Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
La organización de este artículo asume que está usando la interfaz de usuario de cálculo sencilla. Para obtener información general sobre las actualizaciones de formulario simples, consulte Uso del formulario sencillo para administrar el proceso.
En este artículo se explican las configuraciones disponibles al crear un nuevo recurso de cómputo multifuncional o de tareas. La mayoría de los usuarios crean recursos de proceso mediante las directivas asignadas, lo que limita las opciones configurables. Si no ve una configuración determinada en la interfaz de usuario, se debe a que la directiva que ha seleccionado no le permite configurar esa opción.
Para obtener recomendaciones sobre cómo configurar el proceso para la carga de trabajo, consulte Recomendaciones de configuración de proceso.
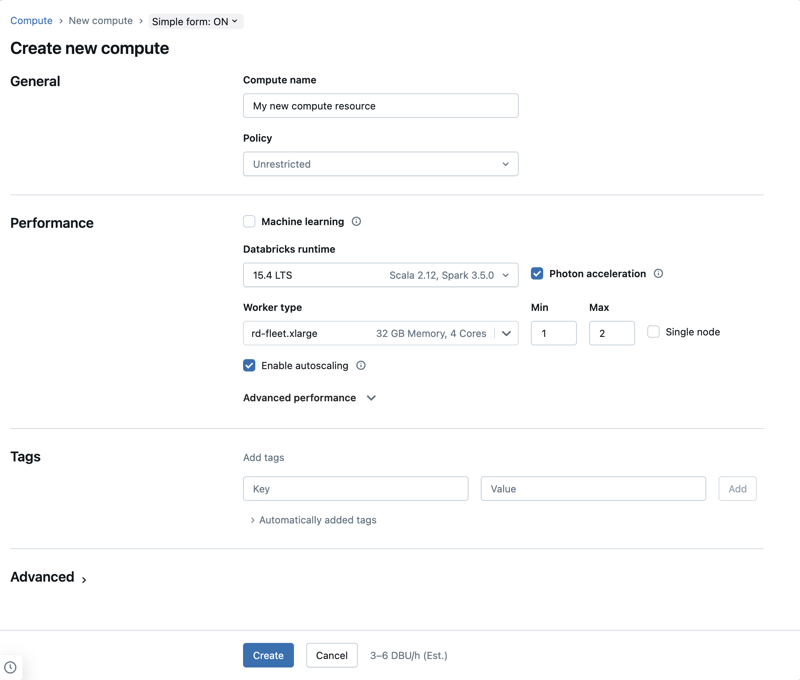
Las configuraciones y las herramientas de administración que se describen en este artículo se aplican tanto al procesamiento de propósitos generales como al procesamiento por trabajo. Para obtener más información acerca de la configuración de computación para tareas, consulte Configurar la computación para tareas.
Creación de un nuevo recurso de computación de propósito general
Para crear un nuevo recurso computacional versátil, siga estos pasos:
- En la barra lateral del área de trabajo, haga clic en Proceso.
- Haga clic en el botón Crear cómputo.
- Configurar el recurso de computación.
- Haga clic en Crear.
Su nuevo recurso de proceso comenzará a funcionar automáticamente y estará listo para usarse en breve.
Política de cómputo
Las directivas son un conjunto de reglas que se usan para limitar las opciones de configuración disponibles para los usuarios al crear recursos de proceso. Si un usuario no tiene derechos de creación de clústeres sin restricciones , solo puede crear recursos de proceso mediante sus directivas concedidas.
Para crear recursos de proceso en función de una directiva, seleccione una directiva del menú desplegable Directiva.
De forma predeterminada, todos los usuarios tienen acceso a la directiva de Proceso personal, lo que les permite crear fácilmente recursos de proceso de una sola máquina. Si necesita acceso a Personal Compute o a otras políticas adicionales, póngase en contacto con el administrador del espacio de trabajo.
Configuración de rendimiento
La siguiente configuración aparece en la sección Rendimiento de la interfaz de usuario de proceso de formulario simple:
- Versiones de Databricks Runtime
- Uso de la aceleración de Photon
- Tipo de nodo de trabajo
- Computación de un solo nodo
- Habilitación del escalado automático
- Configuración de rendimiento avanzada
Versiones de Databricks Runtime
Databricks Runtime es el conjunto de componentes principales que se ejecutan en tu infraestructura de computación. Seleccionar el runtime usando el menú desplegable Databricks Runtime Version. Para obtener detalles sobre versiones específicas de Databricks Runtime, consulte las notas de la versión y compatibilidad de Databricks Runtime. Todas las versiones incluyen Apache Spark. Databricks recomienda lo siguiente:
- Para procesos multiuso, use la versión actual para garantizar que tenga las optimizaciones más recientes y la compatibilidad más actualizada entre el código y los paquetes cargados previamente.
- Para cargas de trabajo operativas en ejecución, considere usar una versión de Databricks Runtime con soporte a largo plazo (LTS). El uso de la versión LTS garantizará que no se encuentra con problemas de compatibilidad y puede probar exhaustivamente la carga de trabajo antes de actualizar.
- Para casos de uso de ciencia de datos y aprendizaje automático, considere la versión Databricks Runtime ML.
Utiliza la aceleración de Photon
Photon está habilitado de forma predeterminada en procesos que ejecuten Databricks Runtime 9.1 LTS y versiones posteriores.
Para habilitar o deshabilitar la aceleración de Photon, active la casilla Usar aceleración de Photon. Para obtener más información sobre Photon, consulte ¿Qué es Photon?.
Tipo de nodo de trabajo
Un recurso de cómputo consta de un nodo controlador y cero o varios nodos de trabajo. Puede elegir tipos de instancia de proveedor de nube independientes para los nodos de controlador y de trabajo, aunque de forma predeterminada el nodo de controlador usa el mismo tipo de instancia que el nodo de trabajo. La configuración del nodo de controlador está debajo de la sección Rendimiento avanzado .
Las distintas familias de tipos de instancia se ajustan a distintas aplicaciones, como cargas de trabajo de uso intensivo de memoria o de computación intensiva. También es posible seleccionar un grupo para usarlo como nodo de trabajo o controlador.
Importante
No use un grupo con instancias de acceso puntual como tipo de controlador. Seleccione un tipo de controlador a petición para evitar que se recupere el controlador. Consulte Conexión a los grupos.
En procesos de varios nodos, los nodos de trabajo ejecutan los ejecutores de Spark y otros servicios necesarios para el correcto funcionamiento de un recurso de proceso. Al distribuir la carga de trabajo con Spark, todo el procesamiento distribuido se produce en los nodos de trabajo. Azure Databricks ejecuta un ejecutor por nodo de trabajo. Por lo tanto, los términos ejecutor y nodo de trabajo se usan indistintamente en el contexto de la arquitectura de Databricks.
Sugerencia
Para ejecutar un trabajo de Spark, necesita al menos un nodo trabajador. Si el recurso de proceso tiene cero trabajadores, es posible ejecutar comandos que no sean de Spark en el nodo de controlador, pero se producirá un error en los comandos de Spark.
Tipos de nodo flexibles
Si el área de trabajo tiene habilitados tipos de nodo flexibles, puede usar tipos de nodo flexibles para el recurso de cómputo. Los tipos de nodo flexibles permiten que el recurso de proceso vuelva a tipos de instancias alternativos y compatibles cuando el tipo de instancia especificado no esté disponible. Este comportamiento mejora la confiabilidad del inicio de proceso al reducir los errores de capacidad durante los inicios de proceso. Consulte Mejora de la confiabilidad del inicio de proceso mediante tipos de nodo flexibles.
Direcciones IP de los nodos de trabajo
Azure Databricks inicia nodos de trabajo con dos direcciones IP privadas cada una. La dirección IP privada principal del nodo es la que hospeda el tráfico interno de Azure Databricks. La dirección IP privada secundaria es la que usa el contenedor de Spark para la comunicación entre clústeres. Este modelo permite Azure Databricks proporcionar aislamiento entre varios recursos de proceso en la misma área de trabajo.
Tipos de instancia de GPU
Para tareas complejas de cálculo que exigen un alto rendimiento, como las asociadas al aprendizaje profundo, Azure Databricks admite recursos de proceso que se aceleran con unidades de procesamiento de gráficos (GPU). Para más información, consulte Cómputo habilitado para GPU.
Máquinas virtuales confidenciales de computación de Azure
Los tipos de máquinas virtuales de computación confidencial de Azure impiden el acceso no autorizado a los datos mientras están en uso, incluyendo frente al operador de la nube. Este tipo de máquina virtual es beneficioso para sectores y regiones altamente regulados, así como para empresas con datos confidenciales en la nube. Para obtener más información sobre la computación confidencial de Azure, consulte Azure computación confidencial.
Para ejecutar las cargas de trabajo utilizando máquinas virtuales de computación confidencial de Azure, seleccione los tipos de máquina virtual de la serie DC o EC en las listas desplegables del nodo de trabajo y conductor. Consulte Opciones de máquina virtual confidencial de Azure.
Computación de un solo nodo
La casilla Nodo único permite crear un recurso de proceso de nodo único.
Los procesos de nodo único están pensados para trabajos que usan pequeñas cantidades de datos o cargas de trabajo no distribuidas, como las bibliotecas de aprendizaje automático de nodo único. Los procesos de varios nodos deberían usarse para trabajos más grandes con cargas de trabajo distribuidas.
Propiedades de nodo único
Los recursos de proceso de nodo único tienen las siguientes propiedades:
- Ejecuta Spark localmente.
- El driver actúa tanto de maestro como de trabajador, sin nodos trabajadores.
- Genera un subproceso de ejecutor por núcleo lógico en el recurso de proceso, menos un núcleo para el controlador.
- Guarda todas las salidas de registro
stderr,stdoutylog4jen el registro del controlador. - No se puede convertir en un recurso de proceso de varios nodos.
Seleccionar un solo nodo o varios nodos
Tenga en cuenta el caso de uso al decidir entre procesos de un solo nodo o varios nodos:
El procesamiento de datos a gran escala agotará los recursos de un recurso de proceso de nodo único. Para estas cargas de trabajo, Databricks recomienda usar un proceso de varios nodos.
Un recurso de computación de varios nodos no se puede escalar a 0 trabajadores. En su lugar, use una computación de nodo único.
La programación de GPU no está habilitada en los procesos de nodo único.
En un único nodo, Spark no puede leer archivos Parquet con una columna UDT. Aparece el siguiente mensaje de error:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Para solucionar este problema, deshabilite el lector nativo de Parquet:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Habilitar escalado automático
Cuando se activa Habilitar escalado automático, puede establecer un número mínimo y máximo de trabajadores para el recurso de cálculo. A continuación, Databricks selecciona el número adecuado de trabajadores necesarios para ejecutar la tarea.
Para establecer el número mínimo y el número máximo de trabajadores entre los que se escalará automáticamente el recurso de cómputo, use los campos Min y Max junto a la lista desplegable Tipo de trabajador.
Si no habilita el escalado automático, debe escribir un número fijo de trabajadores en el campo Trabajadores junto al menú desplegable Tipo de trabajador.
Nota:
Cuando se ejecuta el recurso de computación, la página de detalles del recurso muestra el número de trabajadores asignados. Puede comparar el número de trabajos asignados con la configuración de trabajo y realizar ajustes según sea necesario.
Ventajas del escalado automático
Con el escalado automático, Azure Databricks reasigna dinámicamente los trabajos para tener en cuenta las características de su trabajo. Algunas partes de la canalización pueden ser más exigentes de cálculo que otras y Databricks agrega automáticamente trabajos adicionales durante estas fases del trabajo (y los quita cuando ya no son necesarios).
El escalado automático facilita lograr una alta utilización porque no es necesario aprovisionar la capacidad de cómputo para que coincida con una carga de trabajo. Esto se aplica especialmente a las cargas de trabajo cuyos requisitos cambian con el tiempo (como explorar un conjunto de datos en el transcurso de un día), pero también se puede aplicar a una carga de trabajo única más corta cuyos requisitos de aprovisionamiento se desconocen. Por lo tanto, el escalado automático ofrece dos ventajas:
- Las cargas de trabajo se pueden ejecutar más rápido en comparación con un recurso de cálculo de tamaño constante insuficientemente aprovisionado.
- El escalado automático puede reducir los costos generales en comparación con un recurso de proceso de tamaño estático.
En función del tamaño constante del recurso de proceso y la carga de trabajo, el escalado automático le ofrece una o ambas ventajas al mismo tiempo. El tamaño de cómputo puede estar por debajo del número mínimo de trabajadores seleccionados cuando el proveedor de nube termina las instancias. En este caso, Azure Databricks reintenta continuamente volver a aprovisionar instancias con el fin de mantener el número mínimo de trabajadores.
Nota:
El escalado automático no está disponible para los trabajos de spark-submit.
Nota:
El escalado automático de cómputo tiene limitaciones al reducir el tamaño del clúster para cargas de trabajo de Structured Streaming. Databricks recomienda usar canalizaciones declarativas de Spark de Lakeflow con escalado automático mejorado para cargas de trabajo de streaming. Consulte Optimización del uso del clúster de canalizaciones declarativas de Spark de Lakeflow con escalado automático.
Cómo se comporta el escalado automático
El espacio de trabajo en el Plan Premium utiliza el escalado automático optimizado. Las áreas de trabajo del plan de precios estándar usan el escalado automático estándar.
El escalado automático optimizado tiene las siguientes características:
- El escalado va de mínimo a máximo en 2 pasos.
- Es posible reducir la escala, incluso si el recurso de cómputo no está inactivo, si se observa el estado del archivo de intercambio.
- Reduce en función de un porcentaje de los nodos actuales.
- En el cómputo de tareas, reduce o escala hacia abajo si el recurso de cálculo ha sido subutilizado en los últimos 40 segundos.
- En cómputo de uso general, reduce si el recurso de cómputo ha estado infrautilizado en los últimos 150 segundos.
- La propiedad
spark.databricks.aggressiveWindowDownSde configuración de Spark especifica en segundos la frecuencia con la que el proceso toma decisiones de reducción vertical. Al aumentar el valor, el proceso de cálculo se reduce más lentamente. El valor máximo es 600.
El escalado automático estándar se utiliza en espacios de trabajo del plan estándar. El escalado automático estándar tiene las siguientes características:
- Comienza agregando 8 nodos. Luego se expande exponencialmente, dando tantos pasos como sea necesario para alcanzar el máximo.
- Se reduce cuando el 90 % de los nodos no están ocupados durante 10 minutos y los recursos de cálculo han estado inactivos durante al menos 30 segundos.
- Se escala verticalmente de manera exponencial, empezando por 1 nodo.
Advertencia
No habilite la asignación dinámica de Apache Spark (spark.dynamicAllocation.enabled) en los recursos de proceso que usan el escalado automático de Databricks. El escalado automático de Databricks administra los nodos de trabajo y el ciclo de vida del ejecutor en el nivel de plataforma. La habilitación de la asignación dinámica de Spark en paralelo puede provocar decisiones de escalado en conflicto, lo que conduce a la rotación de ejecutores, NODES_LOST errores y tareas que nunca son recogidas.
Escalado automático con grupos
Si usted va a asociar su recurso de procesamiento a un pool, tenga en cuenta lo siguiente:
- Asegúrese de que el tamaño de cómputo solicitado sea menor o igual que el número mínimo de instancias inactivas del grupo. Si es mayor, el tiempo de inicio de cómputo será equivalente al cómputo que no usa un grupo de recursos.
- Asegúrese de que el tamaño máximo de cómputo sea menor o igual que la capacidad máxima del grupo. Si es mayor, fallará la creación del cómputo.
Ejemplo de escalado automático
Si vuelve a configurar un recurso de proceso estático para el escalado automático, Azure Databricks cambia inmediatamente el tamaño del recurso de proceso dentro de los límites mínimo y máximo y, a continuación, inicia el escalado automático. Por ejemplo, en la tabla siguiente se muestra lo que sucede con un recurso de proceso con un tamaño inicial determinado si se vuelve a configurar el recurso de proceso para escalar automáticamente entre 5 y 10 nodos.
| Tamaño inicial | Tamaño después de la reconfiguración |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Configuración de rendimiento avanzada
La siguiente configuración aparece en la sección Rendimiento avanzado de la interfaz de usuario de proceso de formulario simple.
Instancias de acceso puntual
Para ahorrar costos, puede elegir usar instancias Spot, también conocidas como máquinas virtuales Azure Spot marcando la casilla instancias de Spot.

La primera instancia siempre será bajo demanda (el nodo controlador siempre es bajo demanda) y las instancias posteriores serán instancias puntuales.
Si las instancias se expulsan debido a una falta de disponibilidad, Azure Databricks intentará adquirir nuevas instancias de spot para reemplazar las instancias expulsadas. Si las instancias de acceso puntual no se pueden adquirir, las instancias a petición se implementarán para reemplazar las instancias expulsadas. Esta conmutación por recuperación a petición solo se admite para instancias de spot que se han adquirido completamente y que se están ejecutando. Las instancias de spot que producen un error durante la configuración no se reemplazan automáticamente.
Además, cuando se agregan nuevos nodos a los recursos de proceso existentes, Azure Databricks intenta adquirir instancias de acceso puntual para esos nodos.
Terminación automática
Puede establecer la terminación automática para el proceso en la sección Rendimiento avanzado . Durante la creación del recurso informático, especifique un periodo de inactividad definido en minutos después del cual quiere que se termine el recurso informático.
Si la diferencia entre la hora actual y la última ejecución del comando en el recurso de proceso es mayor que el período de inactividad especificado, Azure Databricks finaliza automáticamente ese recurso de proceso. Para obtener más información sobre la terminación del proceso, consulte Finalizar un proceso.
Tipo de controlador
Puede seleccionar el tipo de controlador en la sección Rendimiento avanzado . El nodo de controlador mantiene la información de estado de todos los cuadernos asociados al recurso de proceso. El nodo de controlador también mantiene SparkContext, interpreta todos los comandos que se ejecutan desde un cuaderno o una biblioteca en el recurso de proceso y ejecuta el maestro de Apache Spark que se coordina con los ejecutores de Spark.
El valor predeterminado del tipo de nodo de controlador es el mismo que el tipo de nodo de trabajo. Puede elegir un tipo de nodo de controlador mayor con más memoria si planea collect() una gran cantidad de datos de los trabajadores de Spark y analizarlos en el cuaderno.
Sugerencia
Puesto que el nodo de controlador mantiene toda la información de estado de los cuadernos asociados, asegúrese de desasociar los cuadernos no utilizados del nodo de controlador.
Etiquetas
Las etiquetas permiten supervisar fácilmente el costo de los recursos de proceso usados por varios grupos de su organización. Especifique etiquetas como pares clave-valor al crear recursos de cómputo, y Azure Databricks aplica estas etiquetas a recursos en la nube, como máquinas virtuales y volúmenes de disco, así como a los registros de uso de Databricks.
En el caso de procesos iniciados desde grupos, las etiquetas personalizadas solo se aplican a los informes de uso de DBU y no se propagan a los recursos en la nube.
Para obtener información detallada sobre cómo funcionan conjuntamente los tipos de etiquetas de grupo y proceso, consulte Uso de etiquetas para atribuir y realizar un seguimiento del uso.
Para agregar etiquetas al recurso informático:
- En la sección Etiquetas, agregue un par clave-valor para cada etiqueta personalizada.
- Haga clic en Agregar.
Configuración avanzada
Las siguientes configuraciones aparecen en la sección Avanzadas de la interfaz de usuario de cálculo de formulario simple.
- Modos de acceso
- Habilitación del escalado automático del almacenamiento local
- Cifrado de disco local
- Configuración de Spark
- Entrega de registros de proceso
- Acceso SSH a recursos de computación
- Variables de entorno
Modos de acceso
El modo de acceso es una característica de seguridad que determina quién puede usar el recurso de proceso y a qué datos se pueden acceder mediante el recurso de proceso. Cada recurso de proceso de Azure Databricks tiene un modo de acceso. La configuración del modo de acceso se encuentra en la sección Avanzadas de la interfaz de usuario de proceso de formulario simple.
La selección del modo de acceso es Automática de forma predeterminada, lo que significa que el modo de acceso se elige automáticamente según el entorno de ejecución de Databricks seleccionado. El valor predeterminado es Estándar a menos que se seleccione un entorno de ejecución de aprendizaje automático o un Databricks Runtime inferior a 14.3, en cuyo caso se usa Dedicated.
Databricks recomienda usar el modo de acceso estándar a menos que no se admita la funcionalidad necesaria.
| Modo de acceso | Description | Idiomas admitidos |
|---|---|---|
| Estándar | Puede ser utilizado por varios usuarios con aislamiento de datos entre los usuarios. | Python, SQL, Scala |
| Dedicated | Puede ser asignado y utilizado por un único usuario o grupo. | Python, SQL, Scala, R |
Para obtener información detallada sobre la compatibilidad con la funcionalidad para cada uno de estos modos de acceso, consulte Requisitos y limitaciones de proceso estándar yRequisitos de proceso dedicados y limitaciones.
Nota:
En Databricks Runtime 13.3 LTS y versiones posteriores, se admiten scripts de inicialización y bibliotecas en todos los modos de acceso. Los requisitos y los niveles del soporte técnico varían. Consulte ¿Dónde se pueden instalar los scripts de inicialización? y Bibliotecas con ámbito de proceso.
Habilitar el escalado automático del almacenamiento local
A menudo puede ser difícil calcular cuánto espacio en disco necesitará un trabajo determinado. Para evitar que tenga que calcular cuántos gigabytes de discos administrados se van a conectar a su recurso de cómputo en el momento de la creación, Azure Databricks habilita automáticamente el autoescalado del almacenamiento local en todas las instancias de Azure Databricks.
Con el escalado automático del almacenamiento local, Azure Databricks supervisa la cantidad de espacio libre en disco disponible en los nodos de Spark de su computación. Si un trabajo comienza a ejecutarse con demasiado poco espacio en el disco, Databricks asocia automáticamente un nuevo disco administrado al trabajo antes de que se agote el espacio en disco. Los discos se conectan hasta un límite de 5 TB de espacio total en disco por máquina virtual (incluido el almacenamiento local inicial de la máquina virtual).
Los discos administrados conectados a una máquina virtual solo se desasocian cuando la máquina virtual se devuelve a Azure. Es decir, los discos administrados nunca se desasocian de una máquina virtual, siempre y cuando formen parte de un proceso en ejecución. Para reducir el uso de discos administrados, Azure Databricks recomienda usar esta característica en el cómputo configurado con autoscaling compute o terminación automática.
Cifrado de discos locales
Importante
Esta característica está en versión preliminar pública.
Algunos tipos de instancias que se usan para ejecutar procesos pueden tener discos conectados localmente. Azure Databricks puede almacenar datos de reordenamiento o datos efímeros en estos discos conectados localmente. Para asegurarse de que todos los datos en reposo están cifrados para todos los tipos de almacenamiento, incluidos los datos aleatorios que se almacenan temporalmente en los discos locales del recurso de proceso, puede habilitar el cifrado de disco local.
Importante
Las cargas de trabajo pueden ejecutarse más lentamente debido al impacto en el rendimiento de la lectura y escritura de datos cifrados hacia y desde los volúmenes locales.
Cuando se habilita el cifrado de disco local, Azure Databricks genera una clave de cifrado localmente que es única para cada nodo de proceso y se usa para cifrar todos los datos almacenados en discos locales. El ámbito de la clave es local para cada nodo del proceso y se destruye junto con el propio nodo del proceso. Durante su vigencia, la clave reside en la memoria para el cifrado y el descifrado, y se almacena cifrada en el disco.
Para habilitar el cifrado de disco local, debe usar la API de clústeres. Durante la creación o edición del cálculo, establezca enable_local_disk_encryption en true.
Configuración de Spark
Para ajustar los trabajos de Spark, proporcione propiedades de configuración de Spark personalizadas.
En la página de configuración del proceso, haga clic en el botón de alternancia Avanzado.
Haga clic en la pestaña Spark.
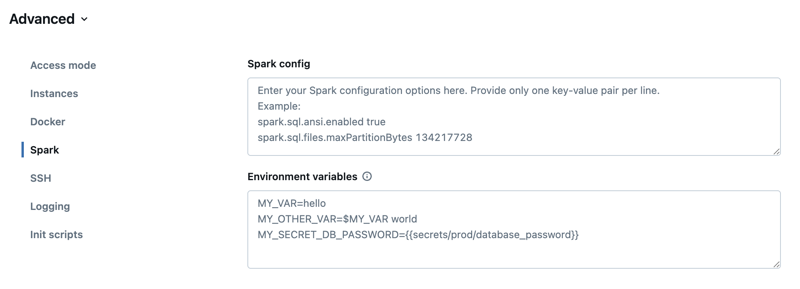
En Configuración de Spark, escriba las propiedades de configuración como un par clave-valor por línea.
Cuando configure procesos mediante la API de clústeres, establezca las propiedades de Spark en el campo spark_conf de Crear API del clúster o Actualizar la API del clúster.
Para hacer cumplir las configuraciones de Spark en procesos, los administradores del área de trabajo pueden usar directivas de proceso.
Recuperar una propiedad de configuración de Spark desde un secreto
Databricks recomienda almacenar información confidencial, como contraseñas, en un secreto en lugar de almacenarla como texto no cifrado. Para hacer referencia a un secreto en la configuración de Spark, use la sintaxis siguiente:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Por ejemplo, para establecer una propiedad de configuración de Spark llamada password en el valor del secreto almacenado en secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Para obtener más información, consulte Administración de secretos.
Entrega de registros de proceso
Cuando crea computación de propósito general o para trabajos, puede especificar una ubicación para los registros del clúster, incluidos los registros del controlador de Spark, los nodos de trabajo y los eventos. Los registros se entregan cada cinco minutos y se archivan cada hora en el destino seleccionado. Databricks continúa entregando registros hasta que finaliza el recurso de proceso.
Puede almacenar registros en una de las siguientes ubicaciones:
- Volúmenes (recomendados): Almacena los registros en una ruta de volumen del Catálogo de Unity. Esta es la opción recomendada y más segura al usar los recursos de proceso habilitados para el catálogo de Unity.
- DBFS (heredado): almacena los logs en la ruta del sistema de archivos de Databricks (DBFS). Esta opción solo está disponible si la raíz y los puntos de montaje de DBFS no están deshabilitados en el área de trabajo. Consulte Deshabilitar el acceso a la raíz de DBFS y montajes en su espacio de trabajo de Azure Databricks existente.
Para configurar la ubicación de entrega del registro:
- En la página de proceso, haga clic en el botón de alternancia Avanzado.
- Haga clic en la pestaña Registro.
- Seleccione un tipo de destino.
- Escriba la ruta de acceso del registro.
Para almacenar los registros, Databricks crea una subcarpeta en la ruta de acceso de registro elegida denominada después de la cluster_iddel proceso.
Por ejemplo, si la ruta de acceso del registro especificada es /Volumes/catalog/schema/volume, los registros de 06308418893214 se entregan a /Volumes/catalog/schema/volume/06308418893214.
Nota:
La entrega de registros a un volumen solo se admite en la computación habilitada para el catálogo de Unity con el modo de acceso estándar o el modo de acceso dedicado asignado a un usuario. No se admite el modo de acceso dedicado asignado a un grupo. Si selecciona un volumen como ruta de acceso, verifique que el propietario del recurso de computación o el usuario asignado a él tiene los permisos READ VOLUME y WRITE VOLUME en el volumen. Consulte Privilegios para volúmenes del catálogo de Unity.
Acceso SSH a los recursos de cómputo
Por motivos de seguridad, en Azure Databricks el puerto SSH está cerrado de forma predeterminada. Si desea habilitar el acceso SSH a los clústeres de Spark, consulte SSH al nodo del controlador.
Nota:
SSH solo se puede habilitar si el área de trabajo se implementa en su propia red virtual Azure.
Variables de entorno
Configura variables de entorno personalizadas a las que puedas acceder desde scripts de inicio que se ejecutan en el recurso de computación. Databricks también ofrece variables de entorno predefinidas que se pueden usar en los scripts de inicialización. No puede invalidar estas variables de entorno predefinidas.
En la página de configuración de computación, haga clic en Avanzado.
Haga clic en la pestaña Spark.
Establezca las variables de entorno en el campo Variables de entorno .

También es posible establecer variables de entorno mediante el campo spark_env_vars de la API de creación de clústeres o la API de actualización de clústeres.