Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo las pilas MLOps permiten implementar el proceso de desarrollo e implementación como código en un repositorio controlado por código fuente. También se describen las ventajas del desarrollo del modelo en la plataforma Data Intelligence de Databricks, una única plataforma que unifica cada paso del proceso de desarrollo e implementación del modelo.
¿Qué son los conjuntos de MLOps?
Con MLOps Stacks, todo el proceso de desarrollo del modelo se implementa, guarda y realiza un seguimiento como código en un repositorio con control de versiones. La automatización del proceso de esta manera facilita implementaciones más repetibles, predecibles y sistemáticas y permite la integración con el proceso de CI/CD. La representación del proceso de desarrollo del modelo como código le permite implementar el código en lugar de implementar el modelo. La implementación del código automatiza la capacidad de crear el modelo, lo que facilita mucho el entrenamiento del modelo cuando sea necesario.
Al crear un proyecto mediante pilas MLOps, se definen los componentes del proceso de desarrollo e implementación de ML, como los cuadernos que se usarán para la ingeniería de características, el entrenamiento, las pruebas y la implementación, las canalizaciones para el entrenamiento y las pruebas, las áreas de trabajo que se usarán para cada fase y los flujos de trabajo de CI/CD mediante Acciones de GitHub o Azure DevOps para las pruebas automatizadas y la implementación de su código.
El entorno creado por MLOps Stacks implementa el flujo de trabajo de MLOps recomendado por Databricks. Puede personalizar el código para crear pilas que se ajusten a los procesos o requisitos de su organización.
¿Cómo operan las MLOps Stacks?
Utilizar la CLI de Databricks para crear un stack de MLOps. Para obtener instrucciones paso a paso, consulte Paquetes de automatización declarativos para stacks de MLOps.
Al iniciar un proyecto de MLOps Stacks, el software le guiará por la introducción de los detalles de configuración y, a continuación, creará un directorio que contiene los archivos que componen el proyecto. Este directorio o pila implementa el flujo de trabajo de MLOps de producción recomendado por Databricks. Los componentes que se muestran en el diagrama se crean automáticamente y solo necesita editar los archivos para agregar el código personalizado.
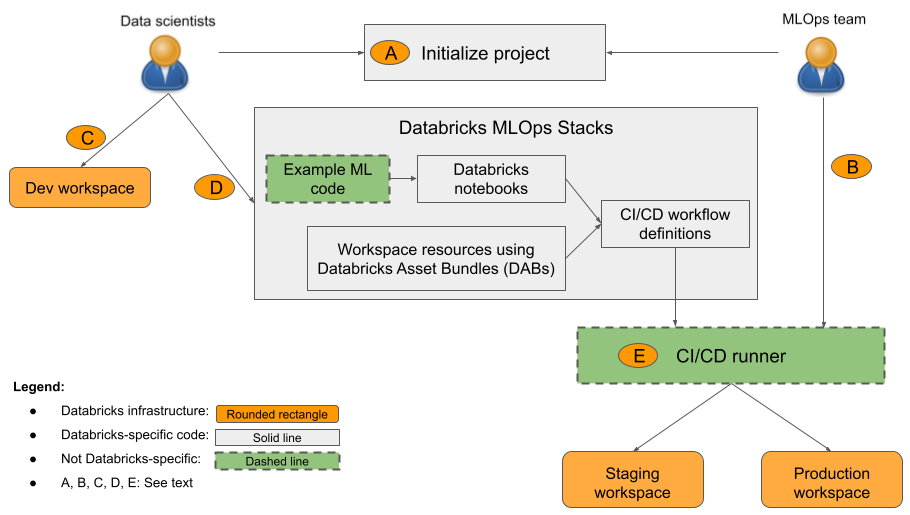
En el diagrama:
-
A: Un científico de datos o ingeniero de ML inicializa el proyecto mediante
databricks bundle init mlops-stacks. Al inicializar el proyecto, puede elegir configurar los componentes de código de ML (que suelen usar los científicos de datos), los componentes de CI/CD (que normalmente usan los ingenieros de ML) o ambos. - B: Los ingenieros de ML configuran secretos del principal de servicio de Databricks para CI/CD.
- C: Los científicos de datos desarrollan modelos en Databricks o en su sistema local.
- D: Los científicos de datos crean solicitudes de incorporación de cambios para actualizar el código de ML.
- E: El ejecutor de CI/CD ejecuta cuadernos, crea trabajos y realiza otras tareas en las áreas de trabajo de ensayo y producción.
Su organización puede usar la pila predeterminada o personalizarla según sea necesario para agregar, quitar o revisar componentes para ajustarse a las prácticas de su organización. Consulte el archivo Léame del repositorio de GitHub para obtener más información.
MLOps Stacks está diseñado con una estructura modular para permitir que los distintos equipos de aprendizaje automático (ML) trabajen de forma independiente en un proyecto, mientras siguen las mejores prácticas de ingeniería de software y mantienen CI/CD de nivel de producción. Los ingenieros de producción configuran la infraestructura de ML que permite a los científicos de datos desarrollar, probar e implementar canalizaciones y modelos de ML en producción.
Como se muestra en el diagrama, la pila MLOps predeterminada incluye los tres componentes siguientes:
- Código de ML. Las pilas MLOps crean un conjunto de plantillas para un proyecto de ML, incluidos cuadernos para entrenamiento, inferencia por lotes, etc. La plantilla estandarizada permite a los científicos de datos empezar a trabajar rápidamente, unifica la estructura del proyecto en todos los equipos y aplica el código modularizado listo para las pruebas.
- Recursos de ML como código. Las pilas MLOps definen recursos como áreas de trabajo y canalizaciones para tareas como el entrenamiento y la inferencia por lotes. Los recursos se definen en agrupaciones de automatización declarativa para facilitar las pruebas, la optimización y el control de versiones para el entorno de ML. Por ejemplo, puede probar un tipo de instancia más grande para el reentrenamiento del modelo automatizado y se realiza un seguimiento automático del cambio para futuras referencias.
- CI/CD. Puede usar Acciones de GitHub o Azure DevOps para probar e implementar código y recursos de ML, lo que garantiza que todos los cambios de producción se realizan mediante automatización y que solo se implemente el código probado en prod.
Flujo de proyecto de MLOps
Un proyecto predeterminado de Stacks de MLOps incluye un pipeline de ML con flujos de trabajo de CI/CD para probar e implementar trabajos de entrenamiento automatizado de modelos y de inferencia por lotes en las áreas de trabajo de Databricks de desarrollo, staging y producción. MlOps Stacks es configurable, por lo que puede modificar la estructura del proyecto para satisfacer los procesos de su organización.
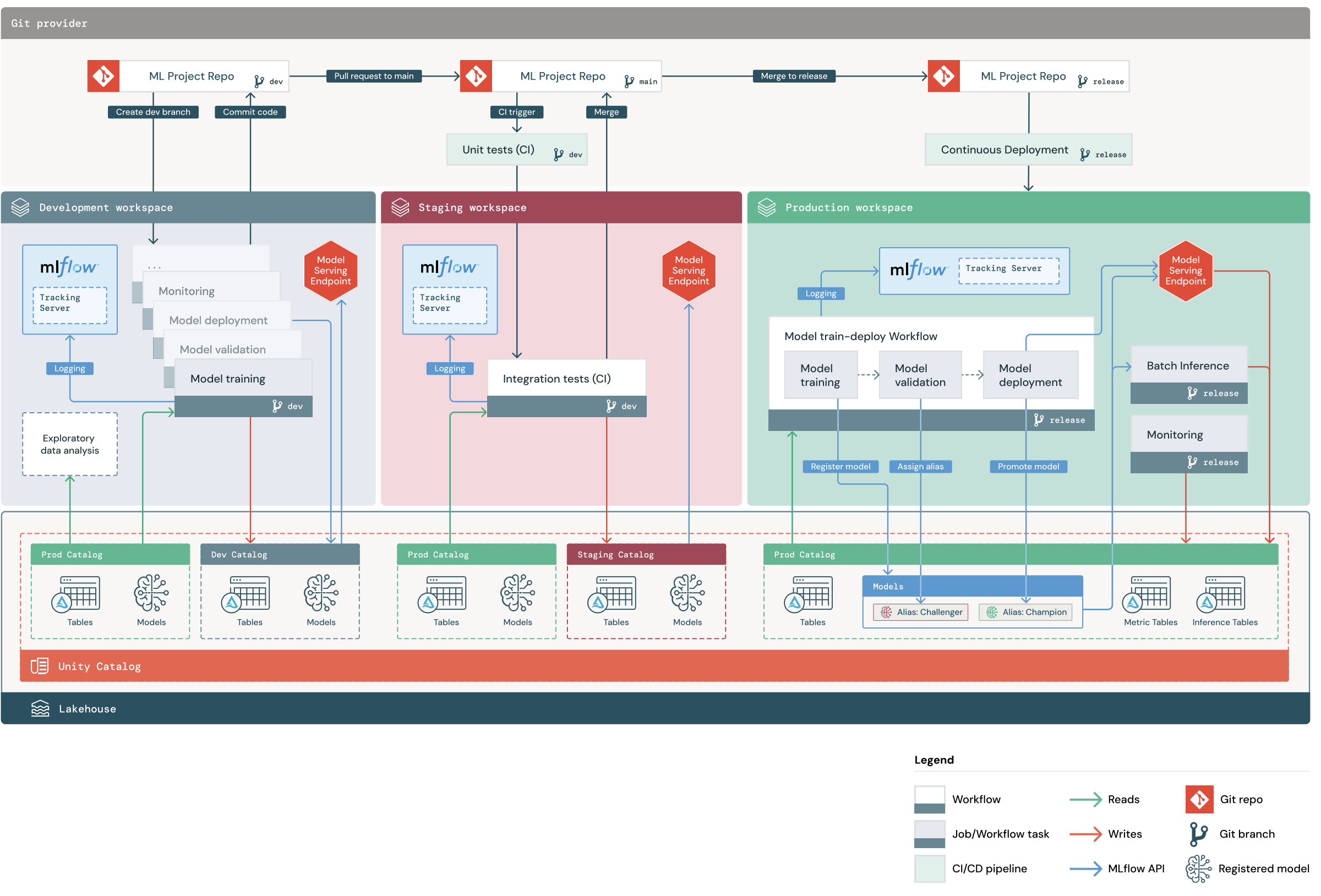
En el diagrama se muestra el proceso implementado por la pila MLOps predeterminada. En el área de trabajo de desarrollo, los científicos de datos efectúan una iteración sobre el código y las solicitudes de cambios (RP) de archivos de ML. Las pull requests desencadenan pruebas unitarias y pruebas de integración en un área de trabajo de Databricks de preproducción aislado. Cuando una solicitud de extracción se combina con la rama principal, los trabajos de entrenamiento del modelo y de inferencia por lotes que se ejecutan en el entorno de pruebas se actualizan inmediatamente para ejecutar el código más reciente. Después de combinar una solicitud de cambios en la versión principal, puede cortar una nueva rama de versión como parte del proceso de lanzamiento programado e implementar los cambios de código en producción.
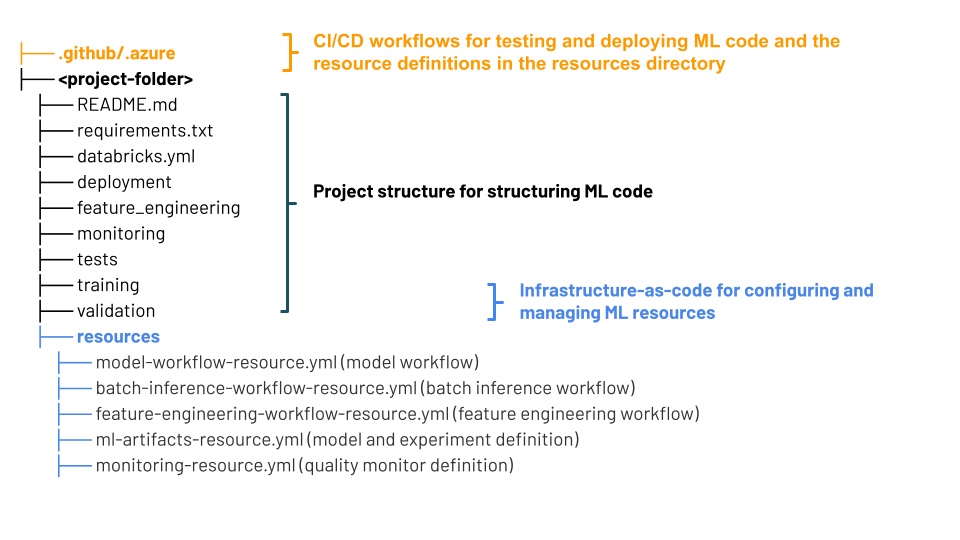
Estructura del proyecto de MLOps Stacks
Una pila de MLOps usa agrupaciones de automatización declarativa - una colección de archivos de origen que actúa como la definición completa de un proyecto. Estos archivos de origen incluyen información sobre cómo se van a probar e implementar. La recopilación de archivos como agrupación facilita la co-versión de los cambios y usa procedimientos recomendados de ingeniería de software, como el control de código fuente, la revisión de código, las pruebas y CI/CD.
En el diagrama se muestran los archivos creados para la pila de MLOps predeterminada. Para obtener más información sobre los archivos incluidos en la pila, consulte la documentación del repositorio de GitHub o los paquetes de automatización declarativa para pilas MLOps.
Componentes de MLOps Stacks
Una "pila" hace referencia al conjunto de herramientas que se usan en un proceso de desarrollo. La pila de MLOps predeterminada aprovecha la plataforma unificada de Databricks y usa las siguientes herramientas:
| Componente | Herramienta de Databricks |
|---|---|
| Código de desarrollo del modelo de ML | Cuadernos de Databricks, MLflow |
| Desarrollo y gestión de funcionalidades | Ingeniería de características |
| Repositorio del modelo de ML | Modelos en Unity Catalog |
| Servicio de modelos de aprendizaje automático | Servicio de modelo de IA de Mosaic |
| Infraestructura como código | Agrupaciones de automatización declarativa |
| Orquestador | Trabajos de Lakeflow |
| CI/CD | Acciones de GitHub, Azure DevOps |
| Supervisión del rendimiento de datos y modelo | Generación de perfiles de datos |
Pasos siguientes
Para empezar, considere consultar paquetes de automatización declarativos para stacks de MLOps o el repositorio de Databricks MLOps Stacks en GitHub.