Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La evolución del esquema hace referencia a la capacidad de un sistema de adaptarse a los cambios en la estructura de los datos a lo largo del tiempo. Estos cambios son comunes al trabajar con datos semiestructurados, flujos de eventos o orígenes de terceros en los que se agregan nuevos campos, los tipos de datos cambian o evolucionan las estructuras anidadas.
Entre los cambios comunes se incluyen:
- Nuevas columnas: campos adicionales no definidos anteriormente, a veces con un valor de reposición personalizado.
-
Cambio de nombre de columna: cambio de un nombre de columna, por ejemplo, de
nameafull_name. - Columnas quitadas: quitar columnas del esquema de tabla.
-
Ampliación de tipos: cambiar el tipo de una columna a uno más amplio. Por ejemplo, un
INTcampo que se convierte enDOUBLE. -
Otros cambios de tipo: cambiar el tipo de una columna. Por ejemplo, un
INTcampo que se convierte enSTRING.
La compatibilidad con la evolución del esquema es fundamental para crear canalizaciones resistentes y de larga duración que puedan acomodar el cambio de datos sin actualizaciones manuales frecuentes.
Components
La evolución del esquema de Azure Databricks implica cuatro categorías de componentes principales, cada una de las cuales controla los cambios de esquema de forma independiente:
- Conectores: componentes que ingieren datos de orígenes externos. Entre ellos se incluyen los conectores Auto Loader, Kafka, Kinesis y Lakeflow.
-
Analizadores de formato: funciones que descodifican formatos sin formato, incluidos
from_json,from_avro,from_xmlyfrom_protobuf. - Motores: motores de procesamiento que ejecutan consultas, incluido Structured Streaming.
- Conjuntos de datos: tablas de streaming, vistas materializadas, tablas delta y vistas que conservan y sirven datos.
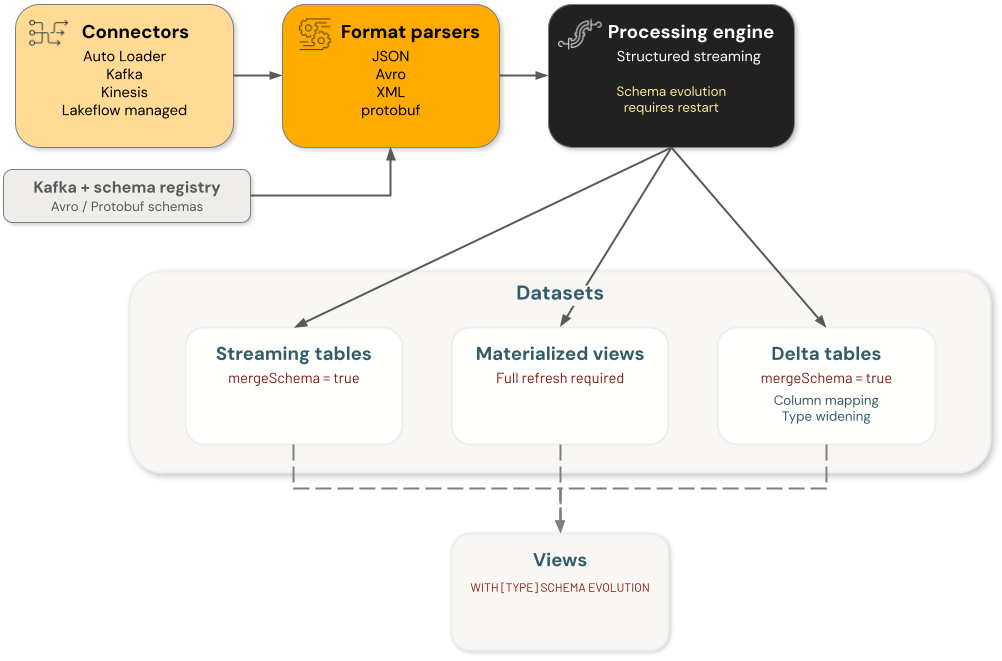
Cada componente de la evolución del esquema de la arquitectura de ingeniería de datos es independiente. Es responsable de configurar la evolución del esquema en componentes individuales para lograr el comportamiento deseado en el flujo de procesamiento de datos.
Por ejemplo, cuando se usa Auto Loader para ingerir datos en una tabla Delta, hay dos esquemas persistentes: uno se administra mediante Auto Loader en su ubicación de esquema y el otro es el esquema de la tabla Delta de destino. En un estado estable, esos dos son los mismos. Cuando Auto Loader evoluciona su esquema, en función de los datos entrantes, la tabla Delta también debe evolucionar su esquema o se produce un error en la consulta. En ese caso, puede (a) actualizar el esquema de tabla Delta de destino habilitando la evolución del esquema o usando un comando DDL directo, o (b) realizar una reescritura completa de la tabla Delta de destino.
Compatibilidad con la evolución del esquema mediante el conector
En las secciones siguientes se detalla cómo cada componente de Azure Databricks controla los distintos tipos de cambios de esquema.
Cargador automático
Auto Loader admite cambios de columna, pero no cambios de tipo. Configure la evolución automática del esquema con cloudFiles.schemaEvolutionMode y rescuedDataColumn. Puede configurar manualmente schemaHints o un schema inmutable. Al evolucionar el esquema automáticamente, la secuencia inicialmente falla. Al reiniciar, se usa el esquema evolucionado. Consulte ¿Cómo funciona la evolución del esquema del cargador automático?.
-
Nuevas columnas: admitidas, en función de la
schemaEvolutionModeseleccionada. Se produce un error con un reinicio manual necesario para agregar nuevas columnas al esquema. -
Cambio de nombre de columna: se admite, en función del
schemaEvolutionModeseleccionado. La columna cuyo nombre se ha cambiado se trata como una nueva columna agregada y la columna anterior se rellena conNULLpara las nuevas filas. Se produce un error con un reinicio manual necesario para actualizar el esquema. -
Columnas eliminadas: Soportadas. Se trata como eliminaciones parciales, donde las nuevas filas de la columna eliminada se establecen en
NULL. -
Ampliación de tipos: no se admite. Los cambios de tipo se capturan en
rescuedDataColumnsirescueDataColumnse ha establecido yschemaEvolutionModese ha configurado enrescue. De lo contrario, requiere un cambio de esquema manual. -
Otros cambios de tipo: no compatibles. Los cambios de tipo se capturan en
rescuedDataColumnsirescueDataColumnse ha establecido yschemaEvolutionModese ha configurado enrescue. De lo contrario, requiere un cambio de esquema manual.
Conector delta
El conector Delta puede admitir la evolución del esquema. Si lee desde una tabla Delta con asignación de columnas y schemaTrackingLocation habilitada, admite la evolución del esquema para renombrar y quitar columnas. Debe establecer la configuración correcta de Spark para cada uno de esos cambios respectivos para evolucionar el esquema sin detener la secuencia. De lo contrario, la secuencia evoluciona su esquema de seguimiento cada vez que se detecta un cambio y, a continuación, se detiene. A continuación, debe reiniciar manualmente la consulta de streaming para reanudar el procesamiento.
-
Nuevas columnas: son compatibles. Con
mergeSchemahabilitado, las nuevas columnas se agregan automáticamente. De lo contrario, se produce un error en la consulta y debe reiniciar la secuencia para agregar las nuevas columnas al esquema, pero la tabla Delta no requiere una reescritura. -
Cambio de nombre de columna: compatible. Con
mergeSchemahabilitado, el cambio de nombre se controla automáticamente. De lo contrario, puede evolucionar el esquema dentro de una consulta de streaming con la configuración de Sparkspark.databricks.delta.streaming.allowSourceColumnRename. -
Columnas eliminadas: Soportadas. Con
mergeSchemahabilitado, las columnas quitadas se gestionan automáticamente. De lo contrario, puede evolucionar el esquema dentro de una consulta en streaming con la configuración de Sparkspark.databricks.delta.streaming.allowSourceColumnDrop. -
Ampliación de tipos: compatible con Databricks Runtime 16.4 LTS y versiones posteriores. Con
mergeSchemahabilitado y la ampliación de tipos habilitada en la tabla de destino, los cambios de tipo se controlan automáticamente. Puede habilitar la ampliación de tipo con la propiedad de tablatype widening. - Otros cambios de tipo: no compatibles.
Conectores SaaS y CDC
Los conectores SaaS y CDC evolucionan automáticamente el esquema cuando cambian las columnas. Esto se controla mediante un reinicio automático cuando se detecta un cambio. Los cambios de tipo requieren una actualización completa.
- Nuevas columnas: son compatibles. La consulta se reinicia automáticamente para resolver el error de coincidencia de esquema.
- Cambio de nombre de columna: compatible. La consulta se reinicia automáticamente para resolver el error de coincidencia de esquema. La columna cuyo nombre se ha cambiado se trata como una nueva columna agregada.
-
Columnas eliminadas: Soportadas. Las columnas quitadas se tratan como eliminaciones parciales, donde las nuevas filas de la columna eliminada se establecen en
NULL. - Ampliación de tipos: no se admite. La actualización del esquema requiere una actualización completa.
- Otros cambios de tipo: no compatibles. La actualización del esquema requiere una actualización completa.
Conectores Kinesis, Kafka, Pub/Sub y Pulsar
No se admite ninguna evolución de esquema nativa. Cada una de las funciones del conector devuelve un blob binario. La evolución del esquema se controla mediante el analizador de formato.
- Nuevas columnas: controladas por el analizador de formato.
- Cambio de nombre de columna: controlado por el analizador de formato.
- Columnas quitadas: controladas por el analizador de formato.
- Tipo de ampliación: controlado por el analizador de formato.
- Otros cambios de tipo: controlado por el analizador de formato.
Compatibilidad con la evolución del esquema por analizador de formato
from_json Analizador
El from_json analizador no admite la evolución del esquema. Debe actualizar el esquema manualmente. Cuando se usa from_json en canalizaciones declarativas de Spark de Lakeflow, la evolución automática del esquema se puede habilitar con schemaLocationKey y schemaEvolutionMode.
- Nuevas columnas: cuando se habilita la evolución automática del esquema, se comporta como Auto Loader.
- Cambio de nombre de columnas: cuando se habilita la evolución automática del esquema, se comporta como Auto Loader.
- Columnas eliminadas: cuando se habilita la evolución automática del esquema, se comporta como Auto Loader.
- Ampliación de tipos: cuando se habilita la evolución automática del esquema, se comporta como Auto Loader.
- Otros cambios de tipo: cuando la evolución automática del esquema está habilitada, se comporta como Auto Loader.
from_avro y from_protobuf analizadores
Los analizadores from_avro y from_protobuf se comportan del mismo modo. El esquema se puede capturar desde el Registro de esquemas de Confluent, o el usuario puede proporcionar un esquema y debe actualizar el esquema manualmente. No hay ningún concepto de evolución del esquema dentro de la from_avro función o from_protobuf ; el motor de ejecución y el Registro de esquemas deben controlarlo.
- Nuevas columnas: compatible con el Registro de esquemas de Confluent. De lo contrario, el usuario debe actualizar el esquema manualmente.
- Cambio de nombre de columna: compatible con el Registro de esquemas de Confluent. De lo contrario, el usuario debe actualizar el esquema manualmente.
- Columnas eliminadas: compatible con el Registro de esquemas de Confluent. De lo contrario, el usuario debe actualizar el esquema manualmente.
- Ampliación de tipos: compatible con el Registro de esquemas de Confluent. De lo contrario, el usuario debe actualizar el esquema manualmente.
- Otros cambios de tipo: compatible con el Confluent Schema Registry. De lo contrario, el usuario debe actualizar el esquema manualmente.
from_csv y from_xml analizadores
Los analizadores from_csv y from_xml no admiten la evolución del esquema.
- Nuevas columnas: no compatibles
- Cambio de nombre de columna: no compatible
- Columnas quitadas: no compatibles
- Ampliación de tipos: no compatible
- Otros cambios de tipo: no compatibles
Compatibilidad con la evolución del esquema mediante el motor
Transmisión Estructurada
El esquema de una consulta de streaming está bloqueado durante la fase de planeación y todos los microprocesos reutilizan ese plan sin volver a planearlo. Si el esquema de origen cambia a mitad de ejecución, se produce un error en la consulta y el usuario debe reiniciar la consulta de streaming para que Spark pueda volver a planear el nuevo esquema.
El conjunto de datos en el que escribe el flujo también debe admitir la evolución del esquema.
- Nuevas columnas: son compatibles. Se produce un error en la consulta y debe reiniciar la secuencia para resolver la falta de coincidencia del esquema.
- Cambio de nombre de columna: compatible. Se produce un error en la consulta y debe reiniciar la secuencia para resolver la falta de coincidencia del esquema.
- Columnas eliminadas: Soportadas. Se produce un error en la consulta y debe reiniciar la secuencia para resolver la falta de coincidencia del esquema.
- Ampliación de tipos: está admitida. Se produce un error en la consulta y debe reiniciar la secuencia para resolver la falta de coincidencia del esquema.
- Otros cambios de tipo: compatibles. Se produce un error en la consulta y debe reiniciar la secuencia para resolver la falta de coincidencia del esquema.
Evolución del esquema por conjunto de datos
Tablas de streaming
Las tablas de streaming admiten el comportamiento de evolución del esquema de combinación de forma predeterminada. La actualización del esquema no requiere un reinicio manual, pero los cambios arbitrarios de esquema requieren una actualización completa.
- Nuevas columnas: son compatibles. La consulta se reinicia automáticamente para resolver el error de coincidencia del esquema.
- Cambio de nombre de columna: compatible. La consulta se reinicia para resolver el error de coincidencia del esquema. La columna cuyo nombre se ha cambiado se trata como una nueva columna agregada.
- Columnas eliminadas: Soportadas. Las columnas quitadas se tratan como eliminaciones parciales, donde las nuevas filas de la columna eliminada se establecen en NULL.
- Ampliación de tipos: está admitida. La ampliación de tipos debe habilitarse ya sea a nivel de la pipeline o directamente en la tabla. Consulte la ampliación de tipos en Canalizaciones declarativas de Lakeflow Spark.
- Otros cambios de tipo: no compatibles. La actualización del esquema requiere una actualización completa.
Vistas materializadas
Cualquier actualización del esquema o la consulta de definición desencadena una recompute completa de la vista materializada.
- Nuevas columnas: recomputación completa ejecutada.
- Cambio de nombre de columna: recomputación completa desencadenada.
- Columnas eliminadas: Recálculo completo desencadenado.
- Ampliación de tipos: La recomputación completa ha sido desencadenada.
- Otros cambios de tipo: se ha desencadenado una recomputación total.
Tablas delta
Las tablas delta admiten una variedad de configuraciones para actualizar el esquema de la tabla, como cambiar el nombre, quitar y ampliar el tipo de columnas sin volver a escribir los datos de la tabla. Entre las configuraciones admitidas se incluyen la evolución del esquema de combinación, la asignación de columnas, la ampliación de tipos y la sobrescritura del esquema.
- Nuevas columnas: son compatibles. Evoluciona automáticamente cuando se habilita la evolución del esquema de combinación, sin necesidad de volver a escribir una tabla Delta. Si la evolución del esquema de combinación no está habilitada, se producirá un error en las actualizaciones.
-
Cambio de nombre de columna: compatible. Puede cambiar el nombre a través de comandos manuales
ALTER TABLE DDLcon la asignación de columnas habilitada. No requiere una reescritura de tabla Delta. -
Columnas eliminadas: Soportadas. Es posible eliminar columnas mediante comandos manuales
ALTER TABLE DDLcuando la asignación de columnas está habilitada. No requiere una reescritura de tabla Delta. -
Ampliación de tipos: está admitida. Aplica automáticamente el cambio de tipo cuando están habilitadas la ampliación del tipo y la evolución del esquema de combinación. Puede ampliar las columnas a través de comandos manuales
ALTER TABLE DDLcuando se habilita la ampliación de tipos. Sin que ninguno de los dos esté configurado, las operaciones fallan. Consulte Tipos anchos con evolución automática del esquema. -
Otros cambios de tipo: compatible, pero requiere una reescritura completa de la tabla Delta. Debe habilitar
overwriteSchema, que habilita una reescritura completa de la tabla delta. De lo contrario, se produce un error en las operaciones.
Views
Si la vista tiene un column_list que no coincide con el nuevo esquema o tiene una consulta que no se puede analizar, la vista deja de ser válida. Si no lo hace, puede habilitar la evolución del esquema para los cambios de tipo con SCHEMA TYPE EVOLUTION y para los cambios de tipo, así como las columnas nuevas, cambiadas de nombre y quitadas con SCHEMA EVOLUTION (que es un superconjunto de evolución de tipos).
-
Nuevas columnas: son compatibles. Con
SCHEMA EVOLUTIONel modo , la vista evoluciona automáticamente sin intervención manual si no hay ningún elemento explícitocolumn_list. De lo contrario, la vista puede dejar de ser válida y el usuario no puede consultarla. -
Cambio de nombre de columnas: compatible. Con
SCHEMA EVOLUTIONel modo , la vista evoluciona automáticamente sin intervención manual si no hay ningún elemento explícitocolumn_list. De lo contrario, la vista puede dejar de ser válida. -
Columnas eliminadas: Soportadas. Con
SCHEMA EVOLUTIONel modo , la vista evoluciona automáticamente sin intervención manual si no hay ningún elemento explícitocolumn_list. De lo contrario, la vista puede dejar de ser válida. -
Ampliación de tipos: está admitida. Con el modo
SCHEMA TYPE EVOLUTION, la vista se evoluciona automáticamente ante cualquier cambio de tipo. ConSCHEMA EVOLUTIONel modo , la vista evoluciona automáticamente sin intervención manual si no hay ningún elemento explícitocolumn_list. De lo contrario, la vista puede dejar de ser válida. -
Otros cambios de tipo: compatibles. Con el modo
SCHEMA TYPE EVOLUTION, la vista se evoluciona automáticamente ante cualquier cambio de tipo. ConSCHEMA EVOLUTIONel modo , la vista evoluciona automáticamente sin intervención manual si no hay ningún elemento explícitocolumn_list. De lo contrario, la vista puede dejar de ser válida.
Example
En el ejemplo siguiente se muestra cómo ingerir un tema de Kafka con cargas codificadas en Avro registradas en el Registro de esquemas de Confluent y escribirlas en una tabla Delta administrada con la evolución del esquema habilitada.
Puntos clave ilustrados:
- Integración con el conector de Kafka.
- Descodificar registros de Avro mediante from_avro con un registro de esquema de Kafka.
- Controle la evolución del esquema estableciendo
avroSchemaEvolutionMode. - Escriba en una tabla Delta con
mergeSchemahabilitada para permitir cambios aditivos.
El código asume que tiene un tópico de Kafka utilizando el registro de esquemas de Confluent y genera datos codificados en Avro.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)