Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En esta página se describen los conectores estándar de Databricks Lakeflow Connect, que ofrecen niveles más altos de personalización de canalización de ingesta en comparación con los conectores administrados.
Capas de la pila ETL
Algunos conectores funcionan en un nivel de la pila ETL. Por ejemplo, Databricks ofrece conectores totalmente administrados para aplicaciones empresariales como Salesforce y bases de datos como SQL Server. Otros conectores operan en varias capas de la pila ETL. Por ejemplo, puede usar conectores estándar en Structured Streaming para lograr una personalización completa o canalizaciones declarativas de Lakeflow Spark para obtener una experiencia más administrada.
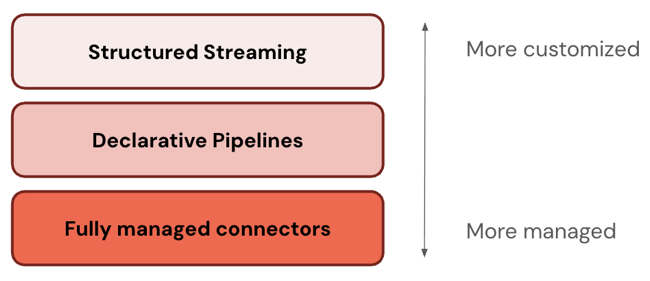
Databricks recomienda empezar con la capa más administrada. Si no cumple los requisitos (por ejemplo, si no es compatible con el origen de datos), vaya a la siguiente capa.
En la tabla siguiente se describen las tres capas de productos de ingesta, ordenados de la mayoría personalizables a la mayoría administrados:
| Nivel | Descripción |
|---|---|
| Structured Streaming | Apache Spark Structured Streaming es un motor de streaming que ofrece tolerancia a errores de un extremo a otro con garantías de procesamiento exactamente una vez mediante las API de Spark. |
| Canalizaciones declarativas de Lakeflow Spark | Las canalizaciones declarativas de Spark de Lakeflow se basan en Structured Streaming, ofreciendo un marco declarativo para crear canalizaciones de datos. Puede definir las transformaciones que se van a realizar en los datos y Las canalizaciones declarativas de Spark de Lakeflow administran la orquestación, la supervisión, la calidad de los datos, los errores, etc. Por lo tanto, ofrece más automatización y menos sobrecarga que Structured Streaming. |
| Conectores administrados | Conectores completamente gestionados se basan en las canalizaciones declarativas de Lakeflow Spark, ofreciendo aún más automatización para los orígenes de datos más populares. Amplían la funcionalidad de canalizaciones declarativas de Spark de Lakeflow para incluir también autenticación específica del origen, CDC, control de casos perimetrales, mantenimiento de API a largo plazo, reintentos automatizados, evolución automatizada del esquema, etc. Por lo tanto, ofrecen aún más automatización para los orígenes de datos admitidos. |
Elija un conector
En la tabla siguiente se enumeran los conectores de ingesta estándar por origen de datos y nivel de personalización de canalización. Para una experiencia de ingesta totalmente automatizada, use conectores administrados en su lugar.
Ejemplos de SQL para la ingesta incremental desde el almacenamiento de objetos en la nube usan la sintaxis CREATE STREAMING TABLE. Ofrece a los usuarios de SQL una experiencia de ingesta escalable y sólida, por lo que es la alternativa recomendada a COPY INTO.
| Fuente | Más personalización | Algunas personalizaciones | Más automatización |
|---|---|---|---|
| Almacenamiento de objetos en la nube |
Cargador automático con streaming estructurado (Python, Scala) |
Cargador automático con canalizaciones declarativas de Lakeflow Spark (Python, SQL) |
Cargador automático con Databricks SQL (SQL) |
| Servidores SFTP |
Ingesta de archivos de servidores SFTP (Python, SQL) |
N/A | N/A |
| Apache Kafka |
Structured Streaming con la fuente de Kafka (Python, Scala) |
Canalizaciones declarativas de Lakeflow Spark con origen en Kafka (Python, SQL) |
Databricks SQL con fuente Kafka (SQL) |
| Google Pub/Sub |
Structured Streaming con fuente Pub/Sub (Python, Scala) |
Canalizaciones declarativas de Lakeflow Spark con fuente Pub/Sub (Python, SQL) |
Databricks SQL con origen Pub/Sub (SQL) |
| Apache Pulsar |
Structured Streaming with Pulsar source (Streaming estructurado con origen de Pulsar) (Python, Scala) |
Canalizaciones declarativas de Spark de Lakeflow con el origen Pulsar (Python, SQL) |
Databricks SQL con origen Pulsar (SQL) |
Programaciones de ingesta
Puede configurar los pipelines de ingesta para que se ejecuten en una programación recurrente o de forma continua.
| Caso de uso | Modo de canalización |
|---|---|
| Ingesta por lotes | Desencadenado: procesa nuevos datos según una programación o cuando se desencadena manualmente. |
| Ingesta de streaming | Continuo: procesa los nuevos datos a medida que llegan al origen. |