Carga incremental de datos de varias tablas de SQL Server en Azure SQL Database mediante Azure Portal
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial creará una instancia de Azure Data Factory con una canalización que carga los datos diferenciales de varias tablas de una base de datos de SQL Server en Azure SQL Database.
En este tutorial, realizará los siguientes pasos:
- Preparación de los almacenes de datos de origen y de destino
- Creación de una factoría de datos.
- Cree una instancia de Integration Runtime autohospedada.
- Instalación del entorno de ejecución de integración
- Cree servicios vinculados.
- Creación de conjuntos de datos de marca de agua, de origen y de receptor.
- Creación, ejecución y supervisión de una canalización
- Consulte los resultados.
- Adición o actualización de datos en tablas de origen
- Nueva ejecución y supervisión de la canalización
- Revisión de los resultados finales
Información general
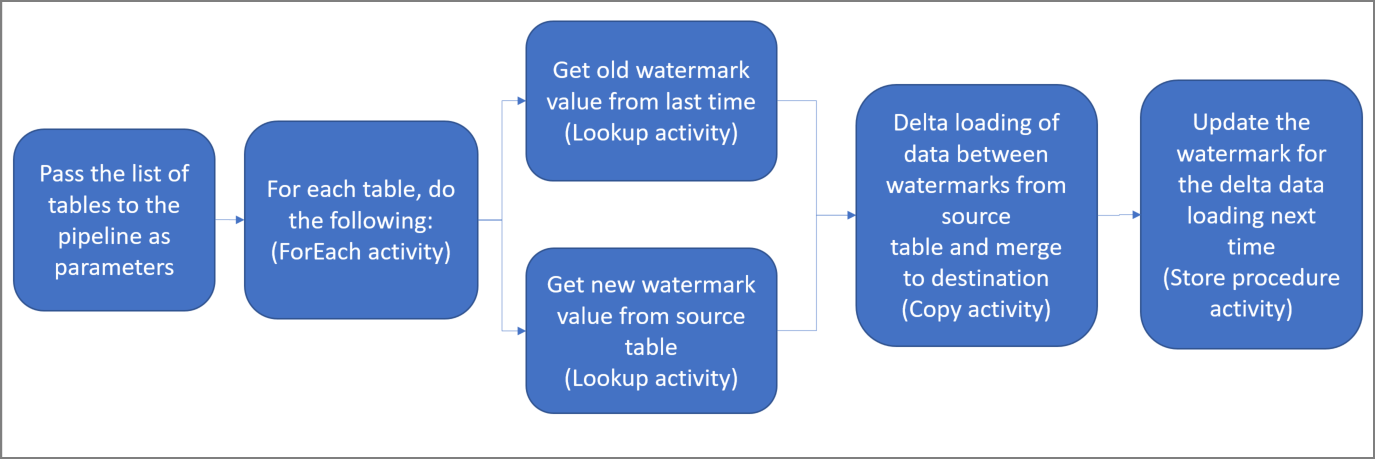
Estos son los pasos importantes para crear esta solución:
Seleccione la columna de marca de agua.
Seleccione una columna de cada tabla del almacén de datos de origen que pueda usarse para identificar los registros nuevos o actualizados de cada ejecución. Normalmente, los datos de esta columna seleccionada (por ejemplo, last_modify_time o id.) siguen aumentando cuando se crean o se actualizan las filas. El valor máximo de esta columna se utiliza como una marca de agua.
Prepare el almacén de datos para almacenar el valor de marca de agua.
En este tutorial, el valor de marca de agua se almacena en una base de datos SQL.
Cree una canalización con las siguientes actividades:
a. Cree una actividad ForEach que recorra en iteración una lista de nombres de tabla de origen que se pase como parámetro a la canalización. Para cada tabla de origen, invoca las siguientes actividades para realizar la carga diferencial de esa tabla.
b. Cree dos actividades de búsqueda. Use la primera actividad de búsqueda para recuperar el último valor de marca de agua. y, la segunda actividad, para recuperar el nuevo valor de marca de agua. Estos valores de marca de agua se pasan a la actividad de copia.
c. Cree una actividad de copia que copie filas del almacén de datos de origen con el valor de la columna de marca de agua que sea mayor que el valor anterior y menor que el nuevo. A continuación, copie los datos diferenciales del almacén de datos de origen a Azure Blob Storage como un archivo nuevo.
d. Cree un procedimiento almacenado que actualice el valor de marca de agua de la canalización que se ejecute la próxima vez.
Este es el diagrama de solución de alto nivel:
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- SQL Server. En este tutorial, usará una base de datos de SQL Server como almacén de datos de origen.
- Azure SQL Database. Se usa una base de datos de Azure SQL Database como almacén de datos receptor. Si no tiene ninguna base de datos en SQL Database, consulte el artículo Creación de una base de datos en Azure SQL Database para ver los pasos y crear una.
Creación de tablas de origen en la base de datos de SQL Server
Abra SQL Server Management Studio y conéctese a la base de datos SQL Server.
En el Explorador de servidores, haga clic con el botón derecho en la base de datos y elija Nueva consulta.
Ejecute el siguiente comando SQL en la base de datos para crear las tablas denominadas
customer_tableyproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Creación de las tablas de destino en la base de datos
Abra SQL Server Management Studio y conéctese a su base de datos de Azure SQL Database.
En el Explorador de servidores, haga clic con el botón derecho en la base de datos y elija Nueva consulta.
Ejecute el siguiente comando SQL en la base de datos para crear las tablas denominadas
customer_tableyproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Creación de otra tabla en la base de datos para almacenar el valor de límite máximo
Ejecute el siguiente comando SQL en la base de datos SQL para crear una tabla denominada
watermarktabley almacenar el valor de marca de agua:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Inserte los valores del límite inicial de ambas tablas de origen en la tabla de límites.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Creación de un procedimiento almacenado en la base de datos
Ejecute el siguiente comando para crear un procedimiento almacenado en la base de datos. Este procedimiento almacenado actualiza el valor de la marca de agua después de cada ejecución de canalización.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Creación de tipos de datos y procedimientos almacenados adicionales en la base de datos
Ejecute la consulta siguiente para crear dos procedimientos almacenados y dos tipos de datos en la base de datos. Estos procedimientos se usan para combinar los datos de las tablas de origen en las tablas de destino.
Para que sea más fácil comenzar el proceso, usamos directamente estos procedimientos almacenados, para lo cual pasamos los datos diferenciales a través de una variable de tabla y, luego, los combinamos en el almacén de destino. Tenga presente que no se espera que se almacene un "gran" número de filas diferenciales (más de 100) en la variable de tabla.
Si debe realizar una combinación de un gran número de filas diferenciales en el almacén de destino, es aconsejable usar la actividad de copia para copiar primero todos los datos diferenciales en una tabla de almacenamiento temporal en el almacén de destino y, luego, crear su propio procedimiento almacenado sin usar variables de tabla para combinar esos datos diferenciales de la tabla temporal en la tabla final.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Crear una factoría de datos
Inicie el explorador web Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory:
En la página Nueva factoría de datos, escriba ADFMultiIncCopyTutorialDF como nombre.
El nombre de la instancia de Azure Data Factory debe ser único globalmente. Si ve un signo de exclamación rojo con el siguiente error, cambie el nombre de la factoría de datos (por ejemplo, yournameADFIncCopyTutorialDF) e intente crearla de nuevo. Consulte el artículo Azure Data Factory: reglas de nomenclatura para conocer las reglas de nomenclatura de los artefactos de Data Factory.
Data factory name "ADFIncCopyTutorialDF" is not availableSeleccione la suscripción de Azure donde desea crear la factoría de datos.
Para el grupo de recursos, realice uno de los siguientes pasos:
- Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
- Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para obtener más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
Seleccione V2 para la versión.
Seleccione la ubicación de Data Factory. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Haga clic en Crear.
Una vez completada la creación, verá la página Data Factory tal como se muestra en la imagen.

Seleccione Abrir en el icono Abrir Azure Data Factory Studio para iniciar la aplicación de interfaz de usuario (IU) de Azure Data Factory en una pestaña independiente.
Creación de un entorno de ejecución de integración autohospedado
Cuando mueva datos de un almacén de datos de una privada red (local) a un almacén de datos de Azure, instale un entorno de ejecución de integración (IR) autohospedado en su entorno local. El entorno de ejecución de integración autohospedado mueve los datos entre la red privada y Azure.
En la página principal de la interfaz de usuario de Azure Data Factory, seleccione la pestaña Administrar en el panel izquierdo.
Seleccione Entornos de ejecución de integración en el panel izquierdo y, a continuación, seleccione + Nuevo.
En la ventana Integration Runtime Setup (Configuración de Integration Runtime), seleccione la opción Perform data movement and dispatch activities to external computes (Realizar movimientos de datos y enviar actividades a procesos externos) y haga clic en Continue (Continuar).
Seleccione Self-Hosted (Autohospedado) y haga clic en Continue (Continuar).
Escriba MySelfHostedIR en Name (Nombre) y haga clic en Next (Siguiente).
Haga clic en Click here to launch the express setup for this computer (Haga clic aquí para iniciar la configuración rápida en este equipo) en la sección Option 1: Express setup (Opción 1: configuración rápida).
En la ventana Microsoft Integration Runtime (Self-hosted) Express Setup (Configuración rápida de Integration Runtime [autohospedado]), haga clic en Close (Cerrar).
En el explorador web, en la ventana Integration Runtime Setup (Configuración de Integration Runtime), haga clic en Finish (Finalizar).
Confirme que ve MySelfHostedIR en la lista de entornos de ejecución de integración.
Crear servicios vinculados
Los servicios vinculados se crean en una factoría de datos para vincular los almacenes de datos y los servicios de proceso con la factoría de datos. En esta sección, creará servicios vinculados a la base de datos de SQL Server y a la base de datos de Azure SQL Database.
Creación del servicio vinculado de SQL Server
En este paso, vinculará la base de datos de SQL Server a la factoría de datos.
En la ventana Connections ventana, cambie de la pestaña Integration Runtimes (Entornos de ejecución de integración) a la pestaña Linked Services (Servicios vinculados) y haga clic en + New (Nuevo).

En la ventana New Linked Service (Nuevo servicio vinculado), seleccione SQL Server y haga clic en Continue (Continuar).
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
- Escriba SqlServerLinkedService en Name (Nombre).
- Seleccione MySelfHostedIR en la opción Connect via integration runtime (Conectar mediante IR). Este es un paso importante. El entorno de ejecución de integración predeterminado no se puede conectar a un almacén de datos local. Utilice el entorno de ejecución de integración auto-hospedado que creó anteriormente.
- En Server name (Nombre de servidor), escriba el nombre del equipo que tiene la base de datos de SQL Server.
- En Database name (Nombre de base de datos), escriba el nombre de la base de datos de SQL Server que tiene los datos de origen. Como parte de los requisitos previos creó una tabla e insertó datos en esta base de datos.
- En Authentication type (Tipo de autenticación), seleccione el tipo de autenticación que desea usar para conectarse a la base de datos.
- En User name (Nombre de usuario), escriba el nombre del usuario que tiene acceso a la base de datos de SQL Server. Si necesita usar un carácter de barra diagonal (
\) en el nombre de servidor o en la cuenta de usuario, utilice el carácter de escape (\). Un ejemplo esmydomain\\myuser. - En Password (Contraseña), escriba la contraseña del usuario.
- Para comprobar si Data Factory puede conectarse a su base de datos de SQL Server, haga clic en Test connection (Probar conexión). Corrija todos los errores que aparezcan hasta que la conexión se realice correctamente.
- Para guardar el servicio vinculado, haga clic en Finish (Finalizar).
Creación del servicio vinculado de Azure SQL Database
En el último paso, creó un servicio vinculado para vincular su base de datos de Azure SQL Server de origen con la factoría de datos. En este paso, vinculará su base de datos de destino o receptora con la factoría de datos.
En la ventana Connections ventana, cambie de la pestaña Integration Runtimes (Entornos de ejecución de integración) a la pestaña Linked Services (Servicios vinculados) y haga clic en + New (Nuevo).
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Azure SQL Database y haga clic en Continue (Continuar).
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
- Escriba AzureSqlDatabaseLinkedService en Name (Nombre).
- En Server name (Nombre del servidor), seleccione el nombre del servidor en la lista desplegable.
- En Database name (Nombre de base de datos), seleccione la base de datos en la que creó customer_table y project_table como parte de los requisitos previos.
- En User name (Nombre de usuario), escriba el nombre del usuario que tiene acceso a la base de datos.
- En Password (Contraseña), escriba la contraseña del usuario.
- Para comprobar si Data Factory puede conectarse a su base de datos de SQL Server, haga clic en Test connection (Probar conexión). Corrija todos los errores que aparezcan hasta que la conexión se realice correctamente.
- Para guardar el servicio vinculado, haga clic en Finish (Finalizar).
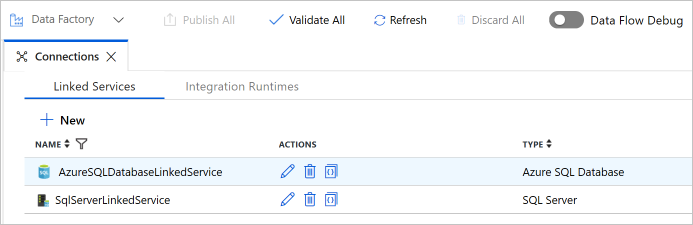
Confirme que ve dos servicios vinculados en la lista.
Creación de conjuntos de datos
En este paso, creará conjuntos de datos para representar el origen de datos, el destino de los datos y el lugar para almacenar la marca de agua.
Creación de un conjunto de datos de origen
En el panel izquierdo, haga clic en el signo + (más) y en Dataset (Conjunto de datos).
En la ventana New Dataset (Nuevo conjunto de datos), seleccione SQL Server y haga clic en Continue (Continuar).
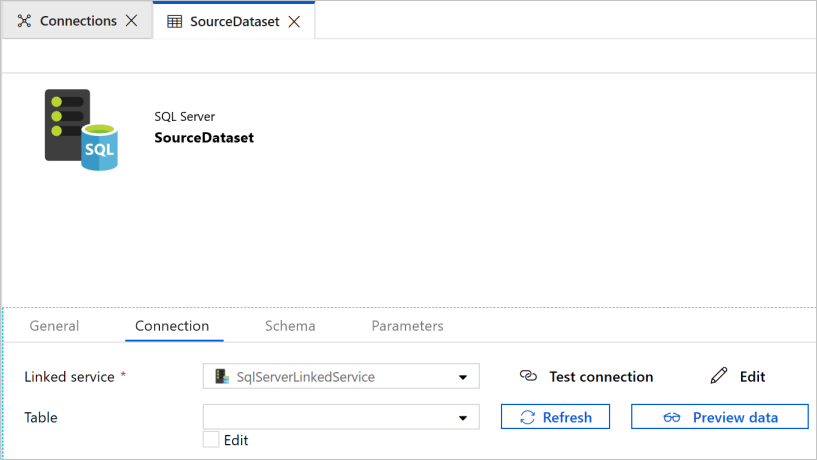
Verá que se abre una nueva pestaña en el explorador web para configurar el conjunto de datos. También verá un conjunto de datos en la vista de árbol. En la pestaña General de la ventana de propiedades de la parte inferior, escriba SourceDataset en Name (Nombre).
Cambie a la pestaña Connection (Conexión) de la ventana de propiedades y seleccione SqlServerLinkedService en Linked service (Servicio vinculado). No seleccione ninguna tabla aquí. La actividad de copia en la canalización usa una consulta SQL para cargar los datos en lugar de cargar la tabla entera.
Creación de un conjunto de datos receptor
En el panel izquierdo, haga clic en el signo + (más) y en Dataset (Conjunto de datos).
En la ventana New Dataset (Nuevo conjunto de datos), seleccione Azure SQL Database y haga clic en Continue (Continuar).
Verá que se abre una nueva pestaña en el explorador web para configurar el conjunto de datos. También verá un conjunto de datos en la vista de árbol. En la pestaña General de la ventana de propiedades de la parte inferior, escriba SinkDataset en Name (Nombre).
Cambie a la pestaña Parameters (Parámetros) de la ventana de propiedades y realice los pasos siguientes:
Haga clic en + New (+ Nuevo) en la sección Create/update parameters (Crear o actualizar parámetros).
Escriba SinkTableName en Name (Nombre) and String en Type (Tipo). Este conjunto de datos toma SinkTableName como parámetro. El parámetro SinkTableName lo establece la canalización dinámicamente en el runtime. La actividad ForEach de la canalización recorre en iteración una lista de nombres de tabla y pasa el nombre de tabla a este conjunto de datos en cada iteración.
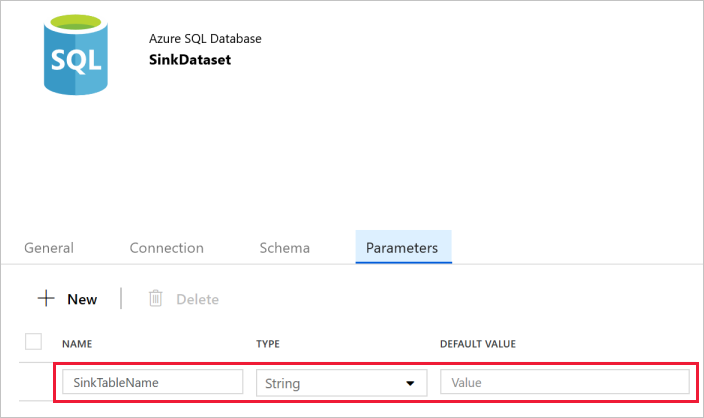
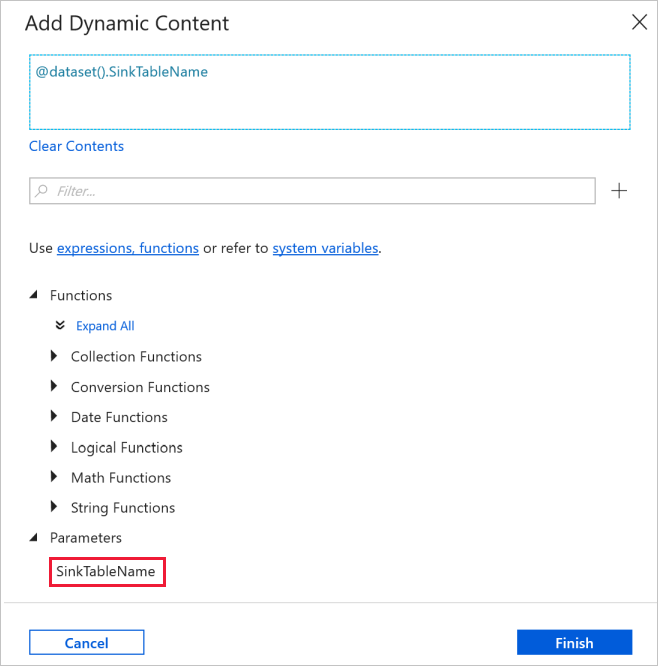
Cambie a la pestaña Connection (Conexión) de la ventana de propiedades y seleccione AzureSqlDatabaseLinkedService en Linked service (Servicio vinculado). En la propiedad Table, haga clic en Agregar contenido dinámico.
En la ventana Add Dynamic Content (Agregar contenido dinámico), seleccione SinkTableName en la sección Parameters (Parámetros).
Después de hacer clic en Finalizar, aparecerá "dataset().SinkTableName" como nombre de la tabla.
Creación de un conjunto de datos para una marca de agua
En este paso, creará un conjunto de datos para almacenar un valor de límite máximo.
En el panel izquierdo, haga clic en el signo + (más) y en Dataset (Conjunto de datos).
En la ventana New Dataset (Nuevo conjunto de datos), seleccione Azure SQL Database y haga clic en Continue (Continuar).
En la pestaña General de la ventana de propiedades de la parte inferior, escriba WatermarkDataset en Name (Nombre).
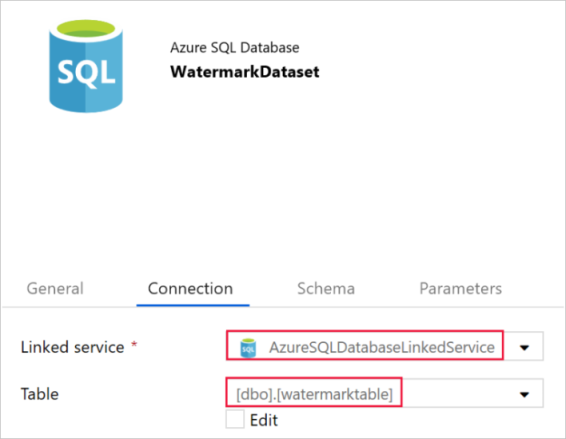
Cambie a la pestaña Connection (Conexión) y realice los pasos siguientes:
Seleccione AzureSqlDatabaseLinkedService como Linked service (Servicio vinculado).
Seleccione [dbo].[watermarktable] para Table (Tabla).
Crear una canalización
La canalización toma una lista de tablas como un parámetro. La actividad ForEach recorre en iteración la lista de nombres de tabla y realiza las siguientes operaciones:
Usa la actividad de búsqueda para recuperar el valor de marca de agua antiguo (valor inicial o que se usó en la última iteración).
Usa la actividad de búsqueda para recuperar el nuevo valor de marca de agua (valor máximo de la columna de marca de agua en la tabla de origen).
Usa la actividad de copia para copiar datos entre estos dos valores de marca de agua desde la base de datos de origen hasta la base de datos de destino.
Usa la actividad de procedimiento almacenado para actualizar el valor de marca de agua antiguo que se usará en el primer paso de la iteración siguiente.
Creación de la canalización
En el panel izquierdo, haga clic en el signo + (más) y en Pipeline (Canalización).
En el panel General, en Propiedades, especifique IncrementalCopyPipeline en Nombre. A continuación, contraiga el panel; para ello, haga clic en el icono Propiedades en la esquina superior derecha.
En la pestaña Parameters (Parámetros), haga lo siguiente:
- Haga clic en + Nuevo.
- Escriba tableList en el parámetro name.
- Seleccione Array (Matriz) para el parámetro type.
En el cuadro de herramientas Activities (Actividades), expanda Iteration & Conditionals (Iteraciones y condiciones), arrastre la actividad ForEach (Para cada uno) y colóquela en la superficie del diseñador de canalizaciones. En la pestaña General de la ventana de propiedades, escriba IterateSQLTables.
Cambie a la pestaña Settings (Configuración) y escriba
@pipeline().parameters.tableListen Items (Elementos). La actividad ForEach recorre en iteración una lista de tablas y realiza la operación de copia incremental.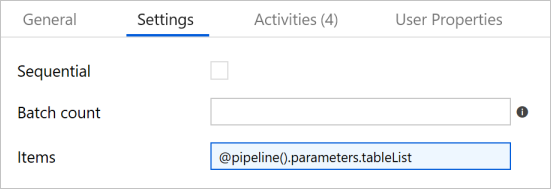
Seleccione la actividad ForEach en la canalización, en caso de que aún no esté seleccionada. Haga clic en el botón Edit (icono del lápiz) .
En el cuadro de herramientas Activities (Actividades), expanda General (General), arrastre la actividad Lookup (Búsqueda), colóquela en la superficie del diseñador de canalizaciones y escriba LookupOldWaterMarkActivity como Name (Nombre).
Cambie a la pestaña Settings (Configuración) de la ventana de propiedades y realice los pasos siguientes:
Seleccione WatermarkDataset en Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en Use Query (Usar consulta).
Escriba la siguiente consulta SQL en el campo Query (Consulta).
select * from watermarktable where TableName = '@{item().TABLE_NAME}'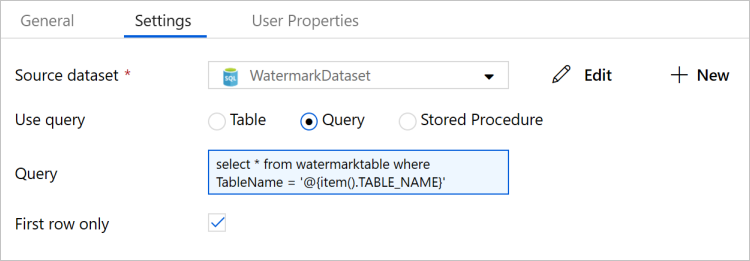
Arrastre y coloque la actividad Lookup (Búsqueda) del cuadro de herramientas Activities (Actividades) y escriba LookupNewWaterMarkActivity en Name (Nombre).
Cambie a la pestaña Configuración .
Seleccione SourceDataset como Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en Use Query (Usar consulta).
Escriba la siguiente consulta SQL en el campo Query (Consulta).
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}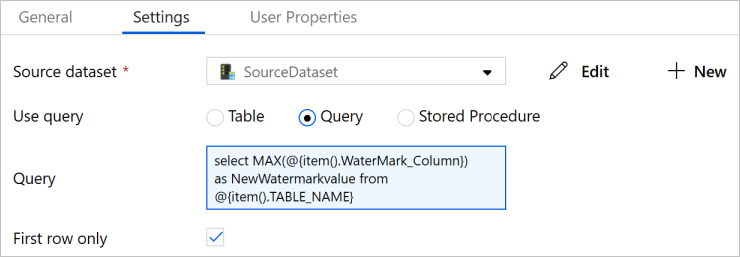
Arrastre y coloque la actividad Copy (Copia) del cuadro de herramientas Activities (Actividades) y escriba IncrementalCopyActivity en Name (Nombre).
Conecte las dos actividades Lookup (Búsqueda) con la actividad Copy (Copia) una a una. Para conectarse, empiece a arrastrar en el cuadro verde adjunto a la actividad Lookup (Búsqueda) y colóquela en la actividad Copy (Copia). Suelte el botón del mouse cuando el color del borde de la actividad de copia cambie a azul.
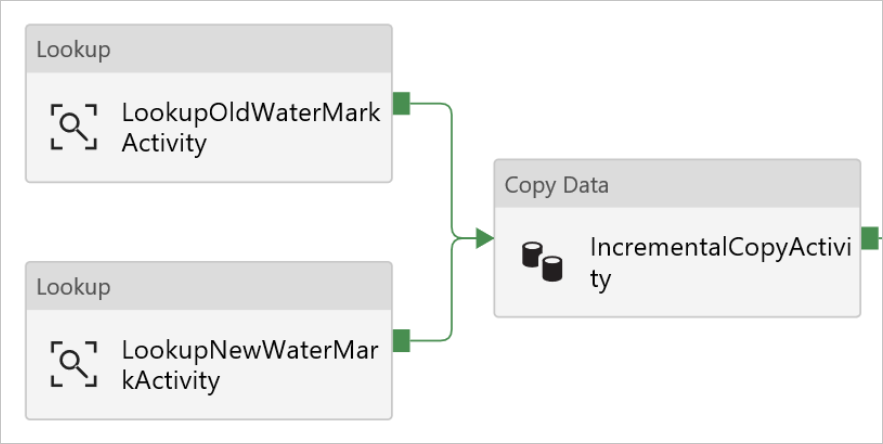
Seleccione la actividad Copy (Copia) de la canalización. Cambie a la pestaña Source (Origen) en la ventana de propiedades.
Seleccione SourceDataset como Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en Use Query (Usar consulta).
Escriba la siguiente consulta SQL en el campo Query (Consulta).
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'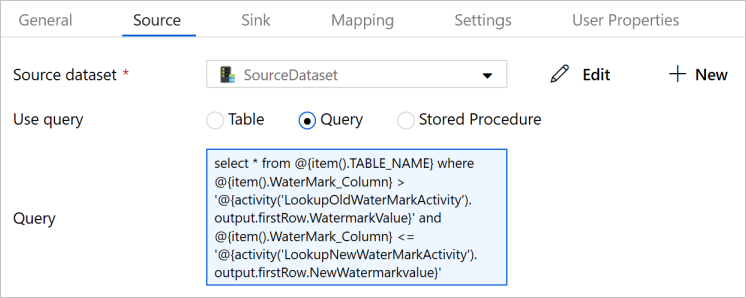
Cambie a la pestaña Sink (Receptor) y seleccione SinkDataset en Sink Dataset (Conjunto de datos receptor).
Siga estos pasos:
En la propiedad Dataset properties (Propiedades del conjunto de datos), en el parámetro SinkTableName, escriba
@{item().TABLE_NAME}.En la propiedad Stored Procedure Name (Nombre del procedimiento almacenado), escriba
@{item().StoredProcedureNameForMergeOperation}.En la propiedad Table Type (Tipo de tabla), escriba
@{item().TableType}.En Table type parameter name (Nombre del parámetro de tipo de tabla), escriba
@{item().TABLE_NAME}.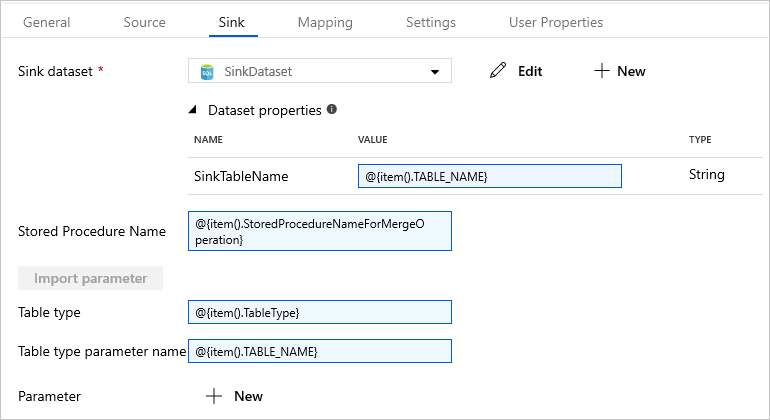
Arrastre la actividad Stored Procedure (procedimiento almacenado) del cuadro de herramientas Activities (Actividades) y colóquela en la superficie del diseñador de canalizaciones. Conecte la actividad Copy (Copia) a la actividad Stored Procedure (Procedimiento almacenado).
Seleccione el Stored Procedure actividad en la canalización y escriba StoredProceduretoWriteWatermarkActivity para nombre en la General pestaña de la propiedades ventana.
Cambie a la pestaña SQL Account (Cuenta de SQL) y seleccione AzureSqlDatabaseLinkedService en Linked service (Servicio vinculado).

Cambie a la pestaña Stored Procedure (Procedimiento almacenado) y realice los pasos siguientes:
Como Stored procedure name (Nombre de procedimiento almacenado), seleccione
[dbo].[usp_write_watermark].Seleccione Import parameter (Importar parámetro).
Especifique los siguientes valores para los parámetros:
Nombre Tipo Value LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}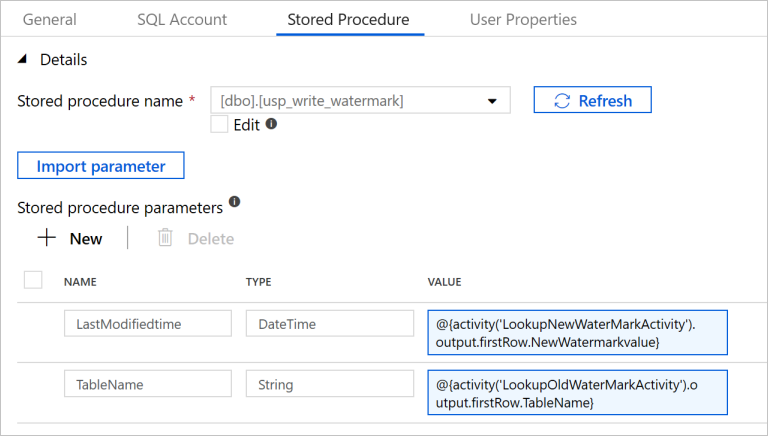
Seleccione Publish All (Publicar todo) para publicar las entidades que creó en el servicio Data Factory.
Espere a que aparezca el mensaje Successfully published (Publicado correctamente). Para ver las notificaciones, haga clic en el vínculo Show Notifications (Mostrar notificaciones). Para cerrar la ventana de notificaciones, haga clic en la X.
Ejecución de la canalización
En la barra de herramientas de la canalización, haga clic en Add trigger (Agregar desencadenador) y en Trigger Now (Desencadenar ahora).
En la ventana Pipeline Run (Ejecución de canalización), escriba el siguiente valor para el parámetro tableList y haga clic en Finish (Finalizar).
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]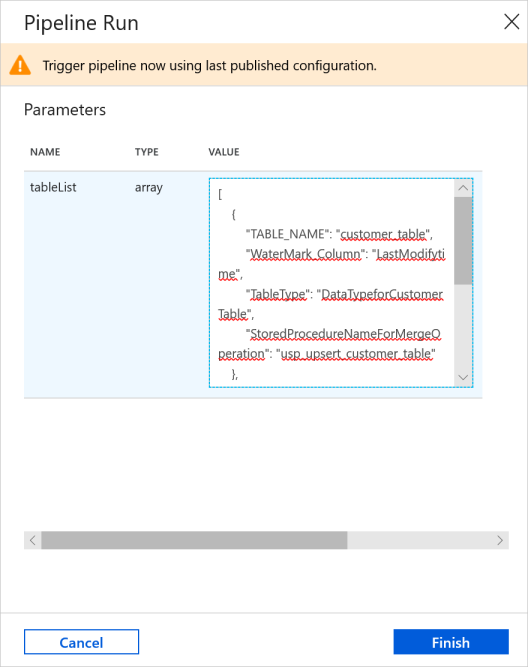
Supervisar la canalización
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Verá la ejecución de canalización que ha desencadenado el desencadenador manual. Puede usar los vínculos de la columna PIPELINE NAME (Nombre de la canalización) para ver los detalles de la actividad y volver a ejecutar la canalización.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo en la columna NOMBRE DE CANALIZACIÓN. Para más información sobre las ejecuciones de actividad, seleccione el vínculo Detalles (icono de gafas) en la columna NOMBRE DE ACTIVIDAD.
Para volver a la vista Ejecuciones de canalización, seleccione All pipeline runs (Todas las ejecuciones de canalización) en la parte superior. Para actualizar la vista, seleccione Refresh (Actualizar).
Revisión del resultado
En SQL Server Management Studio, ejecute las consultas siguientes contra la base de datos SQL de Azure de destino para comprobar que los datos se copiaron de las tablas de origen a las tablas de destino:
Consultar
select * from customer_table
Salida
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Consultar
select * from project_table
Salida
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Consultar
select * from watermarktable
Salida
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Observe que se actualizaron los valores de marca de agua de ambas tablas.
Adición de más datos a las tablas de origen
Ejecute la consulta siguiente contra la base de datos SQL Server de origen para actualizar una fila existente en customer_table. Inserte una nueva fila en project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Nueva ejecución de la canalización
En la ventana del explorador web, cambie a la pestaña Edit (Editar) de la izquierda.
En la barra de herramientas de la canalización, haga clic en Add trigger (Agregar desencadenador) y en Trigger Now (Desencadenar ahora).
En la ventana Pipeline Run (Ejecución de canalización), escriba el siguiente valor para el parámetro tableList y haga clic en Finish (Finalizar).
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Nueva supervisión de la canalización
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Verá la ejecución de canalización que ha desencadenado el desencadenador manual. Puede usar los vínculos de la columna PIPELINE NAME (Nombre de la canalización) para ver los detalles de la actividad y volver a ejecutar la canalización.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo en la columna NOMBRE DE CANALIZACIÓN. Para más información sobre las ejecuciones de actividad, seleccione el vínculo Detalles (icono de gafas) en la columna NOMBRE DE ACTIVIDAD.
Para volver a la vista Ejecuciones de canalización, seleccione All pipeline runs (Todas las ejecuciones de canalización) en la parte superior. Para actualizar la vista, seleccione Refresh (Actualizar).
Revisión de los resultados finales
En SQL Server Management Studio, ejecute las siguientes consultas en la base de datos SQL de destino para comprobar que los datos nuevos o actualizados se han copiado de las tablas de origen a las tablas de destino.
Consultar
select * from customer_table
Salida
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Observe los nuevos valores de Nombre y LastModifytime de PersonID: 3.
Consultar
select * from project_table
Salida
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Tenga en cuenta que la entrada NewProject se agregó a project_table.
Consultar
select * from watermarktable
Salida
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Observe que se actualizaron los valores de marca de agua de ambas tablas.
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Preparación de los almacenes de datos de origen y de destino
- Creación de una factoría de datos.
- Creación de una instancia de Integration Runtime (IR) autohospedado
- Instalación del entorno de ejecución de integración
- Cree servicios vinculados.
- Creación de conjuntos de datos de marca de agua, de origen y de receptor.
- Creación, ejecución y supervisión de una canalización
- Consulte los resultados.
- Adición o actualización de datos en tablas de origen
- Nueva ejecución y supervisión de la canalización
- Revisión de los resultados finales
Pase al tutorial siguiente para obtener información acerca de la transformación de datos mediante el uso de un clúster de Spark en Azure:
Incrementally load data from Azure SQL Database to Azure Blob Storage using Change Tracking technology (Carga incremental de datos de Azure SQL Database a Azure Blob Storage mediante la tecnología de control de cambios)
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de