Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo leer y escribir en tablas de Google BigQuery en Azure Databricks.
Importante
La documentación de federación de consultas heredada ha quedado obsoleta y ya no se actualizará. Las configuraciones mencionadas en este contenido no están aprobadas o probadas oficialmente por Databricks. Si Lakehouse Federation admite la base de datos de origen, Databricks recomienda usarlo en su lugar.
Debe conectarse a BigQuery mediante la autenticación basada en claves.
Permisos
Los proyectos deben tener permisos específicos de Google para leer y escribir mediante BigQuery.
Nota:
En este artículo se describen las vistas materializadas de BigQuery. Para obtener más información, consulte el artículo de Google Introduction to materialized views (Introducción a las vistas materializadas). Para obtener información sobre otras terminologías de BigQuery y el modelo de seguridad de BigQuery, consulte la documentación de Google BigQuery.
La lectura y escritura de datos con BigQuery depende de dos proyectos de Google Cloud:
- Project (
project): el identificador del proyecto de Google Cloud desde el que Azure Databricks lee o escribe la tabla BigQuery. - Proyecto principal (
parentProject): el identificador del proyecto principal, que es el identificador de proyecto de Google Cloud para facturar al leer y escribir. Establézcalo en el proyecto de Google Cloud asociado a la cuenta de servicio de Google para la que generará claves.
Debe proporcionar explícitamente los valores project y parentProject en el código que accede a BigQuery. Use código similar al siguiente:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Los permisos necesarios para los proyectos de Google Cloud dependen de si project y parentProject son los mismos. En las secciones siguientes se enumeran los permisos necesarios para cada escenario.
Permisos necesarios si project y parentProject coinciden
Si los identificadores de project y parentProject son los mismos, use la tabla siguiente para determinar los permisos mínimos:
| Tarea de Azure Databricks | Permisos de Google necesarios en el proyecto |
|---|---|
| Leer una tabla BigQuery sin vista materializada | En el proyecto project.
|
| Leer una tabla BigQuery con vista materializada | En el proyecto project.
En el proyecto de materialización:
|
| Escribir una tabla de BigQuery | En el proyecto project.
|
Permisos necesarios si project y parentProject son diferentes
Si los identificadores de project y parentProject son diferentes, use la tabla siguiente para determinar los permisos mínimos:
| Tarea de Azure Databricks | Permisos de Google necesarios |
|---|---|
| Leer una tabla BigQuery sin vista materializada | En el proyecto parentProject.
En el proyecto project.
|
| Leer una tabla BigQuery con vista materializada | En el proyecto parentProject.
En el proyecto project.
En el proyecto de materialización:
|
| Escribir una tabla de BigQuery | En el proyecto parentProject.
En el proyecto project.
|
Paso 1: Configuración de Google Cloud
Habilitación de bigQuery Storage API
La API de Almacenamiento de BigQuery está habilitada de forma predeterminada en los nuevos proyectos de Google Cloud en los que bigQuery está habilitado. Sin embargo, si tiene un proyecto existente y la API de Almacenamiento bigQuery no está habilitado, siga los pasos descritos en esta sección para habilitarlo.
Puede habilitar bigQuery Storage API mediante la CLI de Google Cloud o google Cloud Console.
Habilitación de la API de Almacenamiento de BigQuery mediante la CLI de Google Cloud
gcloud services enable bigquerystorage.googleapis.com
Habilitación de la API de BigQuery Storage mediante Google Cloud Console
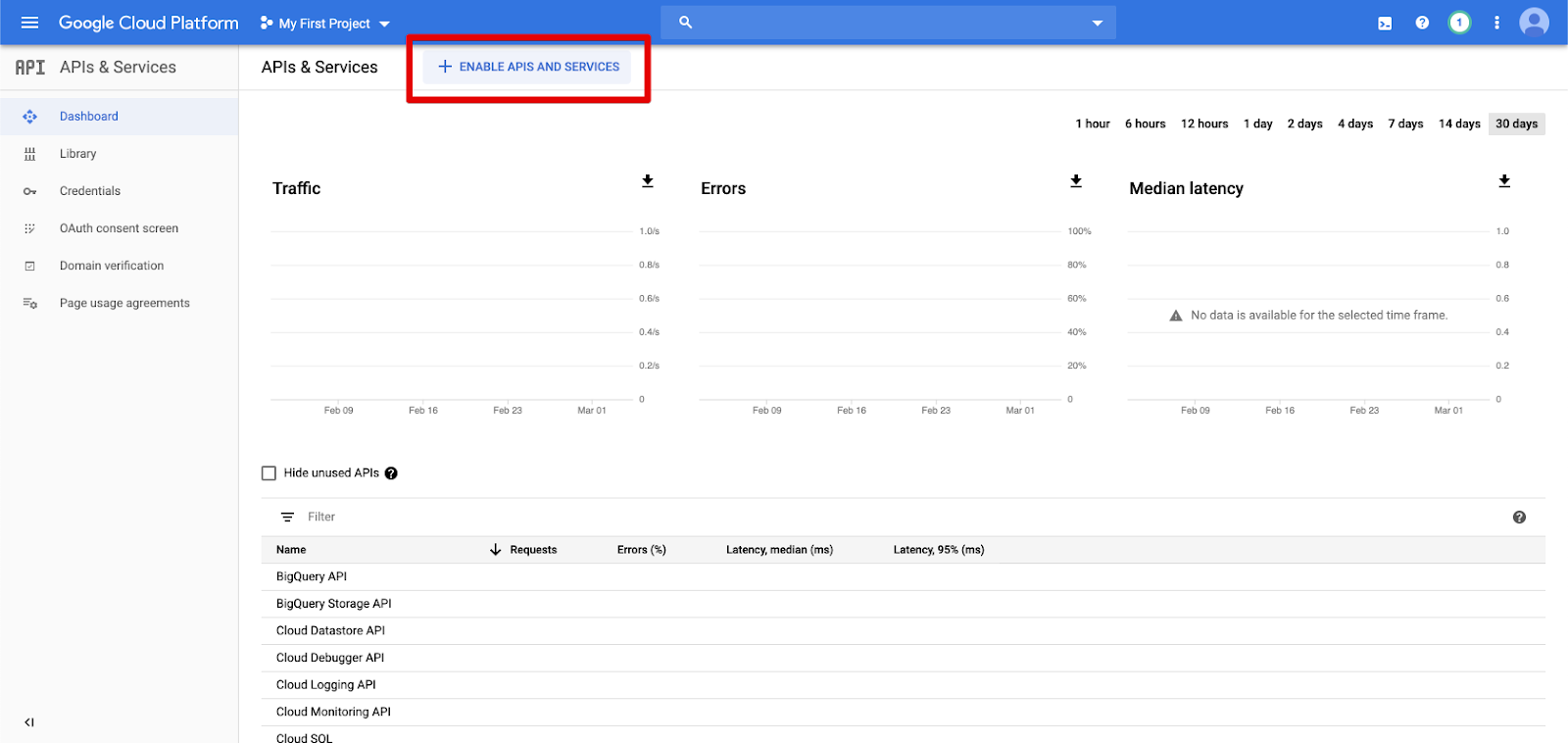
Haga clic en API y servicios en el panel de navegación izquierdo.
Haga clic en el botón ENABLE APIS AND SERVICES (HABILITAR API Y SERVICIOS ).
Escriba
bigquery storage apila barra de búsqueda y seleccione el primer resultado.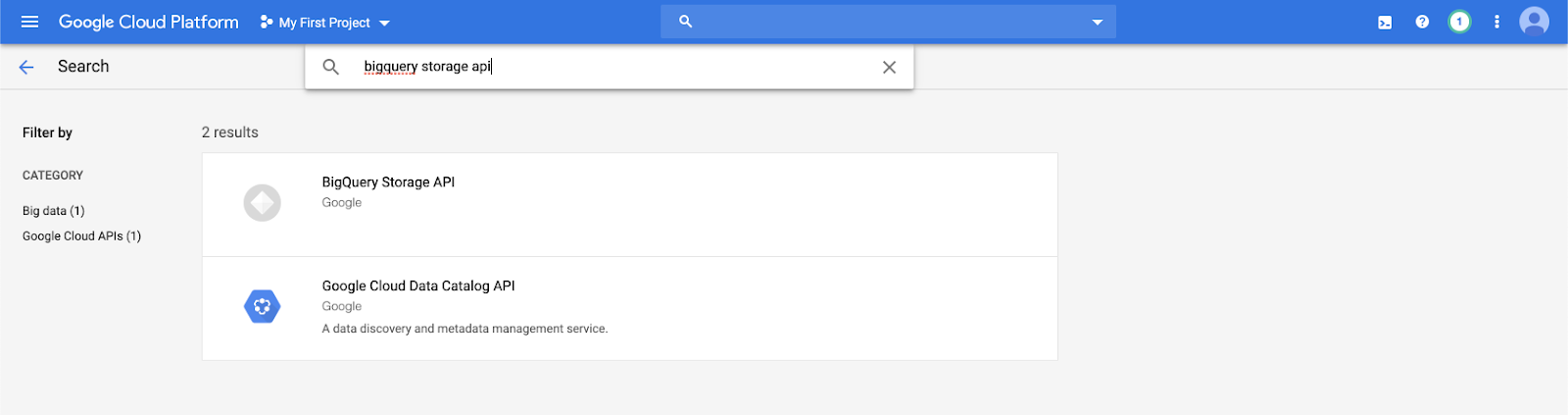
Asegúrese de que la API de Almacenamiento de BigQuery esté habilitada.
Creación de una cuenta de servicio de Google para Azure Databricks
Cree una cuenta de servicio para el clúster de Azure Databricks. Databricks recomienda proporcionar a esta cuenta de servicio los privilegios mínimos necesarios para realizar sus tareas. Consulte Roles y permisos de BigQuery.
Puede crear una cuenta de servicio mediante la CLI de Google Cloud o google Cloud Console.
Creación de una cuenta de servicio de Google mediante la CLI de Google Cloud
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Cree las claves de la cuenta de servicio:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Creación de una cuenta de servicio de Google mediante Google Cloud Console
Para crear la cuenta:
Haga clic en IAM y Administrador en el panel de navegación izquierdo.
Haga clic en Cuentas de servicio.
Haga clic en + CREAR CUENTA DE SERVICIO.
Escriba el nombre y la descripción de la cuenta de servicio.
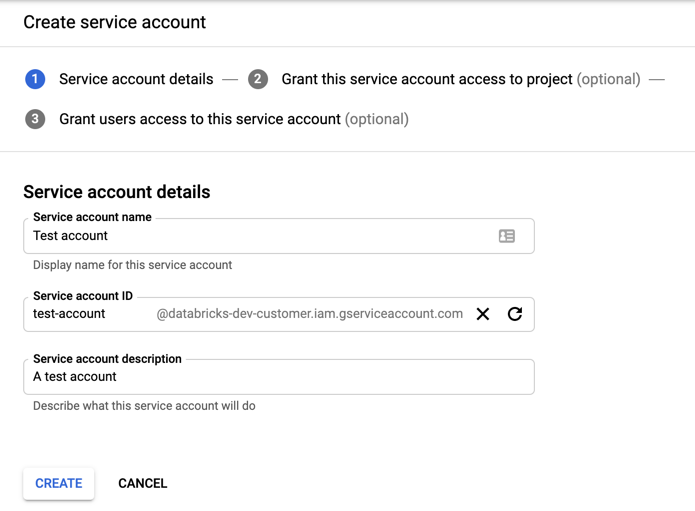
Haga clic en CREATE (Crear).
Especifique los roles de la cuenta de servicio. En la lista desplegable Seleccionar un rol , escriba
BigQueryy agregue los siguientes roles: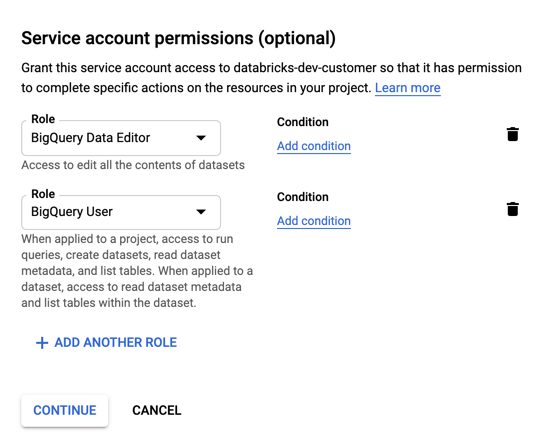
Haga clic en CONTINUE (Continuar).
Haga clic en LISTO.
Para crear claves para la cuenta de servicio:
En la lista de cuentas de servicio, haga clic en la cuenta recién creada.
En la sección Claves, seleccione el botón AGREGAR CLAVE > Crear nueva clave .
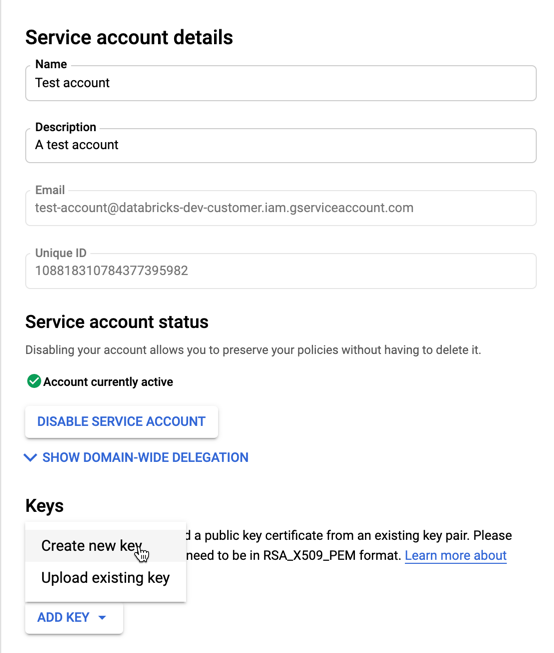
Acepte el tipo de clave JSON .
Haga clic en CREATE (Crear). El archivo de clave JSON se descarga en el equipo.
Importante
El archivo de clave JSON que genera para la cuenta de servicio es una clave privada que solo se debe compartir con usuarios autorizados, ya que controla el acceso a conjuntos de datos y recursos de la cuenta de Google Cloud.
Creación de un cubo de Google Cloud Storage (GCS) para el almacenamiento temporal
Para escribir datos en BigQuery, el origen de datos necesita acceso a un cubo de GCS.
Haga clic en Almacenamiento en el panel de navegación izquierdo.
Haga clic en CREAR BUCKET.
Configure los detalles del cubo.
Haga clic en CREATE (Crear).
Haga clic en la pestaña Permisos y agregar miembros.
Proporcione los permisos siguientes a la cuenta de servicio en el cubo.
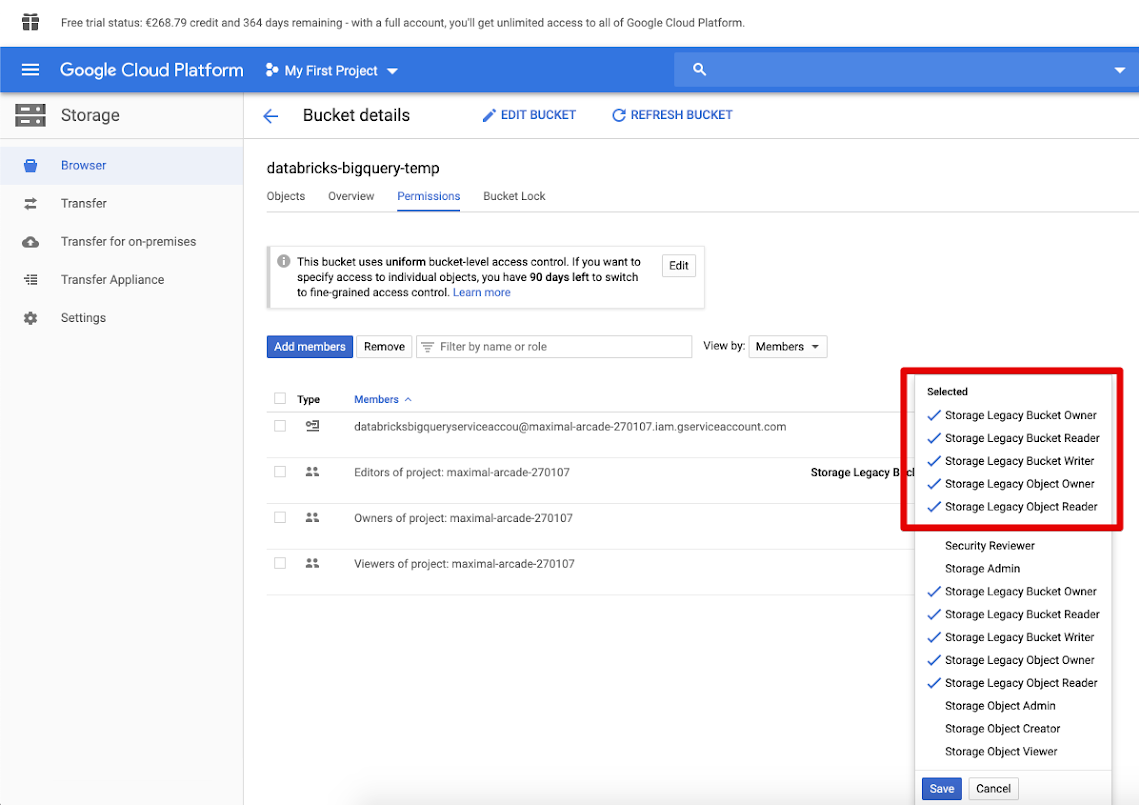
Haga clic en Guardar.
Paso 2: Configuración de Azure Databricks
Para configurar un clúster para acceder a las tablas de BigQuery, debe proporcionar el archivo de clave JSON como una configuración de Spark. Use una herramienta local para codificar en Base64 el archivo de clave JSON. Con fines de seguridad no se usa una herramienta remota o basada en web que pueda acceder a las claves.
En la pestaña Configuración de Spark , agregue la siguiente configuración de Spark. Reemplace por <base64-keys> la cadena del archivo de clave JSON codificado en Base64. Reemplace los demás elementos entre corchetes (como <client-email>) por los valores de esos campos del archivo de clave JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Lectura y escritura en una tabla BigQuery
Para leer una tabla BigQuery, especifique
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Para escribir en una tabla BigQuery, especifique
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
donde <bucket-name> es el nombre del cubo que creó en Creación de un cubo de Google Cloud Storage (GCS) para el almacenamiento temporal. Consulte Permisos para obtener información sobre los requisitos para los valores de <project-id> y <parent-id>.
Creación de una tabla externa desde BigQuery
Importante
Este catálogo de Unity no admite esta característica.
Puede declarar una tabla no administrada en Databricks que leerá datos directamente desde BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Ejemplo de cuaderno de Python: Carga de una tabla de Google BigQuery en un dataFrame
El siguiente cuaderno de Python carga una tabla de Google BigQuery en un DataFrame de Azure Databricks.
Cuaderno de ejemplo de Python de Google BigQuery
Ejemplo de cuaderno de Scala: Carga de una tabla de Google BigQuery en un DataFrame
El siguiente notebook de Scala carga una tabla de Google BigQuery en un DataFrame de Azure Databricks.