Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En la ingeniería de datos, el backfilling se refiere al proceso de procesar de manera retroactiva los datos históricos a través de una canalización de datos diseñada para procesar datos actuales o de streaming.
Normalmente, se trata de un flujo independiente que envía datos a las tablas existentes. En la ilustración siguiente se muestra un flujo de reposición que envía datos históricos a las tablas bronce de la canalización.
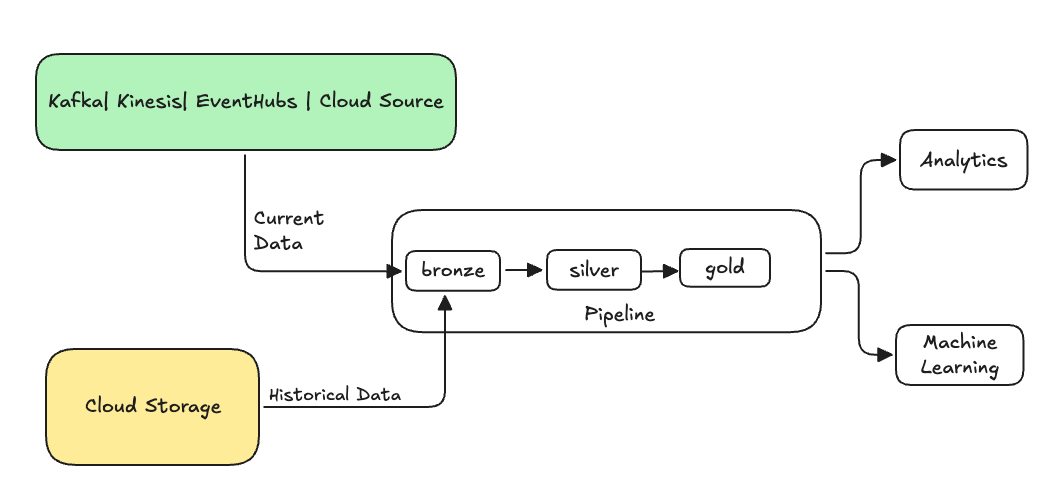
Algunos escenarios que pueden requerir un reposición:
- Procese datos históricos de un sistema heredado para entrenar un modelo de aprendizaje automático (ML) o crear un panel de análisis histórico de tendencias.
- Reprocesar un subconjunto de datos debido a un problema de calidad en las fuentes de datos ascendentes.
- Los requisitos empresariales cambiaron y necesita rerrellenar los datos durante un período de tiempo diferente que no estaba cubierto por la canalización inicial.
- La lógica de negocios ha cambiado y debe volver a procesar los datos históricos y actuales.
Se admite un relleno posterior en las canalizaciones declarativas de Lakeflow Spark con un flujo de anexión especializado que utiliza la opción ONCE. Consulte append_flow o CREATE FLOW (canalizaciones) para obtener más información sobre la ONCE opción.
Consideraciones al reponer datos históricos en una tabla de transmisión
- Normalmente, anexe los datos a la tabla de streaming bronze. Las capas de plata y oro de bajada recogerán los nuevos datos de la capa de bronce.
- Asegúrese de que la canalización puede controlar los datos duplicados correctamente en caso de que los mismos datos se anexen varias veces.
- Asegúrese de que el esquema de datos históricos es compatible con el esquema de datos actual.
- Tenga en cuenta el tamaño del volumen de datos y el Acuerdo de Nivel de Servicio de tiempo de procesamiento necesario y, en consecuencia, configure los tamaños del clúster y del lote.
Ejemplo: Adición de un relleno a una tubería existente
En este ejemplo, supongamos que tiene una canalización que ingiere datos de registro de eventos sin procesar desde un origen de almacenamiento en la nube, a partir del 1 de enero de 2025. Más adelante se da cuenta de que quiere rellenar los tres años anteriores de datos históricos para los casos de uso de informes y análisis posteriores. Todos los datos están en una ubicación, particionada por año, mes y día, en formato JSON.
Canalización inicial
Este es el código de canalización inicial que ingiere incrementalmente los datos de registro de eventos sin procesar del almacenamiento en la nube.
Pitón
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Aquí usamos la opción modifiedAfter Auto Loader para asegurarnos de que no estamos procesando todos los datos de la ubicación de almacenamiento en la nube. El procesamiento incremental se corta en ese límite.
Sugerencia
Otros orígenes de datos, como Kafka, Kinesis y Azure Event Hubs, tienen opciones de lector equivalentes para lograr el mismo comportamiento.
Reposición de datos de 3 años anteriores
Ahora quiere agregar uno o varios flujos para rellenar los datos anteriores. En este ejemplo, siga estos pasos:
- Utiliza el
append onceflujo. Esto realiza un relleno una vez sin seguir ejecutándose después de ese primer relleno. El código permanece en el flujo de trabajo y si se actualiza por completo, el llenado se vuelve a ejecutar. - Cree tres flujos de reposición, uno para cada año (en este caso, los datos se dividen por año en la ruta de acceso). Para Python, parametrizamos la creación de los flujos, pero en SQL repetimos el código tres veces, una vez para cada flujo.
Si está trabajando en un proyecto propio y no usa computación sin servidor, es posible que quiera actualizar el número máximo de trabajadores de la canalización. Aumentar el número máximo de trabajadores garantiza que tiene los recursos para procesar los datos históricos mientras continúa procesando los datos de streaming actuales dentro del SLA (Acuerdo de Nivel de Servicio) esperado.
Sugerencia
Si usa el proceso sin servidor con el escalado automático mejorado (valor predeterminado), el clúster aumenta automáticamente el tamaño cuando aumenta la carga.
Pitón
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Esta implementación resalta varios patrones importantes.
Separación de responsabilidades
- El procesamiento incremental es independiente de las operaciones de reposición.
- Cada flujo tiene su propia configuración y configuración de optimización.
- Hay una distinción clara entre las operaciones incrementales y de reposición.
Ejecución controlada
- El uso de la
ONCEopción garantiza que cada reposición se ejecute exactamente una vez. - El flujo de reposición permanece en el gráfico de canalización, pero después de completarse, se vuelve inactivo. Está listo para su uso en la actualización completa, automáticamente.
- Hay una pista de auditoría clara de las operaciones de reposición en la definición de la canalización.
Optimización del procesamiento
- Puede dividir el gran rellenado en varios rellenados más pequeños para un procesamiento más rápido o para tener control sobre el procesamiento.
- El escalado automático mejorado escala dinámicamente el tamaño del clúster en función de la carga del clúster actual.
Evolución del esquema
- Usar
schemaEvolutionMode="addNewColumns"maneja los cambios de esquema adecuadamente. - Usted dispone de una inferencia de esquema consistente en los datos históricos y actuales.
- Hay un control seguro de las nuevas columnas en los datos más recientes.