Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Esta página trata de cómo personalizar el Registro automático de Databricks, que capturan automáticamente los parámetros del modelo, las métricas, los archivos y la información del linaje al entrenar modelos a partir de una serie de bibliotecas populares de aprendizaje automático. Las sesiones de entrenamiento se registran como ejecuciones de seguimiento de MLflow. También se realiza un seguimiento de los archivos de modelo para poder registrarlos fácilmente en el registro de modelos de MLflow.
Nota:
Para habilitar el registro de seguimiento para cargas de trabajo de IA generativas, MLflow admite el registro automático de OpenAI.
En el vídeo siguiente se muestra el registro automático de Databricks con una sesión de entrenamiento de modelos scikit-learn en un cuaderno interactivo de Python. La información de seguimiento se captura y muestra automáticamente en la barra lateral de ejecuciones de experimento y en la interfaz de usuario de MLflow.
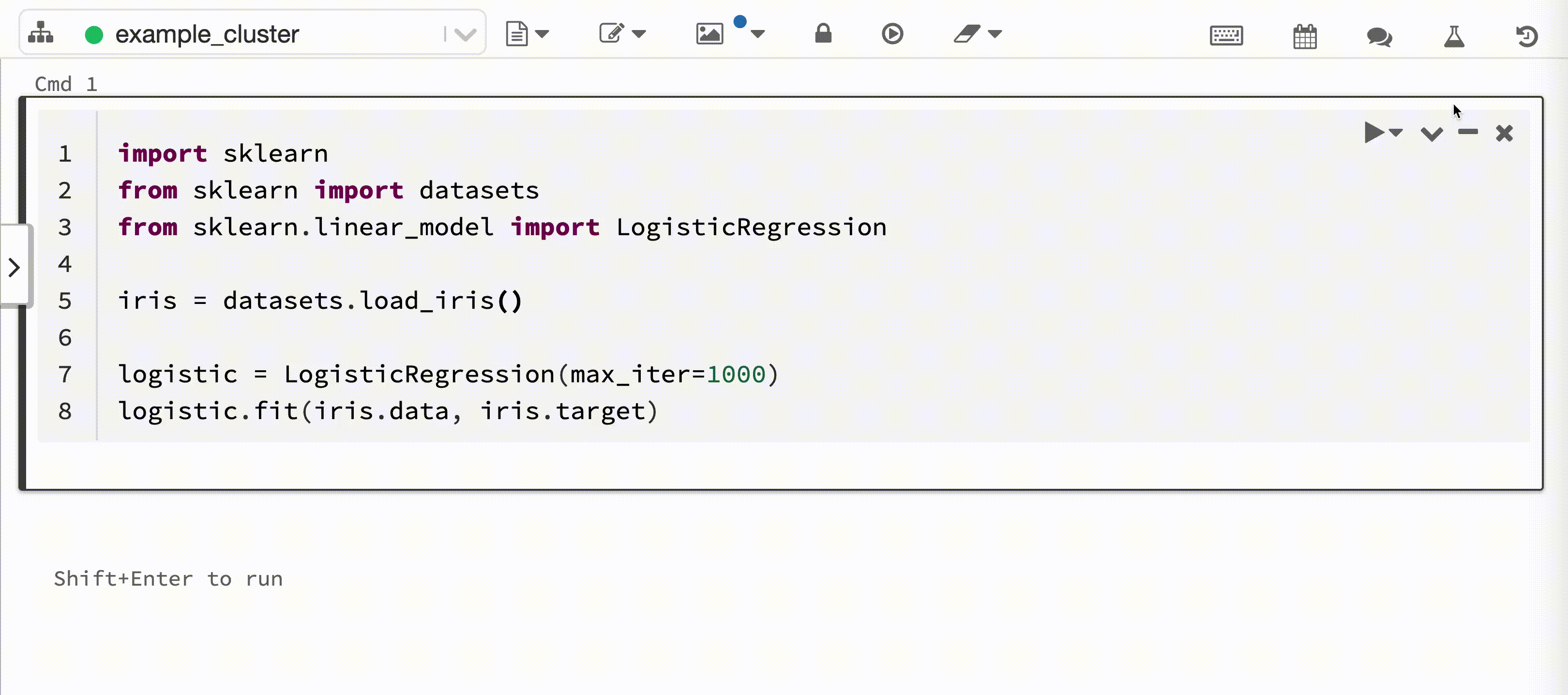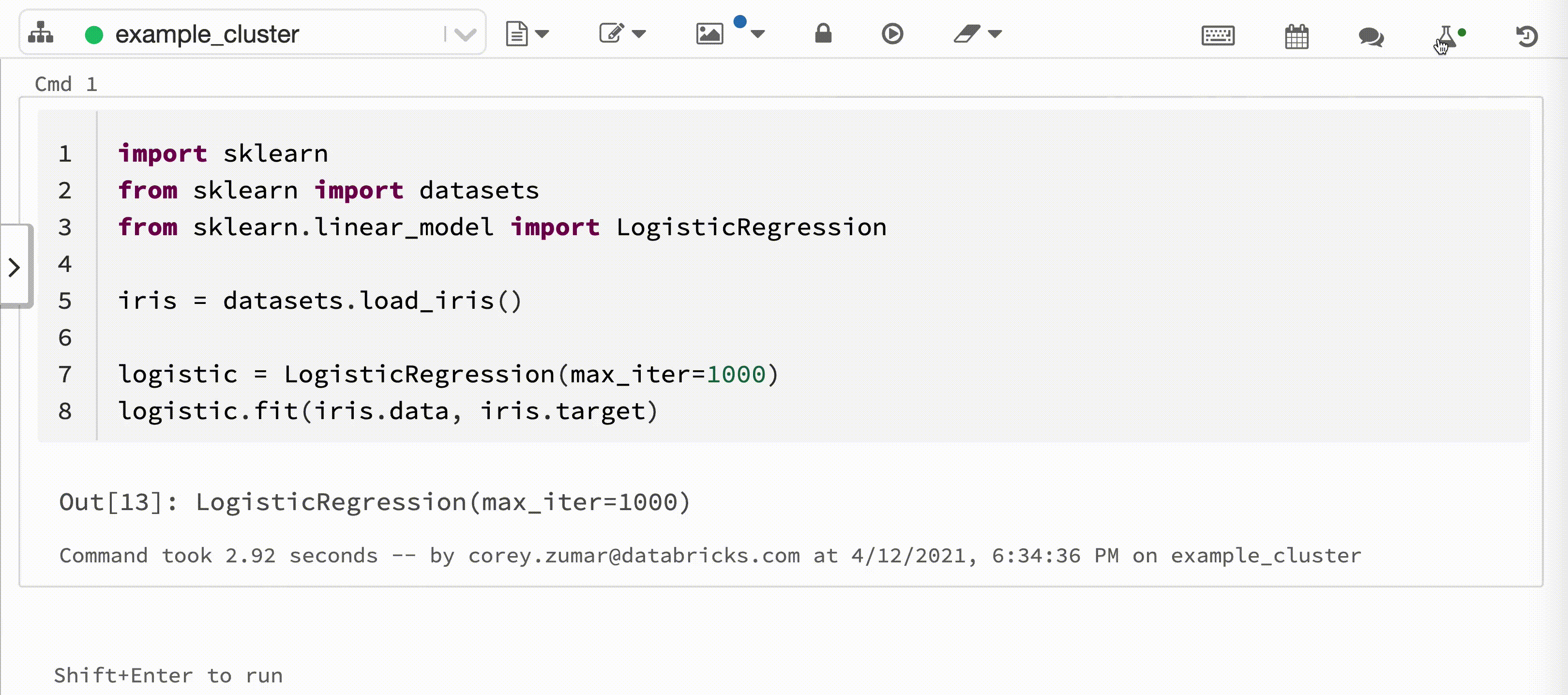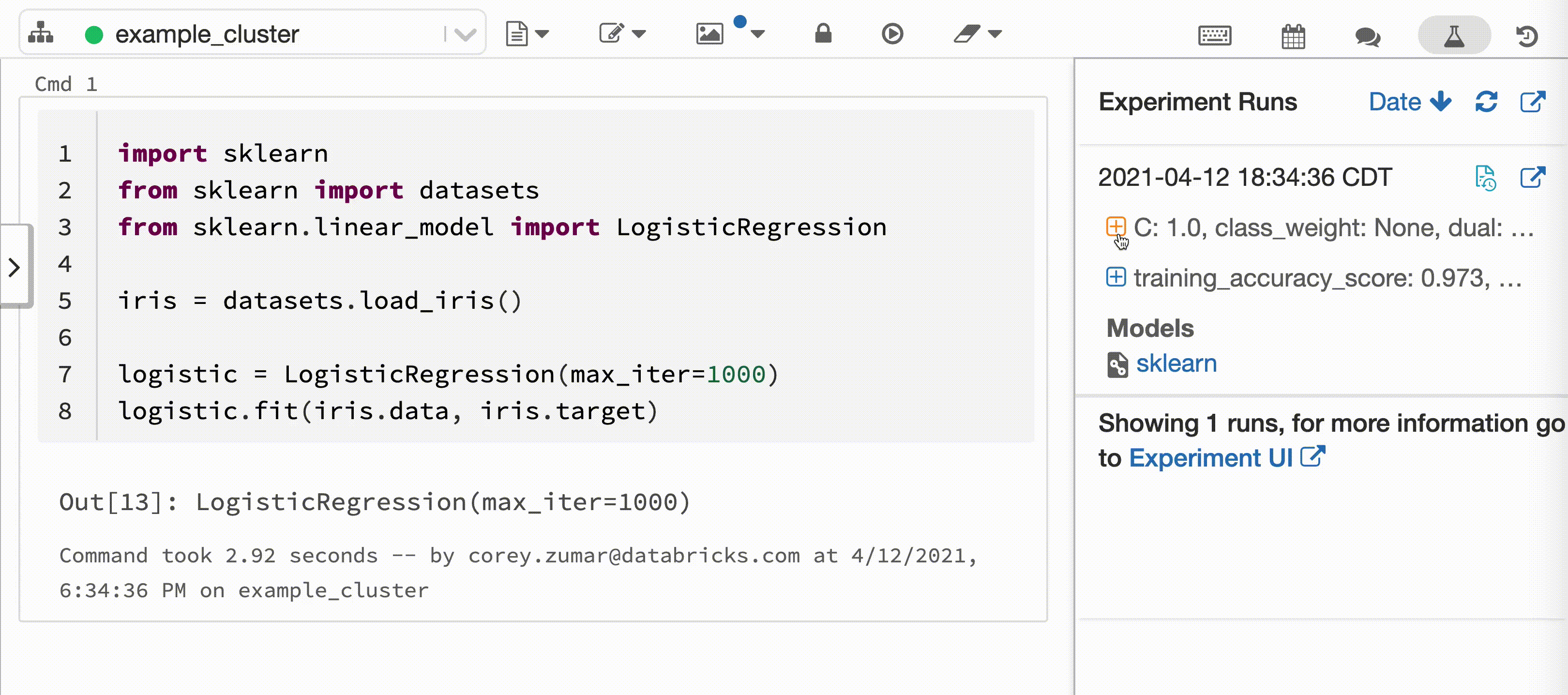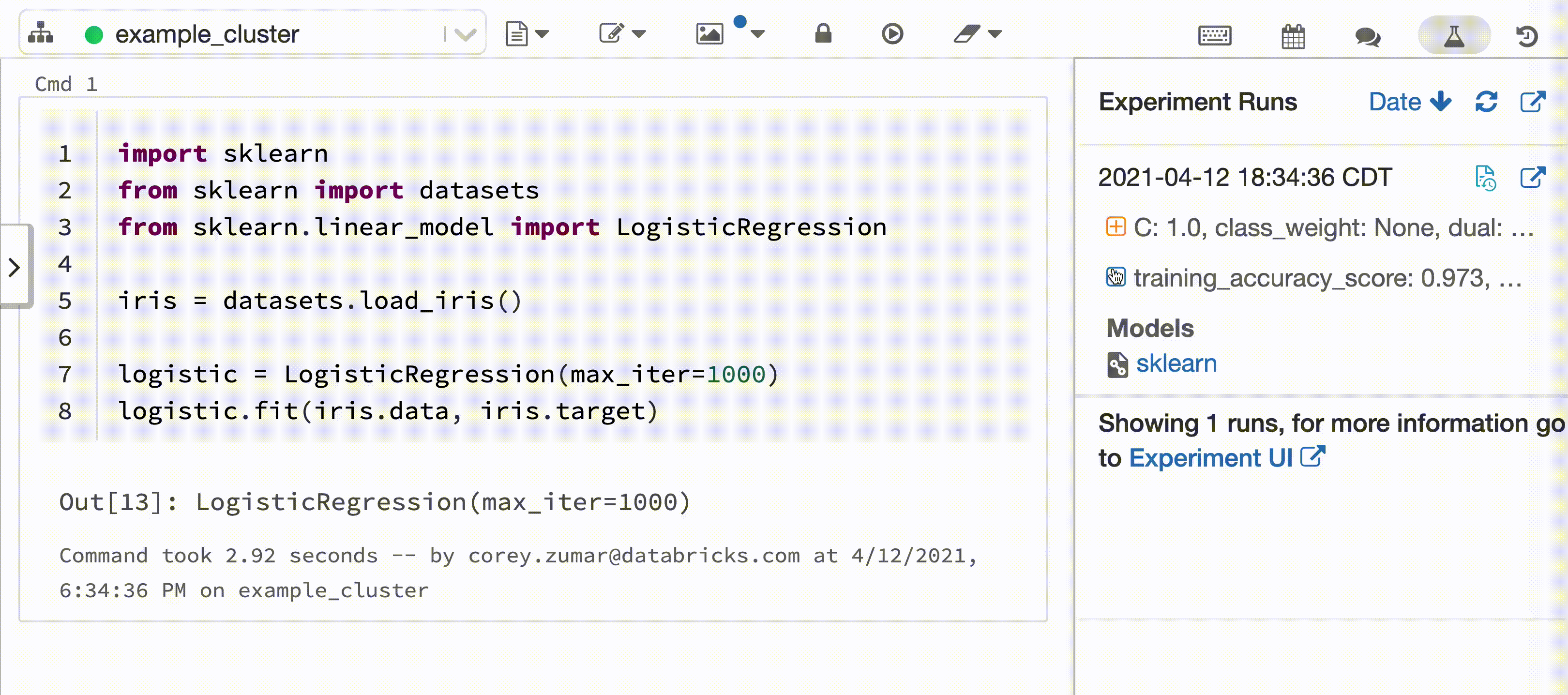
Requisitos
- El registro automático de Databricks está disponible con carácter general en todas las regiones con Databricks Runtime 10.4 LTS ML o versiones posteriores.
- El registro automático de Databricks está disponible en las regiones seleccionadas para la versión preliminar con Databricks Runtime 9.1 LTS ML o versiones posteriores.
Funcionamiento
Al adjuntar un cuaderno de Python interactivo a un clúster de Azure Databricks, el registro automático de Databricks llama a mlflow.autolog() para configurar el seguimiento de las sesiones de entrenamiento del modelo. Al entrenar modelos en el cuaderno, se realiza el seguimiento automático de la información de entrenamiento del modelo con MLflow Tracking. Para obtener información sobre cómo se protege y administra esta información de entrenamiento del modelo, vea Seguridad y administración de datos.
Nota:
El registro automático no está habilitado automáticamente en el proceso sin servidor. En el caso de los clústeres de proceso sin servidor, debe llamar mlflow.autolog() explícitamente para habilitar la funcionalidad de registro automático.
La configuración predeterminada para la llamada a mlflow.autolog() es:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Puede personalizar la configuración de registro automático.
Uso
Para usar el registro automático de Databricks, entrene un modelo de aprendizaje automático en un marco compatible mediante un cuaderno interactivo de Python en Azure Databricks. El registro automático de Databricks registra automáticamente la información, los parámetros y las métricas de linaje del modelo en MLflow Tracking. También puede personalizar el comportamiento del registro automático de Databricks.
Nota:
El registro automático de Databricks no se aplica a las ejecuciones creadas mediante la API fluida de MLflow con mlflow.start_run(). En estos casos, debe llamar a mlflow.autolog() para guardar el contenido marcado automáticamente en la ejecución de MLflow. Vea Seguimiento de contenido adicional.
Personalización del comportamiento del registro
Para personalizar el registro, use mlflow.autolog().
Esta función proporciona parámetros de configuración para habilitar el registro de modelos (log_models), registrar conjuntos de datos (log_datasets), recopilar ejemplos de entrada (log_input_examples), registrar firmas de modelos (log_model_signatures), configurar advertencias (silent) y mucho más.
Seguimiento de contenido adicional
Para realizar el seguimiento de métricas, parámetros, archivos y metadatos adicionales con ejecuciones de MLflow creados por el registro automático de Databricks, siga estos pasos en un cuaderno de Python interactivo en Azure Databricks:
- Llame a mlflow.autolog() con
exclusive=False. - Inicie una ejecución de MLflow mediante mlflow.start_run().
Puede encapsular esta llamada en
with mlflow.start_run(); cuando lo haga, la ejecución finaliza automáticamente una vez que se complete. - Use métodos de seguimiento de MLflow, como mlflow.log_param(), para realizar el seguimiento del contenido previo al entrenamiento.
- Entrene uno o varios modelos de Machine Learning en un marco compatible con el registro automático de Databricks.
- Use métodos de seguimiento de MLflow, como mlflow.log_metric(), para realizar el seguimiento del contenido posterior al entrenamiento.
- Si no ha usado
with mlflow.start_run()en el paso 2, finalice la ejecución de MLflow con mlflow.end_run().
Por ejemplo:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Deshabilitación del registro automático de Databricks
Para deshabilitar el registro automático de Databricks en un cuaderno interactivo de Python de Azure Databricks, llame a mlflow.autolog() con disable=True:
import mlflow
mlflow.autolog(disable=True)
Los administradores también pueden deshabilitar el registro automático de Databricks para todos los clústeres de un área de trabajo desde la pestaña Opciones avanzadas de la página de configuración de administración. Para que se produzca este cambio, es necesario reiniciar los clústeres.
Entornos y marcos admitidos
El registro automático de Databricks se admite en cuadernos interactivos de Python y está disponible para los siguientes marcos de ML:
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluón
- Fast.ai
- statsmodels (paquete de Python para análisis estadístico)
- PaddlePaddle
- OpenAI
- LangChain
Para más información sobre cada uno de los marcos admitidos, vea Registro automático de MLflow.
Habilitación de seguimiento de MLflow
El seguimiento de MLflow utiliza la característica autolog dentro de las integraciones del marco de modelo correspondientes para controlar la habilitación o deshabilitación de la compatibilidad de seguimiento con las integraciones que admiten el seguimiento.
Por ejemplo, para habilitar el seguimiento al usar un modelo LlamaIndex, use mlflow.llama_index.autolog() con log_traces=True:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
Nota:
En el caso de los clústeres de proceso sin servidor, el registro automático para el seguimiento no está habilitado automáticamente. Debe habilitar explícitamente el registro automático para las integraciones específicas del marco de trabajo que desea realizar el seguimiento (por ejemplo, mlflow.openai.autolog() o mlflow.langchain.autolog()).
Las integraciones admitidas que tienen habilitación de seguimiento dentro de sus implementaciones de registro automático son:
Seguridad y administración de datos
Toda la información de entrenamiento del modelo de la que se realiza el seguimiento con el registro automático de Databricks se almacena en MLflow Tracking y se protege mediante permisos de experimento de MLflow. Puede compartir, modificar o eliminar información de entrenamiento del modelo mediante la API MLflow Tracking o la interfaz de usuario.
Administración
Los administradores pueden habilitar o deshabilitar el registro automático de Databricks para todas las sesiones interactivas de cuadernos en su área de trabajo en la pestaña Opciones avanzadas de la página de configuración de administración. Los cambios no surten efecto hasta que se reinicia el clúster.
Limitaciones
- El registro automático de Databricks solo está habilitado en el nodo de controlador del clúster de Azure Databricks. Para usar el registro automático desde nodos de trabajo, debe llamar explícitamente a mlflow.autolog() desde el código que se ejecuta en cada trabajo.
- No se admite la integración de scikit-learn de XGBoost.
Apache Spark MLlib, Hyperopt y seguimiento de MLflow automatizado
El registro automático de Databricks no cambia el comportamiento de las integraciones de seguimiento de MLflow automatizadas existentes para Apache Spark MLlib e Hyperopt.
Nota:
En Databricks Runtime 10.1 ML, al deshabilitar la integración automatizada de seguimiento de MLflow para los modelos CrossValidator y TrainValidationSplit de Apache Spark MLlib también se deshabilita la característica de registro automático de Databricks para todos los modelos de Apache Spark MLlib.