Entrenamiento de modelos de ML con la interfaz de usuario de AutoML de Azure Databricks
En este artículo se muestra cómo entrenar un modelo de Machine Learning mediante AutoML y la interfaz de usuario de Databricks Mosaic AI. La interfaz de usuario de AutoML le ayuda a entrenar modelos de clasificación, regresión o previsión en un conjunto de datos.
Consulte los requisitos para los experimentos de AutoML.
Abrir la interfaz de usuarios de AutoML
Para acceder a la interfaz de usuario de AutoML:
En la barra lateral, seleccione Nuevo > Experimento de AutoML.
También puede crear un nuevo experimento de AutoML desde la página Experimentos.
Aparece la página Configurar experimento de AutoML. En esta página hay que configurar el proceso de AutoML, especificando el conjunto de datos, el tipo de problema, la columna de destino o de etiqueta que se va a predecir, la métrica que se va a usar para evaluar y puntuar las ejecuciones del experimento, y las condiciones de detención.
Configuración de problemas de clasificación o de regresión
Puede configurar un problema de clasificación o regresión mediante la interfaz de usuario de AutoML con los pasos siguientes:
En el campo Proceso, seleccione un clúster que ejecute Databricks Runtime ML.
En el menú desplegable Tipo de problema de ML, seleccione Regresión o Clasificación. Si está intentando predecir un valor numérico continuo para cada observación, como los ingresos anuales, seleccione regresión. Si está intentando asignar cada observación a un valor de un conjunto discreto de clases, como el buen o mal riesgo de crédito, seleccione clasificación.
En Conjunto de datos, seleccione Examinar.
Vaya a la tabla que desea usar y haga clic en Seleccionar. Aparece el esquema de tabla.
- Tanto en Databricks Runtime 10.3 ML como en las versiones posteriores, se puede especificar qué columnas debe usar AutoML para el entrenamiento. No se puede quitar la columna seleccionada como destino de predicción ni la columna de tiempo para dividir los datos.
- Tanto en Databricks Runtime 10.4 LTS ML como en las versiones superiores, puede especificar cómo se imputan los valores null seleccionando la opción deseada en la lista desplegable Imputar con. De forma predeterminada, AutoML selecciona un método de imputación basado en el tipo de columna y el contenido.
Nota:
Si elige un método de imputación distinto del predeterminado, AutoML no realiza la detección de tipos semánticos.
Haga clic en el campo Destino de predicción. Aparece una lista desplegable con las columnas que se muestran en el esquema. Seleccione la columna en la que quiere que el modelo haga la predicción.
El campo Nombre del experimento muestra el nombre predeterminado. Para cambiarlo, escriba el nuevo nombre en el campo.
También puede:
- Especificar opciones de configuración adicionales.
- Usar tablas de características existentes en el Almacén de características para aumentar el conjunto de datos de entrada original.
Configuración de problemas de previsión
Puede configurar un problema de previsión mediante la interfaz de usuario de AutoML con los pasos siguientes:
En el campo Proceso, seleccione un clúster que ejecute Databricks Runtime 10.0 ML o posterior.
En el menú desplegable Tipo de problema de ML, seleccione Previsión.
En Conjunto de datos, haga clic en Examinar. Vaya a la tabla que desea usar y haga clic en Seleccionar. Aparece el esquema de tabla.
Haga clic en el campo Destino de predicción. Aparece un menú desplegable con las columnas que se muestran en el esquema. Seleccione la columna en la que quiere que el modelo haga la predicción.
Haga clic en el campo Columna de tiempo. Aparece una lista desplegable que muestra las columnas del conjunto de datos que son de tipo
timestampodate. Seleccione la columna que contiene los períodos de tiempo de la serie temporal.Para la previsión de varias series, seleccione la/s columna/s que identifican la serie temporal individual, en la lista desplegable Identificadores de serie temporal. AutoML agrupa los datos por estas columnas como series temporales diferentes, y entrena un modelo para cada serie de forma independiente. Si deja este campo en blanco, AutoML asume que el conjunto de datos contiene una única serie temporal.
En los campos Horizonte de previsión y Frecuencia, especifique el número de períodos de tiempo en el futuro para los que AutoML debe calcular los valores previstos. En el cuadro izquierdo, escriba el número entero de períodos en los que hacer la previsión. En el cuadro derecho, seleccione las unidades.
Nota:
Para usar Auto-ARIMA, la serie temporal debe tener una frecuencia regular, en la que el intervalo entre dos puntos cualesquiera debe ser el mismo en toda la serie temporal. La frecuencia debe coincidir con la unidad de frecuencia especificada en la llamada API o en la UI de AutoML. AutoML controla los pasos de tiempo que faltan, rellenando esos valores con el valor anterior.
En Databricks Runtime 11.3 LTS ML y versiones posteriores, puedes guardar los resultados de la predicción. Para ello, especifique una base de datos en el campo Base de datos de salida. Haga clic en Examinar y seleccione una base de datos en el cuadro de diálogo. AutoML escribe los resultados de predicción en una tabla de esta base de datos.
El campo Nombre del experimento muestra el nombre predeterminado. Para cambiarlo, escriba el nuevo nombre en el campo.
También puede:
- Especificar opciones de configuración adicionales.
- Usar tablas de características existentes en el Almacén de características para aumentar el conjunto de datos de entrada original.
Uso de tablas de características existentes del Almacén de características de Databricks
En Databricks Runtime 11.3 LTS ML y versiones posteriores, puede usar tablas de características en el Almacén de características de Databricks para expandir el conjunto de datos de entrenamiento de entrada para los problemas de clasificación y regresión.
Tanto en Databricks Runtime 12.2 LTS ML como en las versiones posteriores, se pueden usar tablas de características en Databricks Feature Store para expandir el conjunto de datos de entrenamiento de entrada para todos los problemas de AutoML: clasificación, regresión y previsión.
Para crear una tabla de características, consulte Crear una tabla de características en Unity Catalog o Crear una tabla de características en Databricks Feature Store.
Después de configurar el experimento de AutoML, siga los pasos que se indican a continuación para seleccionar una tabla de características:
Haga clic en Combinar características (opcional).
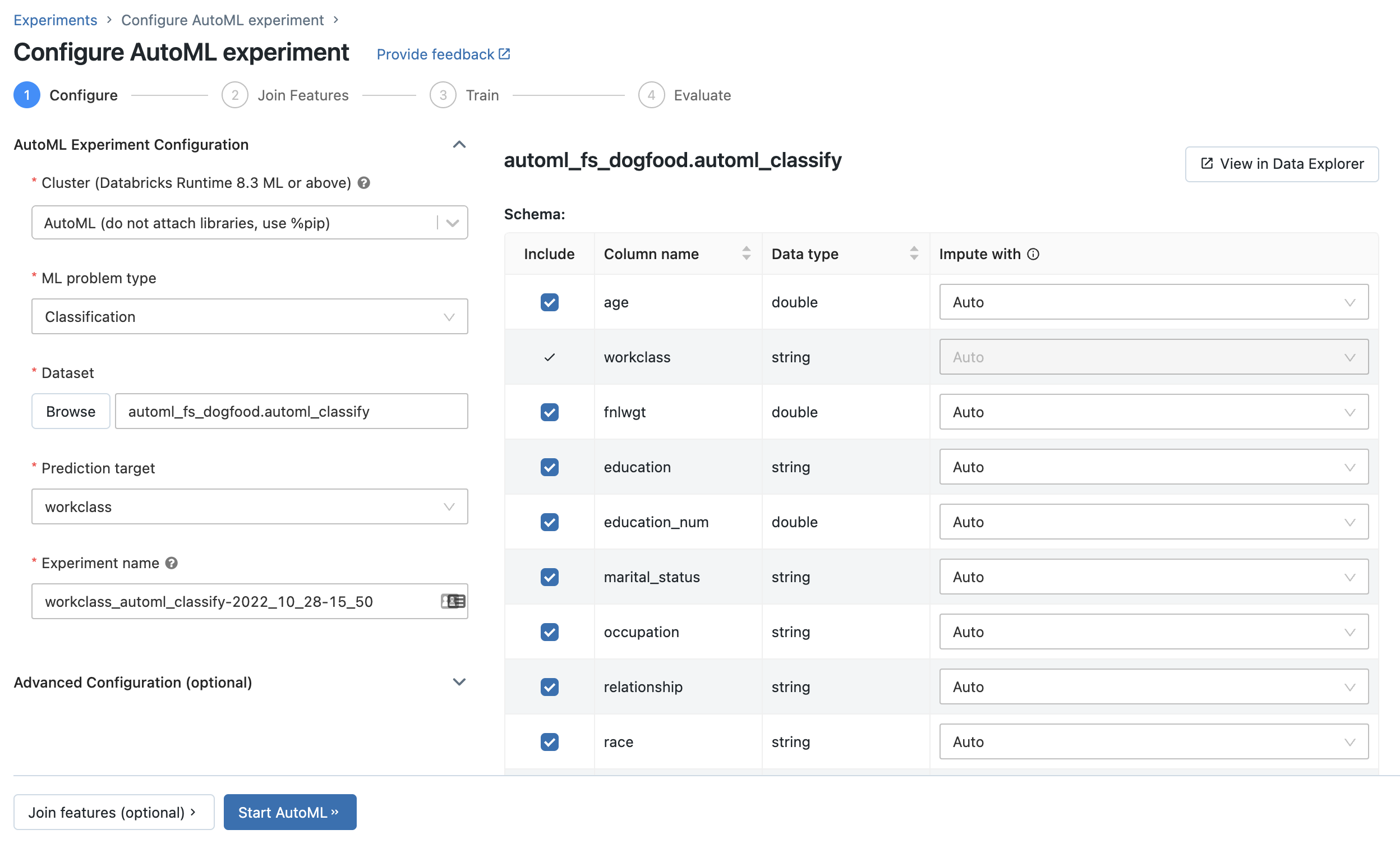
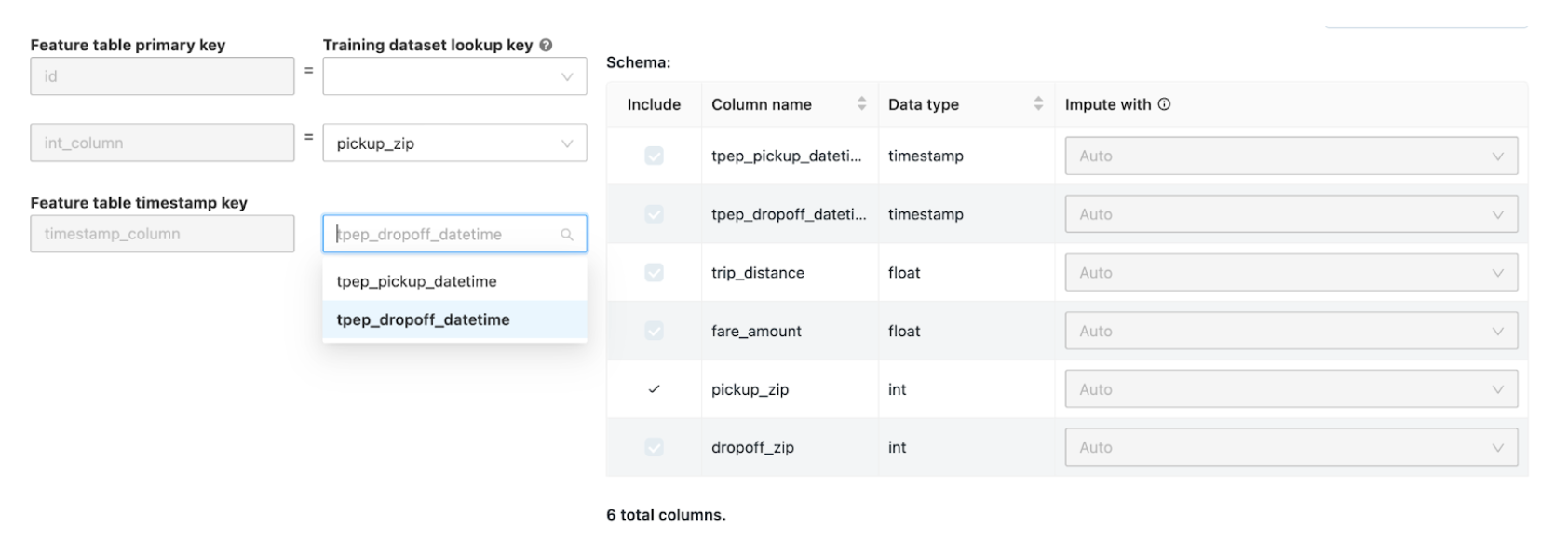
En la página Combinar características adicionales, seleccione una tabla de características en el campo Tabla de características.
Para cada clave principal de la tabla de características, seleccione la clave de búsqueda correspondiente. La clave de búsqueda debe ser una columna del conjunto de datos de entrenamiento que proporcionó para el experimento de AutoML.
Para las tablas de características de serie temporal, seleccione la clave de búsqueda de marca de tiempo correspondiente. Del mismo modo, la clave de búsqueda de marca de tiempo debe ser una columna del conjunto de datos de entrenamiento que proporcionó para el experimento de AutoML.
Para agregar más tablas de características, haga clic en Agregar otra tabla y repita los pasos anteriores.
Configuraciones avanzadas
Abra la sección Configuración avanzada (opcional) para acceder a estos parámetros.
- La métrica de evaluación es la métrica principal que se usa para puntuar las ejecuciones.
- En Databricks Runtime 10.4 LTS ML y posteriores, puedes excluir los marcos de entrenamiento de esta consideración. De manera predeterminada, AutoML entrena modelos mediante marcos enumerados en Algoritmos de AutoML.
- Puede editar las condiciones de detención. Las condiciones de detención predeterminadas son:
- Para los experimentos de previsión, se detiene al llegar a 120 minutos.
- En Databricks Runtime 10.4 LTS ML y versiones anteriores, para los experimentos de clasificación y regresión, se detiene al llegar a 60 minutos o después de completar 200 pruebas, lo que ocurra antes. Para Databricks Runtime 11.0 ML y versiones posteriores, el número de pruebas no se usa como condición de detención.
- En Databricks Runtime 10.4 LTS ML y posteriores, para los experimentos de clasificación y regresión, AutoML incorpora la detención temprana; detiene el entrenamiento y el ajuste de los modelos si la métrica de validación ya no mejora.
- En Databricks Runtime 10.4 LTS ML y posteriores, puedes seleccionar una columna de tiempo a fin de dividir los datos para el entrenamiento, la validación y las pruebas en orden cronológico (solo se aplica a la clasificación y regresión).
- Databricks recomienda no rellenar el campo Directorio de datos. Al hacerlo, se desencadena el comportamiento predeterminado de almacenar de forma segura el conjunto de datos como si fuera un artefacto de MLflow. Se puede especificar una ruta de acceso DBFS, pero en este caso, el conjunto de datos no hereda los permisos de acceso del experimento de AutoML.
Ejecución del experimento y comprobación de los resultados
Para iniciar el experimento de AutoML, haga clic en Iniciar AutoML. El experimento comienza a ejecutarse, y aparece la página de entrenamiento de AutoML. Para actualizar la tabla de ejecuciones, haga clic en el  .
.
En esta página puede realizar las siguientes acciones:
- Detener el experimento en cualquier momento.
- Abrir el cuaderno de exploración de datos.
- Supervisar las ejecuciones.
- Ir a la página de ejecución de cualquier ejecución.
Con Databricks Runtime 10.1 ML y posteriores, AutoML muestra advertencias de posibles problemas con el conjunto de datos, como tipos de columna no admitidos o columnas de cardinalidad alta.
Nota:
Databricks hace todo lo posible para indicar posibles errores o problemas. Sin embargo, es posible que la operación no sea exhaustiva y que no capture los problemas o errores que el usuario pueda estar buscando.
Para ver las advertencias del conjunto de datos, haga clic en la pestaña Advertencias de la página de entrenamiento, o bien en la página del experimento cuando esté completo.
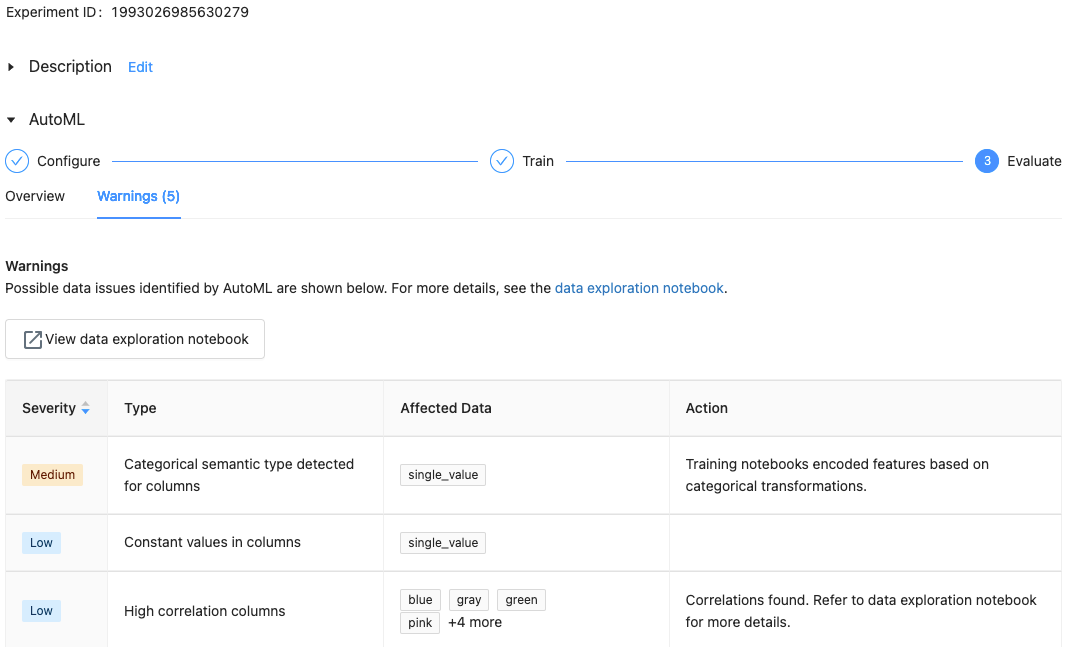
Una vez completado el experimento, puede hacer lo siguiente:
- Registre e implemente uno de los modelos con MLflow.
- Seleccione Ver cuaderno del mejor modelo. Ahí podrá revisar y editar el cuaderno que creó el mejor modelo.
- Seleccione Ver cuaderno de exploración de datos para abrir el cuaderno de exploración de datos.
- Busque, filtre y organice las ejecuciones en la tabla de ejecuciones.
- Consulte los detalles de cualquier ejecución:
- El cuaderno generado que contiene el código fuente de una ejecución de prueba se puede encontrar haciendo clic en la ejecución de MLflow. El cuaderno se guarda en la sección Artefactos de la página de ejecución. Puede descargar este cuaderno e importarlo en el área de trabajo, si los administradores del área de trabajo han habilitado la descarga de artefactos.
- Para ver los resultados de la ejecución, haga clic en la columna Modelos o en la columna Hora de inicio. Aparece la página de ejecución, que muestra información sobre la ejecución de prueba (como parámetros, métricas y etiquetas) y los artefactos creados por la ejecución, incluido el modelo. Esta página también incluye fragmentos de código que puede usar para realizar predicciones con el modelo.
Para volver a este experimento de AutoML más adelante, puede ir a la tabla de la página Experimentos. Los resultados de cada experimento de AutoML, incluidos los cuadernos de entrenamiento y de exploración de datos, se almacenan en una carpeta databricks_automl de la carpeta particular del usuario que ejecutó el experimento.
Registro e implementación de un modelo
Puede registrar e implementar el modelo con la interfaz de usuario de AutoML:
- Seleccione el vínculo de la columna Modelos para el modelo que se registrará. Cuando se completa una ejecución, en la primera fila está el mejor modelo (basado en la métrica principal).
- Seleccione el
 para registrar el modelo en Registro de modelos.
para registrar el modelo en Registro de modelos. - Seleccione
 Modelos en la barra lateral, para ir al Registro de modelos.
Modelos en la barra lateral, para ir al Registro de modelos. - Seleccione el nombre del modelo en la tabla de modelos.
- En la página del modelo registrado, puede servir el modelo con Servicio de modelos.
No hay ningún módulo denominado pandas.core.indexes.numeric
Al atender un modelo compilado mediante AutoML con el servicio de modelos, puede obtener este error: No module named 'pandas.core.indexes.numeric.
Esto se debe a una versión de pandas incompatible entre AutoML y el entorno de punto de conexión del servicio de modelos. Para resolver este error, ejecute el script add-pandas-dependency.py. El script edita requirements.txt y conda.yaml para que el modelo registrado incluya la versión de dependencia pandas adecuada: pandas==1.5.3
- Modifique el script para incluir el
run_idde la ejecución de MLflow donde se ha registrado el modelo. - Vuelva a registrar el modelo en el registro del modelo de MLflow.
- Pruebe a servir la nueva versión del modelo de MLflow.