Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
En este tutorial, creará una instancia de Azure Data Factory con una canalización que carga los datos diferenciales de varias tablas de una base de datos de SQL Server a Azure SQL Database.
En este tutorial, realizará los siguientes pasos:
- Preparación de los almacenes de datos de origen y de destino.
- Creación de una factoría de datos.
- Cree una instancia de Integration Runtime autohospedada.
- Instalación del entorno de ejecución de integración.
- Cree servicios vinculados.
- Creación de conjuntos de datos de marca de agua, de origen y de receptor.
- Creación, ejecución y supervisión de una canalización.
- Consulte los resultados.
- Adición o actualización de datos en tablas de origen.
- Nueva ejecución y supervisión de la canalización.
- Revisión de los resultados finales.
Información general
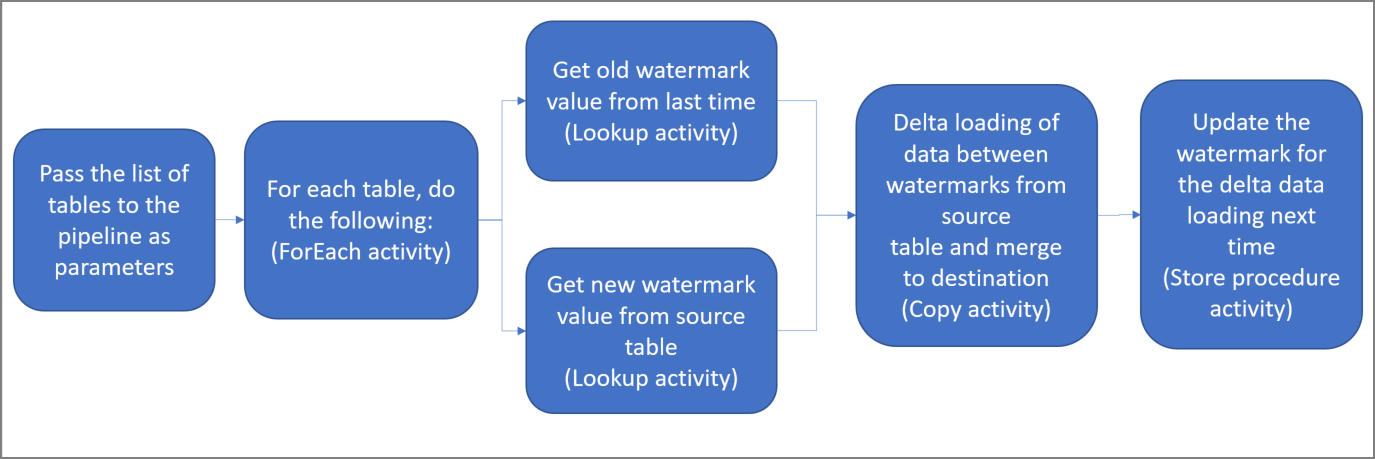
Estos son los pasos importantes para crear esta solución:
Seleccione la columna de marca de agua.
Seleccione una columna de cada tabla del almacén de datos de origen que pueda usarse para identificar los registros nuevos o actualizados de cada ejecución. Normalmente, los datos de esta columna seleccionada (por ejemplo, last_modify_time o id.) siguen aumentando cuando se crean o se actualizan las filas. El valor máximo de esta columna se utiliza como una marca de agua.
Prepare el almacén de datos para almacenar el valor de marca de agua.
En este tutorial, el valor de marca de agua se almacena en una base de datos SQL.
Cree una canalización con las siguientes actividades:
Cree una actividad ForEach que recorra en iteración una lista de nombres de tabla de origen que se pase como parámetro a la canalización. Para cada tabla de origen, invoca las siguientes actividades para realizar la carga diferencial de esa tabla.
Cree dos actividades de búsqueda. Use la primera actividad de búsqueda para recuperar el último valor de marca de agua. y, la segunda actividad, para recuperar el nuevo valor de marca de agua. Estos valores de marca de agua se pasan a la actividad de copia.
Cree una actividad de copiado que copie las filas del almacén de datos de origen con el valor de la columna de marca de agua mayor que el valor de la marca de agua anterior y menor o igual que el nuevo valor de la marca de agua. A continuación, copie los datos diferenciales del almacén de datos de origen a Azure Blob Storage como un archivo nuevo.
Cree un procedimiento almacenado que actualice el valor de marca de agua de la canalización que se ejecute la próxima vez.
Este es el diagrama de solución de alto nivel:
Si no tiene una suscripción de Azure, cree una cuenta free antes de comenzar.
Requisitos previos
- SQL Server. En este tutorial se usa una base de datos de SQL Server como almacén de datos de origen.
- Azure SQL Database. Se usa una base de datos de Azure SQL Database como almacén de datos receptor. Si no tiene una base de datos SQL, consulte Crear una base de datos en Azure SQL Database para ver los pasos para crear una.
Creación de tablas de origen en la base de datos de SQL Server
Abra SQL Server Management Studio (SSMS) o Visual Studio Code y conéctese a la base de datos de SQL Server.
En Server Explorer (SSMS) o en el panel Connections (Visual Studio Code), haga clic con el botón derecho en la base de datos y elija Nuevo consulta.
Ejecute el siguiente comando SQL en la base de datos para crear las tablas denominadas
customer_tableyproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Creación de tablas de destino en el Azure SQL Database
Abra SQL Server Management Studio (SSMS) o Visual Studio Code y conéctese a la base de datos de SQL Server.
En Server Explorer (SSMS) o en el panel Connections (Visual Studio Code), haga clic con el botón derecho en la base de datos y elija Nuevo consulta.
Ejecute el siguiente comando SQL en la base de datos para crear las tablas denominadas
customer_tableyproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Creación de otra tabla en Azure SQL Database para almacenar el valor de límite máximo
Ejecute el siguiente comando SQL en la base de datos SQL para crear una tabla denominada
watermarktabley almacenar el valor de marca de agua:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Inserte los valores del límite inicial de ambas tablas de origen en la tabla de límites.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Creación de un procedimiento almacenado en el Azure SQL Database
Ejecute el siguiente comando para crear un procedimiento almacenado en la base de datos. Este procedimiento almacenado actualiza el valor de la marca de agua después de cada ejecución de canalización.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Crear tipos de datos y procedimientos almacenados adicionales en Azure SQL Database
Ejecute la consulta siguiente para crear dos procedimientos almacenados y dos tipos de datos en la base de datos. Estos procedimientos se usan para combinar los datos de las tablas de origen en las tablas de destino.
Para que sea más fácil comenzar el proceso, usamos directamente estos procedimientos almacenados, para lo cual pasamos los datos diferenciales a través de una variable de tabla y, luego, los combinamos en el almacén de destino. Tenga presente que no se espera que se almacene un "gran" número de filas diferenciales (más de 100) en la variable de tabla.
Si debe realizar una combinación de un gran número de filas diferenciales en el almacén de destino, es aconsejable usar la actividad de copia para copiar primero todos los datos diferenciales en una tabla de almacenamiento temporal en el almacén de destino y, luego, crear su propio procedimiento almacenado sin usar variables de tabla para combinar esos datos diferenciales de la tabla temporal en la tabla final.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Instale los módulos de Azure PowerShell más recientes siguiendo las instrucciones de Install y configure Azure PowerShell.
Crear una factoría de datos
Defina una variable para el nombre del grupo de recursos que usa en los comandos de PowerShell más adelante. Copie el siguiente texto de comando en PowerShell, especifique un nombre para el grupo de recursos Azure entre comillas dobles y ejecute el comando. Un ejemplo es
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Si el grupo de recursos ya existe, puede que no desee sobrescribirlo. Asigne otro valor a la variable
$resourceGroupNamey vuelva a ejecutar el comando.Defina una variable para la ubicación de la factoría de datos.
$location = "East US"Para crear el grupo de recursos Azure, ejecute el siguiente comando:
New-AzResourceGroup $resourceGroupName $locationSi el grupo de recursos ya existe, puede que no desee sobrescribirlo. Asigne otro valor a la variable
$resourceGroupNamey vuelva a ejecutar el comando.Defina una variable para el nombre de la factoría de datos.
Importante
Actualice el nombre de la factoría de datos para que sea globalmente único. Por ejemplo, ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Para crear la factoría de datos, ejecute el siguiente cmdlet, Set-AzDataFactoryV2:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Tenga en cuenta los siguientes puntos:
El nombre de la factoría de datos debe ser globalmente único. Si recibe el siguiente error, cambie el nombre y vuelva a intentarlo:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Para crear instancias de Data Factory, la cuenta de usuario que usa para iniciar sesión en Azure debe ser miembro de roles de colaborador o propietario, o un administrador de la suscripción de Azure.
Para obtener una lista de las regiones de Azure en las que Data Factory está disponible actualmente, seleccione las regiones que le interesan en la página siguiente y, a continuación, expanda Analytics para buscar Data Factory: Productos disponibles por región. Los almacenes de datos (Azure Storage, SQL Database, SQL Managed Instance, etc.) y los procesos (Azure HDInsight, etc.) usados por la factoría de datos pueden estar en otras regiones.
Creación de una instancia de Integration Runtime autohospedada
En esta sección, creará un entorno de ejecución de integración autohospedado y lo asociará a una máquina local con la base de datos de SQL Server. El entorno de ejecución de integración autohospedado es el componente que copia datos desde SQL Server en su máquina a la base de datos SQL de Azure.
Cree una variable para el nombre de Integration Runtime. Utilice un nombre único y anótelo. Lo usará más adelante en este tutorial.
$integrationRuntimeName = "ADFTutorialIR"Cree una instancia de Integration Runtime autohospedada.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameEste es la salida de ejemplo:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRPara recuperar el estado de la instancia de Integration Runtime creada, ejecute el siguiente comando. Confirme que el valor de la propiedad Estado está establecida en NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusEste es la salida de ejemplo:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Para recuperar las claves de autenticación usadas para registrar el entorno de ejecución de integración autohospedado con Azure Data Factory servicio en la nube, ejecute el siguiente comando:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonEste es la salida de ejemplo:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Copie una de las claves (sin las comillas dobles) utilizadas para registrar la instancia de Integration Runtime autohospedado que instalará en el equipo en los pasos siguientes.
Instalación de la herramienta Integration Runtime
Si ya tiene Integration Runtime en su equipo, desinstálelo utilizando Agregar o quitar programas.
Descarga el runtime de integración autohospedado en un ordenador Windows local. Ejecución de la instalación.
En la página Bienvenido a la configuración de Microsoft Integration Runtime, seleccione Siguiente.
En la página del Contrato de licencia para el usuario final, acepte los términos del Contrato de licencia y seleccione Siguiente.
En la página Carpeta de destino, seleccione Siguiente.
En la página Ready para instalar Microsoft Integration Runtime, seleccione Install.
En la página Completed the Microsoft Integration Runtime Setup , seleccione Finish.
En la página Registro de Integration Runtime (autohospedado), pegue la clave guardada en la sección anterior y seleccione en Registrar.
En la página Nuevo nodo Integration Runtime (autohospedado), seleccione Finalizar.
Verá el siguiente mensaje cuando la instancia de Integration Runtime autohospedado se haya registrado correctamente:
En la página Registro de Integration Runtime (autohospedado), seleccione Iniciar Configuration Manager.
Verá la siguiente página cuando el nodo esté conectado al servicio en la nube:
Ahora, pruebe la conectividad a la base de datos de SQL Server.
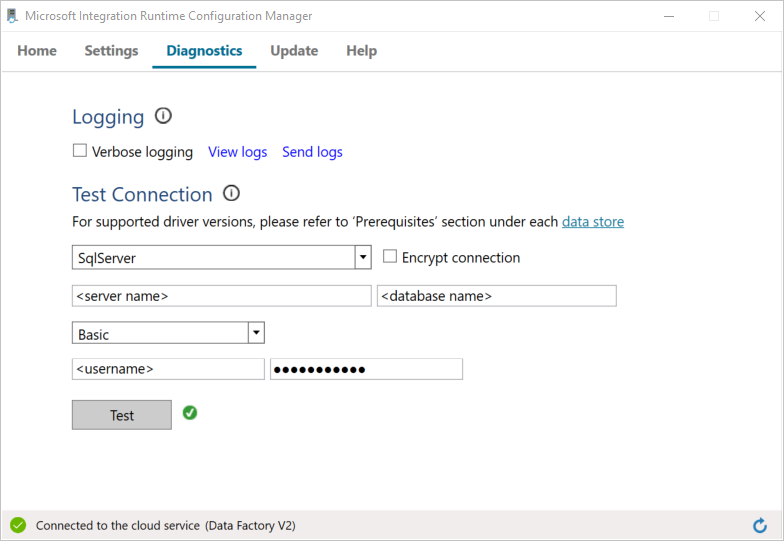
a. En la página Configuration Manager, vaya a la pestaña Diagnostics.
b. Seleccione SqlServer para el tipo de origen de datos.
c. Escriba el nombre del servidor.
d. Escriba el nombre de la base de datos.
e. Seleccione el modo de autenticación.
f. Escriba el nombre de usuario.
g. Escriba la contraseña asociada con el nombre de usuario.
h. Seleccione Test para confirmar que integration Runtime puede conectarse a SQL Server. Verá una marca de verificación verde si la conexión es correcta. Verá un mensaje de error si la conexión no se realiza correctamente. Corrija los problemas y asegúrese de que integration Runtime puede conectarse a SQL Server.
Nota
Tome nota de los valores para la contraseña, el usuario, la base de datos, el servidor y el tipo de autenticación. Los usará más adelante en este tutorial.
Crear servicios vinculados
Los servicios vinculados se crean en una factoría de datos para vincular los almacenes de datos y los servicios de proceso con la factoría de datos. En esta sección, creará servicios vinculados a la base de datos de SQL Server y a la base de datos en Azure SQL Database.
Creación del servicio vinculado de SQL Server
En este paso, vinculará la base de datos de SQL Server a la factoría de datos.
Cree un archivo JSON llamado SqlServerLinkedService.json en la carpeta C:\ADFTutorials\IncCopyMultiTableTutorial (cree las carpetas locales si estas aún no existen) con el contenido siguiente. Seleccione la sección correcta en función de la autenticación que use para conectarse a SQL Server.
Importante
Seleccione la sección correcta en función de la autenticación que use para conectarse a SQL Server.
Si usa la autenticación de SQL, copie la siguiente definición JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Si usa Windows authentication, copie la siguiente definición JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Importante
- Seleccione la sección correcta en función de la autenticación que use para conectarse a SQL Server.
- Reemplace <integration runtime name> por el nombre del entorno de ejecución de integración.
- Reemplace <servername>, <databasename>, <username> y <password> con valores de la base de datos de SQL Server antes de guardar el archivo.
- Si necesita usar un carácter de barra diagonal (
\) en el nombre de servidor o en la cuenta de usuario, utilice el carácter de escape (\). Un ejemplo esmydomain\\myuser.
En PowerShell, ejecute el siguiente cmdlet para cambiar a la carpeta C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Ejecute el cmdlet Set-AzDataFactoryV2LinkedService para crear el servicio vinculado AzureStorageLinkedService. En el ejemplo siguiente, debe pasar los valores de los parámetros ResourceGroupName y DataFactoryName:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Este es la salida de ejemplo:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Creación del servicio vinculado de SQL Database
Cree un archivo JSON llamado AzureSQLDatabaseLinkedService.json en la carpeta C:\ADFTutorials\IncCopyMultiTableTutorial con el contenido siguiente. (Cree la carpeta ADF si aún no existe). Reemplace <servername>, <database name>, <user name> y <password> con el nombre de la base de datos SQL Server, el nombre de la base de datos, el nombre de usuario y la contraseña antes de guardar el archivo.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }En PowerShell, ejecute el cmdlet Set-AzDataFactoryV2LinkedService para crear el servicio vinculado AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Este es la salida de ejemplo:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Creación de conjuntos de datos
En este paso, creará conjuntos de datos para representar el origen de datos, el destino de los datos y el lugar para almacenar la marca de agua.
Creación de un conjunto de datos de origen
Cree un archivo JSON llamado SourceDataset.json en la misma carpeta con el siguiente contenido:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }La actividad de copia en la canalización usa una consulta SQL para cargar los datos en lugar de cargar la tabla entera.
Ejecute el cmdlet Set-AzDataFactoryV2Dataset para crear el conjunto de datos SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Esta es la salida de ejemplo del cmdlet:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Creación de un conjunto de datos receptor
Cree un archivo JSON llamado SinkDataset.json en la misma carpeta con el siguiente contenido. El elemento tableName se establece dinámicamente mediante la canalización en tiempo de ejecución. La actividad ForEach de la canalización recorre en iteración una lista de nombres de tabla y pasa el nombre de tabla a este conjunto de datos en cada iteración.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Ejecute el cmdlet Set-AzDataFactoryV2Dataset para crear el conjunto de datos SinkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Esta es la salida de ejemplo del cmdlet:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Creación de un conjunto de datos para una marca de agua
En este paso, creará un conjunto de datos para almacenar un valor de límite máximo.
Cree un archivo JSON llamado WatermarkDataset.json en la misma carpeta con el siguiente contenido:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Ejecute el cmdlet Set-AzDataFactoryV2Dataset para crear el conjunto de datos WatermarkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Esta es la salida de ejemplo del cmdlet:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Crear una canalización
La canalización toma una lista de tablas como un parámetro. La actividad ForEach recorre en iteración la lista de nombres de tabla y realiza las siguientes operaciones:
Usa la actividad de búsqueda para recuperar el valor de marca de agua antiguo (valor inicial o que se usó en la última iteración).
Usa la actividad de búsqueda para recuperar el nuevo valor de marca de agua (valor máximo de la columna de marca de agua en la tabla de origen).
Usa la actividad de copia para copiar datos entre estos dos valores de marca de agua desde la base de datos de origen hasta la base de datos de destino.
Usa la actividad de procedimiento almacenado para actualizar el valor de marca de agua antiguo que se usará en el primer paso de la iteración siguiente.
Creación de la canalización
Cree un archivo JSON llamado IncrementalCopyPipeline.json en la misma carpeta con el siguiente contenido:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Ejecute el cmdlet Set-AzDataFactoryV2Pipeline para crear la canalización IncrementalCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Este es la salida de ejemplo:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Ejecución de la canalización
Cree un archivo de parámetros llamado Parameters.json en la misma carpeta con el siguiente contenido:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Ejecute la canalización IncrementalCopyPipeline mediante el cmdlet Invoke-AzDataFactoryV2Pipeline. Reemplace los marcadores de posición por su propio grupo de recursos y el nombre de la factoría de datos.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Supervisar la canalización
Inicie sesión en el portal Azure.
Haga clic en Todos los servicios, busque con la palabra clave Factorías de datos y seleccione Factorías de datos.
Busque su factoría de datos en la lista y selecciónela para abrir la página Factoría de datos.
En la página Data factory, seleccione Abrir en el mosaico Abrir Azure Data Factory Studio para iniciar Azure Data Factory en una pestaña independiente.
En la página principal de Azure Data Factory, seleccione Monitor en el lado izquierdo.
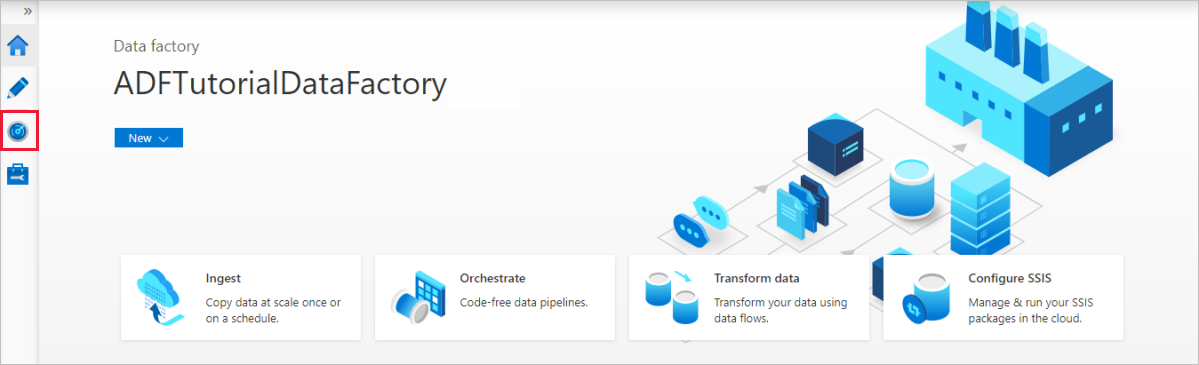
Puede ver todas las ejecuciones de canalización y sus estados. Tenga en cuenta que, en el ejemplo siguiente, el estado de ejecución de la canalización es Correcto. Para comprobar los parámetros pasados a la canalización, seleccione el vínculo en la columna Parámetros. Si se ha producido un error, verá un vínculo en la columna Error.

Al seleccionar el vínculo de la columna Actions (Acciones), verá todas las ejecuciones de actividades de la canalización.
Para volver a la vista Pipeline Runs (Ejecuciones de canalización), seleccione All Pipeline Runs (Todas las ejecuciones de canalización).
Revisión del resultado
En SQL Server Management Studio, ejecute las siguientes consultas en la base de datos SQL de destino para comprobar que los datos se copiaron de tablas de origen a tablas de destino:
Consultar
select * from customer_table
Salida
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Consultar
select * from project_table
Salida
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Consultar
select * from watermarktable
Salida
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Observe que se actualizaron los valores de marca de agua de ambas tablas.
Adición de más datos a las tablas de origen
Ejecute la consulta siguiente en la base de datos de SQL Server de origen para actualizar una fila existente en customer_table. Inserte una nueva fila en project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Nueva ejecución de la canalización
Ahora, vuelva a ejecutar la canalización mediante el siguiente comando de PowerShell:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Supervise las ejecuciones de canalización siguiendo las instrucciones de la sección Supervisión de la canalización. Como el estado de la canalización es En curso, verá otro vínculo de acción en Acciones para cancelar la ejecución de canalización.
Haga clic en Actualizar para actualizar la lista hasta que la ejecución de canalización se realice correctamente.
De manera opcional, seleccione el vínculo View Activity Runs (Ver ejecuciones de actividad) en Acciones para ver todas las ejecuciones de actividad asociadas a esta ejecución de canalización.
Revisión de los resultados finales
En SQL Server Management Studio, ejecute las siguientes consultas en la base de datos de destino para comprobar que los datos actualizados o nuevos se copiaron de tablas de origen a tablas de destino.
Consultar
select * from customer_table
Salida
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Observe los nuevos valores de Nombre y LastModifytime de PersonID: 3.
Consultar
select * from project_table
Salida
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Tenga en cuenta que la entrada NewProject se agregó a project_table.
Consultar
select * from watermarktable
Salida
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Observe que se actualizaron los valores de marca de agua de ambas tablas.
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Preparación de los almacenes de datos de origen y de destino.
- Creación de una factoría de datos.
- Creación de una instancia de Integration Runtime (IR) autohospedado.
- Instalación del entorno de ejecución de integración.
- Cree servicios vinculados.
- Creación de conjuntos de datos de marca de agua, de origen y de receptor.
- Creación, ejecución y supervisión de una canalización.
- Consulte los resultados.
- Adición o actualización de datos en tablas de origen.
- Nueva ejecución y supervisión de la canalización.
- Revisión de los resultados finales.
Avance al siguiente tutorial para obtener información sobre la transformación de datos mediante un clúster de Spark en Azure: