Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
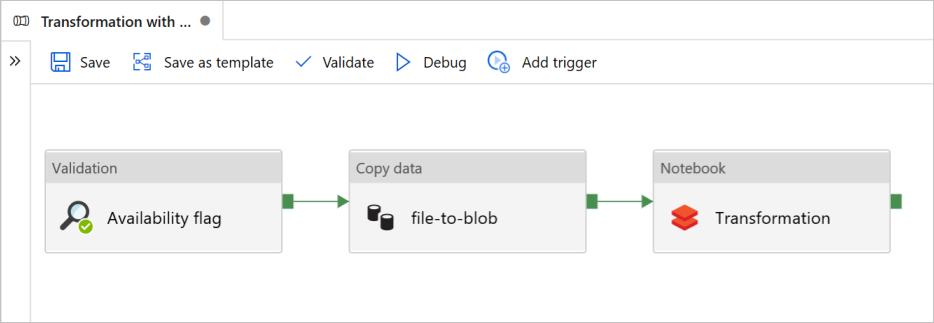
En este tutorial, creará una canalización integral que contiene las actividades de Validación, Copia de datos y Notebook en Azure Data Factory.
Validation garantiza que el conjunto de datos de origen esté listo para el consumo subsecuente antes de iniciar el trabajo de copia y análisis.
Copiar datos (Copy data) duplica el conjunto de datos de origen en el almacenamiento receptor, que se monta como DBFS en el cuaderno de Azure Databricks. De esta manera, el conjunto de datos puede ser consumido directamente por Spark.
Notebook: desencadena el cuaderno de Databricks que transforma el conjunto de datos. También agrega el conjunto de datos a una carpeta procesada o Azure Synapse Analytics.
Por motivos de simplicidad, la plantilla de este tutorial no crea un desencadenador programado. Puede agregar uno si es necesario.
Requisitos previos
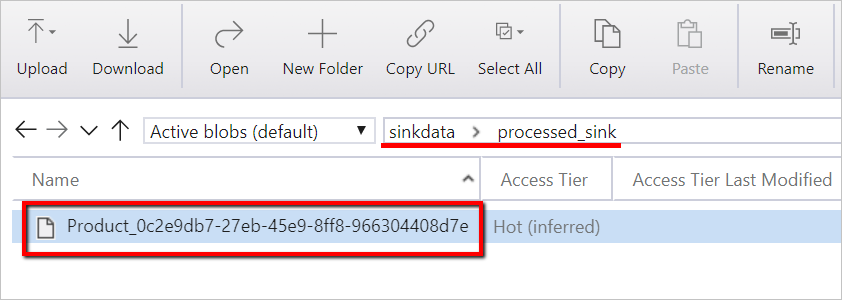
Una cuenta de Azure Blob Storage con un contenedor llamado
sinkdatapara su uso como receptor.Anote el nombre de la cuenta de almacenamiento, el nombre del contenedor y la clave de acceso. Los necesitará más adelante en la plantilla.
Un área de trabajo de Azure Databricks.
Importar un cuaderno para la transformación
Para importar un cuaderno de Transformation al área de trabajo de Databricks:
Inicie sesión en el área de trabajo de Azure Databricks.
Haga clic con el botón derecho en una carpeta del área de trabajo y seleccione Importar.
Seleccione Importar desde: URL. En el cuadro de texto, escriba
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.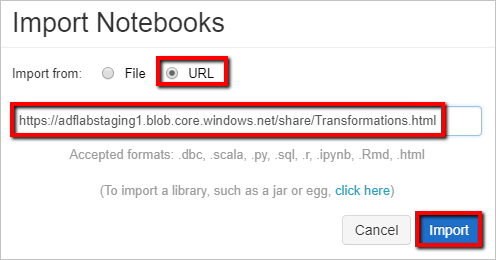
Actualicemos el cuaderno de Transformation con la información de la conexión de almacenamiento.
En el cuaderno importado, vaya a command 5 (comando 5), como se muestra en el siguiente fragmento de código.
- Reemplace
<storage name>y<access key>por su propia información de conexión de almacenamiento. - Use la cuenta de almacenamiento con el contenedor
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Reemplace
Genere un token de acceso de Databricks para Data Factory para acceder a Databricks.
- En el área de trabajo de Azure Databricks, seleccione el nombre de usuario Azure Databricks en la barra superior y, a continuación, seleccione Configuración en la lista desplegable.
- Seleccione Programador.
- Después, junto a Tokens de acceso, seleccione Administrar.
- Seleccione Generar nuevo token.
- (Opcional) Escriba un comentario que le ayude a identificar este token en el futuro y cambie la duración predeterminada del token de 90 días. Para crear un token sin duración (no recomendado), deje el cuadro Duración (días) vacío (en blanco).
- Selecciona Generar.
- Copie el token mostrado en una ubicación segura y, a continuación, seleccione Listo.
Guarde el token de acceso para usarlo más adelante en la creación de un servicio vinculado de Databricks. El token de acceso será similar a dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Uso de esta plantilla
Vaya a la plantilla Transformation con Azure Databricks y cree nuevos servicios vinculados para las siguientes conexiones.
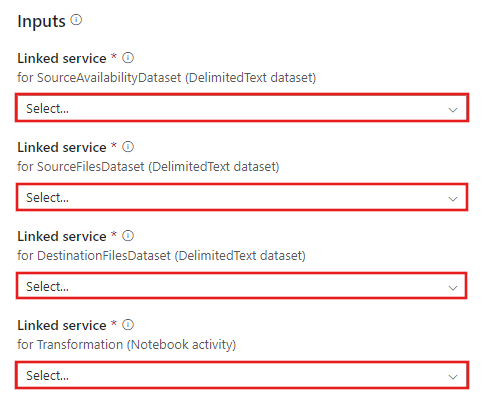
Conexión al blob de origen: para acceder a los datos de origen.
Para este ejercicio, puede usar el almacenamiento de blobs público que contiene los archivos de origen. Tome como referencia la siguiente captura de pantalla para la configuración. Use la siguiente dirección URL de SAS para conectarse al almacenamiento de origen (acceso de solo lectura):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D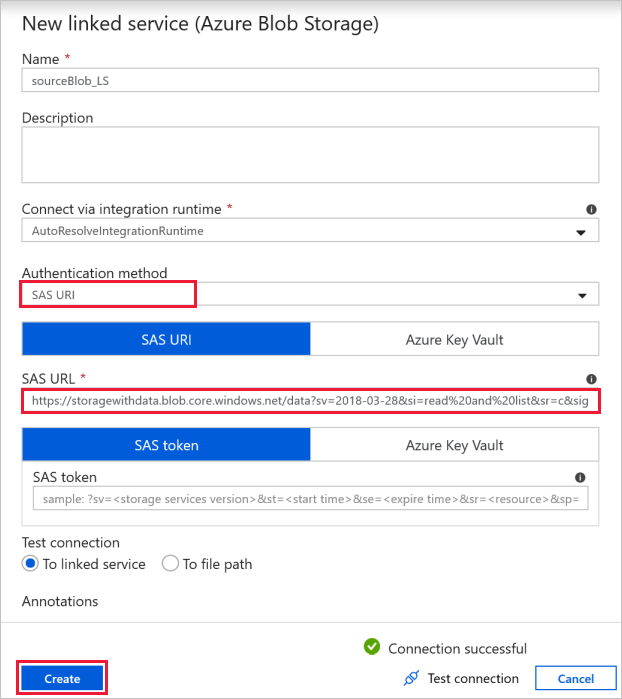
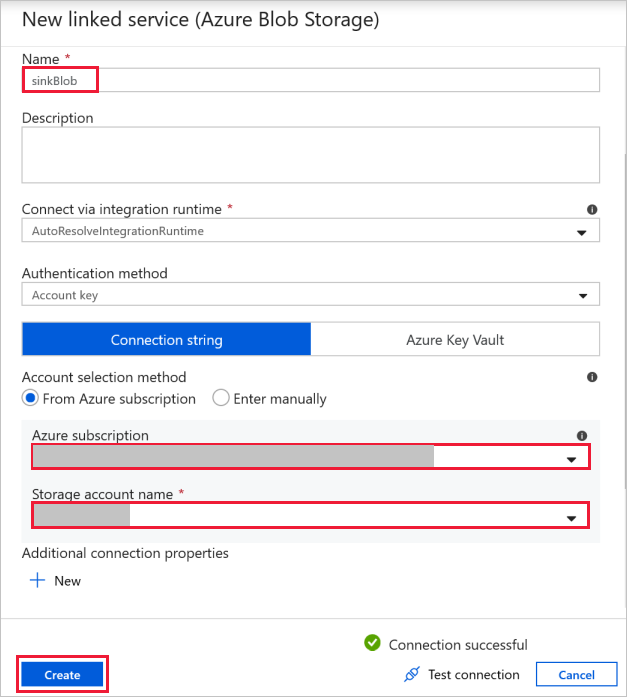
Conexión al blob de destino: para almacenar los datos copiados.
En la ventana Nuevo servicio vinculado, seleccione su blob de almacenamiento de destino.
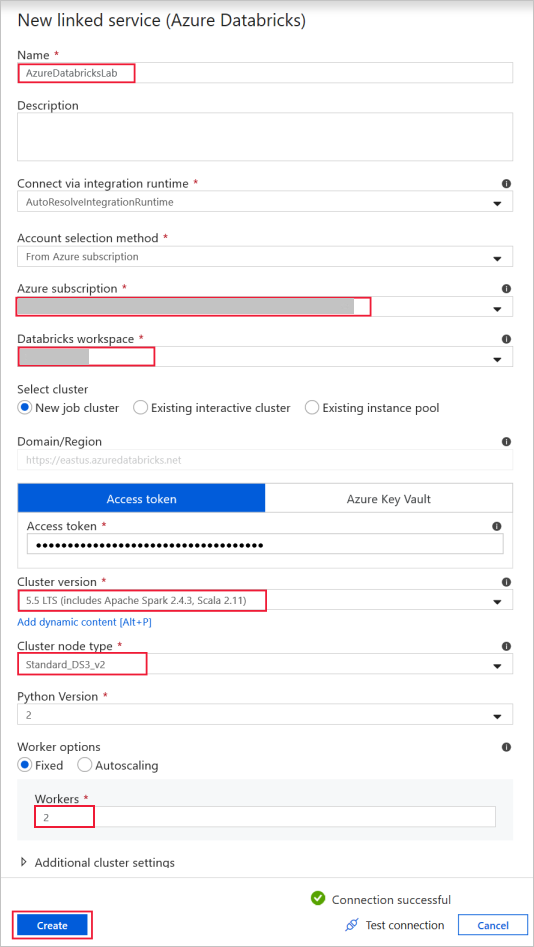
Azure Databricks: para conectarse al clúster de Databricks.
Cree un servicio vinculado de Databricks con la clave de acceso que ha generado anteriormente. Puede seleccionar un clúster interactivo si tiene uno. En este ejemplo se usa la opción New job cluster (Nuevo clúster de trabajo).
Seleccione Usar esta plantilla. Verá que se ha creado una canalización.
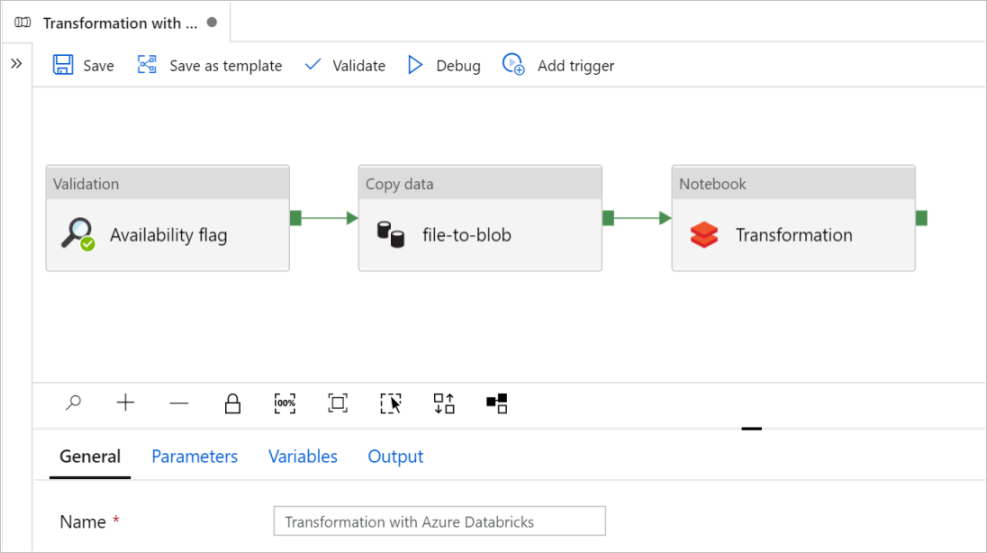
Introducción y configuración de canalizaciones
En la nueva canalización, la mayoría de las opciones se han configurado automáticamente con los valores predeterminados. Revise las configuraciones de la canalización y realice los cambios necesarios.
En la actividad Validation llamada Availability flag (Marca de disponibilidad), compruebe que el valor del conjunto de datos de origen sea el conjunto
SourceAvailabilityDatasetque ha creado anteriormente.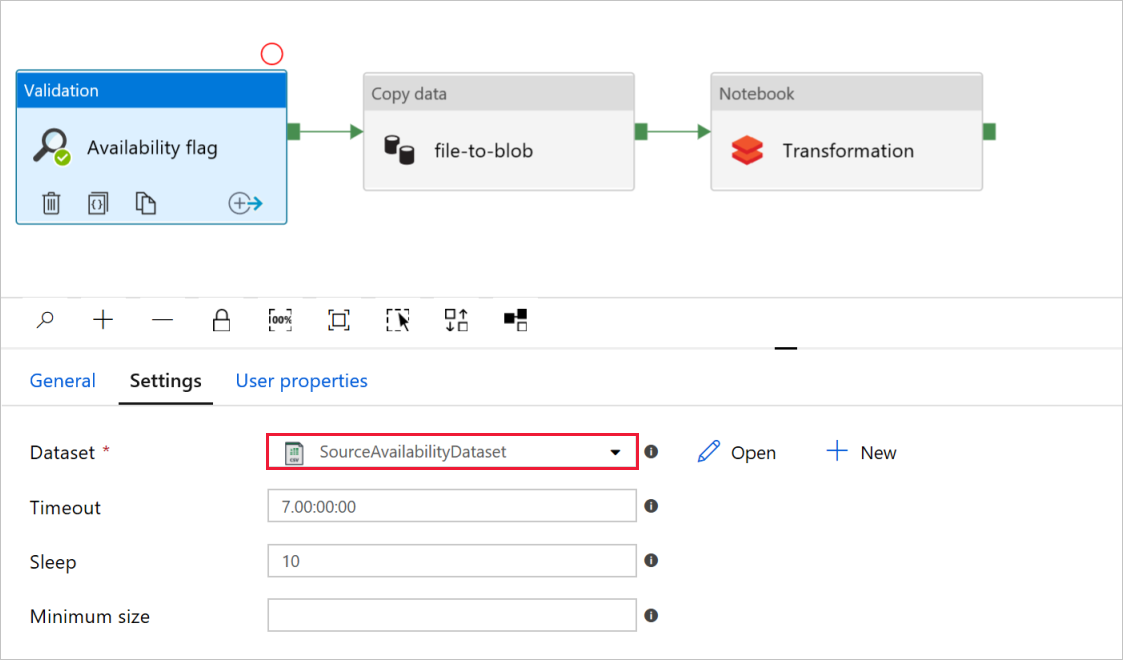
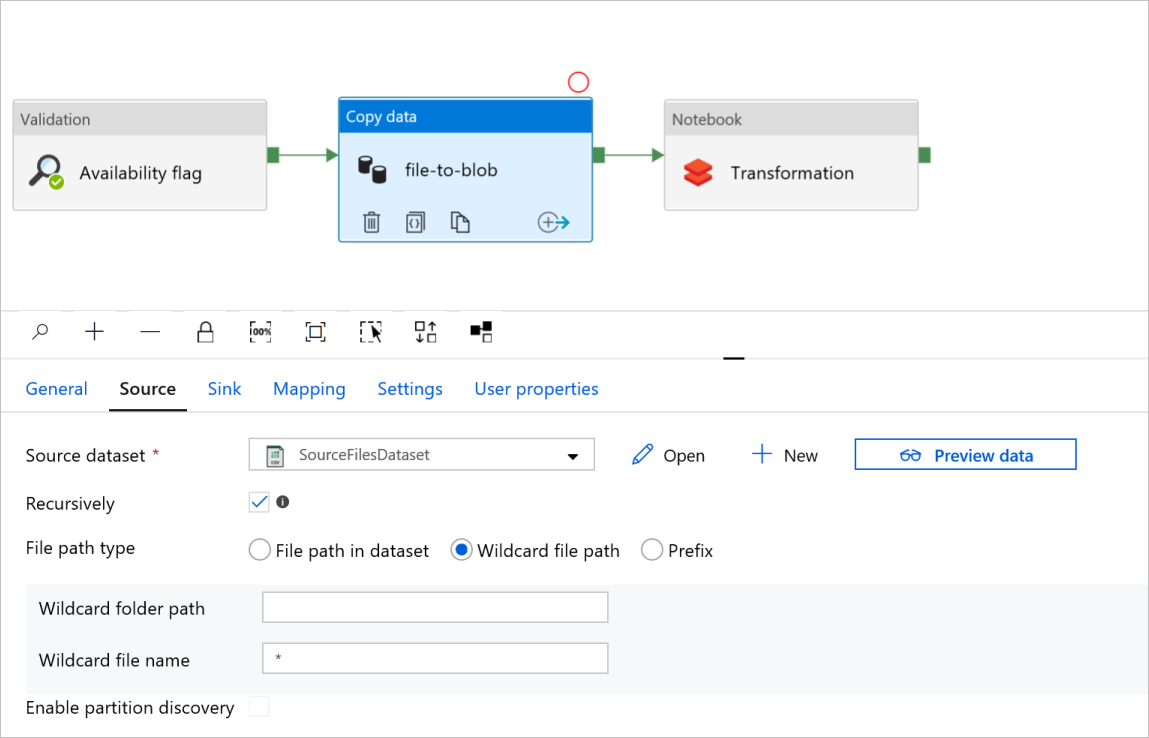
En la actividad Copy data llamada file-to-blob (de archivo a blob), compruebe las pestañas Source (Origen) y Sink (Receptor). Cambie la configuración si es necesario.
Source tab
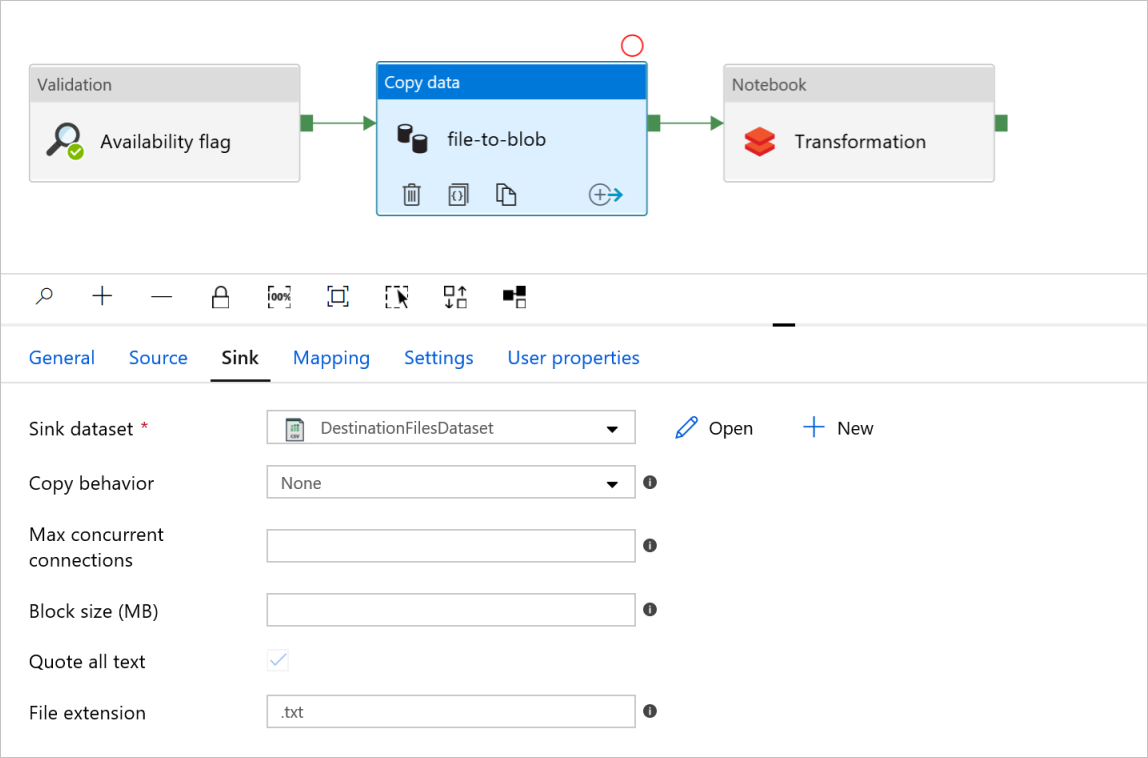
Pestaña Sink (Receptor)
En la actividad NotebookTransformation, revise y actualice las rutas y la configuración según sea necesario.
El campo Servicio vinculado de Databricks debería estar rellenado previamente con el valor de un paso anterior, como se muestra aquí:
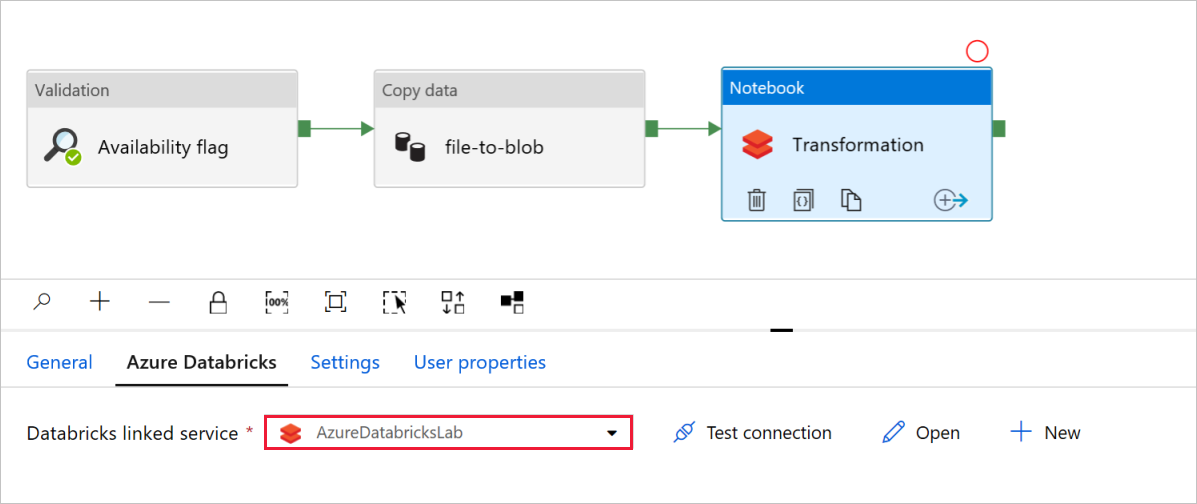
Para comprobar la configuración de Notebook:
Seleccione la pestaña Configuración. En Ruta del cuaderno, compruebe que la ruta predeterminada es correcta. Es posible que necesite examinar y elegir la ruta de acceso correcta del cuaderno.
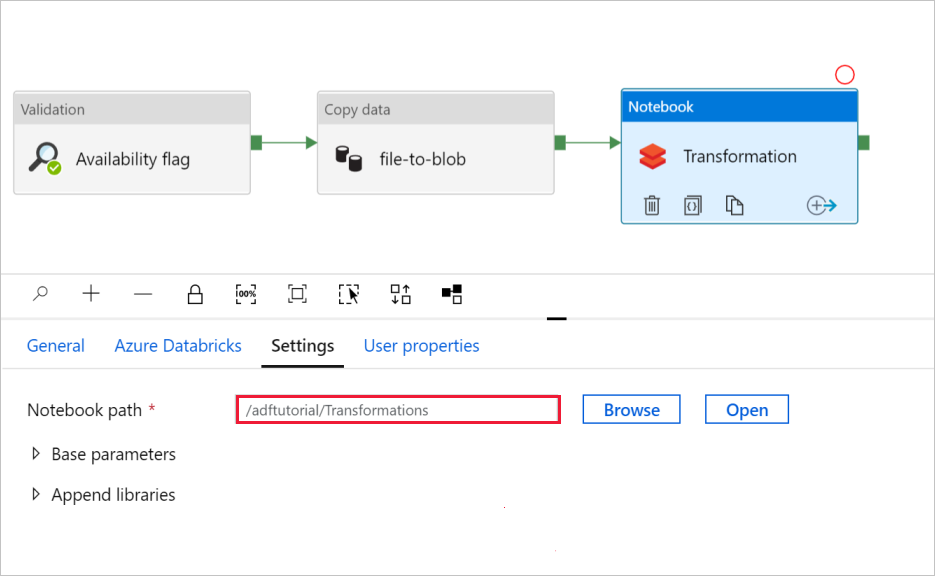
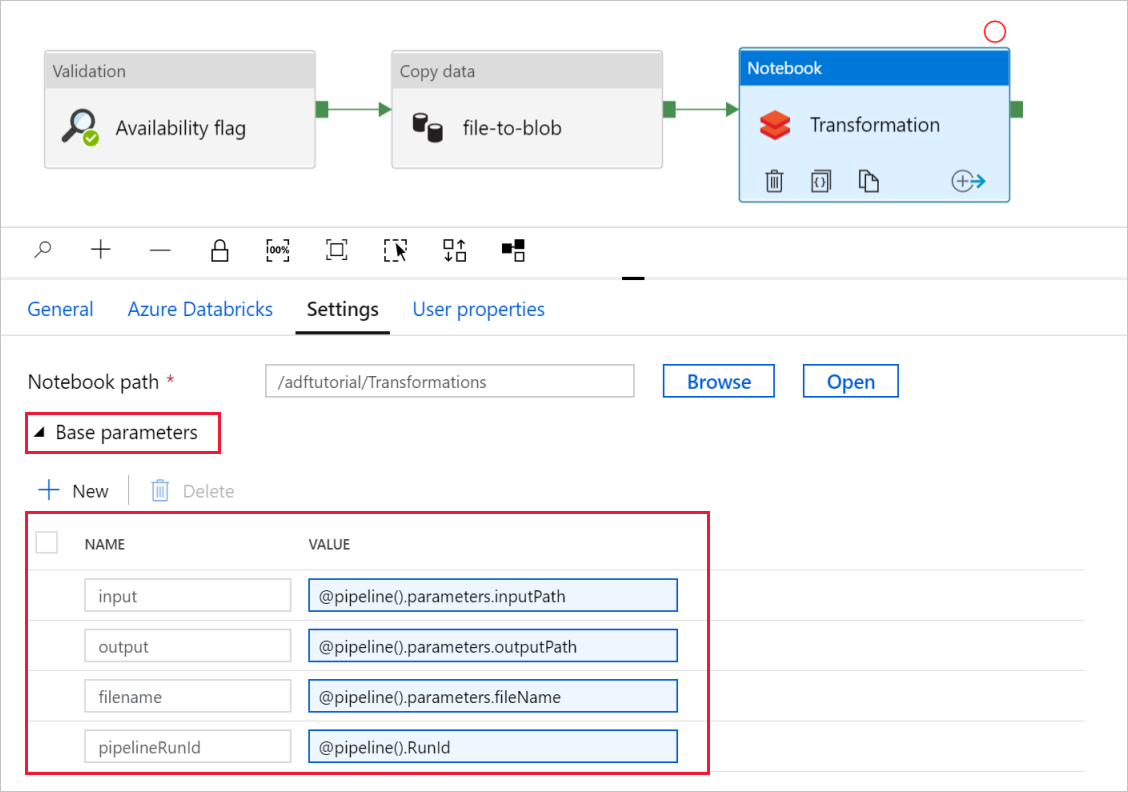
Expanda el selector Base Parameters (Parámetros base) y compruebe que los parámetros coinciden con lo que se muestra en la siguiente captura de pantalla. Estos parámetros se pasan al cuaderno de Databricks desde Data Factory.
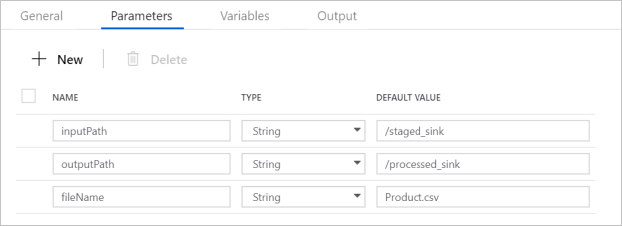
Compruebe que los parámetros de canalización coinciden con los que aparecen en la siguiente captura de pantalla:
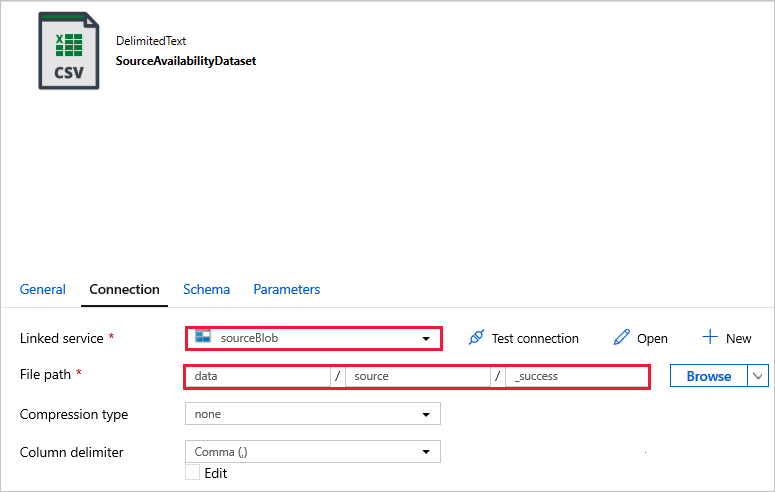
Conéctese a sus conjuntos de datos.
Nota
En los siguientes conjuntos de datos, la ruta de acceso del archivo se ha especificado automáticamente en la plantilla. Si se requiere algún cambio, asegúrese de especificar la ruta de acceso para el contenedor y el directorio en caso de error de conexión.
SourceAvailabilityDataset: para comprobar si los datos de origen están disponibles.
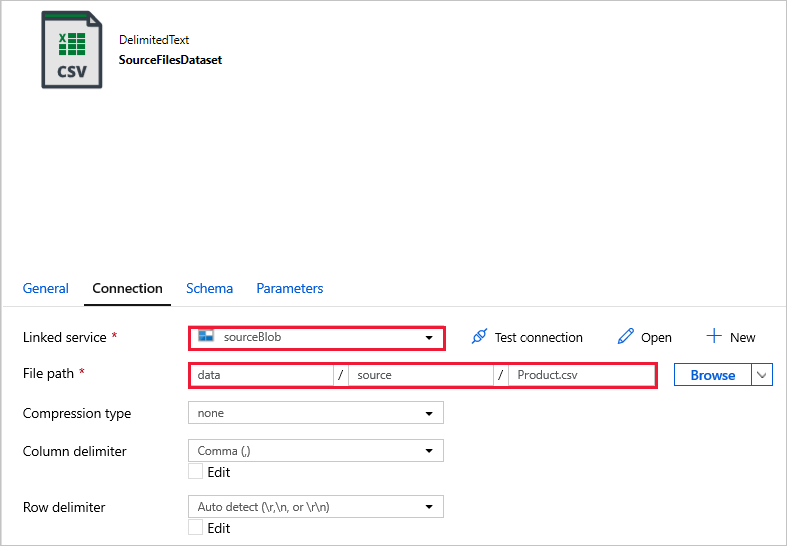
SourceFilesDataset: para acceder a los datos de origen.
DestinationFilesDataset: sirve para copiar los datos en la ubicación de destinos del receptor. Use los valores siguientes:
Linked service - (Servicio vinculado):
sinkBlob_LS, creado en un paso anterior.File path - (Ruta de acceso del archivo):
sinkdata/staged_sink.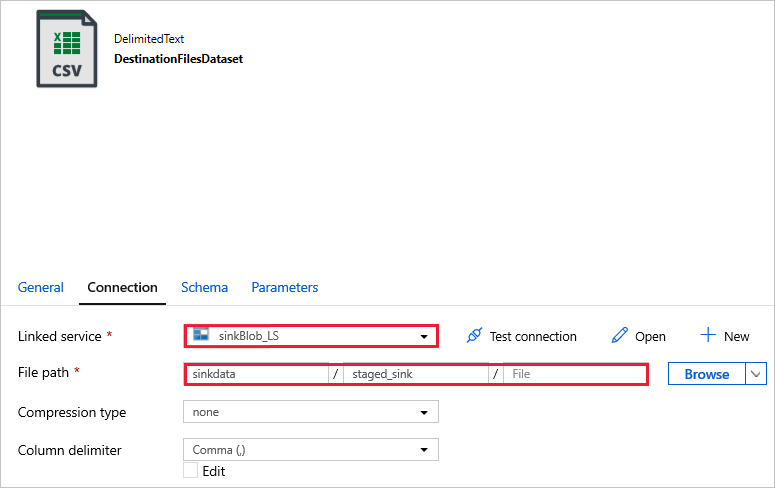
Seleccione Debug para ejecutar la canalización. Puede consultar el vínculo a los registros de Databricks si quiere obtener registros de Spark más detallados.
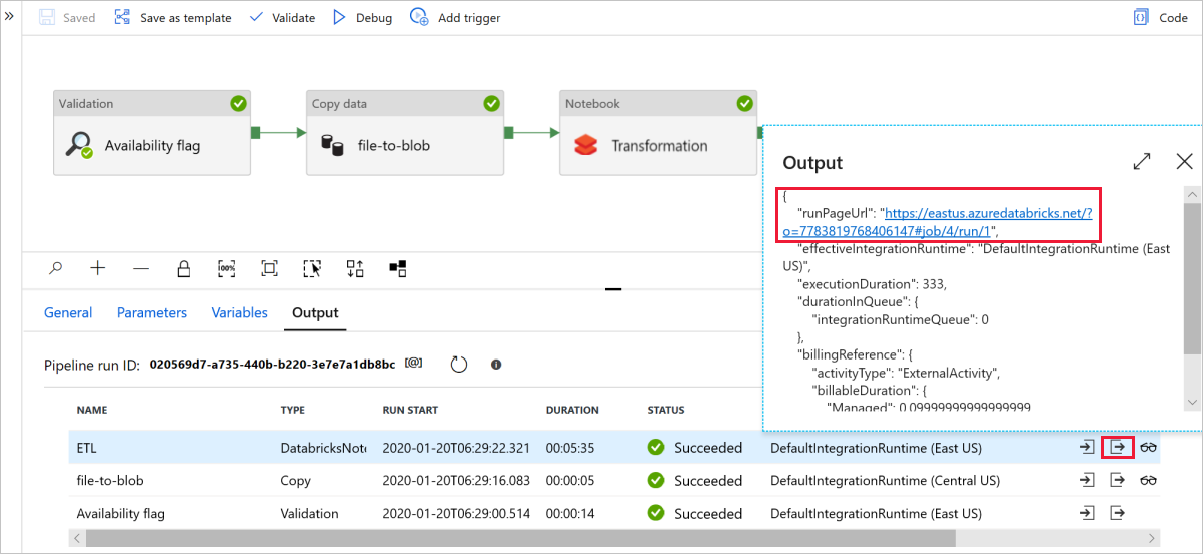
También puede comprobar el archivo de datos mediante Azure Storage Explorer.
Nota
Para correlacionar con las ejecuciones de canalización de Data Factory, este ejemplo agrega el ID de ejecución de la canalización de Data Factory a la carpeta de salida. Esto ayuda a hacer un seguimiento de los archivos generados por cada ejecución.