenta de almacenamiento. No se requieren otros permisos. La entidad de servicio de Azure Data Factory y Azure Synapse Analytics no necesita permiso especial para la cuenta de almacenamiento o Event Grid. Para obtener más información sobre el control de acceso, consulte la sección Control de acceso basado en roles.
- Si ha aplicado un bloqueo de Azure Resource Manager a la cuenta de almacenamiento, puede afectar a la capacidad del desencadenador de blobs para crear o eliminar blobs. Un bloqueo
ReadOnlyimpide la creación y eliminación, mientras que un bloqueoDoNotDeleteimpide la eliminación. Asegúrese de tener en cuenta estas restricciones para evitar problemas con los desencadenadores. - No se recomiendan desencadenadores de llegada de archivos como mecanismo de desencadenamiento de receptores de flujo de datos. Los flujos de datos realizan una serie de tareas de orden aleatorio de archivos de cambio de nombre y partición de archivos en la carpeta de destino que pueden desencadenar accidentalmente un evento de llegada de archivos antes del procesamiento completo de los datos.
Creación de un desencadenador con la interfaz de usuario
En esta sección se muestra cómo crear un desencadenador de eventos de almacenamiento en la interfaz de usuario (UI) de canalización de Azure Data Factory y Azure Synapse Analytics.
Cambie a la pestaña Editar en Data Factory o en la pestaña Integrar de Azure Synapse Analytics.
En el menú, seleccione Desencadenador, y a continuación, seleccione Nuevo o editar.
En la página para agregar desencadenadores, seleccione Elegir desencadenador y, después, Nuevo.
Seleccione el tipo de desencadenador Eventos de almacenamiento.
Seleccione la cuenta de almacenamiento en la lista desplegable suscripción de Azure o manualmente mediante su identificador de recurso de cuenta de almacenamiento. Elija el contenedor en el que desea que se produzcan los eventos. Se requiere la selección de contenedor, pero seleccionar todos los contenedores puede provocar un gran número de eventos.
Las propiedades
Blob path begins withyBlob path begins withpermiten especificar los contenedores, carpetas y nombres de blob para los que desea recibir eventos. El desencadenador de eventos de almacenamiento requiere que se defina al menos una de estas propiedades. Puede usar varios patrones para las propiedadesBlob path begins withyBlob path begins with, como se muestra en los ejemplos que se muestran más adelante en este artículo.Blob path begins with: la ruta de acceso del blob debe comenzar con una ruta de acceso de carpeta. Entre los valores válidos se incluyen2018/y2018/april/shoes.csv. No se puede seleccionar este campo si no se ha seleccionado un contenedor.Blob path begins with: la ruta de acceso del blob debe terminar con un nombre de archivo o una extensión. Entre los valores válidos se incluyenshoes.csvy.csv. Los nombres de contenedor y carpeta, cuando se especifica, deben estar separados por un segmento/blobs/. Por ejemplo, un contenedor denominadoorderspuede tener un valor/orders/blobs/2018/april/shoes.csv. Para especificar una carpeta en cualquier contenedor, omita el carácter/" inicial. Por ejemplo,april/shoes.csvdesencadena un evento en cualquier archivo denominadoshoes.csven una carpeta denominadaaprilen cualquier contenedor.
Tenga en cuenta que
Blob path begins withyBlob path ends withson la única coincidencia de patrones permitida en un desencadenador de eventos de almacenamiento. No se admiten otros tipos de coincidencia de caracteres comodín para el tipo de desencadenador.Seleccione si el desencadenador responde a un evento de Blob creado, un evento de Blob eliminado o ambos. En la ubicación de almacenamiento especificada, cada evento desencadena las canalizaciones de Data Factory y Azure Synapse Analytics asociadas al desencadenador.
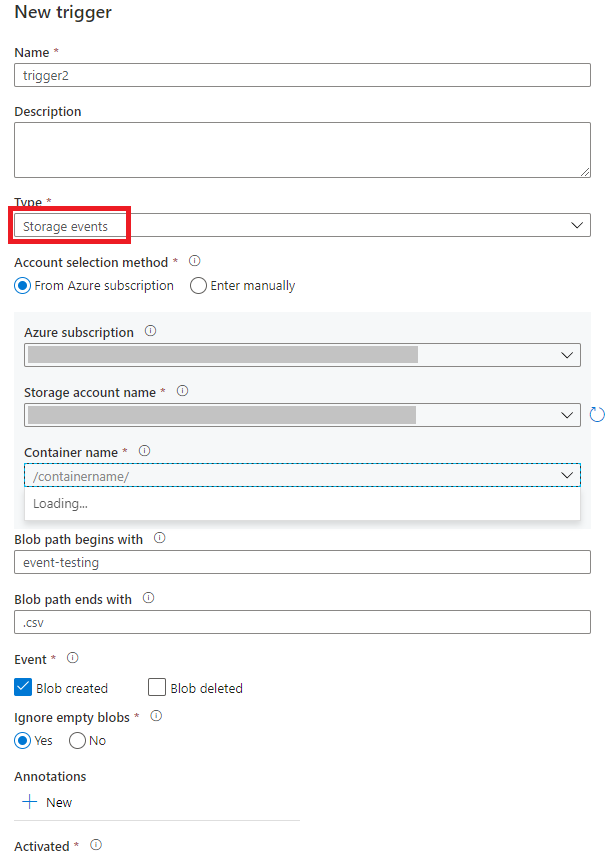
Seleccione si el desencadenador omitirá o no los blobs con cero bytes.
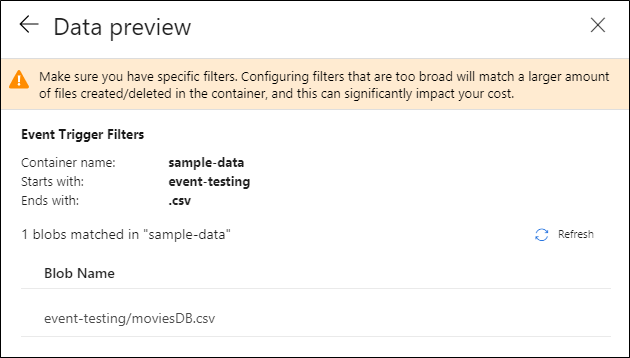
Después de configurar el desencadenador, seleccione Siguiente: vista previa de datos. Esta pantalla muestra los blobs existentes que coinciden con la configuración del desencadenador de eventos de almacenamiento. Asegúrese de que tiene filtros específicos. La configuración de filtros demasiado amplios puede coincidir con un gran número de archivos creados o eliminados y podría afectar significativamente al costo. Una vez comprobadas las condiciones de filtro, seleccione Finalizar.
Para asociar una canalización a este desencadenador, vaya al lienzo de la canalización y seleccione Desencadenador>Nuevo o Editar. Cuando aparezca el panel lateral, seleccione la lista desplegable Elegir desencadenador y seleccione el desencadenador que ha creado. Seleccione Siguiente: Vista previa de datos para confirmar que la configuración es correcta. A continuación, seleccione Siguiente para validar que la vista previa de datos es correcta.
Si la canalización tiene parámetros, puede especificarlos en el panel lateral Desencadenador de parámetros de ejecución. El desencadenador de eventos de almacenamiento captura el nombre de archivo y la ruta de acceso del blob en las propiedades
@triggerBody().folderPathy@triggerBody().fileName. Para usar los valores de estas propiedades en una canalización, debe asignar las propiedades a los parámetros de la canalización. Después de asignar las propiedades a parámetros, puede acceder a los valores capturados por el desencadenador a través de la expresión@pipeline().parameters.parameterNameen toda la canalización. Para obtener una explicación detallada, consulte Metadatos del desencadenador de referencia en canalizaciones.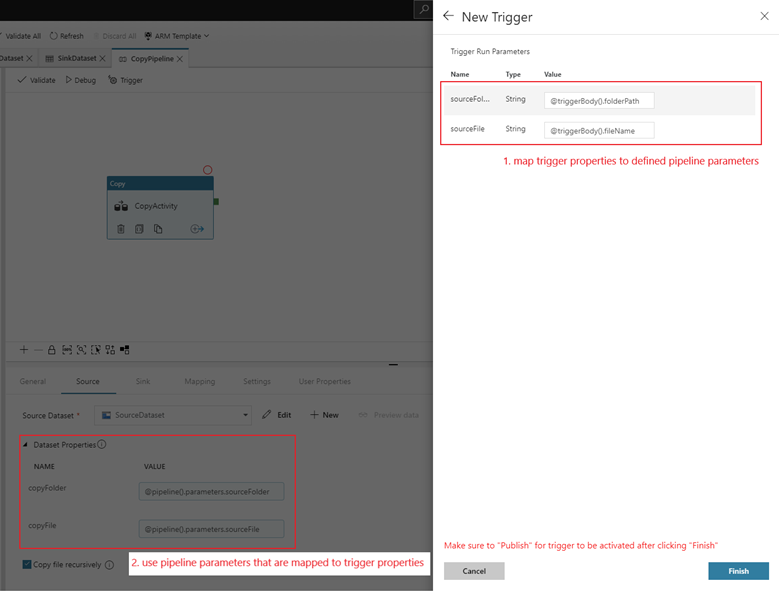
En el ejemplo anterior, el desencadenador está configurado para activarse cuando se crea una ruta de acceso de blob que termina en .csv en la carpeta prueba-de-eventos en el contenedor datos-de-ejemplo. Las propiedades
folderPathyfileNamecapturan la ubicación del nuevo blob. Por ejemplo, cuando se agrega MoviesDB.csv a la ruta de acceso sample-data/event-testing,@triggerBody().folderPathtiene un valor desample-data/event-testingy@triggerBody().fileNametiene un valor demoviesDB.csv. Estos valores se asignan, en el ejemplo, a los parámetros de canalizaciónsourceFolderysourceFile, que se pueden usar en toda la canalización como@pipeline().parameters.sourceFoldery@pipeline().parameters.sourceFile, respectivamente.Cuando haya terminado, seleccione Finalizar.


Esquema JSON
En la tabla siguiente se proporciona información general sobre los elementos de esquema relacionados con los desencadenadores de eventos de almacenamiento.
| Elemento JSON | Descripción | Tipo | Valores permitidos | Obligatorio |
|---|---|---|---|---|
| scope | Identificador de recurso de Azure Resource Manager de la cuenta de almacenamiento. | String | Identificador de Azure Resource Manager | Sí. |
| events | El tipo de eventos que provocan la activación de este desencadenador. | Matriz | Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Sí, cualquier combinación de estos valores. |
blobPathBeginsWith |
La ruta de acceso del blob debe comenzar con el patrón proporcionado para que se active el desencadenador. Por ejemplo, /records/blobs/december/ solo activa el desencadenador de blobs en la carpeta december bajo el contenedor records. |
String | Proporcione un valor para al menos una de estas propiedades: blobPathBeginsWith o blobPathEndsWith. |
|
blobPathEndsWith |
La ruta de acceso del blob debe finalizar con el patrón proporcionado para que se active el desencadenador. Por ejemplo, december/boxes.csv solo activa el desencadenador de blobs denominado "boxes" en una carpeta december. |
String | Proporcione un valor para al menos una de estas propiedades: blobPathBeginsWith o blobPathEndsWith. |
|
ignoreEmptyBlobs |
Si los blobs de bytes cero desencadenan o no una ejecución de canalización. De manera predeterminada, se establece en true. |
Boolean | true o false | No. |
Ejemplos de desencadenadores de eventos de almacenamiento
En esta sección encontrará ejemplos de configuración de desencadenadores de eventos de almacenamiento.
Importante
Debe incluir el segmento /blobs/ de la ruta de acceso, tal como se muestra en los siguientes ejemplos, siempre que especifique el contenedor y la carpeta, el contenedor y el archivo, o el contenedor, la carpeta y el archivo. Para blobPathBeginsWith, la interfaz de usuario agrega automáticamente /blobs/ entre la carpeta y el nombre del contenedor en el JSON del desencadenador.
| Propiedad | Ejemplo | Descripción |
|---|---|---|
Blob path begins with |
/containername/ |
Recibe eventos de cualquier blob del contenedor. |
Blob path begins with |
/containername/blobs/foldername/ |
Recibe eventos de los blobs en el contenedor containername y la carpeta foldername. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
También puede hacer referencia a una subcarpeta. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Recibe eventos de un blob denominado file.txt en la carpeta foldername, en el contenedor containername. |
Blob path ends with |
file.txt |
Recibe eventos para un blob denominado file.txt en cualquier ruta de acceso. |
Blob path ends with |
/containername/blobs/file.txt |
Recibe eventos de un blob denominado file.txt en la carpeta containername en cualquier contenedor. |
Blob path ends with |
foldername/file.txt |
Recibe eventos de un blob denominado file.txt en la carpeta foldername en cualquier contenedor. |
Control de acceso basado en rol
Las canalizaciones de Data Factory y Azure Synapse Analytics usan el control de acceso basado en roles de Azure (Azure RBAC) para garantizar que el acceso no autorizado para escuchar, suscribirse a actualizaciones y activar canalizaciones vinculadas a eventos de blob esté estrictamente prohibido.
- Para crear correctamente un nuevo desencadenador de eventos de almacenamiento o actualizar uno existente, la cuenta de Azure que inició sesión en el servicio debe tener el acceso adecuado a la cuenta de almacenamiento correspondiente. De lo contrario, se produce un error en la operación con el mensaje "Acceso denegado".
- Data Factory y Azure Synapse Analytics no necesitan ningún permiso especial para la instancia de Event Grid y no necesitan asignar un permiso RBAC especial a la entidad de servicio de Data Factory o Azure Synapse Analytics para la operación.
Cualquiera de las siguientes opciones de configuración de RBAC funciona para desencadenadores de eventos de almacenamiento:
- Rol de propietario en la cuenta de almacenamiento
- Rol de colaborador de la cuenta de almacenamiento
Microsoft.EventGrid/EventSubscriptions/Writepermiso para la cuenta de almacenamiento/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Específicamente:
- Al crear en la factoría de datos (por ejemplo, en el entorno de desarrollo), la cuenta de Azure que inició sesión debe tener el permiso anterior.
- Al publicar a través de integración continua y entrega continua, la cuenta usada para publicar la plantilla de Azure Resource Manager en la factoría de pruebas o producción debe tener el permiso anterior.
Para comprender cómo el servicio ofrece las dos promesas, vamos a dar un paso atrás y echar un vistazo en segundo plano. Estos son los flujos de trabajo de alto nivel para la integración entre Data Factory/Azure Synapse Analytics, Storage y Event Grid.
Creación de un desencadenador de eventos de almacenamiento
Este flujo de trabajo de alto nivel describe cómo Interactúa Data Factory con Event Grid para crear un desencadenador de eventos de almacenamiento. El flujo de datos es el mismo en Azure Synapse Analytics, con canalizaciones de Azure Synapse Analytics que toman el rol de la factoría de datos en el diagrama siguiente.
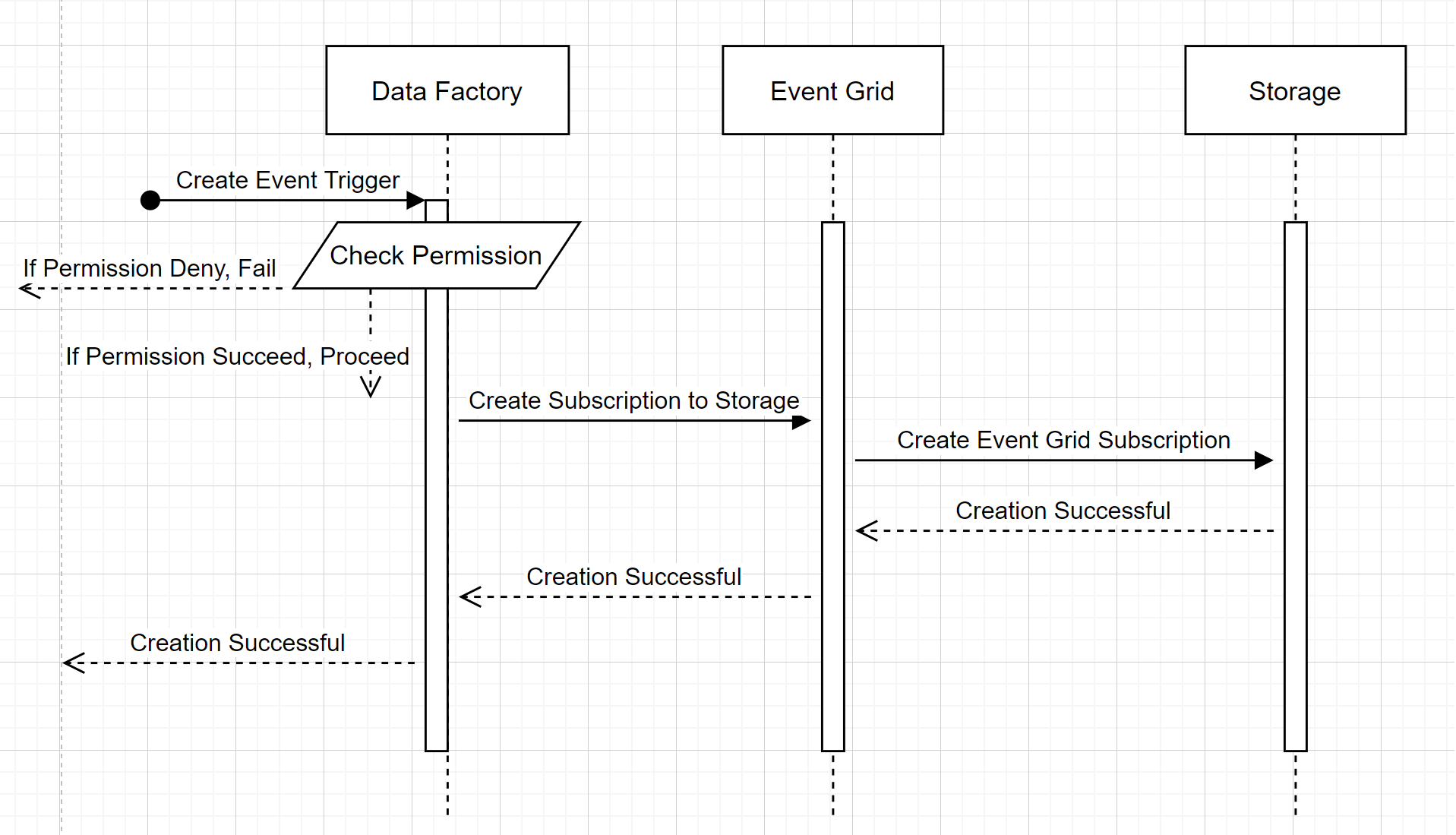
Dos llamadas notables de los flujos de trabajo:
- Data Factory y Azure Synapse Analytics hacen que no contacto directo con la cuenta de almacenamiento. En su lugar, Event Grid retransmite y procesa la solicitud para crear una suscripción. El servicio no necesita permiso para acceder a la cuenta de almacenamiento de este paso.
- El control de acceso y la comprobación de permisos se realizarán dentro del servicio. Antes de que el servicio envíe una solicitud para suscribirse a un evento de almacenamiento, comprueba el permiso para el usuario. Más concretamente, comprueba si la cuenta de Azure que ha iniciado sesión e intenta crear el desencadenador de eventos de almacenamiento tiene el acceso adecuado a la cuenta de almacenamiento correspondiente. Si se produce un error en la comprobación de permisos, la creación del desencadenador también produce un error.
Ejecución de canalización de desencadenador de eventos de almacenamiento
Este flujo de trabajo de alto nivel describe cómo se ejecutan las canalizaciones de desencadenador de eventos de almacenamiento a través de Event Grid. Para Azure Synapse Analytics, el flujo de datos es el mismo, con canalizaciones de Azure Synapse Analytics que toman el rol de Data Factory en el diagrama siguiente.
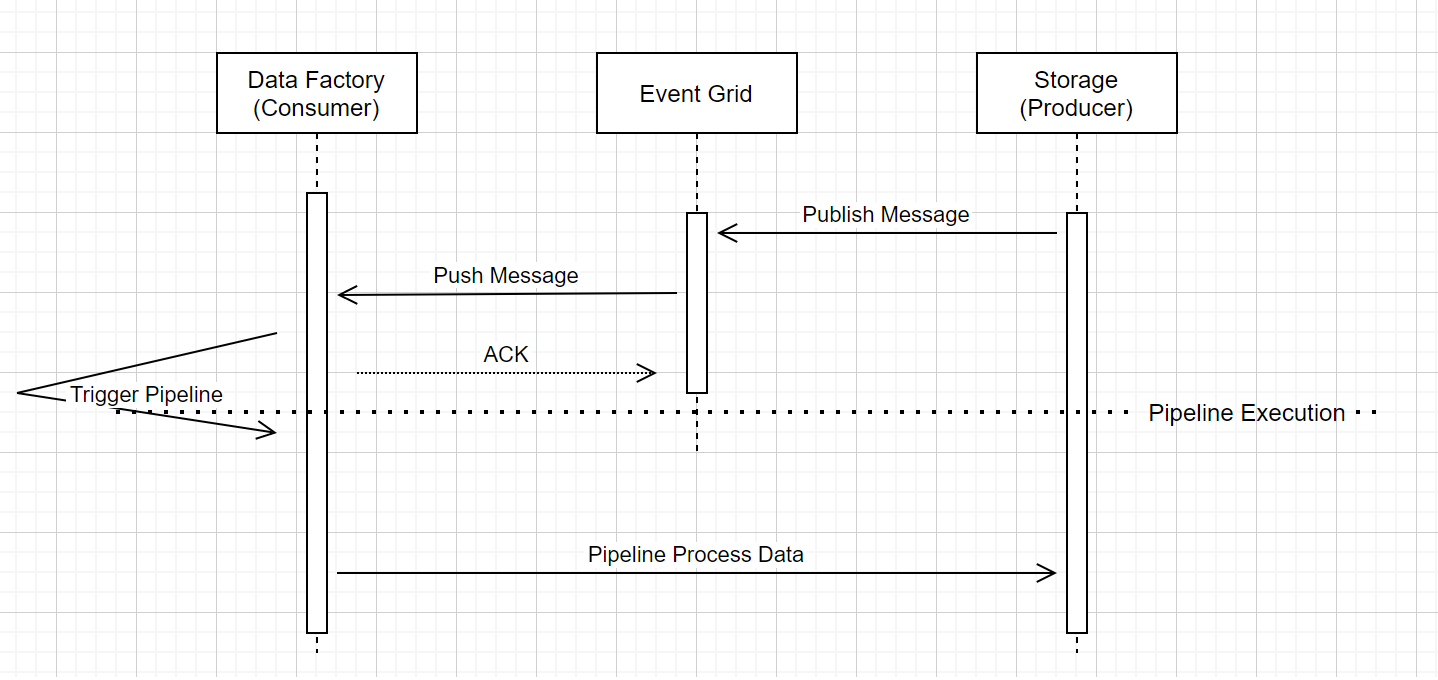
Tres llamadas notables en el flujo de trabajo están relacionadas con las canalizaciones de desencadenamiento de eventos dentro del servicio:
Event Grid usa un modelo de inserción que retransmite el mensaje lo antes posible cuando el almacenamiento lo coloca en el sistema. Este enfoque es diferente de un sistema de mensajería, como Kafka, donde se usa un sistema de extracción.
El desencadenador de eventos actúa como agente de escucha activo para el mensaje entrante y desencadena correctamente la canalización asociada.
El propio desencadenador de eventos de almacenamiento no realiza ningún contacto directo con la cuenta de almacenamiento.
- Si tiene una actividad de copia u otra actividad dentro de la canalización para procesar los datos de la cuenta de almacenamiento, el servicio se pone en contacto directo con la cuenta de almacenamiento mediante las credenciales almacenadas en el servicio vinculado. Asegúrese de que el servicio vinculado esté configurado correctamente.
- Si no hace referencia a la cuenta de almacenamiento de la canalización, no es necesario conceder permiso al servicio para acceder a la cuenta de almacenamiento.
Contenido relacionado
- Para obtener más información sobre los desencadenadores, consulte ejecución y desencadenadores de canalización.
- Para hacer referencia a los metadatos del desencadenador en una canalización, consulte Metadatos del desencadenador de referencia en ejecuciones de canalización.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de