Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Databricks Connect para Databricks Runtime 12.2 LTS y versiones anteriores está en desuso. Databricks Runtime 12.2 LTS y todas las versiones anteriores de LTS han llegado al final del soporte técnico. Use Databricks Connect para Databricks Runtime 13.3 LTS y versiones posteriores en su lugar. Para obtener información sobre la migración desde Databricks Connect para Databricks Runtime 12.2 LTS y versiones posteriores a Databricks Connect para Databricks Runtime 13.3 LTS y versiones posteriores, consulte Migración a Databricks Connect para Python o Migración a Databricks Connect para Scala.
Databricks Connect permite conectar a clústeres de Azure Databricks entornos de desarrollo integrado populares, como Visual Studio Code y PyCharm, servidores de cuadernos y otras aplicaciones personalizadas.
En este artículo, se explica el funcionamiento de Databricks Connect, los pasos para empezar a utilizarlo, cómo solucionar los problemas que puedan surgir al usarlo y las diferencias entre la ejecución con Databricks Connect y la ejecución en un cuaderno de Azure Databricks.
Información general
Databricks Connect es una biblioteca cliente para Databricks Runtime. Permite escribir trabajos mediante las API de Spark y ejecutarlos de manera remota en un clúster de Azure Databricks en lugar de hacerlo en la sesión local de Spark.
Por ejemplo, al ejecutar el comando DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() mediante Databricks Connect, la representación lógica del comando se envía al servidor Spark que se ejecuta en Azure Databricks para su ejecución en el clúster remoto.
Con Databricks Connect, puede:
- Ejecutar trabajos de Spark a gran escala desde cualquier aplicación de Python, R, Scale o Java. En cualquier lugar donde pueda ejecutar
import pyspark,require(SparkR)oimport org.apache.spark, ahora puede ejecutar trabajos de Spark directamente desde la aplicación sin necesidad de instalar ningún complemento de IDE ni utilizar scripts de envío de Spark. - Realiza pasos y depura código en tu IDE incluso cuando trabajes con un clúster remoto.
- Iterar rápidamente al crear bibliotecas. No es necesario reiniciar el clúster después de cambiar las dependencias de biblioteca de Python o Java en Databricks Connect, porque las sesiones de cliente están aisladas entre sí en el clúster.
- Apagar los clústeres inactivos sin perder el trabajo realizado. Como la aplicación cliente está desacoplada del clúster, no se ve afectada al reiniciar o actualizar el clúster, lo que normalmente provocaría la pérdida de todas las variables, RDD y objetos DataFrame definidos en un cuaderno.
Nota:
Para el desarrollo de Python con consultas SQL, Databricks recomienda utilizar Databricks SQL Connector para Python en lugar de Databricks Connect. El conector SQL para Python de Databricks es más fácil de configurar que Databricks Connect. Además, Databricks Connect analiza y planea las ejecuciones de trabajos en la máquina local, mientras que los trabajos se ejecutan en recursos de proceso remotos. Esto puede dificultar especialmente la depuración de errores en tiempo de ejecución. Databricks SQL Connector para Python envía consultas SQL directamente a recursos de proceso remotos y captura los resultados.
Requisitos
En esta sección se enumeran los requisitos de Databricks Connect.
Solo se admiten las versiones de Databricks Runtime siguientes:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Debe instalar Python 3 en la máquina de desarrollo y la versión secundaria de la instalación de Python del cliente debe ser la misma que la versión secundaria de Python del clúster de Azure Databricks. En la tabla siguiente se muestra la versión de Python instalada con cada versión de Databricks Runtime.
Versión de Databricks Runtime Versión de Python 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7.3 LTS 3.7 Databricks recomienda que tenga un entorno virtual de Python activado para cada versión de Python que use con Databricks Connect. Los entornos virtuales de Python ayudan a garantizar que usa las versiones correctas de Python y Databricks Connect juntas. Esto puede ayudar a reducir el tiempo que se tarda en resolver problemas técnicos relacionados.
Por ejemplo, si usa venv en el equipo de desarrollo y el clúster ejecuta Python 3.9, debe crear un
venventorno con esa versión. El siguiente comando de ejemplo genera los scripts para activar unvenventorno con Python 3.9 y, a continuación, este comando coloca esos scripts en una carpeta oculta denominada.venvdentro del directorio de trabajo actual:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvPara activar este
venventorno con estos scripts, consulte Funcionamiento de venvs.Como otro ejemplo, si usa Conda en el equipo de desarrollo y el clúster ejecuta Python 3.9, debe crear un entorno de Conda con esa versión, por ejemplo:
conda create --name dbconnect python=3.9Para activar el entorno de Conda con este nombre de entorno, ejecute
conda activate dbconnect.Las versiones principales y secundarias del paquete de Databricks Connect deben coincidir siempre con tu versión de Databricks Runtime. Databricks recomienda usar siempre el paquete más reciente de Databricks Connect que coincida con la versión de Databricks Runtime. Por ejemplo, si usa un clúster de Databricks Runtime 12.2 LTS, debe usar el paquete
databricks-connect==12.2.*.Nota:
Consulte las notas de la versión de Databricks Connect para una lista de las actualizaciones de mantenimiento y las versiones disponibles de Databricks Connect.
Java Runtime Environment (JRE) 8. El cliente se probó con el entorno OpenJDK 8 JRE. El cliente no admite Java 11.
Nota:
En Windows, si ve un error que Databricks Connect no encuentra winutils.exe, consulte No se encuentra winutils.exe en Windows.
Configurar el cliente
Complete los pasos siguientes para configurar el cliente local de Databricks Connect.
Nota:
Antes de empezar a configurar el cliente de Databricks Connect, debe cumplir con los requisitos de este.
Paso 1: Instale el cliente de Databricks Connect
Con el entorno virtual activado, desinstale PySpark, si ya está instalado, ejecutando el comando
uninstall. Esto es necesario porque el paquetedatabricks-connectentra en conflicto con PySpark. Para información detallada, consulte Instalaciones de PySpark en conflicto. Para comprobar si PySpark ya está instalado, ejecute el comandoshow.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkCon el entorno virtual aún activado, instale el cliente de Databricks Connect mediante la ejecución del comando
install. Use la opción--upgradepara actualizar cualquier instalación de cliente existente a la versión especificada.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Nota:
Databricks recomienda anexar la notación "dot-asterisk" para especificar
databricks-connect==X.Y.*en lugar dedatabricks-connect=X.Y, para asegurarse de que está instalado el paquete más reciente.
Paso 2: Configuración de las propiedades de conexión
Recopile las propiedades de configuración siguientes.
The Azure Databricks URL específica para cada área de trabajo. Se trata del mismo valor que
https://seguido del Nombre de host del servidor de su clúster. Consulte Obtener detalles de conexión para un recurso de proceso de Azure Databricks.Su token de acceso personal de Azure Databricks o token de Microsoft Entra ID (anteriormente Azure Active Directory).
- Para el acceso directo a credenciales de Azure Data Lake Storage (ADLS), debe usar un token de Microsoft Entra ID. El acceso directo a credenciales de Microsoft Entra ID solo se admite en clústeres Estándar que ejecutan Databricks Runtime 7.3 LTS y versiones posteriores, y no es compatible con la autenticación de la entidad de servicio.
- Para más información sobre la autenticación con tokens de Microsoft Entra ID, vea Autenticación mediante tokens de Microsoft Entra ID.
El ID de tu recurso de computación clásico. Puede obtener el identificador de computación clásica de la dirección URL. Aquí el identificador es
1108-201635-xxxxxxxx. Consulte también URL e ID de recursos de computación.
El identificador de organización único para el espacio de trabajo. Consulte Obtener identificadores para objetos del área de trabajo.
El puerto al que se conecta Databricks Connect en el clúster. El puerto predeterminado es
15001. Si el clúster está configurado para utilizar otro puerto, como8787que se indicó en instrucciones anteriores para Azure Databricks, utilice el número de puerto configurado.
Configure la conexión de la manera siguiente.
Puede usar la CLI, configuraciones de SQL o variables de entorno. La prioridad de los métodos de configuración es, de mayor a menor: claves de configuración de SQL, la CLI y variables de entorno.
Interfaz de línea de comandos (CLI)
Ejecute
databricks-connect.databricks-connect configureLa licencia muestra:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Acepte la licencia y suministre los valores de configuración. En Host de Databricks y Token de Databricks, escriba la dirección URL del área de trabajo y el token de acceso personal que anotó en el paso 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Si recibe un mensaje que indica que el token de Azure Microsoft Entra ID es demasiado largo, puede dejar vacío el campo Token de Databricks y escribir manualmente el token en
~/.databricks-connect.
Configuraciones de SQL o variables de entorno. En la tabla siguiente, se muestran las claves de configuración de SQL y las variables de entorno que corresponden a las propiedades de configuración que anotó en el paso 1. Para establecer una clave de configuración de SQL, utilice
sql("set config=value"). Por ejemplo:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parámetro Clave de configuración de SQL Nombre de la variable de entorno Host de Databricks spark.databricks.service.address DATABRICKS_DIRECCIÓN Token de Databricks spark.databricks.service.token DATABRICKS_API_TOKEN Identificador de clúster spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Identificador de la organización spark.databricks.service.orgId DATABRICKS_ORG_ID Puerto spark.databricks.service.port DATABRICKS_PORT
Con el entorno virtual aún activado, pruebe la conectividad con Azure Databricks como se indica a continuación.
databricks-connect testSi el clúster que configuró no está en ejecución, la prueba inicia el clúster, que se ejecutará hasta la hora de finalización automática configurada. La salida debe tener una apariencia similar a la siguiente:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiSi no se muestran errores relacionados con la conexión (los mensajes
WARNestán bien), se ha conectado correctamente.
Uso de Databricks Connect
En la sección, se describe cómo configurar el IDE o el servidor de cuadernos que prefiera para utilizar el cliente de Databricks Connect.
En esta sección:
- JupyterLab
- Jupyter Notebook clásico
- PyCharm
- SparkR y RStudio Desktop
- sparklyr y RStudio Desktop
- IntelliJ (Scala o Java)
- PyDev con Eclipse
- Eclipse
- SBT
- Shell de Spark
JupyterLab
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Si quiere usar Databricks Connect con JupyterLab y Python, siga estas instrucciones.
Para instalar JupyterLab, con el entorno virtual de Python activado, ejecute el siguiente comando desde el terminal o el símbolo del sistema:
pip3 install jupyterlabPara iniciar JupyterLab en el explorador web, ejecute el siguiente comando desde el entorno virtual de Python activado:
jupyter labSi JupyterLab no aparece en el explorador web, copie la dirección URL que comienza por
localhosto127.0.0.1desde su entorno virtual y escríbala en la barra de direcciones del explorador web.Crear un cuaderno nuevo: en el menú principal de JupyterLab, haga clic en Archivo > Nuevo > Cuaderno , seleccione Python 3 (ipykernel) y haga clic en Seleccionar.
En la primera celda del cuaderno, escriba el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe crear una instancia de
SparkSession.builder.getOrCreate(), como se muestra en el código de ejemplo.Para ejecutar el cuaderno, haga clic en Run > Run All Cells.
Para depurar el cuaderno, haga clic en el icono de error (Habilitar depurador) situado junto a Python 3 (ipykernel) en la barra de herramientas del cuaderno. Establezca uno o varios puntos de interrupción y, a continuación, haga clic en Run > Run All Cells.
Para apagar JupyterLab, haga clic en File > Shut Down. Si el proceso de JupyterLab todavía se está ejecutando en el terminal o en el símbolo del sistema, detenga este proceso presionando
Ctrl + cy después escribiendoypara confirmar.
Para obtener instrucciones de depuración más específicas, consulte Depurador.
Jupyter Notebook clásico
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
El script de configuración de Databricks Connect agrega el paquete a la configuración del proyecto automáticamente. Para empezar a trabajar en un kernel de Python, ejecute:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Si desea habilitar la abreviatura %sql para ejecutar y visualizar consultas SQL, utilice el fragmento de código siguiente:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect con Visual Studio Code, haga lo siguiente:
Compruebe que la extensión de Python está instalada.
Abra la paleta de comandos (Comando+Mayús+P en macOS y Ctrl+Mayús+P en Windows/Linux).
Seleccione un intérprete de Python. Vaya a Code (Código) > Preferences (Preferencias) > Settings (Configuración) y elija python settings (configuración de Python).
Ejecute
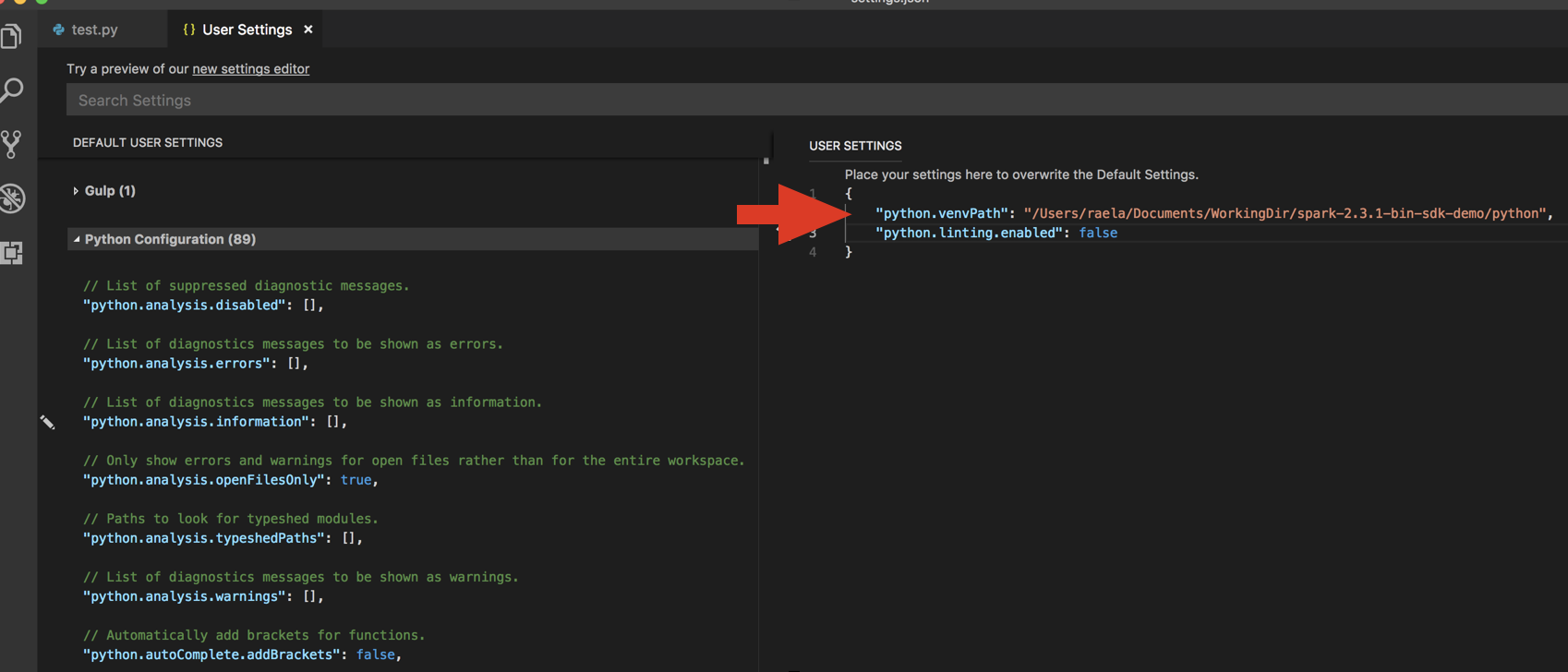
databricks-connect get-jar-dir.Agregue el directorio que el comando devolvió al JSON de configuración de usuario en
python.venvPath. Esto se debe agregar a la configuración de Python.Desactiva el linter. Haga clic en los puntos suspensivos … que se encuentran al lado derecho y edite la configuración de JSON. La configuración modificada es la siguiente:
Si utiliza un entorno virtual, que es el método recomendado de desarrollo para Python en VS Code, escriba
select python interpreteren la paleta de comandos y apunte al entorno que coincide con la versión de Python del clúster.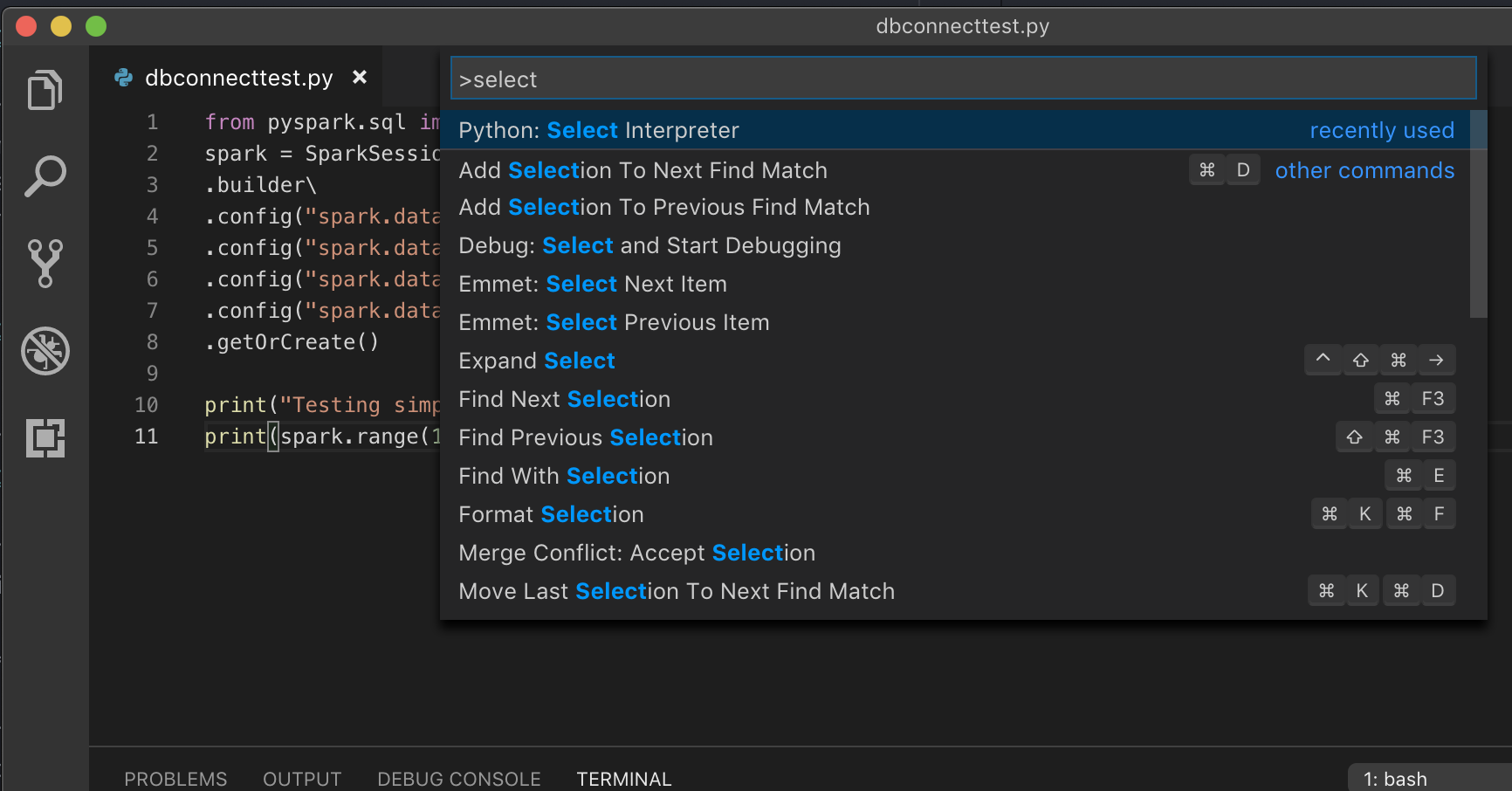
Por ejemplo, si el clúster es Python 3.9, el entorno de desarrollo debe ser Python 3.9.
PyCharm
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
El script de configuración de Databricks Connect agrega el paquete a la configuración del proyecto automáticamente.
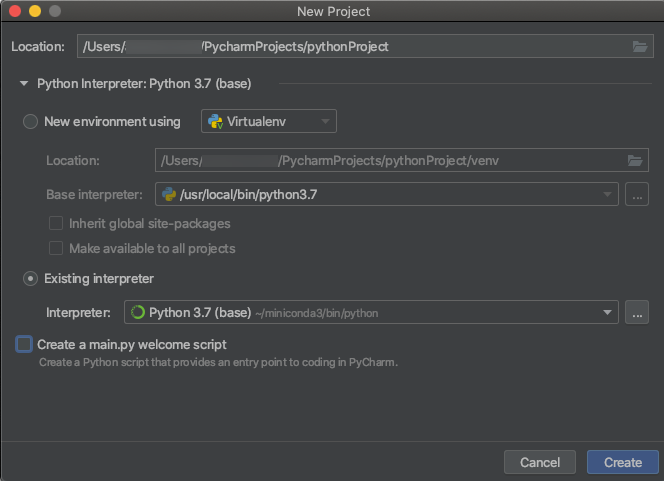
Clústeres de Python 3
Al crear un proyecto de PyCharm, seleccione Existing Interpreter (Intérprete existente). En el menú desplegable, seleccione el entorno de Conda que creó (consulte Requisitos).
Vaya a Ejecutar > Editar configuraciones.
Agregue
PYSPARK_PYTHON=python3como una variable de entorno.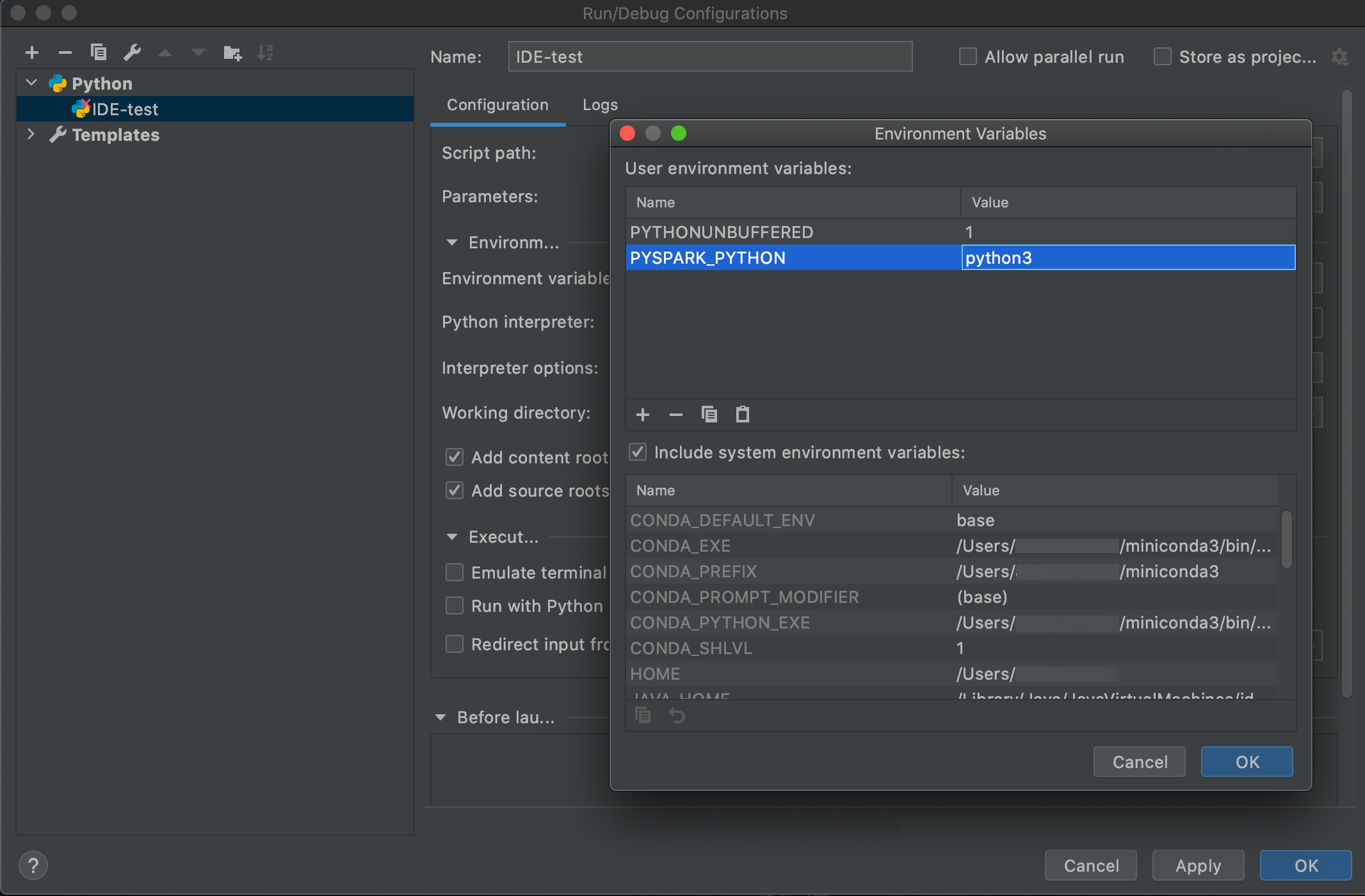
SparkR y RStudio Desktop
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect con SparkR y RStudio Desktop, haga lo siguiente:
Descargue y desempaquete la distribución del código abierto de Spark en la máquina de desarrollo. Elija la misma versión que en el clúster de Azure Databricks (Hadoop 2.7).
Ejecute
databricks-connect get-jar-dir. Este comando devuelve una ruta de acceso como/usr/local/lib/python3.5/dist-packages/pyspark/jars. Copie la ruta de archivo de un directorio por encima de la ruta de archivo del directorio JAR, como/usr/local/lib/python3.5/dist-packages/pyspark, que es el directorioSPARK_HOME.Configure la ruta de acceso de la biblioteca de Spark y la página principal de Spark agregándolos a la parte superior del script de R. Establezca
<spark-lib-path>en el directorio en el que desempaquetó el paquete de Spark de código abierto en el paso 1. Establezca<spark-home-path>en el directorio de Databricks Connect del paso 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Inicie una sesión de Spark y empiece a ejecutar comandos de SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr y RStudio Desktop
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Importante
Esta característica está en versión preliminar pública.
Puede copiar código dependiente de Sparklyr que ha desarrollado localmente mediante Databricks Connect y ejecutarlo en un cuaderno de Azure Databricks o en RStudio Server hospedado en el área de trabajo de Azure Databricks con cambios mínimos o sin código.
En esta sección:
- Requisitos
- Instalación, configuración y uso de sparklyr
- Recursos
- Limitaciones de sparklyr y RStudio Desktop
Requisitos
- sparklyr 1.2 o posterior.
- Databricks Runtime 7.3 LTS o versiones posteriores con la versión coincidente de Databricks Connect.
Instalación, configuración y uso de sparklyr
En RStudio Desktop, instale sparklyr 1.2 o posterior desde CRAN o instale la versión maestra más reciente desde GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Active el entorno de Python con la versión correcta de Databricks Connect instalado y ejecute el comando siguiente en el terminal para obtener
<spark-home-path>:databricks-connect get-spark-homeInicie una sesión de Spark y empiece a ejecutar comandos de sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countCerrar la conexión.
spark_disconnect(sc)
Recursos
Para más información, consulte el README de sparklyr en GitHub.
Para ejemplos de código, consulte sparklyr.
Limitaciones de sparklyr y RStudio Desktop
No se admiten las características siguientes:
- API de streaming de sparklyr
- API de sparklyr para aprendizaje automático (ML)
- API de broom
- Modo de serialización de csv_file
- spark-submit
IntelliJ (Scala o Java)
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect con IntelliJ (Scala o Java), haga lo siguiente:
Ejecute
databricks-connect get-jar-dir.Apunte las dependencias al directorio que el comando devolvió. Vaya a Archivo > Estructura del Proyecto > Módulos > Dependencias > signo '+' > JARs o Directorios.
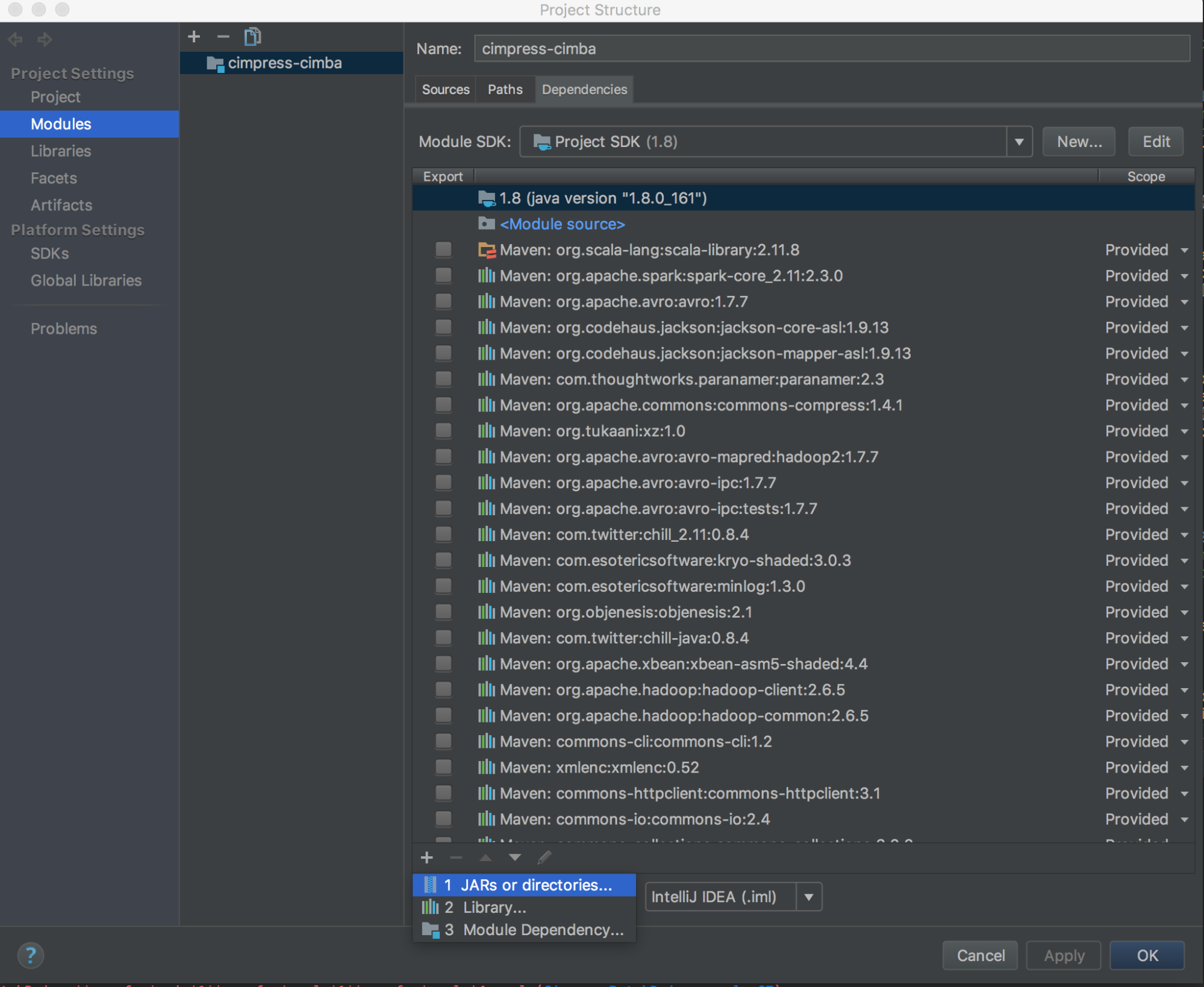
Para evitar conflictos, se recomienda quitar cualquier otra instalación de Spark de la ruta de clase. Si no es posible, asegúrese de que los archivos JAR que agregue estén al inicio de la ruta de clase. En concreto, deben estar por delante de cualquier otra versión instalada de Spark (de lo contrario, utilizarás una de esas otras versiones de Spark y ejecutarla localmente o generar un error
ClassDefNotFoundError).Compruebe la configuración de la opción de interrupción de IntelliJ. El valor predeterminado es All (Todos) y generará tiempos de espera en la red si establece puntos de interrupción para la depuración. Establezca este valor en Thread (Subproceso) para evitar detener los subprocesos de red en segundo plano.
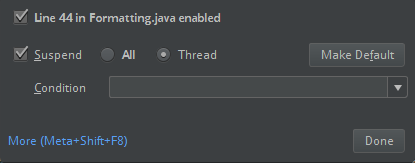
PyDev con Eclipse
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect y PyDev con Eclipse, siga estas instrucciones.
- Inicie Eclipse.
- Cree un proyecto: haga clic en Archivo > Nuevo > Proyecto > PyDev > Proyecto de PyDev y , a continuación, haga clic en Siguiente.
- Especifique un nombre de proyecto.
- En Contenido del proyecto, especifique la ruta de acceso al entorno virtual de Python.
- Haga clic en Configurar un intérprete antes de continuar.
- Haga clic en Configuración manual.
- Haga clic en Nueva > búsqueda de python/pypy exe.
- Navegue hasta la ruta de acceso completa al intérprete de Python al que se hace referencia en el entorno virtual y selecciónela. A continuación, haga clic en Abrir.
- En el diálogo Seleccionar intérprete, haga clic en Aceptar.
- En el diálogo Selección necesaria, haga clic en Aceptar.
- En el diálogo Preferencias, haga clic en Aplicar y cerrar.
- En el diálogo Proyecto de PyDev, haga clic en Finalizar.
- Haga clic en Abrir perspectiva.
- Agregue al proyecto un archivo de código de Python (
.py) que contenga el código de ejemplo o su propio código. Si usa su propio código, como mínimo debe crear una instancia deSparkSession.builder.getOrCreate(), como se muestra en el código de ejemplo. - Con el archivo de código de Python abierto, establezca los puntos de interrupción en los que quiera que se detenga el código cuando se ejecuta.
- Haga clic en Run > Run o en Run > Debug.
Para obtener instrucciones de ejecución y depuración más específicas, consulte Ejecución de un programa.
Eclipse
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect y Eclipse, haga lo siguiente:
Ejecute
databricks-connect get-jar-dir.Indique la configuración de los archivos JAR externos hacia el directorio devuelto por el comando. Vaya a Menú del Proyecto > Propiedades > Ruta de acceso de compilación de Java > Bibliotecas > Agregar JAR externos.
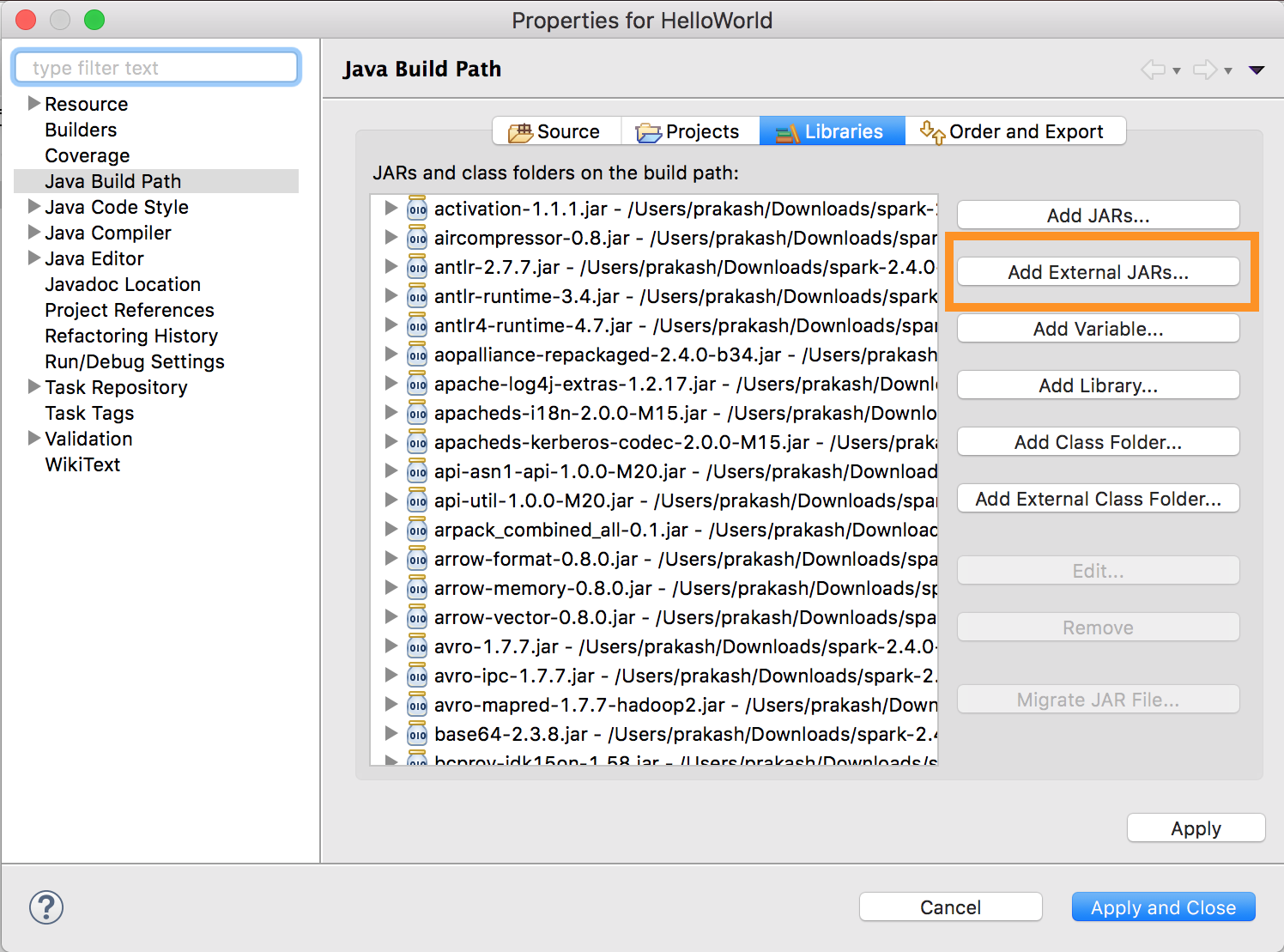
Para evitar conflictos, se recomienda quitar cualquier otra instalación de Spark de la ruta de clase. Si no es posible, asegúrese de que los archivos JAR que agregue estén al inicio de la ruta de clase. En concreto, deben estar por delante de cualquier otra versión instalada de Spark (de lo contrario, utilizarás una de esas otras versiones de Spark y ejecutarla localmente o generar un error
ClassDefNotFoundError).
SBT
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Para usar Databricks Connect con SBT, debe configurar el archivo build.sbt para que se vincule con los JAR de Databricks Connect en lugar de la dependencia de la biblioteca de Spark habitual. Esto puede hacerlo con la directiva unmanagedBase en el siguiente archivo de compilación de ejemplo, que supone una aplicación de Scala que tiene un objeto principal com.example.Test.
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Shell de Spark
Nota:
Antes de empezar a usar Databricks Connect, debe cumplir con los requisitos y configurar el cliente de Databricks Connect.
Si quiere usar Databricks Connect con el shell de Spark y Python o Scala, siga estas instrucciones.
Con el entorno virtual activado, asegúrese de que el
databricks-connect testcomando se ejecutó correctamente en Configurar el cliente.Con el entorno virtual activado, inicie el shell de Spark. Para Python, ejecute el comando
pyspark. En Scala, ejecute el comandospark-shell.# For Python: pyspark# For Scala: spark-shellAparece el shell de Spark, por ejemplo para Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Para Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Consulte Análisis interactivo con el shell de Spark para obtener información sobre cómo usar el shell de Spark con Python o Scala para ejecutar comandos en el clúster.
Use la variable integrada
sparkpara representar el elementoSparkSessiondel clúster en ejecución, por ejemplo para Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPara Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPara detener el shell de Spark, presione
Ctrl + doCtrl + z, o ejecute el comandoquit()oexit()para Python o:q:quitpara Scala.
Ejemplos de código
Este ejemplo de código simple consulta la tabla especificada y, a continuación, muestra las primeras 5 filas de la tabla especificada. Para usar otra tabla, ajuste la llamada a spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Este ejemplo de código más largo hace lo siguiente:
- Crea un DataFrame en memoria.
- Crea una tabla con el nombre
zzz_demo_temps_tabledentro del esquemadefault. Si la tabla con este nombre ya existe, primero se elimina la tabla. Para usar un esquema o tabla diferente, ajuste las llamadas aspark.sql,temps.write.saveAsTableo ambas. - Guarda el contenido del dataframe en la tabla.
- Ejecuta una
SELECTconsulta en el contenido de la tabla. - Muestra el resultado de la consulta.
- Elimina la tabla.
Pitón
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Trabajo con dependencias
Por lo general, tu clase principal o archivo de Python tendrán otros JARs de dependencia y archivos. Para agregar dichos archivos o JAR de dependencia, puede llamar a sparkContext.addJar("path-to-the-jar") o sparkContext.addPyFile("path-to-the-file"). También puede agregar archivos ZIP y archivos EGG con la interfaz addPyFile(). Cada vez que se ejecuta el código en el IDE, los archivos y JAR de dependencia se instalan en el clúster.
Pitón
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + UDF de Java
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Acceso a las utilidades de Databricks
En esta sección se describe cómo usar Databricks Connect para acceder a las utilidades de Databricks.
Puede usar las utilidades dbutils.fs y dbutils.secrets del módulo Referencia de Utilidades de Databricks (dbutils).
Los comandos admitidos son dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, dbutils.secrets.list, dbutils.secrets.listScopes.
Consulte utilidad del sistema de archivos (dbutils.fs) o ejecute dbutils.fs.help() y utilidad de secretos (dbutils.secrets) o ejecute dbutils.secrets.help().
Pitón
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Cuando utilice Databricks Runtime 7.3 LTS o posterior, para acceder al módulo DBUtils de manera que funcione tanto localmente como en clústeres de Azure Databricks, utilice el get_dbutils() siguiente:
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
En caso contrario, utilice el get_dbutils() siguiente:
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Copia de archivos entre sistemas de archivos locales y remotos
Puede usar dbutils.fs para copiar archivos entre los sistemas de archivos de cliente y remotos. El esquema file:/ hace referencia al sistema de archivos local en el cliente.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
El tamaño de archivo máximo que se puede transferir de esa manera es de 250 MB.
Habilite dbutils.secrets.get.
Debido a las restricciones de seguridad, la capacidad de llamar a dbutils.secrets.get está deshabilitada de manera predeterminada. Póngase en contacto con el soporte técnico de Azure Databricks para habilitar esta característica para el área de trabajo.
Establecimiento de las configuraciones de Hadoop
En el cliente, puede establecer configuraciones de Hadoop mediante la API spark.conf.set, que se aplica a las operaciones de DataFrame y SQL. Las configuraciones de Hadoop establecidas en sparkContext se deben establecer en la configuración del clúster o mediante un cuaderno. Esto se debe a que las configuraciones establecidas en sparkContext no están vinculadas a sesiones de usuario, sino que se aplican a todo el clúster.
Solucionar problemas
Ejecute databricks-connect test para comprobar si hay problemas de conectividad. En esta sección se describen algunos problemas comunes que pueden surgir con Databricks Connect y cómo resolverlos.
En esta sección:
- Versión de Python no coincidente
- Servidor no habilitado
- Instalaciones de PySpark en conflicto
-
En conflicto
SPARK_HOME - Entrada ausente o en conflicto
PATHpara los archivos binarios - Configuración de serialización en conflicto en el clúster
-
No se encuentra
winutils.exeen Windows - La sintaxis del nombre de archivo, el nombre del directorio o la etiqueta de volumen no es correcta en Windows
Incompatibilidad de versiones de Python
Compruebe que la versión de Python que utiliza localmente tiene al menos la misma versión secundaria que la versión existente en el clúster (por ejemplo, se admite 3.9.16 respecto de 3.9.15, pero no 3.9 respecto de 3.8).
Si tiene varias versiones de Python instaladas en el entorno local, asegúrese de que Databricks Connect utiliza la correcta; para ello, establezca la variable de entorno PYSPARK_PYTHON (por ejemplo, PYSPARK_PYTHON=python3).
Servidor no habilitado
Asegúrese de que el clúster tiene el servidor de Spark habilitado con spark.databricks.service.server.enabled true. Si es así, debería ver las líneas siguientes en el registro del controlador:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Instalaciones de PySpark en conflicto
El paquete databricks-connect entra en conflicto con PySpark. Tener ambos instalados generará errores al inicializar el contexto de Spark en Python. Estos conflictos se pueden manifestar de varias maneras, incluidos errores de "stream corrupto" o "clase no encontrada". Si tiene instalado PySpark en el entorno de Python, asegúrese de desinstalarlo antes de instalar databricks-connect. Una vez que desinstale PySpark, no olvide volver a instalar completamente el paquete de Databricks Connect:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
En conflicto SPARK_HOME
Si anteriormente utilizó Spark en la máquina, es posible que el IDE esté configurado para utilizar una de esas otras versiones de Spark en lugar de Databricks Connect Spark. Estos conflictos se pueden manifestar de varias maneras, incluidos errores de "stream corrupto" o "clase no encontrada". Para ver qué versión de Spark se utiliza, revise el valor de la variable de entorno SPARK_HOME:
Pitón
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Solución
Si SPARK_HOME se establece en una versión de Spark que no sea la del cliente, debe anular la variable SPARK_HOME y volver a intentarlo.
Revise la configuración de la variable de entorno del IDE, el archivo .bashrc, .zshrc o .bash_profile, y cualquier otro lugar en el que pueda haber variables de entorno establecidas. Lo más probable es que tenga que salir y reiniciar el IDE para purgar el estado anterior, e incluso puede que tenga que crear un proyecto si el problema persiste.
No es necesario establecer SPARK_HOME en un valor nuevo: anularlo debería ser suficiente.
Entrada PATH faltante o en conflicto para los archivos binarios
Es posible que la ruta de acceso PATH esté configurada para que comandos como spark-shell ejecuten otro archivo binario instalado previamente en lugar del que se incluye con Databricks Connect. Esto puede hacer que databricks-connect test falle. Debe asegurarse de que los archivos binarios de Databricks Connect tengan prioridad, o bien quitar los instalados previamente.
Si no puede ejecutar comandos como spark-shell, también es posible que pip3 install no haya configurado el PATH automáticamente y tendrá que agregar el directorio de instalación bin a su PATH manualmente. Es posible usar Databricks Connect con IDE aunque esto no esté configurado. Sin embargo, el comando databricks-connect test no funcionará.
Configuración de serialización en conflicto en el clúster
Si ve errores de "flujo dañado" al ejecutar databricks-connect test, puede deberse a configuraciones de serialización de clúster incompatibles. Por ejemplo, establecer la configuración spark.io.compression.codec puede generar este problema. Para resolver, considere la posibilidad de quitar estas configuraciones de la configuración del clúster, o bien establecer la configuración en el cliente de Databricks Connect.
No se encuentra winutils.exe en Windows
Si utiliza Databricks Connect en Windows y ve lo siguiente:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Siga las instrucciones para configurar la ruta de acceso de Hadoop en Windows.
La sintaxis del nombre de archivo, el nombre del directorio o la etiqueta de volumen no es correcta en Windows
Si utiliza Windows y Databricks Connect y ve lo siguiente:
The filename, directory name, or volume label syntax is incorrect.
Java o Databricks Connect se instaló en un directorio con un espacio en la ruta de acceso. Una solución alternativa es instalar en una ruta de acceso de directorio sin espacios o configurar la ruta usando el formato de nombre corto.
Autenticación mediante tokens de Microsoft Entra ID
Nota:
La siguiente información se aplica solo a las versiones 7.3.5 a 12.2.x de Databricks Connect.
Actualmente, Databricks Connect para Databricks Runtime 13.3 LTS y versiones posteriores no admite tokens de Microsoft Entra ID.
Cuando usa las versiones 7.3.5 a 12.2.x de Databricks Connect, se puede autenticar mediante un token de Microsoft Entra ID en lugar de un token de acceso personal. Los tokens de Microsoft Entra ID tienen una duración limitada. Cuando el token de Microsoft Entra ID expira, se produce el error Invalid Token en Databricks Connect.
Para las versiones 7.3.5 a 12.2.x de Databricks Connect, puede proporcionar el token de Microsoft Entra ID en la aplicación de Databricks Connect en ejecución. La aplicación debe obtener el token de acceso nuevo y establecerlo en la clave de configuración de SQL spark.databricks.service.token.
Pitón
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Una vez que actualice el token, la aplicación puede seguir utilizando el mismo valor SparkSession y cualquier objeto y estado creado en el contexto de la sesión. Para evitar errores intermitentes, Databricks recomienda proporcionar un token nuevo antes de que el token anterior expire.
Puede extender la vigencia del token de Microsoft Entra ID para que se mantenga durante la ejecución de la aplicación. Para ello, adjunte una directiva TokenLifetimePolicy con una vigencia adecuadamente larga a la aplicación de autorización de Microsoft Entra ID que haya usado para adquirir el token de acceso.
Nota:
El acceso directo de Microsoft Entra ID utiliza dos tokens: el token de acceso de Microsoft Entra ID anteriormente descrito que configura en las versiones 7.3.5 a 12.2.x de Databricks Connect y el token de acceso directo de ADLS para el recurso específico que Databricks genera mientras procesa la solicitud. No puede extender la vida útil de los tokens de paso directo de ADLS mediante directivas de vida útil de tokens de Microsoft Entra ID. Si envía un comando al clúster que tarde más de una hora, se producirá un error si el comando accede a un recurso de ADLS cuando pase esa hora.
Limitaciones
- Structured Streaming.
- La ejecución de código arbitrario no forma parte de un trabajo de Spark en el clúster remoto.
- No se admiten las API nativas de Scala, Python y R para operaciones de tabla Delta (por ejemplo,
DeltaTable.forPath). Sin embargo, se admiten tanto la API de SQL (spark.sql(...)) con operaciones de Delta Lake como la API de Spark (por ejemplo,spark.read.load) en tablas Delta. - Copiar en.
- Uso de funciones SQL, UDF de Python o Scala que forman parte del catálogo del servidor. Sin embargo, las UDF de Scala y Python que se introdujeron localmente funcionan.
- Apache Zeppelin 0.7.x y versiones anteriores.
- Conexión a clústeres con control de acceso a tablas.
- Conexión a clústeres con aislamiento de procesos habilitado (en otras palabras, donde
spark.databricks.pyspark.enableProcessIsolationse establece entrue). - Comando SQL
CLONEDelta. - Vistas temporales globales.
-
Koalas y
pyspark.pandas. -
CREATE TABLE table AS SELECT ...Los comandos SQL no siempre funcionan. En su lugar, usespark.sql("SELECT ...").write.saveAsTable("table").
- El acceso directo a credenciales de Microsoft Entra ID solo se admite en clústeres estándar que ejecutan Databricks Runtime 7.3 LTS y versiones posteriores, y no es compatible con la autenticación de la entidad de servicio.
- La siguiente referencia de las utilidades de Databricks (
dbutils):