Confiabilidad del almacén de lago de datos
Los principios arquitectónicos del pilar de confiabilidad abordan la capacidad de un sistema para recuperarse de errores y seguir funcionando.
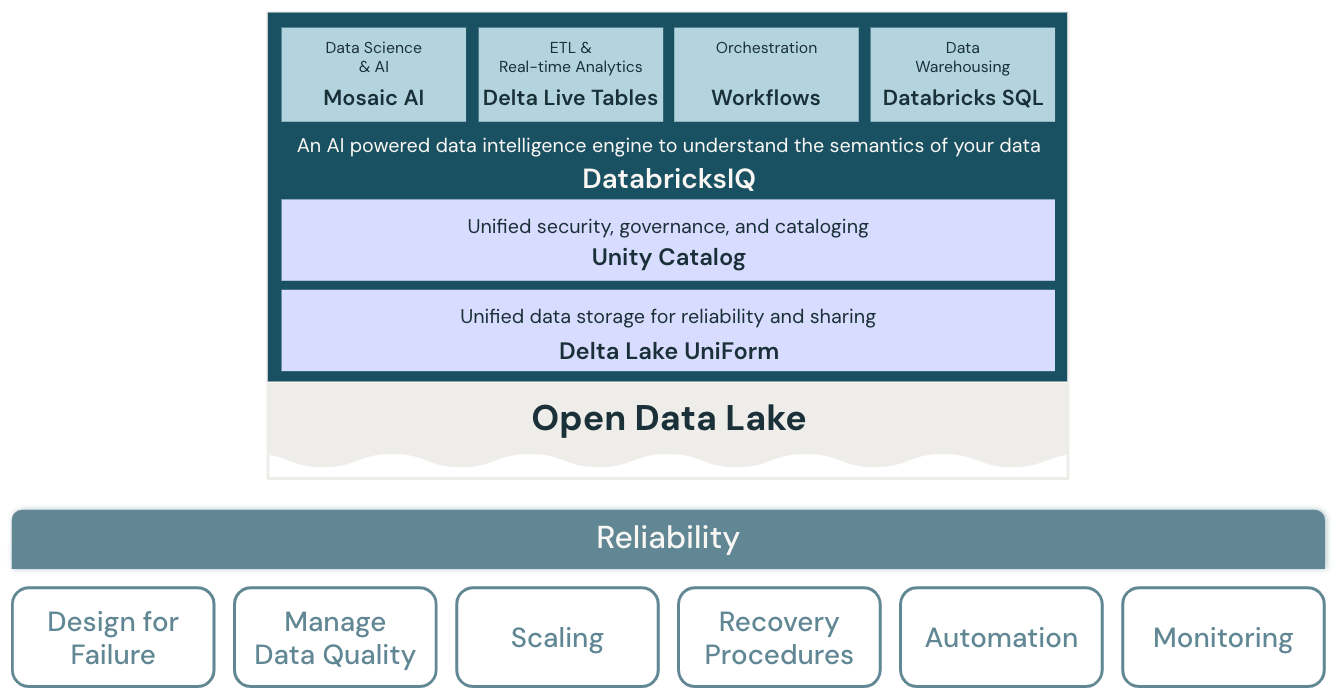
Principios de confiabilidad
Diseño para errores
En un entorno altamente distribuido, se pueden producir interrupciones. Tanto para la plataforma como para las distintas cargas de trabajo, como los trabajos de streaming, los trabajos por lotes, el entrenamiento de modelos y las consultas de BI, se deben prever errores y se deben desarrollar soluciones resistentes para aumentar la confiabilidad. Se debe dar prioridad a diseñar las aplicaciones para que se recuperen rápidamente y, en el mejor de los casos, automáticamente.
Administrar la calidad de los datos
La calidad de los datos es fundamental para derivar información precisa y significativa de los datos. La calidad de los datos tiene muchas dimensiones, incluida la integridad, la precisión, la validez y la coherencia. Debe administrarse activamente para mejorar la calidad de los conjuntos de datos finales, de modo que los datos actúen como información confiable para los usuarios empresariales.
Diseñar para la escalabilidad automática
Los procesos de ETL estándar, los informes empresariales y los paneles suelen tener requisitos de recursos predecibles en términos de memoria y proceso. Sin embargo, los nuevos proyectos, las tareas estacionales o los enfoques avanzados, como el entrenamiento de modelos (para abandono, previsión y mantenimiento) crean picos en los requisitos de recursos. Para que una organización controle todas estas cargas de trabajo, necesita una plataforma de proceso y almacenamiento escalables. La adición de nuevos recursos según sea necesario debe ser fácil y solo se debe cobrar el consumo real. Una vez que se supera el pico, los recursos se pueden liberar y los costes se reducen en consecuencia. Esto se conoce a menudo como escalado horizontal (número de nodos) y escalado vertical (tamaño de nodos).
Probar los procedimientos de recuperación
Una estrategia de recuperación ante desastres en toda la empresa para la mayoría de las aplicaciones y sistemas requiere una evaluación de prioridades, funcionalidades, limitaciones y costes. Un enfoque de recuperación ante desastres confiable comprueba periódicamente cómo se producen errores en las cargas de trabajo y valida los procedimientos de recuperación. La automatización se puede usar para simular errores diferentes o volver a crear escenarios que hayan causado errores en el pasado.
Automatización de las implementaciones y cargas de trabajo
La automatización de implementaciones y cargas de trabajo para el almacén de lago ayuda a estandarizar estos procesos, eliminar errores humanos, mejorar la productividad y proporcionar mayor repetibilidad. Esto incluye el uso de la “configuración como código” para evitar desfases en configuración y la “infraestructura como código” para automatizar el aprovisionamiento de todos los servicios de almacén de lago y en la nube necesarios.
Supervisar sistemas y cargas de trabajo
Las cargas de trabajo del almacén de lago normalmente integran servicios de la plataforma Databricks y servicios en la nube externos, por ejemplo, orígenes o destinos de datos. La ejecución correcta solo puede producirse si cada servicio de la cadena de ejecución funciona correctamente. Cuando esto no sucede, la supervisión, las alertas y el registro son importantes para detectar y realizar un seguimiento de los problemas y comprender el comportamiento del sistema.
Siguiente: procedimientos recomendados para una mayor confiabilidad
Consulte los procedimientos recomendados para una mayor confiabilidad.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de