Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
Este artículo describe Databricks Connect para Databricks Runtime 13.3 LTS y versiones posteriores.
Databricks Connect le permite conectar los clústeres de Azure Databricks a entornos de desarrollo integrado populares como IntelliJ IDEA, servidores de cuadernos y otras aplicaciones personalizadas. Consulte ¿Qué es Databricks Connect?.
En este artículo se muestra cómo empezar a trabajar rápidamente con Databricks Connect para Scala mediante IntelliJ IDEA y el complemento Scala.
- Para obtener la versión de Python de este artículo, consulte Databricks Connect para Python.
- Para ver la versión de R de este artículo, consulte Databricks Connect para R.
Guía
En el siguiente tutorial, creará un proyecto en IntelliJ IDEA, instalará Databricks Connect para Databricks Runtime 13.3 LTS y versiones posteriores, y ejecutará código simple en su área de trabajo de Databricks desde IntelliJ IDEA. Para obtener más información y ejemplos, consulte Pasos siguientes.
Requisitos
Para completar este tutorial, debe cumplir los siguientes requisitos:
El área de trabajo y el clúster de Azure Databricks de destino deben cumplir los requisitos de proceso de Databricks Connect.
Debe tener disponible el identificador de clúster. Para obtener el identificador del clúster, en el área de trabajo, haga clic en Proceso en la barra lateral y, a continuación, haga clic en el nombre del clúster. En la barra de direcciones del explorador web, copie la cadena de caracteres entre
clustersyconfigurationen la dirección URL.El entorno local y el proceso cumplen los requisitos de la versión de instalación de Databricks Connect para Scala.
Tiene el kit de desarrollo de Java (JDK) instalado en la máquina de desarrollo. Databricks recomienda que la versión de la instalación de JDK coincida con la versión de JDK en el clúster de Azure Databricks. Para buscar la versión de JDK de Databricks Runtime en el clúster, consulte la sección Entorno del sistema de las notas de la versión de Databricks Runtime o la matriz de compatibilidad de versiones.
Nota:
Si no tiene instalado un JDK o si tiene varias instalaciones de JDK en el equipo de desarrollo, puede instalar o elegir un JDK específico más adelante en el paso 1. La elección de una instalación de JDK inferior o superior a la versión de JDK en el clúster podría producir resultados inesperados o que el código no se ejecute.
Tiene IntelliJ IDEA instalado. Este tutorial se ha probado con IntelliJ IDEA Community Edition 2023.3.6. Si usa otra versión o edición de IntelliJ IDEA, las instrucciones siguientes pueden variar.
Tiene instalado el complemento de Scala para IntelliJ IDEA.
Paso 1: configuración de la autenticación de Azure Databricks
En este tutorial se usa Azure Databricks Autenticación de usuario a máquina (U2M) de OAuth y un perfil de configuración de Azure Databricks para autenticarse con el área de trabajo de Azure Databricks. Para usar un tipo de autenticación diferente en su lugar, consulte Configuración de propiedades de conexión.
La configuración de la autenticación U2M de OAuth requiere la CLI de Databricks, como se indica a continuación:
Si aún no está instalado, instale la CLI de Databricks de la siguiente manera:
Linux, macOS
Use Homebrew para instalar la CLI de Databricks mediante la ejecución de los dos comandos siguientes:
brew tap databricks/tap brew install databricksWindows
Puede usar winget, Chocolatey o el Subsistema de Windows para Linux (WSL) a fin de instalar la CLI de Databricks. Si no puede usar
winget, Chocolatey o WSL, debe omitir este procedimiento y usar el símbolo del sistema o PowerShell para instalar la CLI de Databricks desde el origen en su lugar.Nota:
La instalación de la CLI de Databricks con Chocolatey es Experimental.
A fin de usar
wingetpara instalar la CLI de Databricks, ejecute los dos comandos siguientes y reinicie el símbolo del sistema:winget search databricks winget install Databricks.DatabricksCLIPara usar Chocolatey a fin de instalar la CLI de Databricks, ejecute el siguiente comando:
choco install databricks-cliPara usar WSL a fin de instalar la CLI de Databricks, haga lo siguiente:
Instale
curlyzipmediante WSL. Para obtener más información, consulte la documentación del sistema operativo.Use WSL para instalar la CLI de Databricks mediante la ejecución del siguiente comando:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Confirme que la CLI de Databricks está instalada mediante la ejecución del siguiente comando, que muestra la versión actual instalada de la CLI de Databricks: Esta versión debe ser 0.205.0 o superior.
databricks -vNota:
Si ejecuta
databrickspero recibe un error comocommand not found: databricks, o si ejecutadatabricks -vy aparece un número de versión de 0.18 o inferior, significa que la máquina no encuentra la versión correcta del ejecutable de la CLI de Databricks. Para corregirlo, consulte Comprobación de la instalación de la CLI.
Inicie la autenticación U2M de OAuth, como se indica a continuación:
Use la CLI de Databricks para iniciar la administración de tokens de OAuth localmente mediante la ejecución del siguiente comando para cada área de trabajo de destino.
En el comando siguiente, reemplace
<workspace-url>por la dirección URL de Azure Databricks por área de trabajo, por ejemplo,https://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>La CLI de Databricks le pide que guarde la información que especificó como un perfil de configuración de Azure Databricks. Presione
Enterpara aceptar el nombre del perfil sugerido o escriba el nombre de un perfil nuevo o existente. Cualquier perfil existente con el mismo nombre se sobrescribe con la información que especificó. Puede usar perfiles para cambiar rápidamente el contexto de autenticación entre varias áreas de trabajo.Para obtener una lista de los perfiles existentes, en un terminal o símbolo del sistema independiente, use la CLI de Databricks para ejecutar el comando
databricks auth profiles. Para ver la configuración existente de un perfil específico, ejecute el comandodatabricks auth env --profile <profile-name>.En el explorador web, complete las instrucciones en pantalla para iniciar sesión en el área de trabajo de Azure Databricks.
En la lista de clústeres disponibles que aparecen en el terminal o el símbolo del sistema, use las teclas de flecha arriba y flecha abajo para seleccionar el clúster de Azure Databricks de destino en el área de trabajo y a continuación, presione
Enter. También puede escribir cualquier parte del nombre de visualización del clúster para filtrar la lista de clústeres disponibles.Para ver el valor actual del token de OAuth de un perfil y la próxima marca de tiempo de expiración del token, ejecute uno de los siguientes comandos:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Si tiene varios perfiles con el mismo valor
--host, es posible que tenga que especificar las opciones--hosty-ppara ayudar a la CLI de Databricks a encontrar la información correcta del token de OAuth coincidente.
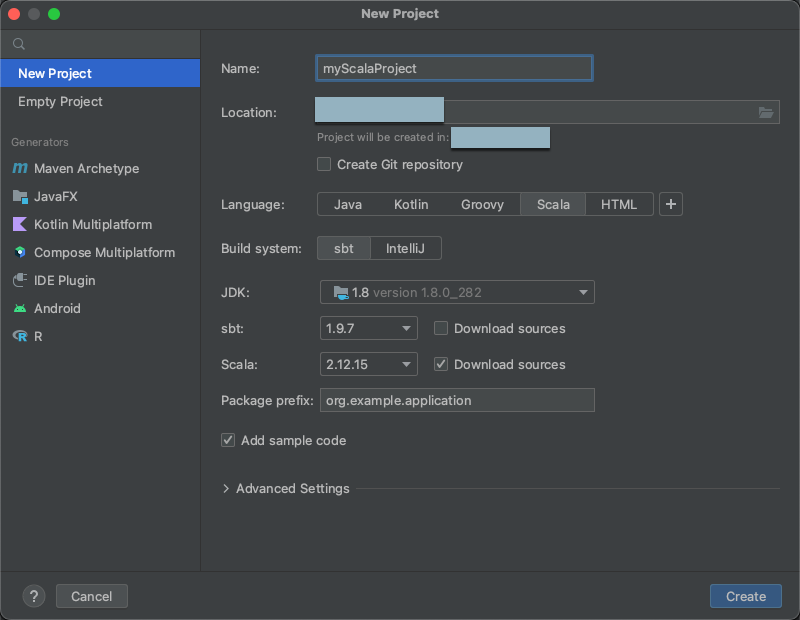
Paso 2: Crear el proyecto
Inicie IntelliJ IDEA.
En el menú principal, haga clic en Archivo > Nuevo > Proyecto.
Ponga a su proyecto un nombre descriptivo.
En Ubicación, haga clic en el icono de carpeta y complete las instrucciones en pantalla para especificar la ruta de acceso al nuevo proyecto de Scala.
En Idioma, haga clic en Scala.
En Sistema de compilación, haga clic en sbt.
En la lista desplegable JDK, seleccione una instalación existente de JDK en el equipo de desarrollo que coincida con la versión de JDK del clúster, o bien seleccione Descargar JDK y siga las instrucciones en pantalla para descargar un JDK que coincida con la versión de JDK en el clúster. Consulte los Requisitos.
Nota:
La elección de una instalación de JDK anterior o inferior a la versión de JDK en el clúster podría producir resultados inesperados o que el código no se ejecute.
En la lista desplegable sbt, seleccione la versión más reciente.
En la lista desplegable Scala, seleccione la versión de Scala que coincida con la versión de Scala en el clúster. Consulte los Requisitos.
Nota:
La elección de una versión de Scala anterior o inferior a la versión de Scala en el clúster podría producir resultados inesperados o que el código no se ejecute.
Asegúrese de que el cuadro Descargar orígenes junto a Scala está activado.
En Prefijo de paquete, escriba algún valor de prefijo de paquete para los orígenes del proyecto, por ejemplo
org.example.application.Asegúrese de que la casilla Agregar código de ejemplo esté activada.
Haga clic en Crear.
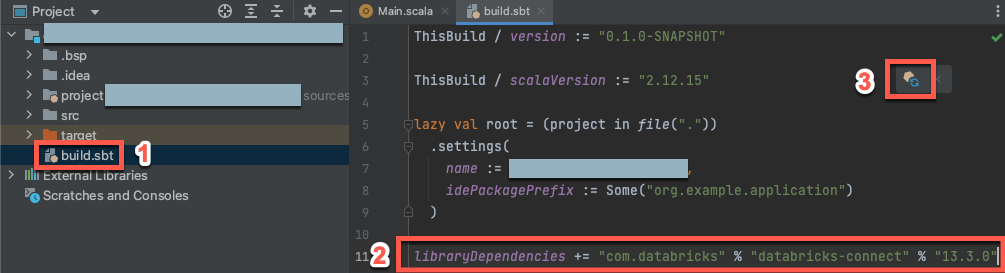
Paso 3: Agregar el paquete de Databricks Connect
Con el nuevo proyecto de Scala abierto, en la ventana de la herramienta Proyecto (Ver > Ventana de herramientas > Proyecto), abra el archivo denominado
build.sbt, en el destino project-name>.Agregue el código siguiente al final del
build.sbtarchivo, que declara la dependencia del proyecto en una versión específica de la biblioteca de Databricks Connect para Scala, compatible con la versión de Databricks Runtime del clúster:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"Reemplace
14.3.1por la versión de la biblioteca de Databricks Connect que coincida con la versión de Databricks Runtime en el clúster. Por ejemplo, Databricks Connect 14.3.1 coincide con Databricks Runtime 14.3 LTS. Puede encontrar los números de versión de la biblioteca de Databricks Connect en el repositorio central de Maven.Haga clic en el icono de notificación Cargar cambios de sbt para actualizar su proyecto de Scala con la nueva ubicación y dependencia de la biblioteca.
Espere hasta que desaparezca el indicador de progreso
sbten la parte inferior del IDE. El proceso de cargasbtpuede tardar unos minutos en completarse.
Paso 4: Agregar un código
En la ventana de herramientas Proyecto, abra el archivo denominado
Main.scala, en project-name> src > main > scala.Reemplace cualquier código existente en el archivo por el siguiente código y, a continuación, guarde el archivo, en función del nombre del perfil de configuración.
Si el perfil de configuración del paso 1 se denomina
DEFAULT, reemplace cualquier código existente en el archivo por el siguiente código y, a continuación, guarde el archivo:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Si el perfil de configuración del paso 1 no se denomina
DEFAULT, reemplace cualquier código existente en el archivo por el siguiente código. Reemplace el marcador de posición<profile-name>por el nombre del perfil de configuración del paso 1 y guarde el archivo:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Paso 5: ejecutar el código
- Inicie el clúster de destino en el área de trabajo remota de Azure Databricks.
- Una vez iniciado el clúster, en el menú principal, haga clic en Ejecutar > ejecutar "Main".
- En la ventana de herramientas Ejecutar (Ver > Ventana de herramientas > Ejecutar), en la pestaña Main, aparecen las primeras cinco filas de la tabla
samples.nyctaxi.trips.
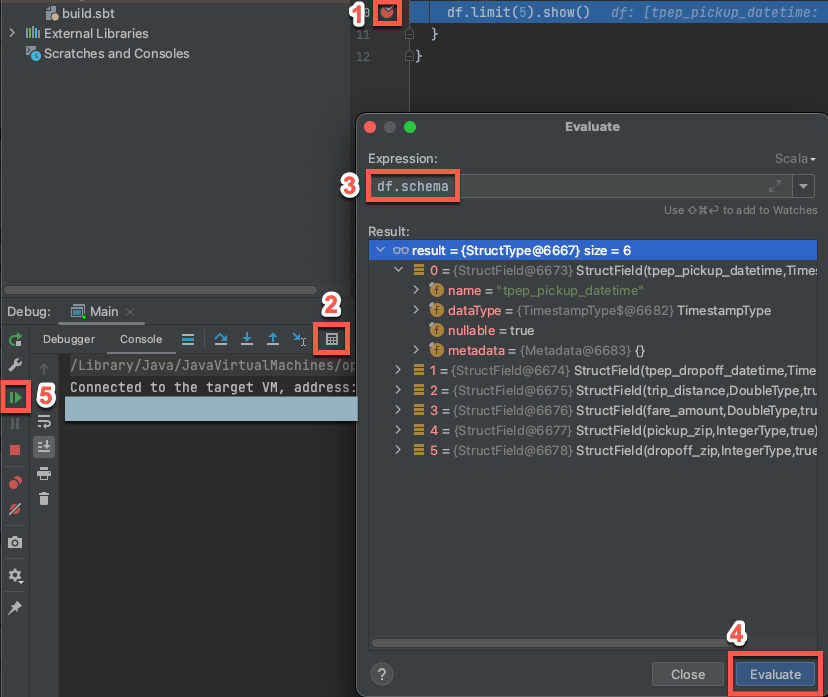
Paso 6: Depurar el código
- Con el clúster en ejecución, en el código anterior, haga clic en el margen junto a
df.limit(5).show()para establecer un punto de interrupción. - En el menú principal, haga clic en >.
- En la ventana de herramientas Depurar (Ver > Ventana de herramientas > Depurar), en la pestaña Consola, haga clic en el icono de la calculadora (Evaluar expresión).
- Escriba la expresión
df.schemay haga clic en Evaluar para mostrar el esquema de DataFrame. - En la barra lateral de la ventana de la herramienta Depurar , haga clic en el icono de flecha verde (Reanudar programa).
- En el panel Consola, aparecen las cinco primeras filas de la tabla
samples.nyctaxi.trips.
Pasos siguientes
Para obtener más información sobre Databricks Connect, consulte los artículos siguientes:
- Para usar tipos de autenticación de Azure Databricks distintos de un token de acceso personal de Azure Databricks, consulte Configuración de propiedades de conexión.
- Para ver ejemplos de código simple adicionales, consulte Ejemplos de código de Databricks Connect para Scala.
- Para ver ejemplos de código más complejos, consulte las aplicaciones de ejemplo para el repositorio de Databricks Connect en GitHub, en concreto:
- Para migrar de Databricks Connect para Databricks Runtime 12.2 LTS y versiones inferiores a Databricks Connect para Databricks Runtime 13.3 LTS y versiones superiores, vea Migración a Databricks Connect para Scala.
- Consulte también la información sobre la solución de problemas y las limitaciones.