Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
CI/CD (integración continua y entrega continua) se refiere a un proceso automatizado para desarrollar, implementar, supervisar y mantener las aplicaciones. Al automatizar la creación, las pruebas y la implementación de código, los equipos de desarrollo son capaces de entregar versiones con mayor frecuencia y fiabilidad que los procesos más manuales que siguen siendo frecuentes en muchos equipos de ingeniería y ciencia de datos. CI/CD para el aprendizaje automático reúne técnicas de MLOps, DataOps, ModelOps y DevOps.
En este artículo, se describe cómo Databricks usa CI/CD para soluciones de aprendizaje automático. En las aplicaciones de aprendizaje automático, CI/CD no solo es importante para los recursos de código, sino que también se aplica a las canalizaciones de datos, incluidos los datos de entrada y los resultados generados por el modelo.
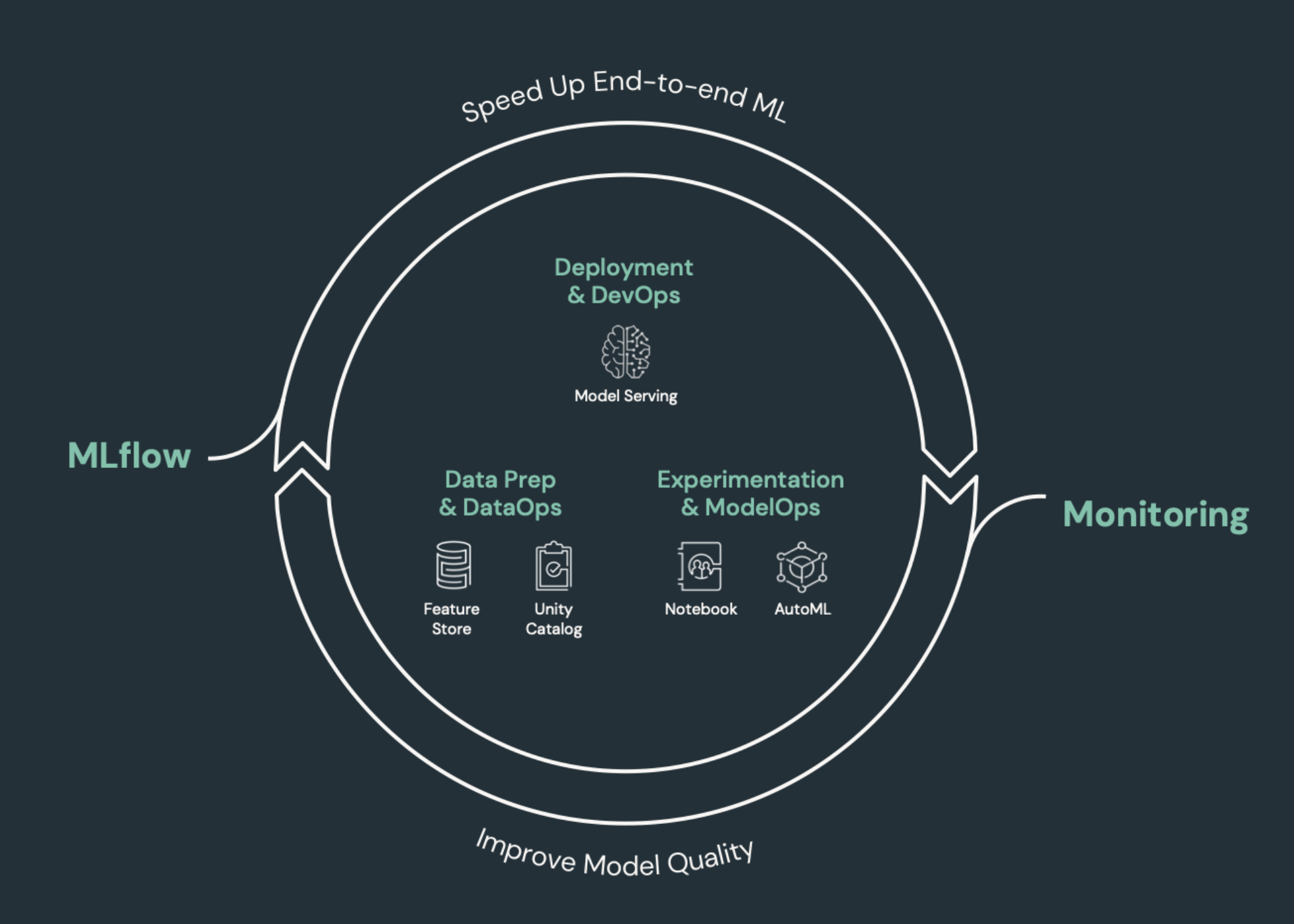
Elementos de aprendizaje automático que necesitan CI/CD
Uno de los desafíos del desarrollo de ML es que los distintos equipos son responsables de diferentes partes del proceso. Los equipos puede depender de diferentes herramientas y tener diferentes programaciones de lanzamiento de versiones. Azure Databricks proporciona una única plataforma de aprendizaje automático y datos unificados con herramientas integradas para mejorar la eficacia de los equipos y garantizar la coherencia y repetibilidad de las canalizaciones de datos y aprendizaje automático.
En general, en las tareas de aprendizaje automático, se debe realizar un seguimiento de lo siguiente en un flujo de trabajo automatizado de CI/CD:
- Datos de entrenamiento, incluida la calidad de los datos, cambios en el esquema y cambios de distribución
- Canalizaciones de datos de entrada
- Código para el entrenamiento, validación y entrega del modelo
- Predicciones y rendimiento del modelo
Integración de Databricks en los procesos de CI/CD
MLOps, DataOps, ModelOps y DevOps hacen referencia a la integración de procesos de desarrollo con "operaciones", lo que hace que los procesos y la infraestructura sean predecibles y confiables. En este conjunto de artículos, se describe cómo integrar los principios de operaciones (“ops”) en los flujos de trabajo de ML en la plataforma de Databricks.
Databricks incorpora todos los componentes necesarios para el ciclo de vida de ML, incluidas las herramientas para compilar “la configuración como código”, a fin de garantizar la reproducibilidad y “la infraestructura como código” para automatizar el aprovisionamiento de servicios en la nube. También incluye servicios de registro y de alertas para ayudarle a detectar y solucionar problemas cuando se producen.
DataOps: datos confiables y seguros
Los buenos modelos de aprendizaje automático dependen de canalizaciones de datos e infraestructura confiables. Con Databricks Data Intelligence Platform, toda la canalización de datos, desde la ingesta de datos hasta las salidas del modelo entregado, se encuentra en una sola plataforma y usa el mismo conjunto de herramientas, lo que facilita la productividad, la reproducibilidad, el uso compartido y la solución de problemas.

Tareas y herramientas de DataOps en Databricks
En la tabla, se enumeran las tareas y herramientas comunes de DataOps en Databricks:
| Tarea de DataOps | Herramienta en Databricks |
|---|---|
| Ingesta y transformación de datos | Cargador automático y Apache Spark |
| Seguimiento de los cambios en los datos, incluidos el control de versiones y el linaje | Tablas delta |
| Compilación, administración y supervisión de canalizaciones de procesamiento de datos | Pipelines declarativas de Lakeflow |
| Garantizar la seguridad y la gobernanza de los datos | Catálogo de Unity |
| Análisis de datos exploratorios y paneles | Databricks SQL, Paneles y Cuadernos de Databricks |
| Codificación general | Databricks SQL y Cuadernos de Databricks |
| Programación de canalizaciones de datos | Trabajos de Lakeflow |
| Automatización de flujos de trabajo generales | Trabajos de Lakeflow |
| Creación, almacenamiento, administración y descubrimiento de características para el entrenamiento de modelos | Almacén de características de Databricks |
| Supervisión de datos | Supervisión del almacén de lago de datos |
ModelOps: desarrollo y ciclo de vida de modelos
El desarrollo de un modelo requiere una serie de experimentos y una manera de realizar un seguimiento para comparar las condiciones y los resultados de esos experimentos. Databricks Data Intelligence Platform incluye MLflow para el seguimiento del desarrollo de modelos y MLflow Model Registry para administrar el ciclo de vida del modelo, incluidos el almacenamiento provisional, la entrega y el almacenamiento de los artefactos del modelo.
Después de lanzar un modelo en producción, pueden cambiar muchos aspectos que podrían afectar a su rendimiento. Además de supervisar el rendimiento de la predicción del modelo, también debe supervisar los datos de entrada de los cambios en las características estadísticas o de calidad que podrían requerir volver a entrenar el modelo.
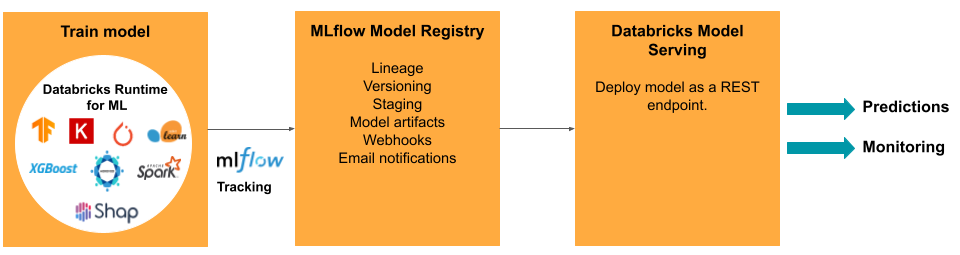
Tareas y herramientas de ModelOps en Databricks
En la tabla, se enumeran las herramientas y tareas comunes de ModelOps proporcionadas por Databricks:
| Tarea de ModelOps | Herramienta en Databricks |
|---|---|
| Seguimiento del desarrollo de modelos | Seguimiento de modelos de MLflow |
| Administración del ciclo de vida de un modelo | Modelos en el catálogo de Unity |
| Control de versiones y uso compartido del código de modelo | Carpetas de Git de Databricks |
| Desarrollo de modelos sin código | AutoML |
| Supervisión de modelos | Supervisión del almacén de lago de datos |
DevOps: producción y automatización
La plataforma Databricks admite modelos de aprendizaje automático en producción con lo siguiente:
- Linaje de modelos y datos de un extremo a otro: desde modelos de producción hasta el origen de datos sin procesar, en la misma plataforma.
- Entrega de modelos de nivel de producción: con escala o reducción vertical automática en función de las necesidades empresariales.
- Trabajos: automatiza los trabajos y crea flujos de trabajo de aprendizaje automático programados.
- Carpetas de Git: el control de versiones de código y el uso compartido del área de trabajo también ayudan a los equipos a seguir los procedimientos recomendados de ingeniería de software.
- Conjuntos de recursos de Databricks: automatiza la creación e implementación de recursos de Databricks, como trabajos, modelos registrados y puntos de conexión de servicio.
- Proveedor de Terraform de Databricks: automatiza la infraestructura de implementación en nubes para trabajos de inferencia de ML, servicios de puntos de conexión y trabajos de caracterización.
Servicio de modelos
Para implementar modelos en producción, MLflow simplifica significativamente el proceso, lo que proporciona una implementación de un solo clic como trabajo por lotes para grandes cantidades de datos o como punto de conexión de REST en un clúster de escalado automático. La integración de la tienda de características de Databricks con MLflow también garantiza la coherencia de las características para el entrenamiento y la entrega. Además, los modelos de MLflow pueden buscar automáticamente características de la tienda, incluso para la entrega de baja latencia en línea.
La plataforma de Databricks admite muchas opciones de implementación de modelos:
- Código y contenedores.
- Servicio por lotes.
- Entrega de baja latencia en línea
- Servicio en el dispositivo perimetral.
- Nubes múltiples, por ejemplo, entrenamiento del modelo en una nube e implementación en otra
Para obtener más información, consulte Mosaic AI Model Serving.
Trabajos
Los trabajos de Lakeflow permiten automatizar y programar cualquier tipo de carga de trabajo, desde ETL a ML. Databricks también admite integraciones con orquestadores de terceros populares como Airflow.
Carpetas Git
La plataforma de Databricks incluye compatibilidad con Git en el área de trabajo para ayudar a los equipos a seguir los procedimientos recomendados de ingeniería de software mediante la realización de operaciones de Git a través de la interfaz de usuario. Los administradores y los ingenieros de DevOps pueden usar la API para configurar la automatización con sus herramientas favoritas de CI/CD. Databricks admite cualquier tipo de implementación de Git, incluidas las redes privadas.
Para más información sobre los procedimientos recomendados para el desarrollo de código mediante carpetas de Git de Databricks, consulte Flujos de trabajo de CI/CD con la integración de Git y carpetas de Git de Databricks y Uso de CI/CD. Estas técnicas, junto con la API de REST de Databricks, permiten desarrollar procesos de implementación automatizados con Acciones de GitHub, canalizaciones de Azure DevOps o trabajos de Jenkins.
Unity Catalog para la gobernanza y la seguridad
La plataforma de Databricks incluye unity Catalog, que permite a los administradores configurar el control de acceso, las directivas de seguridad y la gobernanza de todos los datos y recursos de inteligencia artificial en Databricks.