Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo contiene recomendaciones para implementar expectativas a escala y ejemplos de patrones avanzados admitidos por las expectativas. Estos patrones usan varios conjuntos de datos junto con las expectativas y requieren que los usuarios comprendan la sintaxis y la semántica de vistas materializadas, tablas de streaming y expectativas.
Para obtener información general básica sobre el comportamiento y la sintaxis de las expectativas, consulte Administración de la calidad de los datos con expectativas de canalización.
Expectativas portables y reutilizables
Databricks recomienda los siguientes procedimientos recomendados al implementar expectativas para mejorar la portabilidad y reducir las cargas de mantenimiento:
| Recomendación | Impacto |
|---|---|
| Almacene las definiciones de expectativas por separado de la lógica de canalización. | Aplique fácilmente expectativas a varios conjuntos de datos o canalizaciones. Actualice, audite y mantenga las expectativas sin modificar el código fuente de la canalización. |
| Agregue etiquetas personalizadas para crear grupos de expectativas relacionadas. | Filtre las expectativas en función de las etiquetas. |
| Aplique expectativas de forma coherente en conjuntos de datos similares. | Use las mismas expectativas en varios conjuntos de datos y canalizaciones para evaluar la lógica idéntica. |
En los ejemplos siguientes se muestra el uso de una tabla o diccionario delta para crear un repositorio central de expectativas. Después, las funciones personalizadas de Python aplican estas expectativas a los conjuntos de datos en una canalización de ejemplo:
Tabla delta
En el ejemplo siguiente se crea una tabla denominada rules para mantener reglas:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
En el siguiente ejemplo de Python se definen las expectativas de calidad de los datos en función de las reglas de la rules tabla. La get_rules() función lee las reglas de la rules tabla y devuelve un diccionario de Python que contiene reglas que coinciden con el tag argumento pasado a la función.
En este ejemplo, el diccionario se aplica mediante @dp.expect_all_or_drop() decoradores para imponer restricciones de calidad de datos.
Por ejemplo, los registros que produzcan errores en las reglas etiquetadas con validity se quitarán de la raw_farmers_market tabla:
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Módulo de Python
En el ejemplo siguiente se crea un módulo de Python para mantener reglas. En este ejemplo, almacene este código en un archivo denominado rules_module.py en la misma carpeta que el cuaderno usado como código fuente para la canalización:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
En el ejemplo de Python siguiente se definen las expectativas de calidad de los datos en función de las reglas definidas en el rules_module.py archivo. La get_rules() función devuelve un diccionario de Python que contiene reglas que coinciden con el tag argumento que se le pasa.
En este ejemplo, el diccionario se aplica mediante @dp.expect_all_or_drop() decoradores para imponer restricciones de calidad de datos.
Por ejemplo, los registros que produzcan errores en las reglas etiquetadas con validity se quitarán de la raw_farmers_market tabla:
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Validación del recuento de filas
En el ejemplo siguiente se valida la igualdad de recuento de filas entre table_a y table_b para comprobar que no se pierde ningún dato durante las transformaciones:
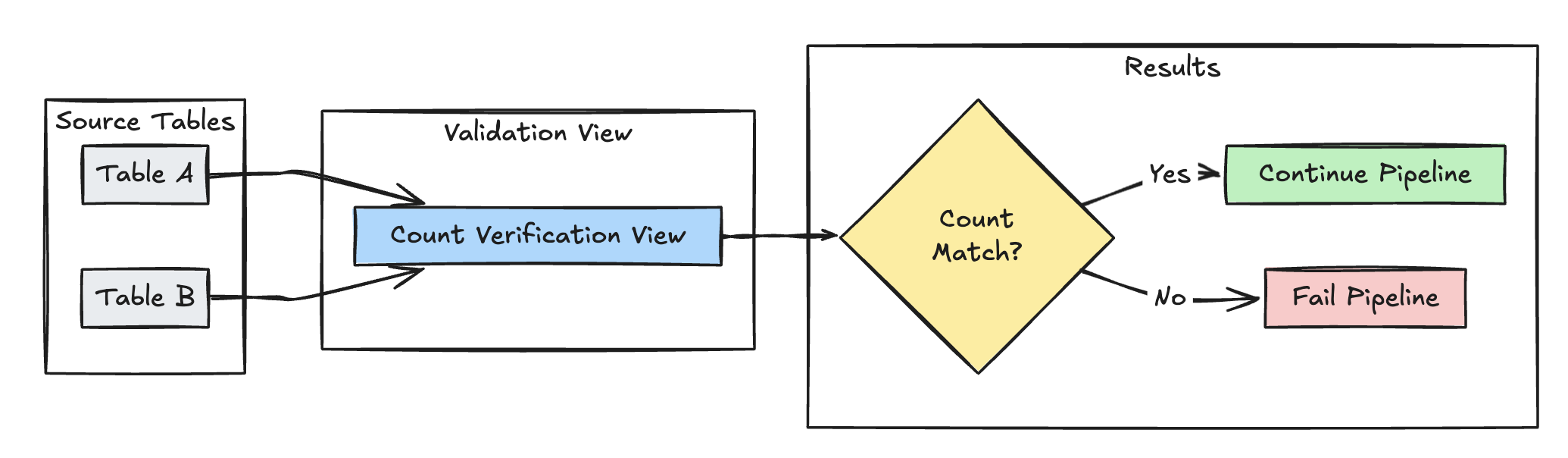
Pitón
@dp.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Detección de registros ausentes
En el ejemplo siguiente se valida que todos los registros esperados están presentes en la report tabla:
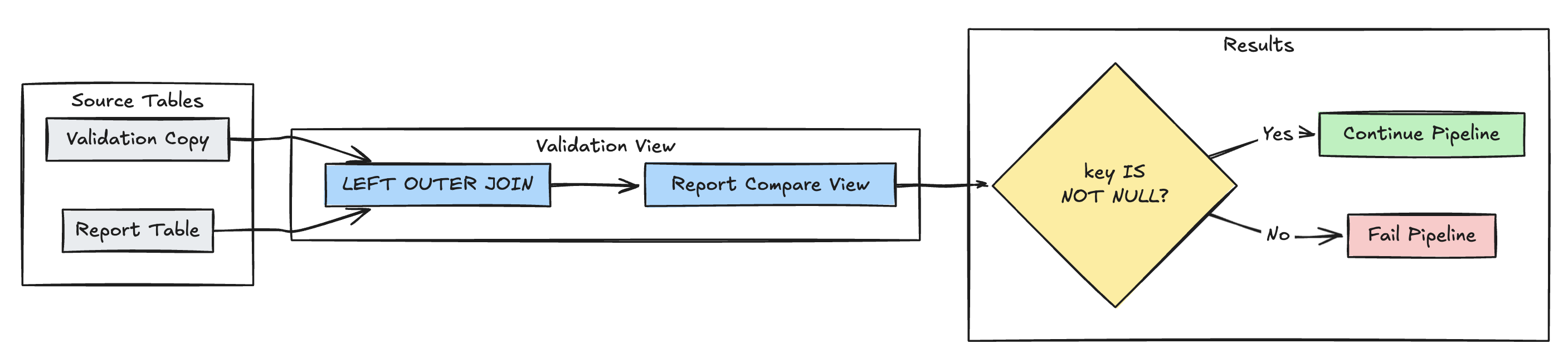
Pitón
@dp.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
Unicidad de clave principal
En el ejemplo siguiente se validan las restricciones de clave principal entre tablas:
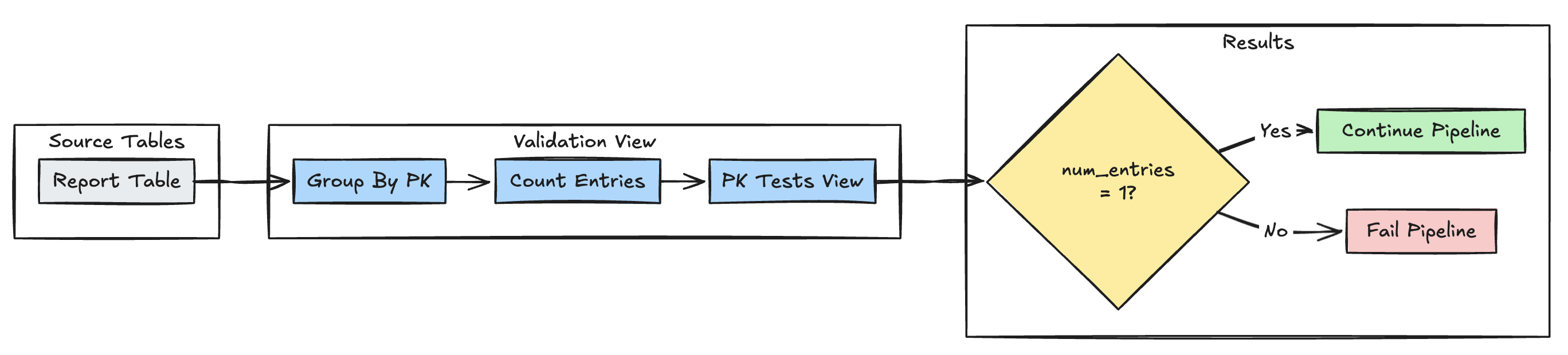
Pitón
@dp.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Patrón de evolución del esquema
En el ejemplo siguiente se muestra cómo controlar la evolución del esquema para columnas adicionales. Utiliza este patrón cuando migres fuentes de datos o manejes múltiples versiones de datos ascendentes, garantizando la compatibilidad con versiones anteriores mientras se asegura la calidad de los datos.
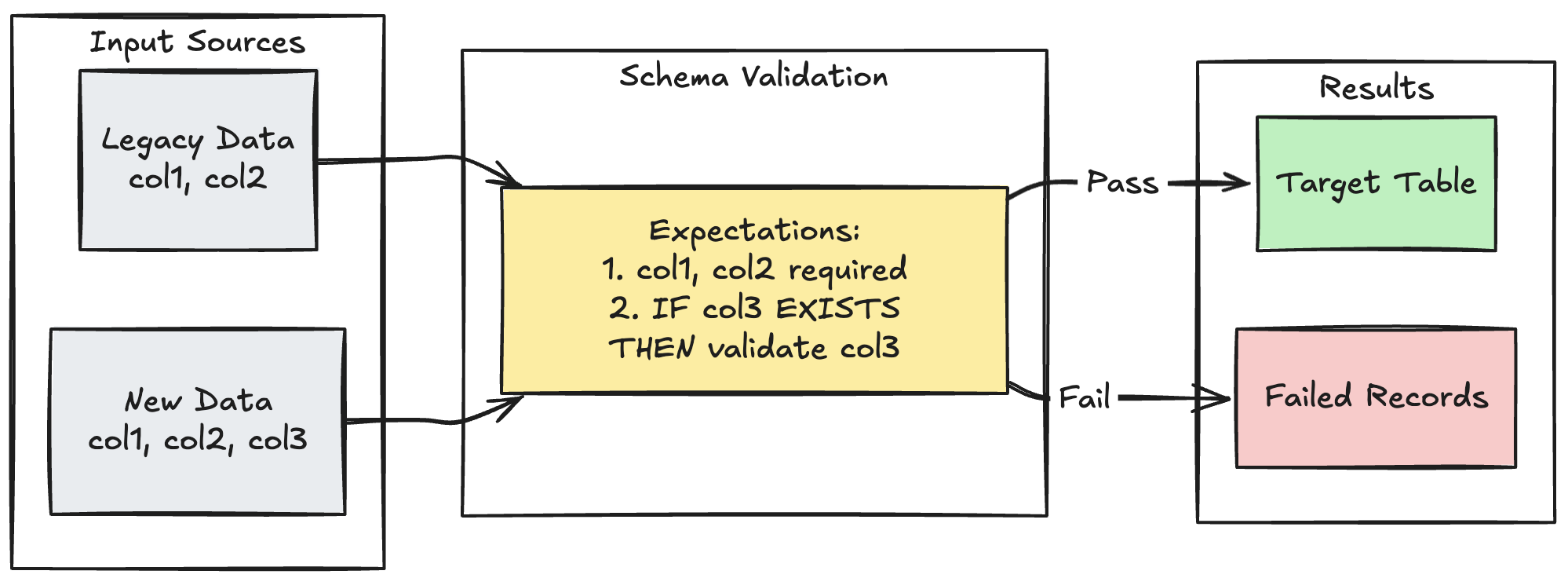
Pitón
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
Patrón de validación basado en intervalos
En el ejemplo siguiente se muestra cómo validar nuevos puntos de datos con intervalos estadísticos históricos, lo que ayuda a identificar valores atípicos y anomalías en el flujo de datos:
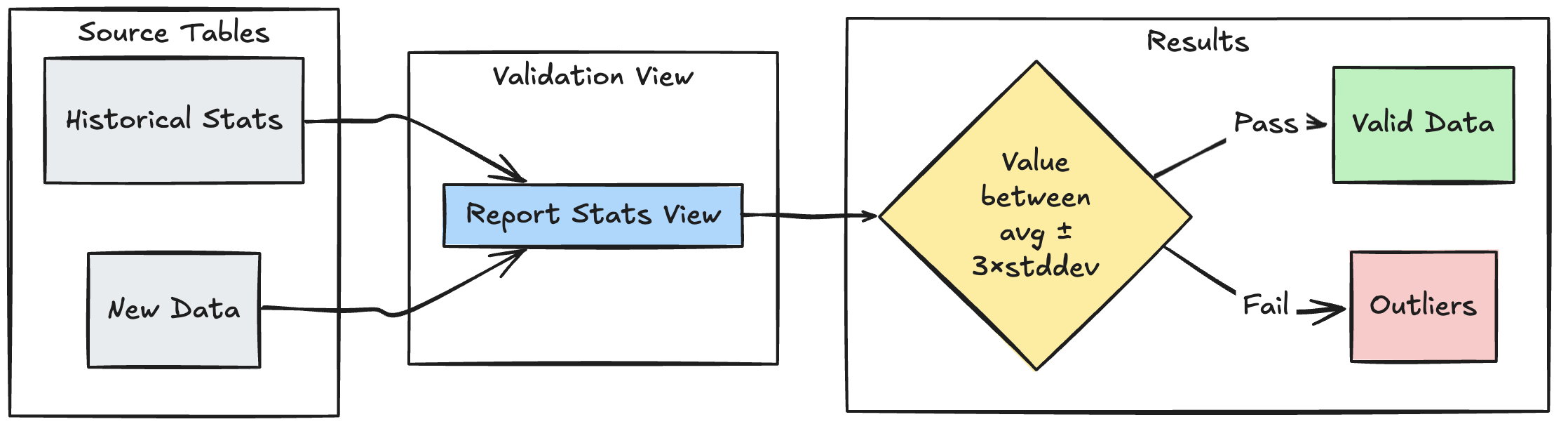
Pitón
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
Poner en cuarentena registros no válidos
Este patrón combina expectativas con tablas y vistas temporales para realizar un seguimiento de las métricas de calidad de los datos durante las actualizaciones de canalización y habilitar rutas de procesamiento independientes para registros válidos e no válidos en las operaciones de bajada.
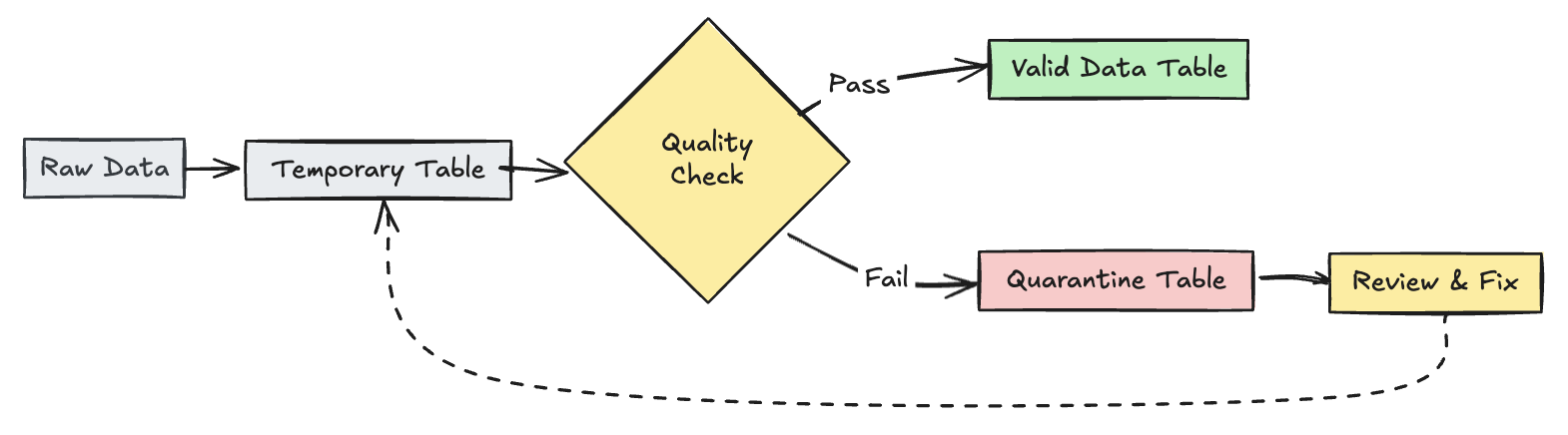
Pitón
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;