Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica es Experimental.
En este artículo se explica cómo usar la materialización de las vistas de métricas para acelerar el rendimiento de las consultas.
La materialización de las vistas de métricas acelera las consultas mediante vistas materializadas. Las canalizaciones declarativas de Spark de Lakeflow organizan vistas materializadas definidas por el usuario para una vista de métrica determinada. En el momento de la consulta, el optimizador de consultas enruta de forma inteligente las consultas de usuario en la vista de métricas a la mejor vista materializada mediante la coincidencia automática de consultas compatibles con agregados, también conocida como reescritura de consultas.
Este enfoque proporciona las ventajas del cálculo previo y las actualizaciones incrementales automáticas, por lo que no es necesario determinar qué tabla de agregación o vista materializada para consultar los distintos objetivos de rendimiento y elimina la necesidad de administrar canalizaciones de producción independientes.
Información general
En el diagrama siguiente se muestra cómo las vistas de métricas controlan la definición y la ejecución de consultas:
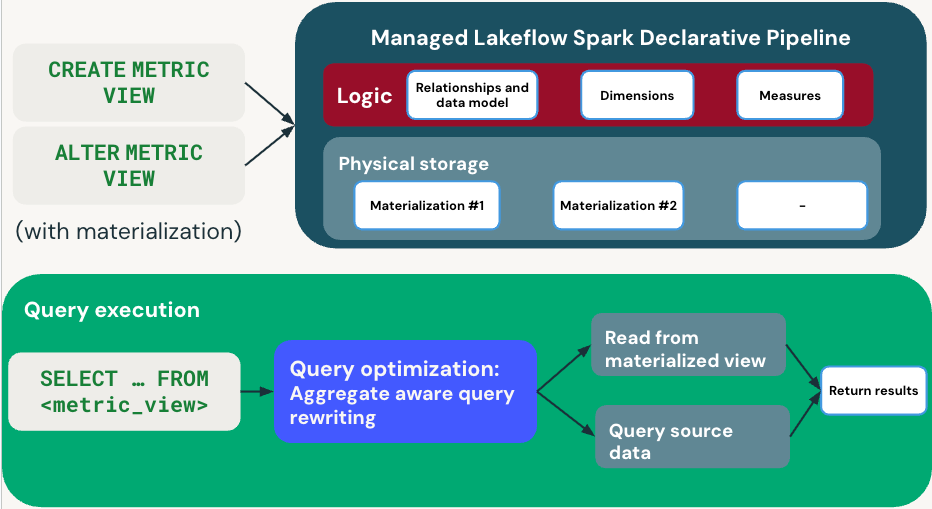
Fase de definición
Cuando se define una vista de métrica con materialización, CREATE METRIC VIEW o ALTER METRIC VIEW se especifican las dimensiones, las medidas y la programación de actualización. Databricks crea una canalización gestionada que mantiene las vistas materializadas.
Ejecución de consultas
Al ejecutar SELECT ... FROM <metric_view>, el optimizador de consultas usa la reescritura de consultas compatibles con agregados para optimizar el rendimiento:
- Ruta rápida: lee de vistas materializadas calculadas previamente cuando corresponda.
- Ruta de acceso alternativa: lee directamente de los datos de origen cuando las materializaciones no están disponibles.
El optimizador de consultas equilibra automáticamente el rendimiento y la actualización eligiendo entre los datos materializados y de origen. Los resultados se reciben de forma transparente, independientemente de la ruta de acceso que se use.
Requisitos
Para utilizar la materialización en las vistas de métricas:
- El área de trabajo debe tener habilitado el proceso sin servidor. Esto es necesario para ejecutar canalizaciones declarativas de Spark de Lakeflow.
- Databricks Runtime 17.2 o superior.
Referencia de configuración
Toda la información relacionada con la materialización se define en un campo de nivel superior denominado materialization en la definición de YAML de la vista de métricas.
Nota:
A medida que esta característica se implementa, las vistas de métricas de la versión 1.1 con materialización podrían producir el siguiente error en la canalización subyacente:
[METRIC_VIEW_INVALID_VIEW_DEFINITION] The metric view definition is invalid. Reason: Invalid YAML version: 1.1.
Si esto ocurre, use la versión 0.1 en su lugar. Tenga en cuenta que la versión 0.1 no admite algunas características disponibles en la versión 1.1. La materialización de las vistas métricas estará disponible en todas las áreas de trabajo en las próximas semanas.
El materialization campo contiene los siguientes campos obligatorios:
- schedule: admite la misma sintaxis que la cláusula de programación en las vistas materializadas.
-
mode: debe establecerse en
relaxed. -
materialized_views: una lista de vistas materializadas.
- name: el nombre de la materialización.
- dimensiones: lista de dimensiones que se van a materializar. Solo se permiten referencias directas a nombres de dimensión; No se admiten expresiones.
- medidas: una lista de medidas que se deben materializar. Solo se permiten referencias directas a los nombres de medida; No se admiten expresiones.
-
type: especifica si la vista materializada es agregada o no. Acepta dos valores posibles:
aggregatedyunaggregated.- Si
typeesaggregated, debe haber al menos una dimensión o medida. - Si
typeesunaggregated, no se debe definir ninguna dimensión o medidas.
- Si
Nota:
La TRIGGER ON UPDATE cláusula no se admite para la materialización de las vistas de métricas.
Definición de ejemplo
version: 0.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
Mode
En relaxed modo, la reescritura automática de consultas solo comprueba si las vistas materializadas candidatas tienen las dimensiones y medidas necesarias para satisfacer la consulta.
Esto significa que se omiten varias comprobaciones:
- No hay comprobaciones sobre si la vista materializada está actualizada.
- No hay comprobaciones en si tiene la configuración de SQL coincidente (por ejemplo,
ANSI_MODEoTIMEZONE). - No se comprueba si la vista materializada devuelve resultados deterministas.
Si la consulta incluye cualquiera de las condiciones siguientes, la reescritura de la consulta no se produce y la consulta vuelve a las tablas de origen:
- Seguridad de nivel de fila (RLS) o enmascaramiento de nivel de columna (CLM) en vistas materializadas.
- Funciones no deterministas como
current_timestamp()en vistas materializadas. Pueden aparecer en la definición de la vista de métricas o en una tabla de origen usada por la vista de métricas.
Nota:
Durante el período de versión experimental, relaxed es el único modo admitido. Si se produce un error en estas comprobaciones, la consulta vuelve a los datos de origen.
Tipos de materializaciones para vistas de métricas
En las secciones siguientes se explican los tipos de vistas materializadas disponibles para las vistas de métricas.
Tipo agregado
Este tipo calcula previamente las agregaciones para combinaciones de medida y dimensión especificadas para la cobertura de destino.
Esto resulta útil para tener como destino patrones de consulta de agregación o widgets comunes específicos. Databricks recomienda incluir posibles columnas de filtro como dimensiones en la configuración de vista materializada. Las columnas de filtro potenciales son columnas que se usan en el momento de la consulta en la WHERE cláusula .
Tipo no agregado
Este tipo materializa todo el modelo de datos no agregado (por ejemplo, los campos source, join y filter) para una cobertura más amplia con menos impacto en el rendimiento en comparación con el tipo agregado.
Use este tipo cuando se cumpla lo siguiente:
- El origen es una vista costosa o una consulta SQL.
- Las uniones definidas en la vista de métricas son costosas.
Nota:
Si el origen es una referencia de tabla directa sin un filtro selectivo aplicado, es posible que una vista materializada no agregada no proporcione ventajas.
Ciclo de vida de materialización
En esta sección se explica cómo se crean, administran y actualizan las materializaciones a lo largo de su ciclo de vida.
Creación y modificación
La creación o modificación de una vista de métricas (mediante CREATE, ALTERo el Explorador de catálogos) se produce sincrónicamente. Las vistas materializadas especificadas se materializan de forma asincrónica mediante las canalizaciones declarativas de Lakeflow Spark.
Al crear una vista de métricas, Databricks crea una canalización declarativa Spark de Lakeflow y programa inmediatamente una actualización inicial si se especifican vistas materializadas. La vista de métrica permanece consultable sin materializaciones al revertir a la consulta de los datos de origen.
Al modificar una vista de métricas, no se programan nuevas actualizaciones, a menos que se habilite la materialización por primera vez. Las vistas materializadas no se usan para la reescritura automática de consultas hasta que se complete la siguiente actualización programada.
Cambiar la programación de materialización no desencadena una actualización.
Consulte Actualización manual para obtener un control más preciso sobre el comportamiento de la actualización.
Inspección de la canalización subyacente
La materialización de las vistas de métricas se implementa mediante las canalizaciones declarativas de Lakeflow Spark. Hay un vínculo a la canalización en la pestaña Información general del Explorador de catálogos. Para obtener información sobre cómo acceder al Explorador de catálogos, consulte ¿Qué es el Explorador de catálogos?.
También puede acceder a esta canalización mediante la ejecución DESCRIBE EXTENDED en la vista de métricas. La sección Información de actualización contiene un vínculo a la canalización.
DESCRIBE EXTENDED my_metric_view;
Ejemplo de resultado:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE TABLE EXTENDED customer;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh information
Latest Refresh status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 3 HOURS
Actualización manual
Desde el vínculo a la página Canalizaciones declarativas de Spark de Lakeflow, puede iniciar manualmente una actualización de canalización para actualizar las materializaciones. También puede orquestarlo mediante una llamada a la API basada en el identificador de canalización.
Por ejemplo, el siguiente script de Python inicia un refresco del pipeline.
from databricks.sdk import WorkspaceClient
client = WorkspaceClient()
pipeline_id = "01484540-0a06-414a-b10f-e1b0e8097f15"
client.pipelines.start_update(pipeline_id)
Para ejecutar una actualización manual como parte de un trabajo de Lakeflow, cree un script de Python con la lógica anterior y agréguelo como una tarea de tipo script de Python. También puede crear un cuaderno con la misma lógica y agregar una tarea de tipo Notebook.
Actualización incremental
Las vistas materializadas usan la actualización incremental siempre que sea posible y tienen las mismas limitaciones con respecto a los orígenes de datos y la estructura del plan.
Para más información sobre los requisitos previos y las restricciones, consulte Actualización incremental para vistas materializadas.
Reescritura automática de consultas
Las consultas a una vista métrica con materialización intentan usar sus materializaciones en la mayor medida posible. Hay dos estrategias de reescritura de consultas: coincidencia exacta y coincidencia no agregada.

Cuando se consulta una vista de métrica, el optimizador analiza la consulta y las materializaciones definidas por el usuario disponibles. La consulta se ejecuta automáticamente en la mejor materialización en lugar de las tablas base mediante este algoritmo:
- Primero intenta una coincidencia exacta.
- Si existe una materialización no agregada, intenta un pareo no agregado.
- Si se produce un error en la reescritura de consultas, la consulta lee directamente de las tablas de origen.
Nota:
Las materializaciones deben terminar de materializarse antes de que la reescritura de la consulta pueda surtir efecto.
Verificar que la consulta usa vistas materializadas
Para comprobar si una consulta usa una vista materializada, ejecute EXPLAIN EXTENDED en la consulta para ver el plan de consulta. Si la consulta utiliza vistas materializadas, el nodo hoja incluye __materialization_mat___metric_view así como el nombre de la materialización del archivo YAML.
Como alternativa, el perfil de consulta muestra la misma información.
Coincidencia exacta
Para que sea apto para la estrategia de coincidencia exacta, las expresiones de agrupación deben coincidir exactamente con las dimensiones de materialización de la consulta. Las expresiones de agregación de la consulta deben ser un subconjunto de las medidas de materialización.
Coincidencia no agregada
** Si hay disponible una materialización no agregada, esta estrategia siempre es elegible.
Facturación
La actualización de vistas materializadas conlleva cargos de uso de canalizaciones declarativas de Spark de Lakeflow.
Restricciones conocidas
Las restricciones siguientes se aplican a la materialización de las vistas de métricas:
- Una vista de métrica con materialización que hace referencia a otra vista de métrica como origen no puede tener una materialización no agregada.