Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta documentación se ha retirado y es posible que no se actualice. Los productos, servicios o tecnologías mencionados en este contenido ya no se admiten. Consulte Patrones de fecha y hora.
Los Date tipos de datos y Timestamp cambiaron significativamente en Databricks Runtime 7.0. En este artículo se describe:
- El
Datetipo y el calendario asociado. - Tipo
Timestampy cómo se relaciona con las zonas horarias. También se explican los detalles de la resolución de los desfases de las zonas horarias y los cambios sutiles de comportamiento en la nueva API de tiempo en Java 8, que utiliza Databricks Runtime 7.0. - API para construir valores de fecha y marca de tiempo.
- Problemas comunes y procedimientos recomendados para recopilar objetos de fecha y marca de tiempo en el controlador de Apache Spark.
Fechas y calendarios
Es Date una combinación de los campos year, month y day, como (year=2012, month=12, day=31). Sin embargo, los valores de los campos year, month y day tienen restricciones para asegurarse de que el valor de fecha es una fecha válida en el mundo real. Por ejemplo, el valor del mes debe ser de 1 a 12, el valor del día debe ser de 1 a 28.29.30 o 31 (según el año y el mes), etc. El Date tipo no tiene en cuenta las zonas horarias.
Calendarios
Las restricciones de los campos Date se definen mediante uno de los muchos calendarios posibles. Algunos, como el calendario lunar, solo se usan en regiones específicas. Algunos, como el calendario juliano, solo se usan en la historia. El estándar internacional de facto es el calendario gregoriano que se utiliza casi en todas partes del mundo con fines civiles. Se introdujo en 1582 y también se extendió para admitir fechas anteriores a 1582. Este calendario extendido se denomina calendario gregoriano proleptico.
Databricks Runtime 7.0 usa el calendario gregoriano proleptico, que ya está siendo utilizado por otros sistemas de datos como pandas, R y Apache Arrow. Databricks Runtime 6.x y versiones posteriores usaron una combinación del calendario juliano y gregoriano: para las fechas anteriores a 1582, se usó el calendario juliano, para las fechas posteriores a 1582 se usó el calendario gregoriano. Esto se hereda de la API heredada java.sql.Date , que se ha reemplazado en Java 8 por java.time.LocalDate, que usa el calendario gregoriano proleptico.
Marcas de tiempo y zonas horarias
El Timestamp tipo amplía el Date tipo con nuevos campos: hora, minuto, segundo (que puede tener una parte fraccionaria) y junto con una zona horaria global (con ámbito de sesión). Define un instante de tiempo concreto. Por ejemplo, (year=2012, month=12, day=31, hour=23, minute=59, second=59.123456) con zona horaria de sesión UTC+01:00. Al escribir valores de marca de tiempo en orígenes de datos que no sean de texto como Parquet, los valores son simplemente instantáneas (como la marca de tiempo en UTC) que no tienen información de zona horaria. Si escribe y lee un valor de marca de tiempo con una zona horaria de sesión diferente, puede ver valores diferentes de los campos hora, minuto y segundo, pero son el mismo instante de tiempo concreto.
Los campos hour, minute y second tienen intervalos estándar: 0–23 para horas y 0–59 durante minutos y segundos. Spark admite fracciones de segundos con una precisión de hasta microsegundos. El intervalo válido para fracciones es de 0 a 999,999 microsegundos.
En cualquier instante concreto, dependiendo de la zona horaria, puede observar muchos valores de reloj de pared diferentes:
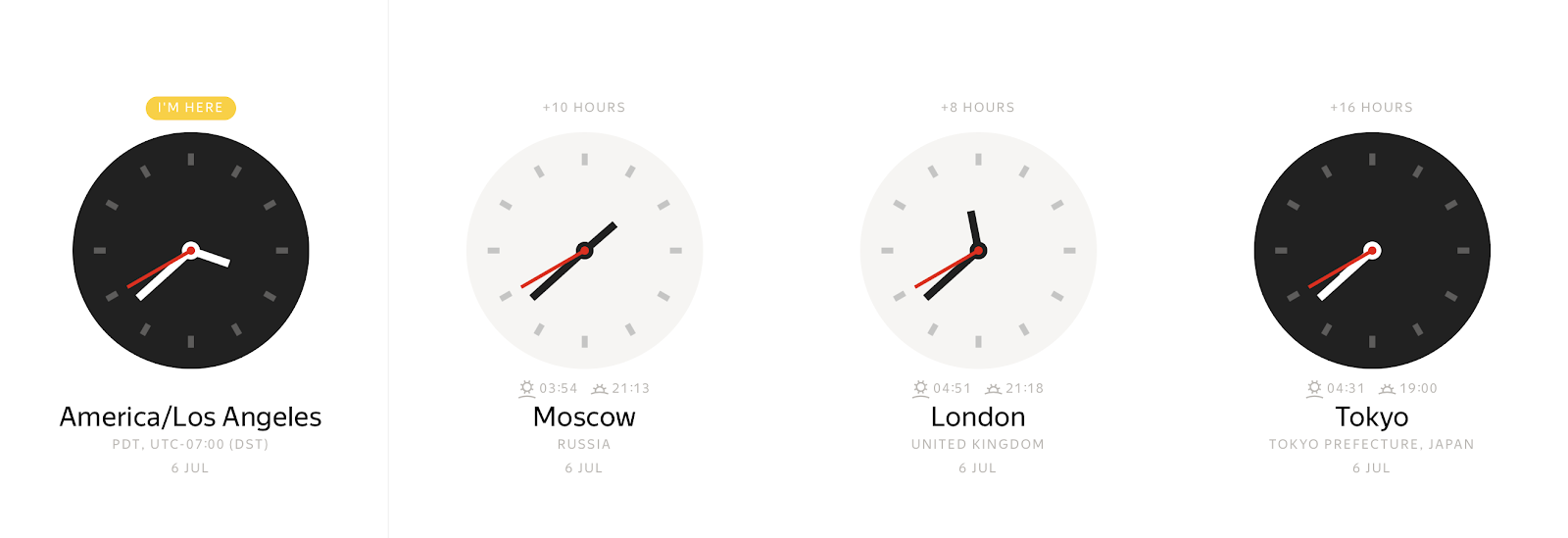
Por el contrario, un valor de reloj de pared puede representar muchos instantes de tiempo diferentes.
El desplazamiento de zona horaria permite enlazar de forma inequívoca una marca de tiempo local a un instante de tiempo. Normalmente, los desplazamientos de zona horaria se definen como desplazamientos en horas desde la hora media de Greenwich (GMT) o UTC+0 (hora universal coordinada). Esta representación de la información de zona horaria elimina la ambigüedad, pero no es conveniente. La mayoría de las personas prefieren señalar una ubicación como America/Los_Angeles o Europe/Paris. Este nivel adicional de abstracción de los desplazamientos de zona facilita la vida, pero aporta complicaciones. Por ejemplo, ahora tiene que mantener una base de datos específica de zona horaria para asignar nombres de zona horaria a desplazamientos. Dado que Spark se ejecuta en la JVM, delega la asignación a la biblioteca estándar de Java, que carga datos de la base de datos de zonas horarias de la Autoridad de Números Asignados en Internet (IANA TZDB). Además, el mecanismo de asignación de la biblioteca estándar de Java tiene algunos matices que influyen en el comportamiento de Spark.
Desde Java 8, JDK expone una API diferente para la manipulación de fecha y hora y la resolución de desplazamiento de zona horaria y Databricks Runtime 7.0 usa esta API. Aunque la asignación de nombres de zona horaria a desplazamientos tiene el mismo origen, IANA TZDB, se implementa de forma diferente en Java 8 y versiones posteriores en comparación con Java 7.
Por ejemplo, eche un vistazo a una marca de tiempo antes del año 1883 en la America/Los_Angeles zona horaria: 1883-11-10 00:00:00. Este año destaca de otros porque el 18 de noviembre de 1883, todos los ferrocarrils norteamericanos cambiaron a un nuevo sistema de tiempo estándar. Con la API de hora de Java 7, puede obtener un desplazamiento de zona horaria en la marca de tiempo local como -08:00:
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
La API de Java 8 equivalente devuelve un resultado diferente:
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
Antes del 18 de noviembre de 1883, la hora del día en Norteamérica era una cuestión local, y la mayoría de las ciudades y pueblos utilizaban alguna forma de hora solar local, mantenida por un reloj conocido (por ejemplo, en una iglesia empinada, o en la ventana de un joyero). Por eso ves un desplazamiento de zona horaria tan extraño.
En el ejemplo se muestra que las funciones de Java 8 son más precisas y tienen en cuenta los datos históricos de IANA TZDB. Después de cambiar a la API de hora de Java 8, Databricks Runtime 7.0 se benefició de la mejora automáticamente y se volvió más precisa en cómo resuelve los desplazamientos de zona horaria.
Databricks Runtime 7.0 también cambió al calendario gregoriano proléptico para el tipo Timestamp. El estándar ISO SQL:2016 declara el intervalo válido para las marcas de tiempo de 0001-01-01 00:00:00 a 9999-12-31 23:59:59.999999. Databricks Runtime 7.0 se ajusta completamente al estándar y admite todas las marcas de tiempo de este intervalo. En comparación con Databricks Runtime 6.x y versiones posteriores, tenga en cuenta los siguientes sub ranges:
-
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Databricks Runtime 6.x y versiones posteriores usa el calendario Julian y no se ajusta al estándar. Databricks Runtime 7.0 corrige el problema y aplica el calendario gregoriano proleptico en operaciones internas en marcas de tiempo, como obtener año, mes, día, etc. Debido a diferentes calendarios, algunas fechas que existen en Databricks Runtime 6.x y a continuación no existen en Databricks Runtime 7.0. Por ejemplo, 1000-02-29 no es una fecha válida porque 1000 no es un año bisiesto en el calendario gregoriano. Además, Databricks Runtime 6.x y versiones anteriores resuelven el nombre de zona horaria en desplazamientos de zona incorrectamente para este rango de marcas de tiempo. -
1582-10-04 00:00:00..1582-10-14 23:59:59.999999. Se trata de un intervalo válido de marcas de tiempo locales en Databricks Runtime 7.0, a diferencia de Databricks Runtime 6.x y por debajo de dónde no existían dichas marcas de tiempo. -
1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Databricks Runtime 7.0 resuelve correctamente los desplazamientos de zona horaria mediante datos históricos de IANA TZDB. En comparación con Databricks Runtime 7.0, Databricks Runtime 6.x y versiones posteriores podrían resolver los desplazamientos de zona de nombres de zona horaria incorrectamente en algunos casos, como se muestra en el ejemplo anterior. -
1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Tanto Databricks Runtime 7.0 como Databricks Runtime 6.x se ajustan al estándar ANSI SQL y usan el calendario gregoriano en operaciones de fecha y hora, como obtener el día del mes. -
2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Databricks Runtime 6.x y versiones posteriores pueden resolver los desplazamientos de zona horaria y los desplazamientos de horario de verano incorrectamente. Databricks Runtime 7.0 no lo hace.
Un aspecto más del mapeo de nombres de zona horaria con sus diferencias es la superposición de marcas de tiempo locales que puede ocurrir debido al horario de verano (DST) o al cambio a otro desplazamiento estándar de zona horaria. Por ejemplo, el 3 de noviembre de 2019, a las 02:00:00, la mayoría de los estados de EE. UU. retrocedieron los relojes 1 hora, a las 01:00:00. La marca 2019-11-03 01:30:00 America/Los_Angeles de tiempo local se puede asignar a 2019-11-03 01:30:00 UTC-08:00 o 2019-11-03 01:30:00 UTC-07:00. Si no especifica el desplazamiento y solo establece el nombre de zona horaria (por ejemplo, 2019-11-03 01:30:00 America/Los_Angeles), Databricks Runtime 7.0 toma el desplazamiento anterior, normalmente correspondiente a "verano". El comportamiento se diferencia de versiones anteriores a Databricks Runtime 6.x, que toman el ajuste "invierno". En el caso de un hueco, donde los relojes saltan hacia delante, no hay ningún desplazamiento válido. Para un cambio típico de horario de verano de una hora, Spark mueve estas marcas de tiempo a la siguiente marca de tiempo válida correspondiente a la hora de "verano".
Como puede observar en los ejemplos anteriores, la correspondencia entre los nombres de zona de tiempo y sus desplazamientos es ambigua y no es una relación uno a uno. En los casos en los que es posible, al construir marcas de tiempo se recomienda especificar desplazamientos exactos de zona horaria, por ejemplo 2019-11-03 01:30:00 UTC-07:00.
Marcas de tiempo de ANSI SQL y Spark SQL
El estándar ANSI SQL define dos tipos de marcas de tiempo:
-
TIMESTAMP WITHOUT TIME ZONEoTIMESTAMP: marca de tiempo local como (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND). Estas marcas de tiempo no están enlazadas a ninguna zona horaria y son marcas de tiempo de reloj de pared. -
TIMESTAMP WITH TIME ZONE: Marca de tiempo con zona como (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND,TIMEZONE_HOUR,TIMEZONE_MINUTE). Estas marcas de tiempo representan un instante en la zona horaria UTC + un desplazamiento de zona horaria (en horas y minutos) asociado a cada valor.
El desplazamiento de zona horaria de un TIMESTAMP WITH TIME ZONE no afecta al momento físico en el tiempo que representa la marca de tiempo, ya que está totalmente representada por el instante de hora UTC proporcionado por los demás componentes de marca de tiempo. En su lugar, el desplazamiento de zona horaria solo afecta al comportamiento predeterminado de un valor de marca de tiempo para la visualización, la extracción de componentes de fecha y hora (por ejemplo, EXTRACT) y otras operaciones que requieren conocer una zona horaria, como agregar meses a una marca de tiempo.
Spark SQL define el tipo de marca de tiempo como TIMESTAMP WITH SESSION TIME ZONE, que es una combinación de los campos (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, SESSION TZ) donde el campo YEAR al SECOND identifica un instante de hora en la zona horaria UTC y donde se toma SESSION TZ de la configuración de SQL spark.sql.session.timeZone. La zona horaria de sesión se puede establecer como:
-
(+|-)HH:mmDesplazamiento de zona . Este formulario le permite definir de forma inequívoca un momento físico en el tiempo. - Nombre de zona horaria en forma de identificador
area/cityde área, comoAmerica/Los_Angeles. Esta forma de información de zona horaria sufre algunos de los problemas descritos anteriormente, como la superposición de marcas de tiempo locales. Sin embargo, cada instante de hora UTC está asociado inequívocamente con un desplazamiento de zona horaria para cualquier identificador de región y, como resultado, cada marca de tiempo con una zona horaria basada en identificador de región puede convertirse inequívocamente a una marca de tiempo con un desplazamiento de zona. De forma predeterminada, la zona horaria de sesión se establece en la zona horaria predeterminada de la máquina virtual Java.
Spark TIMESTAMP WITH SESSION TIME ZONE es diferente de lo siguiente:
-
TIMESTAMP WITHOUT TIME ZONE, dado que un valor de este tipo puede asignarse a varios instantes de tiempo físicos, pero cualquier valor deTIMESTAMP WITH SESSION TIME ZONEes un instante de tiempo físico concreto. El tipo SQL se puede emular mediante un desplazamiento fijo de zona horaria en todas las sesiones, por ejemplo UTC+0. En ese caso, podría considerar las marcas de tiempo en UTC como marcas de tiempo locales. -
TIMESTAMP WITH TIME ZONE, dado que según el estándar SQL, los valores de las columnas del tipo pueden tener diferentes desplazamientos de la zona horaria. No es compatible con Spark SQL.
Debe observar que las marcas de tiempo asociadas a una zona horaria global (con ámbito de sesión) no son algo recién inventado por Spark SQL. LOS RDBMS, como Oracle, proporcionan un tipo similar para las marcas de tiempo: TIMESTAMP WITH LOCAL TIME ZONE.
Construcción de fechas y marcas de tiempo
Spark SQL proporciona algunos métodos para construir valores de fecha y marca de tiempo:
- Constructores predeterminados sin parámetros:
CURRENT_TIMESTAMP()yCURRENT_DATE(). - Desde otros tipos primitivos de Spark SQL, como
INT,LONGySTRING - Desde tipos externos, como datetime de Python o clases de Java
java.time.LocalDate/Instant. - Deserialización de orígenes de datos como CSV, JSON, Avro, Parquet, ORC, etc.
La función MAKE_DATE introducida en Databricks Runtime 7.0 toma tres parámetros(YEAR , MONTHy DAY) y crea un DATE valor. Todos los parámetros de entrada se convierten implícitamente en el INT tipo siempre que sea posible. La función comprueba que las fechas resultantes son fechas válidas en el calendario gregoriano proléptico; de lo contrario, devuelve NULL. Por ejemplo:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
Para imprimir contenido de DataFrame, llame a la show() acción , que convierte fechas en cadenas en ejecutores y transfiere las cadenas al controlador para generarlas en la consola:
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
Del mismo modo, puede construir valores de marca de tiempo mediante las MAKE_TIMESTAMP funciones . Al igual que MAKE_DATE, realiza la misma validación para los campos de fecha y, además, acepta los campos de hora HORA (0-23), MINUTO (0-59) y SEGUNDO (0-60). SECOND tiene el tipo Decimal(precision = 8, escala = 6) porque los segundos se pueden pasar con la parte fraccionaria hasta la precisión de microsegundos. Por ejemplo:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
En cuanto a las fechas, muestra el contenido del DataFrame ts utilizando la acción show(). De forma similar, show() convierte marcas de tiempo en cadenas, pero ahora tiene en cuenta la zona horaria de sesión definida por la configuración spark.sql.session.timeZonede SQL .
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
Spark no puede crear la última marca de tiempo porque esta fecha no es válida: 2019 no es un año bisiesto.
Es posible que observe que no hay información de zona horaria en el ejemplo anterior. En ese caso, Spark toma una zona horaria de la configuración spark.sql.session.timeZone de SQL y la aplica a las invocaciones de función. También puede elegir una zona horaria diferente pasandola como el último parámetro de MAKE_TIMESTAMP. Este es un ejemplo:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
Como se muestra en el ejemplo, Spark tiene en cuenta las zonas horarias especificadas, pero ajusta todas las marcas de tiempo locales a la zona horaria de la sesión. Las zonas horarias originales pasadas a la MAKE_TIMESTAMP función se pierden porque el TIMESTAMP WITH SESSION TIME ZONE tipo supone que todos los valores pertenecen a una zona horaria y ni siquiera almacena una zona horaria por cada valor. Según la definición de TIMESTAMP WITH SESSION TIME ZONE, Spark almacena marcas de tiempo locales en la zona horaria UTC y usa la zona horaria de sesión al extraer campos de fecha y hora o convertir las marcas de tiempo en cadenas.
Además, las marcas de tiempo se pueden construir a partir del tipo LONG mediante la conversión. Si una columna LONG contiene el número de segundos desde la época 1970-01-01 00:00:00Z, se puede convertir a Spark SQL TIMESTAMP:
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
Desafortunadamente, este enfoque no permite especificar la parte fraccionaria de segundos.
Otra manera es construir fechas y marcas de tiempo a partir de valores del STRING tipo. Puede crear literales con palabras clave especiales:
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
Como alternativa, puede usar la conversión que puede aplicar para todos los valores de una columna:
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
Las cadenas de marca de tiempo de entrada se interpretan como marcas de tiempo locales en la zona horaria especificada o en la zona horaria de sesión si se omite una zona horaria en la cadena de entrada. Las cadenas con patrones inusuales se pueden convertir en marca de tiempo mediante la to_timestamp() función . Los patrones admitidos se describen en Patrones de fecha y hora para formateo y análisis:
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
Si no especifica un patrón, la función se comporta de forma similar a CAST.
Para su facilidad de uso, Spark SQL reconoce valores de cadena especiales en todos los métodos que aceptan una cadena y devuelven una marca de tiempo o una fecha:
-
epoches un alias para fecha1970-01-01o marca1970-01-01 00:00:00Zde tiempo . -
nowes la marca de tiempo o la fecha actuales en la zona horaria de la sesión. Dentro de una sola consulta, siempre genera el mismo resultado. -
todayes el principio de la fecha actual delTIMESTAMPtipo o simplemente la fecha actual delDATEtipo. -
tomorrowes el principio del día siguiente para las marcas de tiempo o solo el día siguiente para elDATEtipo. -
yesterdayes el día anterior al día actual o su comienzo para tipoTIMESTAMP.
Por ejemplo:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
Spark permite crear Datasets a partir de colecciones existentes de objetos externos en el lado del controlador y crear columnas de los tipos correspondientes. Spark convierte instancias de tipos externos en representaciones internas semánticamente equivalentes. Por ejemplo, para crear una Dataset con columnas DATE y TIMESTAMP a partir de listas en Python, puede usar:
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
PySpark convierte los objetos de fecha y hora de Python en representaciones internas de Spark SQL en el lado del controlador mediante la zona horaria del sistema, que puede ser diferente de la configuración spark.sql.session.timeZonede zona horaria de sesión de Spark. Los valores internos no contienen información sobre la zona horaria original. Las operaciones futuras sobre los valores de fecha y sello de tiempo paralelizados solo tienen en cuenta la zona horaria de las sesiones de Spark SQL según la definición del tipo TIMESTAMP WITH SESSION TIME ZONE.
De forma similar, Spark reconoce los siguientes tipos como tipos de fecha y hora externos en las API de Java y Scala:
-
java.sql.Dateyjava.time.LocalDatecomo tipos externos para elDATEtipo -
java.sql.Timestampyjava.time.Instantpara elTIMESTAMPtipo.
Hay una diferencia entre los tipos de java.sql.* y java.time.*.
java.time.LocalDate y java.time.Instant se agregaron en Java 8, y los tipos se basan en el calendario gregoriano proleptico, el mismo calendario que usa Databricks Runtime 7.0 y versiones posteriores.
java.sql.Date y java.sql.Timestamp tienen otro calendario debajo: el calendario híbrido (Juliano + Gregoriano desde 1582-10-15), que es el mismo que el calendario heredado usado por Databricks Runtime 6.x y versiones anteriores. Debido a diferentes sistemas de calendario, Spark tiene que realizar operaciones adicionales durante las conversiones a las representaciones internas de Spark SQL y reordenar fechas y sellos de tiempo de entrada de un calendario a otro. La operación de rebase tiene una pequeña sobrecarga para las marcas de tiempo modernas después del año 1900, y puede ser más significativa para las marcas de tiempo antiguas.
En el ejemplo siguiente se muestra cómo realizar marcas de tiempo de colecciones de Scala. En el primer ejemplo se construye un java.sql.Timestamp objeto a partir de una cadena. El valueOf método interpreta las cadenas de entrada como una marca de tiempo local en la zona horaria predeterminada de JVM, que puede ser diferente de la zona horaria de sesión de Spark. Si necesita construir instancias de java.sql.Timestamp o java.sql.Date en una zona horaria específica, vea java.text.SimpleDateFormat (y su método setTimeZone) o java.util.Calendar.
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
De forma similar, puede crear una DATE columna de colecciones de java.sql.Date o java.sql.LocalDate. La paralelización de java.sql.LocalDate instancias es totalmente independiente de la sesión de Spark o de las zonas horarias predeterminadas de JVM, pero lo mismo no es cierto para la paralelización de java.sql.Date instancias. Hay matices:
-
java.sql.Datelas instancias representan fechas locales en la zona horaria predeterminada de JVM en el controlador. - Para las conversiones correctas a valores de Spark SQL, la zona horaria predeterminada de JVM en el controlador y ejecutores debe ser la misma.
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
Para evitar cualquier problema relacionado con el calendario y la zona horaria, recomendamos utilizar los tipos de Java 8 java.sql.LocalDate/Instant como tipos externos en la paralelización de colecciones de Java/Scala, ya sea de marcas de hora o fechas.
Recopilar fechas y marcas de tiempo
La operación inversa de paralelización consiste en recopilar fechas y marcas de tiempo de los ejecutores de vuelta al controlador y devolver una colección de tipos externos. Por ejemplo, puede devolver la DataFrame al conductor mediante la acción collect().
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
Spark transfiere valores internos de las columnas de fechas y marcas de tiempo como instantes de hora en la zona horaria UTC de ejecutores al controlador y realiza conversiones a objetos datetime de Python en la zona horaria del sistema en el controlador, no mediante la zona horaria de sesión de Spark SQL.
collect() es diferente de la show() acción descrita en la sección anterior.
show() usa la zona horaria de sesión al convertir marcas de tiempo en cadenas y recopila las cadenas resultantes en el controlador.
En las API de Java y Scala, Spark realiza las conversiones siguientes de forma predeterminada:
- Los valores de Spark SQL
DATEse convierten en instancias dejava.sql.Date. - Los valores de Spark SQL
TIMESTAMPse convierten en instancias dejava.sql.Timestamp.
Ambas conversiones se realizan en la zona horaria predeterminada de JVM en el controlador. De este modo, para tener los mismos campos de fecha y hora que puede obtener mediante Date.getDay(), getHour(), etc., y con las funciones DAYde Spark SQL , HOUR, la zona horaria predeterminada de JVM en el controlador y la zona horaria de sesión en los ejecutores deben ser iguales.
De forma similar a crear fechas o marcas de tiempo desde java.sql.Date/Timestamp, Databricks Runtime 7.0 realiza el cambio de base del calendario gregoriano proléptico al calendario híbrido (Juliano + Gregoriano). Esta operación es casi gratuita para fechas modernas (después del año 1582) y marcas de tiempo (después del año 1900), pero podría traer cierta sobrecarga para fechas antiguas y marcas de tiempo.
Puede evitar estos problemas relacionados con el calendario y pedir a Spark que devuelva java.time tipos, que se agregaron desde Java 8. Si estableces la configuración de SQL en spark.sql.datetime.java8API.enabled a true, la acción Dataset.collect() devuelve:
-
java.time.LocalDatepara el tipo de SQLDATEde Spark -
java.time.Instantpara el tipo de SQLTIMESTAMPde Spark
Ahora las conversiones no sufren de los problemas relacionados con el calendario porque los tipos de Java 8 y Databricks Runtime 7.0 y versiones posteriores se basan en el calendario proléptico gregoriano. La collect() acción no depende de la zona horaria predeterminada de JVM. Las conversiones de marca de tiempo no dependen de la zona horaria en absoluto. Las conversiones de fecha usan la zona horaria de sesión de la configuración spark.sql.session.timeZonede SQL. Por ejemplo, considere una Dataset con columnas DATE y TIMESTAMP, con la zona horaria predeterminada de JVM establecida en Europe/Moscow y la zona horaria de sesión establecida en America/Los_Angeles.
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
La show() acción imprime la marca de tiempo en el momento America/Los_Angeles de la sesión, pero si recopila el Dataset, se convierte en java.sql.Timestamp y el método toString imprime Europe/Moscow:
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
En realidad, la marca de tiempo local 2020-07-01 00:00:00 es 2020-07-01T07:00:00Z a las UTC. Puede observar que si habilita la API de Java 8 y recopila el conjunto de datos:
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
Puede convertir un java.time.Instant objeto en cualquier marca de tiempo local independientemente de la zona horaria global de JVM. Esta es una de las ventajas de java.time.Instant sobre java.sql.Timestamp. El primero requiere cambiar la configuración global de JVM, lo que influye en otras marcas de tiempo en la misma JVM. Por lo tanto, si las aplicaciones procesan fechas o marcas de tiempo en diferentes zonas horarias, y las aplicaciones no deben entrar en conflicto entre sí mientras recopilan datos para el controlador mediante la API de Java o Scala Dataset.collect(), se recomienda cambiar a la API de Java 8 mediante la configuración de SQL spark.sql.datetime.java8API.enabled.