Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
El conector de Microsoft SQL Server está en versión preliminar pública.
Solución de problemas generales de canalización
Los pasos de solución de problemas de esta sección se aplican a todas las canalizaciones de ingesta en Lakeflow Connect.
Si se produce un error en una canalización durante la ejecución, haga clic en el paso que produjo un error y confirme si el mensaje de error proporciona información suficiente sobre la naturaleza del error.
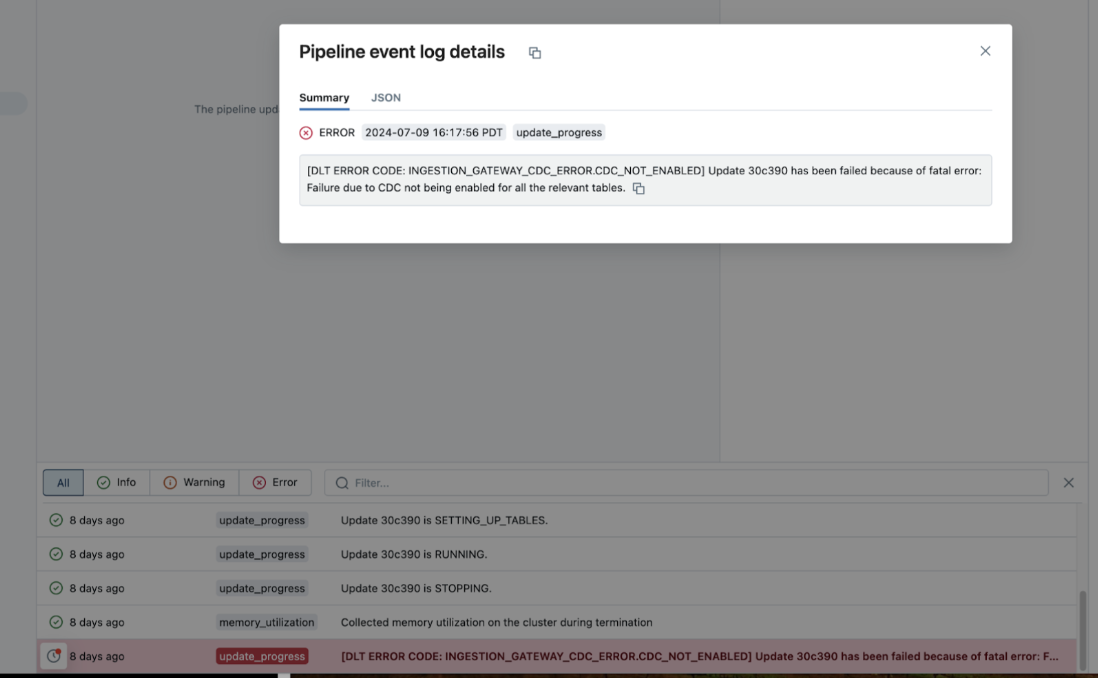
También puede comprobar y descargar los registros del clúster desde la página de detalles de la canalización; para ello, haga clic en Actualizar detalles en el panel derecho y, a continuación, en Registros. Examine los registros de errores o excepciones.
Solución de problemas específica del conector
Los pasos de solución de problemas de esta sección son específicos del conector de SQL Server.
Comprobación de si CDC está habilitado para una base de datos o una tabla
Para comprobar si CDC está habilitado para la base de datos <database-name>:
select is_cdc_enabled from sys.databases where name='<database-name>';
Para comprobar si CDC está habilitado para la tabla <schema-name>.<table-name>:
select t.is_tracked_by_cdc
from sys.tables t join sys.schemas s on t.schema_id = s.schema_id
where s.name='<schema-name>' and t.name='<table-name>';
Compruebe si el seguimiento de cambios está habilitado para una base de datos o una tabla
Para comprobar si el seguimiento de cambios está habilitado para la base de datos\<database-name\>:
select ctdb.*
from sys.change_tracking_databases ctdb join sys.databases db
on db.database_id = ctdb.database_id
where db.name = '<MyDatabaseName>'
Para comprobar si el seguimiento de cambios está habilitado para la tabla <schema-name>.<table-name>:
select s.name schema_name, t.name table_name, ct.*
from sys.change_tracking_tables ct join sys.tables t
on ct.object_id = t.object_id
join sys.schemas s on t.schema_id = s.schema_id
where s.name = '<MySchemaName>' and t.name = '<MyTableName>'
Tiempo de espera agotado al esperar el identificador de tabla
La tubería de ingesta puede agotarse mientras espera que la puerta de enlace proporcione información. Esto puede deberse a lo siguiente:
- Está utilizando una versión anterior del gateway.
- Error al generar la información necesaria. Compruebe si hay errores en los registros del controlador de puerta de enlace.
autenticación predeterminada: no se pueden configurar las credenciales predeterminadas
Si recibe este error, hay un problema con la detección de las credenciales de usuario actuales. Intente reemplazar lo siguiente:
w = WorkspaceClient()
con:
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
Consulte Autenticación en la documentación del SDK de Databricks para Python.
tech.replicant.common.ExtractorException: com.microsoft.sqlserver.jdbc.SQLServerException: nombre de columna "SERIAL_NUMBER" no válido.
Es posible que reciba este error si usa una versión anterior de una tabla interna. Ejecute lo siguiente en la base de datos conectada:
drop table dbo.replicate_io_audit_ddl_trigger_1;
PERMISSION_DENIED: No está autorizado a crear clústeres. Póngase en contacto con el administrador.
Póngase en contacto con un administrador de la cuenta de Databricks para que le concedan Unrestricted cluster creation permisos.
CÓDIGO DE ERROR DLT: ERROR_INTERNO_DEL_PORTAL_DE_INGESTIÓN
Compruebe los stdout archivos en los registros del controlador.
Conflicto de nombres de tabla fuente
Ingestion pipeline error: “org.apache.spark.sql.catalyst.ExtendedAnalysisException: Cannot have multiple queries named `XYZ_snapshot_load` for `XYZ`. Additional queries on that table must be named. Note that unnamed queries default to the same name as the table.
Esto indica que hay un conflicto de nombres debido a varias tablas de origen denominadas XYZ en esquemas de origen diferentes que la misma canalización de ingesta ingiere en el mismo esquema de destino.
Cree varios pares de canalización de puerta de enlace escribiendo estas tablas en conflicto en distintos esquemas de destino.
Cambios de esquema incompatibles
Un cambio de esquema incompatible causa que la canalización de ingesta falle con un error INCOMPATIBLE_SCHEMA_CHANGE. Para continuar con la replicación, desencadene una actualización completa de las tablas afectadas.
Nota:
Databricks no puede garantizar que, al producirse un error en la canalización de ingesta debido a un cambio de estructura incompatible, se hayan ingerido todas las filas anteriores al cambio de estructura.