Exploración y creación de tablas en DBFS
Importante
Esta documentación se ha retirado y es posible que no se actualice. Los productos, servicios o tecnologías mencionados en este contenido ya no se admiten. Consulte Cargar datos mediante la interfaz de usuario de agregar datos y Crear o modificar una tabla mediante la carga de archivos, y ¿Qué es el Explorador de catálogos?.
Acceda a la UI heredada de creación de tablas y carga de archivos DBFS mediante la UI para agregar datos. Haga clic en ![]() Nuevo > Datos > DBFS.
Nuevo > Datos > DBFS.
También puede acceder a la UI desde cuadernos; para ello, haga clic en Archivo > Cargar datos.
Databricks recomienda usar Data Explorer para mejorar la experiencia de visualización de objetos de datos y administrar las ACL y la UI de creación de tablas para ingerir con facilidad archivos pequeños en Delta Lake.
Nota:
La disponibilidad de algunos elementos descritos en este artículo varía en función de las configuraciones del área de trabajo. Póngase en contacto con el administrador del área de trabajo o el representante comercial de Azure Databricks.
Importar datos
Si tiene archivos de datos pequeños en el equipo local que quiera analizar con Azure Databricks, puede importarlos a DBFS mediante la interfaz de usuario.
Nota:
Los administradores del área de trabajo pueden deshabilitar esta característica. Para más información, consulte Administración de las cargas de datos.
Creación de una tabla
Puede iniciar la interfaz de usuario de creación de tabla de DBFS, con un clic en ![]() Nuevo en la barra lateral o en el botón DBFS en el agregar la Interfaz de usuario de datos. Puede rellenar una tabla a partir de archivos en DBFS o cargar archivos.
Nuevo en la barra lateral o en el botón DBFS en el agregar la Interfaz de usuario de datos. Puede rellenar una tabla a partir de archivos en DBFS o cargar archivos.
Con la interfaz de usuario, solo puede crear tablas externas.
Elija un origen de datos y siga los pasos de la sección correspondiente para configurar la tabla.
Si un administrador de un área de trabajo de Azure Databricks ha deshabilitado la opción Cargar archivo, no tendrá la opción de cargar archivos; puede crear tablas con uno de los otros orígenes de datos.
Instrucciones para cargar un archivo
- Arrastre los archivos a la zona de colocación Files (Archivos) o haga clic en la zona de colocación para examinar y elegir archivos. Después de la carga, se muestra una ruta de acceso para cada archivo. La ruta de acceso tendrá un aspecto similar a
/FileStore/tables/<filename>-<integer>.<file-type>. Puede usar esta ruta de acceso en un cuaderno para leer datos. - Haga clic en Create Table with UI (Crear tabla con la UI).
- En la lista desplegable Cluster (Clúster), elija un clúster.
Instrucciones para DBFS
- Seleccionar un archivo.
- Haga clic en Create Table with UI (Crear tabla con la UI).
- En la lista desplegable Cluster (Clúster), elija un clúster.
- Arrastre los archivos a la zona de colocación Files (Archivos) o haga clic en la zona de colocación para examinar y elegir archivos. Después de la carga, se muestra una ruta de acceso para cada archivo. La ruta de acceso tendrá un aspecto similar a
Haga clic en Preview Table (Vista previa de tabla) para ver la tabla.
En el campo Table Name (Nombre de tabla), puede reemplazar el nombre de tabla predeterminado. Un nombre de tabla solo puede contener caracteres alfanuméricos en minúsculas y caracteres de subrayado, y debe comenzar con una letra minúscula o un carácter de subrayado.
En el campo Create in Database (Crear en base de datos), puede reemplazar la base de datos
defaultseleccionada.En el campo File Type (Tipo de archivo), reemplace opcionalmente el tipo de archivo deducido.
Si el tipo de archivo es CSV:
- En el campo Column Delimiter (Delimitador de columna), seleccione si desea reemplazar el delimitador deducido.
- Especifique si se va a usar la primera fila como títulos de columna.
- Especifique si se va a inferir el esquema.
Si el tipo de archivo es JSON, indique si el archivo es de varias líneas.
Haga clic en Create Table (Crear tabla).
Visualización de bases de datos y tablas
Nota:
Las áreas de trabajo con Catalog Explorer habilitado no tienen acceso al comportamiento heredado que se describe a continuación.
Haga clic en ![]() Catálogo en la barra lateral. Azure Databricks selecciona un clúster en ejecución al que tenga acceso. La carpeta Databases (Bases de datos) muestra la lista de bases de datos con la base de datos
Catálogo en la barra lateral. Azure Databricks selecciona un clúster en ejecución al que tenga acceso. La carpeta Databases (Bases de datos) muestra la lista de bases de datos con la base de datos default seleccionada. La carpeta Tables (Tablas) muestra la lista de tablas de la base de datos default.
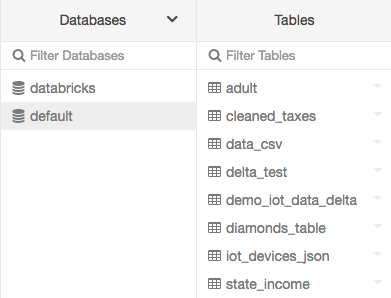
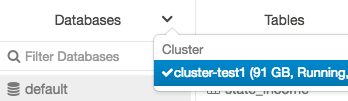
Puede cambiar el clúster desde el menú Databases (Bases de datos), crear la interfaz de usuario de la tabla o ver la interfaz de usuario de la tabla. Por ejemplo, en el menú Databases (Bases de datos):
Haga clic en
 la flecha hacia abajo en la parte superior de la carpeta Bases de datos.
la flecha hacia abajo en la parte superior de la carpeta Bases de datos.Seleccione un clúster.
Visualización de los detalles de una tabla
La vista de detalles de tabla muestra el esquema de la tabla y los datos de ejemplo.
Haga clic en
 Catálogo en la barra lateral.
Catálogo en la barra lateral.En la carpeta Databases (Bases de datos), haga clic en una base de datos.
En la carpeta Tables (Tablas), haga clic en el nombre de la tabla.
En la lista desplegable Cluster (Clúster), seleccione opcionalmente otro clúster para representar la vista previa de la tabla.
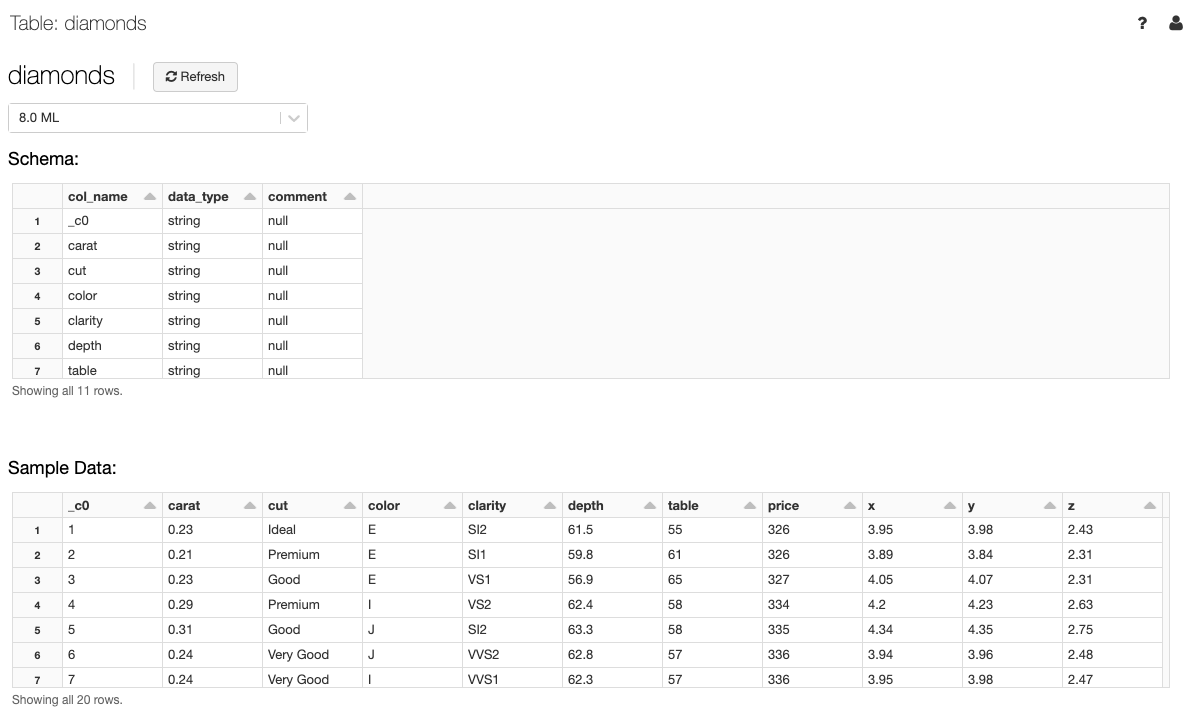
Nota:
Para mostrar la vista previa de la tabla, se ejecuta una consulta SQL de Spark en el clúster seleccionado en la lista desplegable Cluster (Clúster). Si el clúster ya tiene una carga de trabajo en ejecución, la vista previa de la tabla puede tardar más tiempo en cargarse.
Eliminación de una tabla mediante la interfaz de usuario
- Haga clic en Catálogo en la barra lateral.
- Haga clic en
 Siguiente junto al nombre de la tabla y seleccione Eliminar.
Siguiente junto al nombre de la tabla y seleccione Eliminar.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de