Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica se encuentra en su versión beta.
En esta página se describe qué es la supervisión de calidad de los datos, qué supervisa y cómo usarla. Anteriormente, la supervisión de la calidad de los datos se denominaba detección de anomalías.
Para proporcionar comentarios sobre la supervisión de la calidad de los datos, envíe un correo electrónico a lakehouse-monitoring-feedback@databricks.com.
¿Qué es la supervisión de la calidad de los datos?
Con la supervisión de la calidad de los datos, puede supervisar fácilmente la calidad de los datos de todas las tablas de un esquema. Databricks aprovecha la inteligencia de datos para evaluar automáticamente la calidad de los datos, en concreto la evaluación de la actualización y la integridad de cada tabla. La información de calidad se rellena en indicadores de estado para que los consumidores puedan comprender el estado de un vistazo. Los propietarios de datos tienen acceso a tablas y paneles de registro para que puedan identificar, establecer alertas y resolver anomalías en todo un esquema.
La supervisión de la calidad de los datos no modifica ninguna tabla que supervisa ni agrega sobrecarga a los trabajos que rellenan estas tablas.
Requisitos
- Área de trabajo habilitada para el catálogo de Unity.
- Computación sin servidor habilitada. Para obtener instrucciones, consulte Conectar a la computación sin servidor.
- Para habilitar la supervisión de la calidad de los datos en un esquema, debe tener privilegios MANAGE SCHEMA o MANAGE CATALOG en el esquema de catálogo.
¿Cómo funciona la supervisión de la calidad de los datos?
Databricks supervisa las tablas habilitadas para la actualidad y la integridad .
Actualización hace referencia a la actualización de una tabla recientemente. La supervisión de la calidad de los datos analiza el historial de confirmaciones en una tabla y crea un modelo por tabla para predecir la hora de la siguiente confirmación. Si una confirmación es inusualmente tardía, la tabla se marca como obsoleta. En el caso de las tablas de series temporales, puede especificar columnas de tiempo de evento. Después, la supervisión de la calidad de los datos detecta si la latencia de ingesta de los datos, definida como la diferencia entre el tiempo de confirmación y la hora del evento, es inusualmente alta.
Integridad hace referencia al número de filas que se espera que se escriban en la tabla en las últimas 24 horas. La supervisión de la calidad de los datos analiza el recuento histórico de filas y, basándose en estos datos, predice el número esperado de filas. Si el número de filas confirmadas en las últimas 24 horas es menor que el límite inferior de este intervalo, una tabla se marca como incompleta.
¿Con qué frecuencia se ejecuta un monitor de calidad de datos?
De forma predeterminada, un monitor de calidad de datos se ejecuta cada hora. Antes de examinar cada tabla, el sistema comprueba si es probable que la tabla se haya actualizado desde la última ejecución. Si aún no se espera que se haya actualizado una tabla, se omitirá el examen.
Habilitación de la supervisión de la calidad de los datos en un esquema
Para habilitar la supervisión de la calidad de los datos en un esquema, vaya al esquema en el catálogo de Unity.
En la página de esquema, haga clic en la pestaña Detalles.
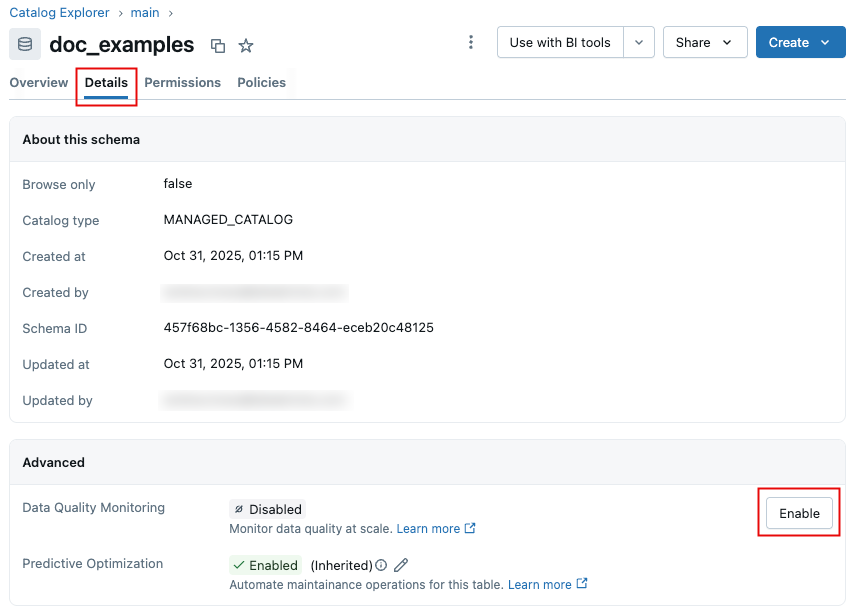
Haga clic en el interruptor Supervisión de calidad de datos para habilitarlo.

Se inicia un trabajo programado de Databricks para examinar el esquema. Para la primera ejecución del trabajo, Databricks también ejecuta el monitor en datos históricos ("backtesting") para comprobar la calidad de las tablas como si la monitorización de la calidad de los datos se hubiera activado en el esquema hace dos semanas. Estos resultados se registran en la tabla de registro.
De forma predeterminada, el trabajo se ejecuta cada hora. Para cambiar esta configuración, consulte Establecer parámetros para la evaluación de actualización e integridad.
Para ver el progreso del trabajo o para configurar el trabajo, haga clic en el
 junto al interruptor. En el cuadro de diálogo que aparece, haga clic en Ver detalles.
junto al interruptor. En el cuadro de diálogo que aparece, haga clic en Ver detalles.
Una vez completado el trabajo, verá los problemas de calidad detectados registrados en la tabla de registro de salida con información rellenada en el Panel de calidad de datos. Puede acceder al panel en cualquier momento haciendo clic en Ver resultados junto al interruptor Supervisión de calidad de datos.
Panel de supervisión de calidad de datos
La primera ejecución del monitor de calidad de datos crea un tablero que resume los resultados y tendencias derivados de la tabla de registro. La ejecución del trabajo muestra un botón que puede usar para acceder al panel. El panel se rellena automáticamente con información para el esquema examinado. En esta ruta de acceso se crea un único panel de control por área de trabajo: /Shared/Databricks Quality Monitoring/Data Quality Monitoring.
Información general sobre la calidad
En la pestaña Información general de calidad se muestra un resumen del estado de calidad más reciente de las tablas del esquema en función de la evaluación más reciente.
Para empezar, debe escribir la tabla de registro para el esquema que desea analizar para rellenar el panel.
En la sección superior del panel se muestra información general sobre los resultados del examen.
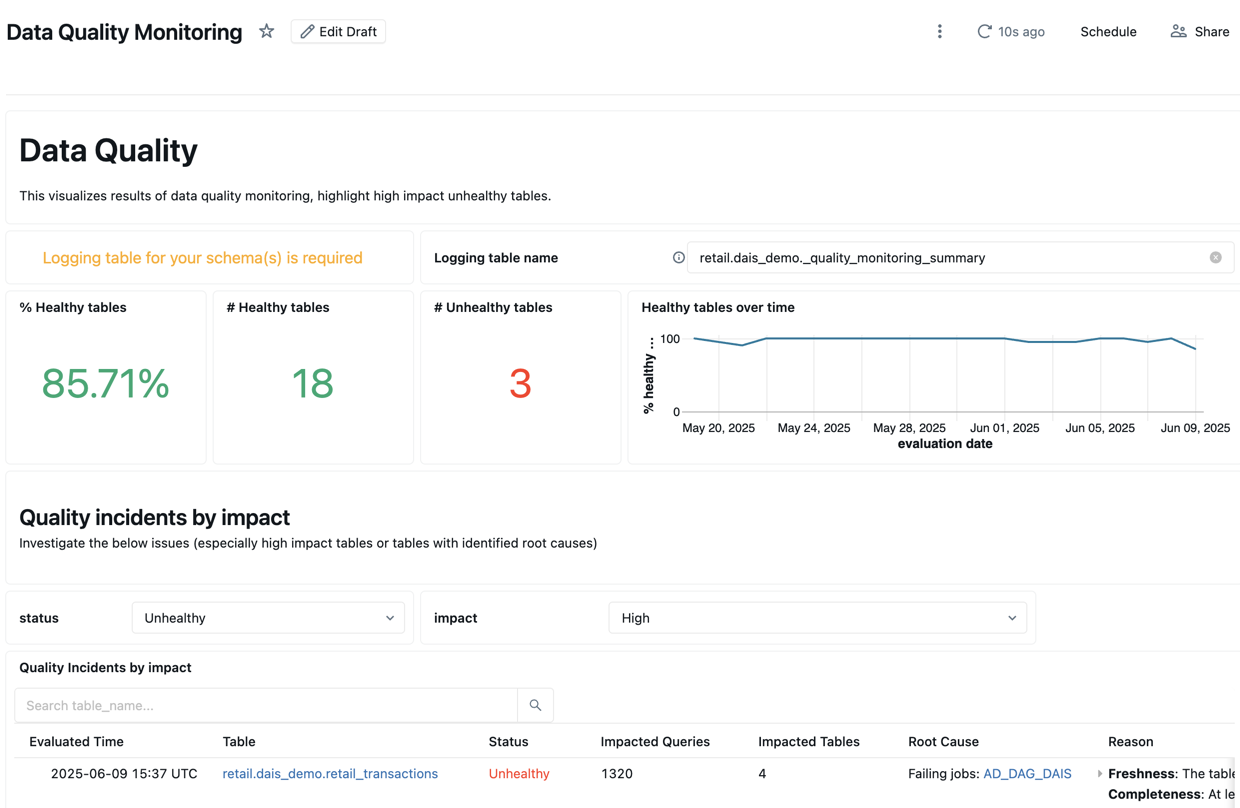
Debajo del resumen se muestra una tabla en la que se enumeran los incidentes de calidad por impacto. Las causas principales identificadas se muestran en la root_cause_analysis columna .
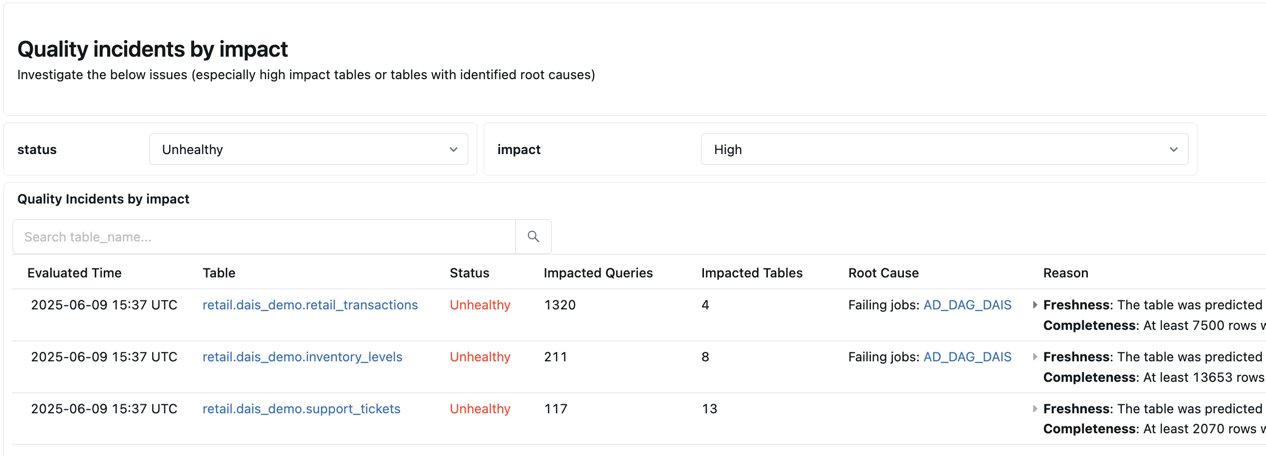
Debajo de la tabla de incidentes de calidad se muestra una tabla de tablas estáticas identificadas que no se han actualizado durante mucho tiempo.
Detalles de calidad de tabla
La interfaz de usuario Tabla de Calidad Detalles permite profundizar en las tendencias y analizar tablas específicas de tu esquema. Puede acceder a la interfaz de usuario haciendo clic en los nombres de tabla del panel Información general de calidad (vea los vínculos en los que se pueden hacer clic en la captura de pantalla anterior) o visitando la pestaña Calidad en el visor de tablas uc.
Dada una tabla, la interfaz de usuario muestra resúmenes de cada comprobación de calidad de la tabla, con gráficos de valores predichos y observados en cada marca de tiempo de evaluación. Los gráficos trazan los resultados de la última semana de datos.
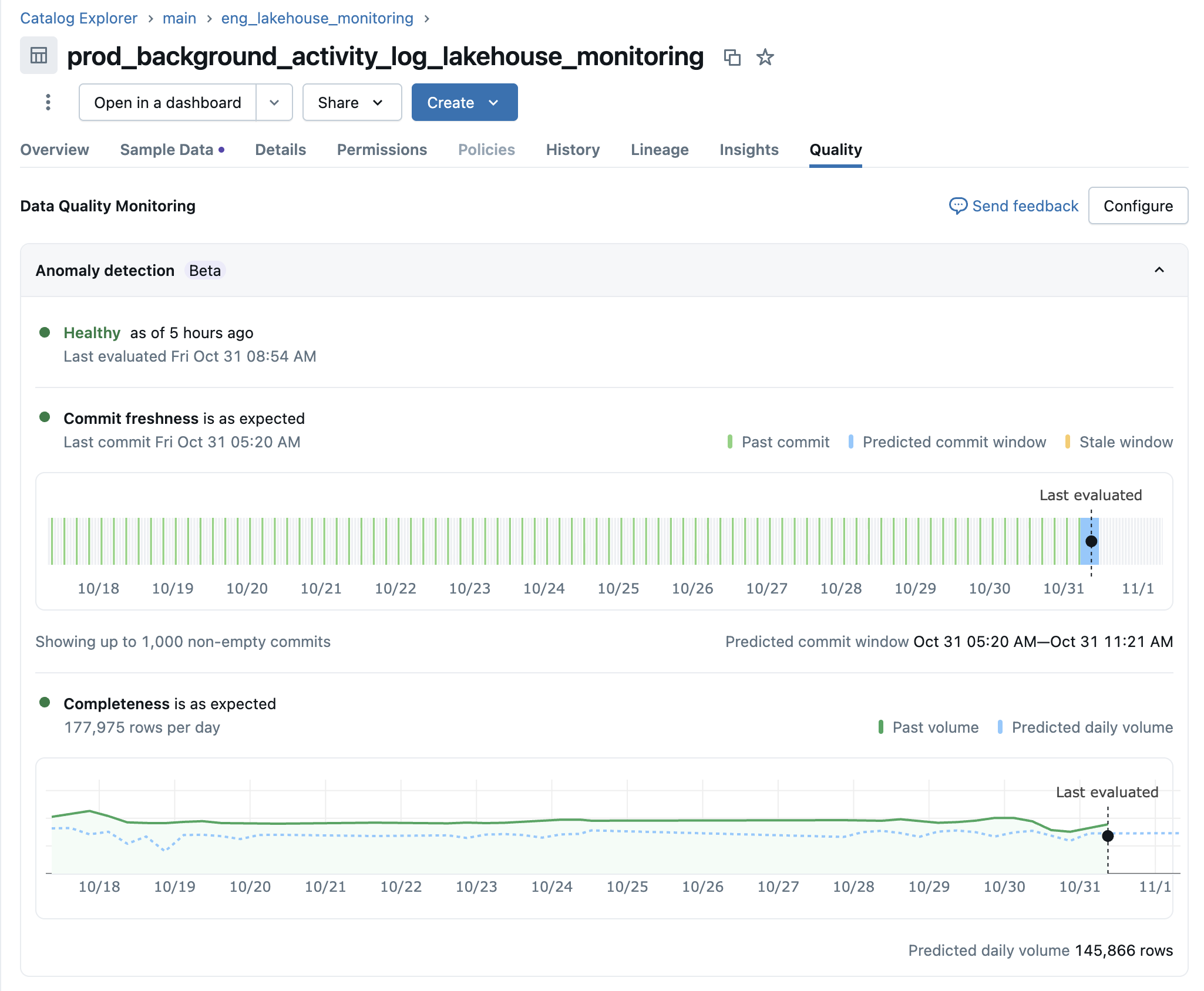
Si la tabla no superó las comprobaciones de calidad, la interfaz de usuario también muestra los trabajos ascendentes identificados como la causa raíz.
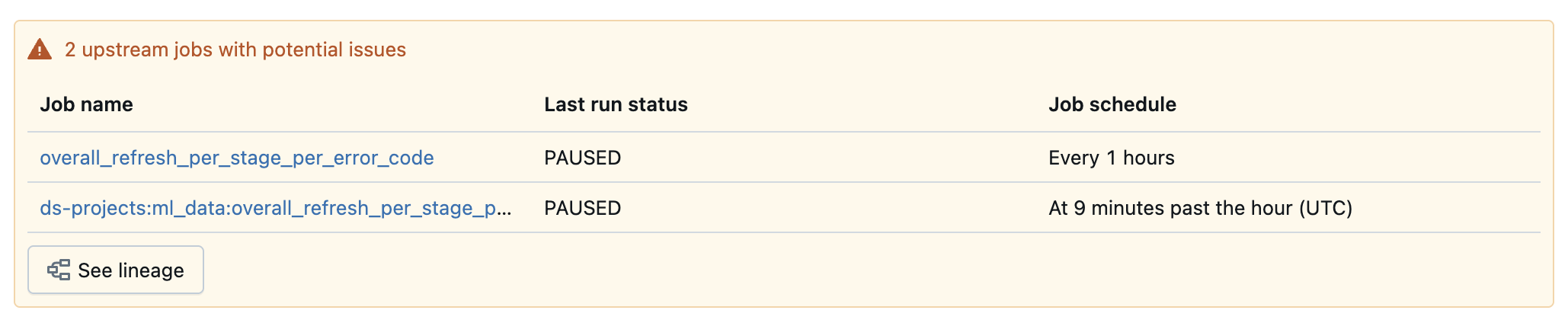
Visualización de indicadores de estado
La supervisión de la calidad de los datos proporciona a los consumidores de datos una confirmación visual rápida de la actualización de los datos de las tablas que usan.
En la página del esquema, en la pestaña Información general, las tablas que pasaron el examen de actualización más reciente se marcan con un punto verde. Las tablas que no pasaron la verificación se muestran con un punto naranja.
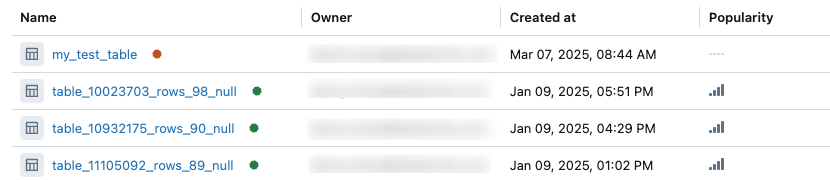
Haga clic en el punto para ver la hora y el estado del escaneo más reciente.
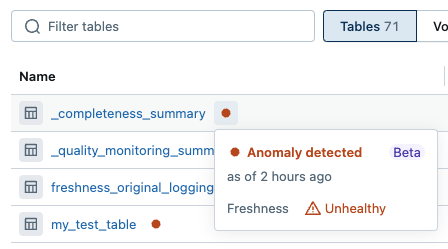
Como propietario de datos, puede evaluar fácilmente el estado general del esquema mediante la ordenación de tablas en función de la calidad. Use el menú Ordenar en la parte superior derecha de la lista de tablas para ordenar las tablas por calidad.
En la página de la tabla, en la pestaña Información general , un indicador de calidad muestra el estado de la tabla y enumera las anomalías identificadas en el examen más reciente.
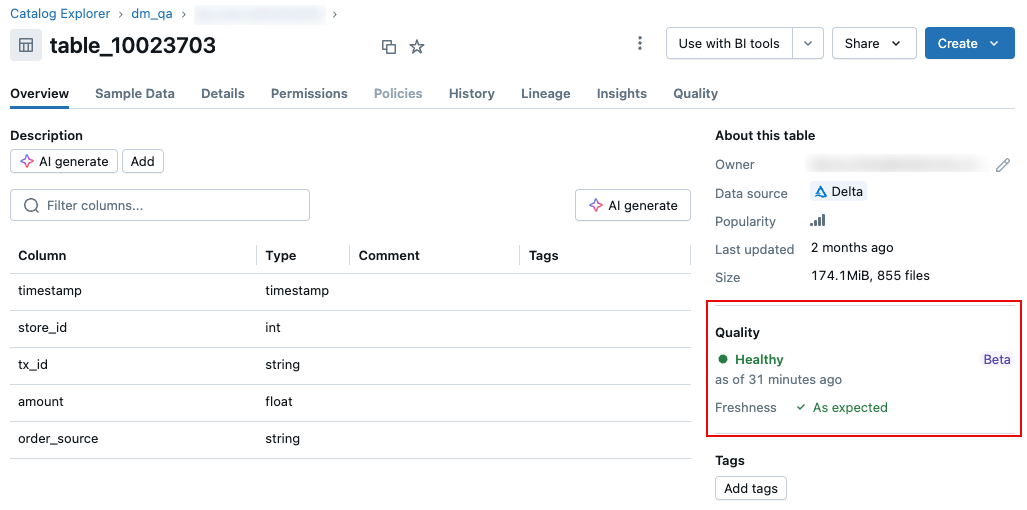
Configuración de alertas
Para configurar una alerta de SQL de Databricks en la tabla de resultados de salida, siga estos pasos en la interfaz de usuario de alertas de Databricks.
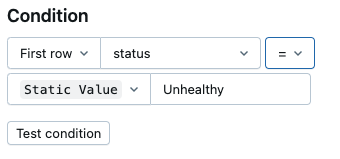
Configure la consulta de la alerta:
WITH rounded_data AS ( SELECT DATE_TRUNC('HOUR', evaluated_at) AS evaluated_at, CONCAT(catalog, ".", schema, ".", table_name) as full_table_name, table_name, status, MAX(downstream_impact.num_queries_on_affected_tables) AS impacted_queries, MAX(CASE WHEN quality_check_type = 'Freshness' AND additional_debug_info.commit_staleness.expectation IS NOT NULL THEN additional_debug_info.commit_staleness.expectation END) AS commit_expected, MAX(CASE WHEN quality_check_type = 'Freshness' AND additional_debug_info.commit_staleness.actual_value IS NOT NULL THEN additional_debug_info.commit_staleness.actual_value END) AS commit_actual, MAX(CASE WHEN quality_check_type = 'Freshness' AND additional_debug_info.event_staleness.expectation IS NOT NULL THEN additional_debug_info.event_staleness.expectation END) AS event_expected, MAX(CASE WHEN quality_check_type = 'Freshness' AND additional_debug_info.event_staleness.actual_value IS NOT NULL THEN additional_debug_info.event_staleness.actual_value END) AS event_actual, MAX(CASE WHEN quality_check_type = 'Completeness' AND additional_debug_info.daily_row_count.expectation IS NOT NULL THEN additional_debug_info.daily_row_count.expectation END) AS completeness_expected, MAX(CASE WHEN quality_check_type = 'Completeness' AND additional_debug_info.daily_row_count.actual_value IS NOT NULL THEN additional_debug_info.daily_row_count.actual_value END) AS completeness_actual FROM <catalog>.<schema>._quality_monitoring_summary GROUP BY ALL ) SELECT evaluated_at, full_table_name, status, commit_expected, commit_actual, event_expected, event_actual, completeness_expected, completeness_actual, impacted_queries, CONCAT("<link-to-dashboard>&f_table-quality-details~table-quality-details-logging-table-name=<catalog>.<schema>._quality_monitoring_summary&f_table-quality-details~9d146eba=", table_name) AS dash_link FROM rounded_data WHERE evaluated_at >= current_timestamp() - INTERVAL 6 HOUR AND -- enter the minimum number of table violations before the alert is triggered impacted_queries > <min-tables-affected> AND status = "Unhealthy"Configure la condición de alerta:
Personalice la plantilla de correo electrónico:
<h4>The following tables are failing quality checks in the last hour</h4> <table> <tr> <td> <table> <tr> <th>Table</th> <th>Expected Staleness</th> <th>Actual Staleness</th> <th>Expected Row Volume</th> <th>Actual Row Volume</th> <th>Impact (queries)</th> </tr> {{#QUERY_RESULT_ROWS}} <tr> <td><a href="{{dash_link}}">{{full_table_name}}</a></td> <td>{{commit_expected}}</td> <td>{{commit_actual}}</td> <td>{{completeness_expected}}</td> <td>{{completeness_actual}}</td> <td>{{impacted_queries}}</td> </tr> {{/QUERY_RESULT_ROWS}} </table> </td> </tr> </table>
Ahora, tiene una alerta que se desencadena en función del impacto de bajada del problema de calidad y expone un vínculo al panel para ayudarle a depurar la tabla que desencadenó la alerta.
Deshabilitar la supervisión de la calidad de los datos
Para desactivar la monitorización de la calidad de los datos, haga clic en el interruptor Supervisión de calidad de datos para desactivarla. El trabajo de supervisión de la calidad de los datos se eliminará y se eliminarán todas las tablas y la información de supervisión de la calidad de los datos.

Limitación
La supervisión de la calidad de los datos no admite lo siguiente:
- Vistas, vistas materializadas o tablas de streaming.
- La determinación de completitud no tiene en cuenta métricas como la fracción de valores null, cero o NaN.
- Indicadores de salud para la completitud
- "Backtesting" para la actualización o integridad basada en eventos
Avanzado
Revisar los resultados registrados
De forma predeterminada, los resultados de un examen de supervisión de calidad de datos se guardan en el esquema de una tabla denominada _quality_monitoring_summary en la que solo el usuario que ha habilitado la supervisión de la calidad de los datos tiene acceso. Para configurar el nombre o la ubicación de la tabla de registro, consulte Establecimiento de parámetros para la evaluación de actualización e integridad.
La tabla tiene la siguiente información:
| Nombre de la columna | Tipo | Descripción |
|---|---|---|
evaluated_at |
marca de tiempo | Hora de inicio del escaneo. |
catalog |
cuerda / cadena | Catálogo que contiene el esquema en el que se ejecutó el análisis. |
schema |
cuerda / cadena | Esquema sobre el que se ejecutó el escaneo. |
table_name |
cuerda / cadena | Nombre de la tabla escaneada. |
quality_check_type |
cuerda / cadena |
Freshness o Completeness |
status |
cuerda / cadena | Resultado de la comprobación de calidad. Uno deHealthy, Unhealthy o Unknown. Si el resultado es Unknown, consulte error_message para obtener más detalles. |
additional_debug_info |
mapa | Este campo proporciona los valores que se usaron para determinar el estado de la tabla. Para obtener más información, consulte Información de depuración. |
error_message |
cuerda / cadena | Si status es Unknown, aparece aquí información adicional para facilitar la depuración. |
table_lineage_link |
cuerda / cadena | Vínculo a la pestaña linaje de tabla en el Explorador de catálogos para ayudar a investigar la causa principal de una Unhealthy tabla. |
downstream_impact |
Estructura | Impacto de un problema de calidad de datos identificado en los activos posteriores. Para obtener más detalles, consulte la información sobre el impacto aguas abajo . |
Depurando información
En la tabla de resultados registrados, la columna additional_debug_info proporciona información con el formato siguiente:
[
<metric_name>:
actual_value: <value> ,
expectation: “actual value < [predicted_value]”
is_violated: true/false,
error_code: <error_code>
from_backtesting: true/false
...
]
Por ejemplo:
{
commit_staleness:
actual_value: "31 min"
expectation: "actual_value < 1 day"
is_violated: "false"
error_code: "None"
from_backtesting: "false"
}
Información de impacto descendente
En la tabla de resultados registrados, la columna downstream_impact es un struct con los campos siguientes:
| Campo | Tipo | Descripción |
|---|---|---|
impact_level |
Int | Valor entero entre 1 y 4 que indica la gravedad del problema de calidad de los datos. Los valores más altos indican una mayor interrupción. |
num_downstream_tables |
Int | Número de tablas descendentes que podrían verse afectadas por el problema identificado. |
num_queries_on_affected_tables |
Int | Número total de consultas a las que se ha hace referencia a las tablas afectadas y descendentes en los últimos 30 días. |
Establecer parámetros para la evaluación de frescura e integridad
Para editar los parámetros que controlan el trabajo, como la frecuencia con la que se ejecuta el trabajo o el nombre de la tabla de resultados registrados, debe editar los parámetros del trabajo en la pestaña Tareas de la página del trabajo.
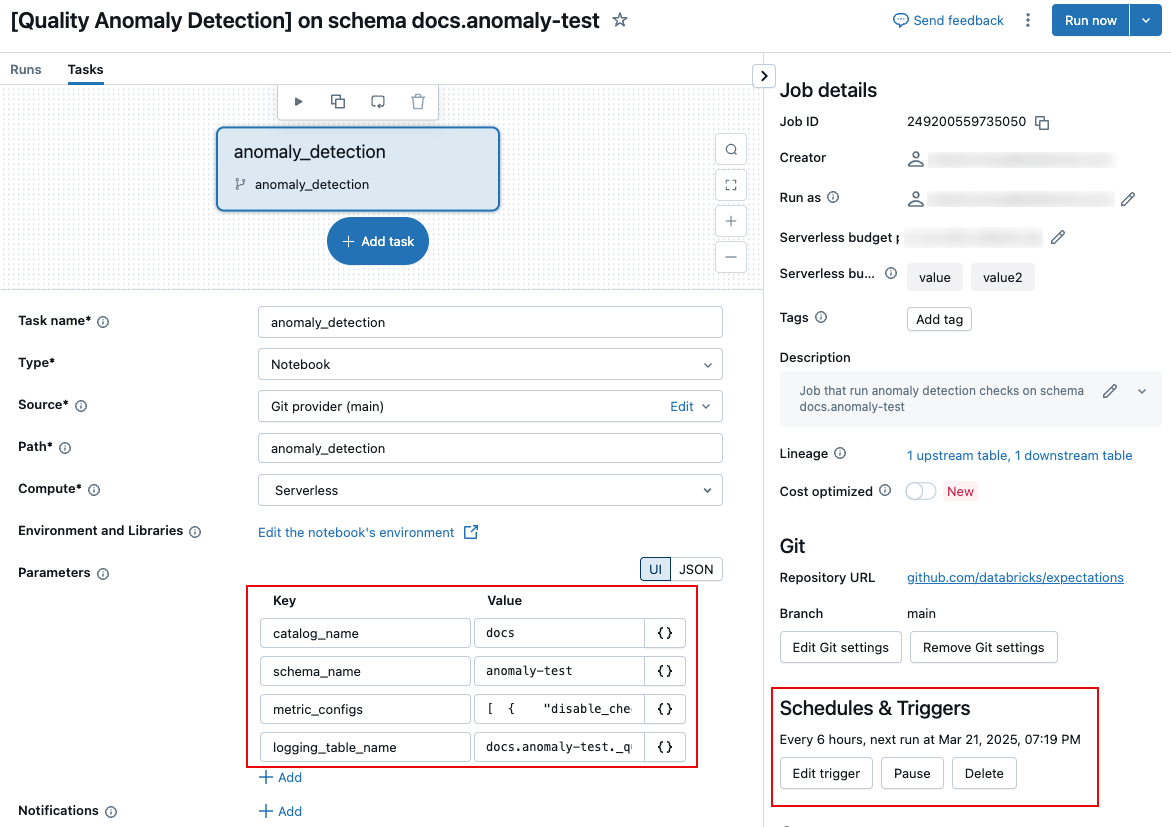
En las secciones siguientes se describe la configuración específica. Para obtener información sobre cómo establecer parámetros de tarea, vea Configurar parámetros de tarea.
Programación y notificaciones
Para personalizar la programación del trabajo o para configurar notificaciones, use la configuración Programaciones y desencadenadores en la página de trabajos. Consulta Automatización de trabajos con programaciones y desencadenadores.
Nombre de la tabla de registro
Para cambiar el nombre de la tabla de registro o guardar la tabla en un esquema diferente, edite el parámetro de tarea de trabajo logging_table_name y especifique el nombre deseado. Para guardar la tabla de registro en un esquema diferente, especifique el nombre completo de 3 niveles.
Personalización freshness y completeness evaluaciones
Todos los parámetros de esta sección son opcionales. De forma predeterminada, la supervisión de la calidad de los datos determina los umbrales en función de un análisis del historial de la tabla.
Estos parámetros son campos dentro del parámetro de tarea metric_configs. El formato de metric_configs es una cadena JSON con los siguientes valores predeterminados:
[
{
"disable_check": false,
"tables_to_skip": null,
"tables_to_scan": null,
"table_threshold_overrides": null,
"table_latency_threshold_overrides": null,
"static_table_threshold_override": null,
"event_timestamp_col_names": null,
"metric_type": "FreshnessConfig"
},
{
"disable_check": true,
"tables_to_skip": null,
"tables_to_scan": null,
"table_threshold_overrides": null,
"metric_type": "CompletenessConfig"
}
]
Los parámetros siguientes se pueden usar para las evaluaciones de freshness y completeness.
| Nombre del campo | Descripción | Ejemplo |
|---|---|---|
tables_to_scan |
Solo se examinan las tablas especificadas. | ["table_to_scan", "another_table_to_scan"] |
tables_to_skip |
Las tablas especificadas se omiten durante el examen. | ["table_to_skip"] |
disable_check |
No se realiza el escaneo. Use este parámetro si desea desactivar solo el escaneo de freshness o solo el escaneo de completeness. |
true, false |
Los parámetros siguientes solo se aplican a la evaluación de freshness:
| Nombre del campo | Descripción | Ejemplo |
|---|---|---|
event_timestamp_col_names |
Es posible que tenga una lista de tablas de columnas de marca de tiempo en el esquema. Si una tabla tiene una de estas columnas, se marca Unhealthy si se supera el valor máximo de esta columna. El uso de este parámetro puede aumentar el tiempo de evaluación y el costo. |
["timestamp", "date"] |
table_threshold_overrides |
Diccionario que consta de nombres de tabla y umbrales (en segundos) que especifican el intervalo máximo desde la última actualización de la tabla antes de marcar una tabla como Unhealthy. |
{"table_0": 86400} |
table_latency_threshold_overrides |
Diccionario que consta de nombres de tabla y umbrales de latencia (en segundos) que especifican el intervalo máximo desde la última marca de tiempo de la tabla antes de marcar una tabla como Unhealthy. |
{"table_1": 3600} |
static_table_threshold_override |
Cantidad de tiempo (en segundos) antes de que una tabla se considere una tabla estática (es decir, una que ya no se actualiza). | 2592000 |
El parámetro siguiente solo se aplica a la evaluación de completeness:
| Nombre del campo | Descripción | Ejemplo |
|---|---|---|
table_threshold_overrides |
Diccionario que consta de nombres de tabla y umbrales de volumen de fila (especificados como enteros). Si el número de filas agregadas a una tabla durante las 24 horas anteriores es menor que el umbral especificado, la tabla se marca Unhealthy. |
{"table_0": 1000} |