Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describen dos patrones comunes para mover artefactos de ML a través del almacenamiento provisional y a producción. La naturaleza asincrónica de los cambios en los modelos y el código significa que hay varios patrones posibles que puede seguir un proceso de desarrollo de ML.
Los modelos se crean mediante código, pero los artefactos del modelo resultantes y el código que los creó pueden funcionar de forma asincrónica. Es decir, es posible que las nuevas versiones del modelo y los cambios de código no se produzcan al mismo tiempo. Por ejemplo, considere los siguientes escenarios:
- Para detectar transacciones fraudulentas, desarrollas una canalización de ML que vuelve a entrenar un modelo semanalmente. Es posible que el código no cambie con mucha frecuencia, pero el modelo se puede volver a entrenar cada semana para incorporar nuevos datos.
- Puede crear una red neuronal grande y profunda para clasificar documentos. En ese caso, el entrenamiento del modelo es costoso y lento a nivel computacional, y es probable que el modelo se vuelva a entrenar con poca frecuencia. Sin embargo, el código que implementa, sirve y supervisa este modelo se puede actualizar sin volver a entrenar el modelo.
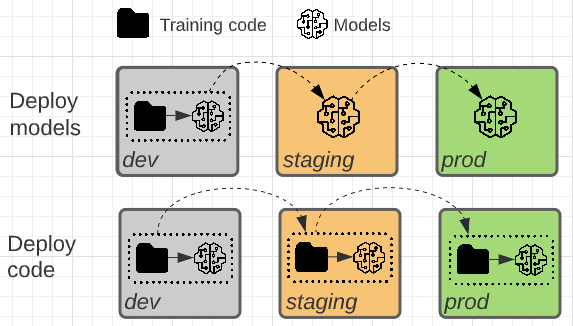
Los dos patrones difieren en si el artefacto del modelo o el código de entrenamiento que genera el artefacto del modelo se promueve hacia la producción.
Implementación de código (recomendado)
En la mayoría de los casos, Databricks recomienda el enfoque de "implementación de código". Este enfoque se incorpora al flujo de trabajo de MLOps recomendado.
En este patrón, el código para entrenar modelos se desarrolla en el entorno de desarrollo. El mismo código se mueve a preproducción y, a continuación, a producción. El modelo se entrena en cada entorno: inicialmente en el entorno de desarrollo como parte del desarrollo del modelo, en el almacenamiento provisional (en un subconjunto limitado de datos) como parte de las pruebas de integración y en el entorno de producción (en los datos de producción completos) para generar el modelo final.
Ventajas:
- En las organizaciones en las que se restringe el acceso a los datos de producción, este patrón permite entrenar el modelo con los datos de producción en el entorno de producción.
- El reentrenamiento del modelo automatizado es más seguro, ya que el código de entrenamiento se revisa, prueba y aprueba para la producción.
- El código auxiliar sigue el mismo patrón que el código de entrenamiento del modelo. Ambos pasan por pruebas de integración en el entorno de preproducción.
Desventajas:
- La curva de aprendizaje para que los científicos de datos entreguen código a los colaboradores puede ser empinada. Las plantillas de proyecto y los flujos de trabajo predefinidos son útiles.
Además, en este patrón, los científicos de datos deben poder revisar los resultados de entrenamiento del entorno de producción, ya que tienen el conocimiento para identificar y corregir problemas específicos del ML.
Si su situación requiere que el modelo se entrene en el entorno de pruebas sobre el conjunto de datos de producción completo, puede usar un enfoque híbrido desplegando código en el entorno de pruebas, entrenando el modelo y, a continuación, implementando el modelo en producción. Este enfoque ahorra costos de entrenamiento en producción, pero agrega un costo de operación adicional en el almacenamiento provisional.
Implementación de modelos
En este patrón, el artefacto del modelo se genera mediante el código de entrenamiento en el entorno de desarrollo. A continuación, el artefacto se prueba en el entorno de ensayo antes de implementarse en producción.
Tenga en cuenta esta opción cuando se aplique una o varias de las siguientes opciones:
- El entrenamiento del modelo es muy caro o difícil de reproducir.
- Todo el trabajo se realiza en una única área de trabajo de Azure Databricks.
- No está trabajando con repositorios externos ni con un proceso de CI/CD.
Ventajas:
- Una transferencia más sencilla para los científicos de datos.
- En los casos en los que el entrenamiento del modelo es costoso, solo requiere entrenar el modelo una vez.
Desventajas:
- Si los datos de producción no son accesibles desde el entorno de desarrollo (lo que puede ocurrir por motivos de seguridad), es posible que esta arquitectura no sea viable.
- El reentrenamiento del modelo automatizado es complicado en este patrón. Puede automatizar el reentrenamiento en el entorno de desarrollo, pero el equipo responsable de implementar el modelo en producción podría no aceptar el modelo resultante como listo para producción.
- El código auxiliar, como las canalizaciones usadas para la caracterización, la inferencia y la supervisión, deben implementarse en producción por separado.
Normalmente, un entorno (desarrollo, ensayo o producción) corresponde a un catálogo en Unity Catalog. Para obtener más información sobre cómo implementar este patrón, vea la guía de actualización.
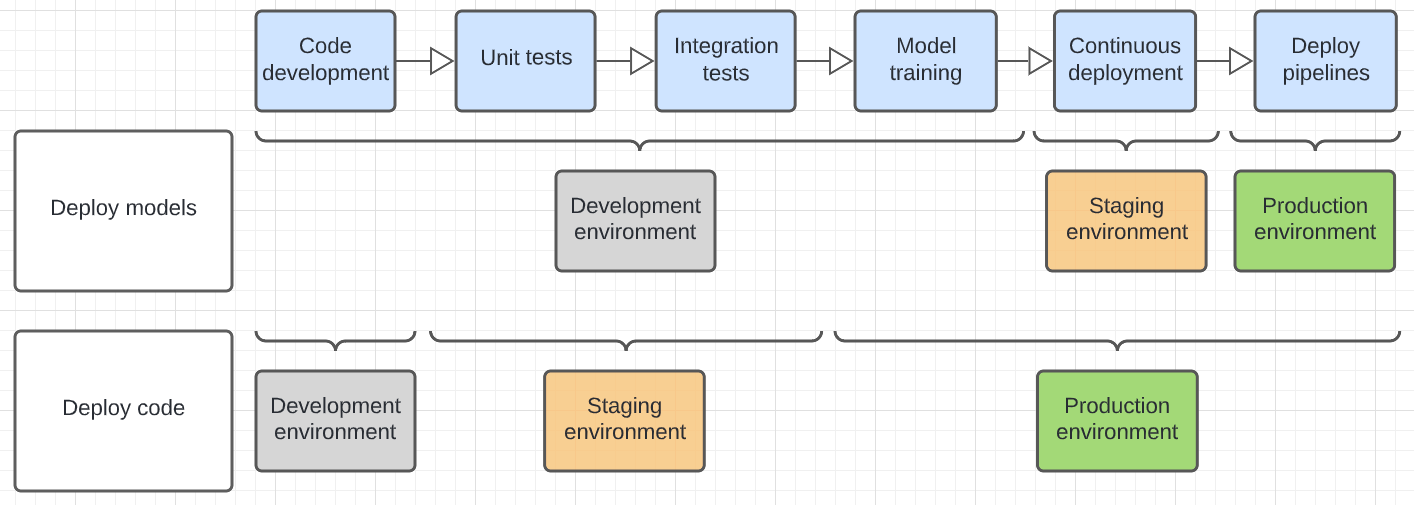
En el diagrama siguiente se contrasta el ciclo de vida del código de los patrones de implementación anteriores en los distintos entornos de ejecución.
En el diagrama se muestra el entorno final en el que se ejecuta un paso. Por ejemplo, en el patrón de implementación de modelos, la unidad final y las pruebas de integración se realizan en el entorno de desarrollo. En el patrón de código de implementación, las pruebas unitarias y las pruebas de integración se ejecutan en los entornos de desarrollo, mientras que la unidad final y las pruebas de integración finales se realizan en el entorno de ensayo.