Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica está en versión preliminar pública.
Nota:
No es necesario usar trabajos de implementación con clientes de MLflow 3 o seguimiento de modelos, y los trabajos de implementación se pueden habilitar en modelos más antiguos ya existentes en Unity Catalog. Sin embargo, se recomienda usar MLflow 3.
En este artículo se describe cómo usar trabajos de implementación de MLflow como parte del flujo de trabajo de aprendizaje automático para administrar el ciclo de vida completo de los modelos de ML.
¿Qué son los trabajos de implementación?
Los trabajos de implementación permiten automatizar tareas como evaluación, aprobación e implementación cada vez que se crea una nueva versión de modelo, integrando sin problemas con los modelos de Catálogo de Unity y los trabajos de Lakeflow. Estos trabajos simplifican la configuración de canalizaciones de implementación de modelos, incorporan aprobaciones humanas en el bucle y proporcionan flujos de trabajo regulados con visibilidad clara sobre el progreso y el contexto histórico de cada versión del modelo.
Con los trabajos de implementación, el proceso está totalmente automatizado; se desencadenan automáticamente cada vez que se crea una nueva versión del modelo, mostrando el estado de ejecución del trabajo de implementación directamente en las páginas modelo y versión del modelo. En el registro de actividad se realiza un seguimiento práctico de la información histórica sobre cada ejecución de trabajos de implementación, lo que garantiza la transparencia y la facilidad de administración.
Integración con el seguimiento de modelos de MLflow 3
Databricks recomienda usar el seguimiento de MLflow 3 para registrar modelos y realizar la evaluación en el trabajo de implementación. El nuevo cliente registrará automáticamente las métricas de la parte de evaluación del trabajo de implementación, que estará visible en la interfaz de usuario de la versión del modelo del catálogo de Unity. Esto permitirá a los usuarios usar las métricas, parámetros y seguimientos centralizados en la página de versión del modelo para tomar decisiones informadas sobre cuándo avanzar el modelo más allá del ciclo de vida del trabajo de implementación.
Integración con CREATE MODEL VERSION ACL de Unity Catalog
Los trabajos de implementación se integran naturalmente con el recién lanzado Creación de ACL de versión de modelo de Unity Catalog para completar la historia de MLOps. En concreto, se puede conceder a un usuario la CREATE MODEL VERSION ACL para registrar nuevas versiones de modelo en el modelo. Una vez que el usuario considera que un modelo es lo suficientemente bueno para producción, registrará esta versión en el modelo de catálogo de Unity, que iniciará el trabajo de implementación para evaluar automáticamente el modelo. En este momento, un aprobador puede aprobar manualmente esta versión para implementarla o rechazarla.
Importante
El trabajo de implementación se desencadenará automáticamente mediante las credenciales del propietario del modelo. Esto significa que conceder a un usuario CREATE MODEL VERSION permiso en el modelo de catálogo de Unity permite al usuario ejecutar código arbitrario como parte del trabajo. Por este motivo, Databricks recomienda configurar el trabajo de implementación mediante una entidad de servicio con permisos mínimos para evitar el escalamiento de privilegios.
Ejemplos de trabajos de implementación
A continuación se muestran algunos ejemplos de trabajos de implementación que reflejan casos de uso comunes. Tenga en cuenta que estos son solo ejemplos y se pueden personalizar según sea necesario.
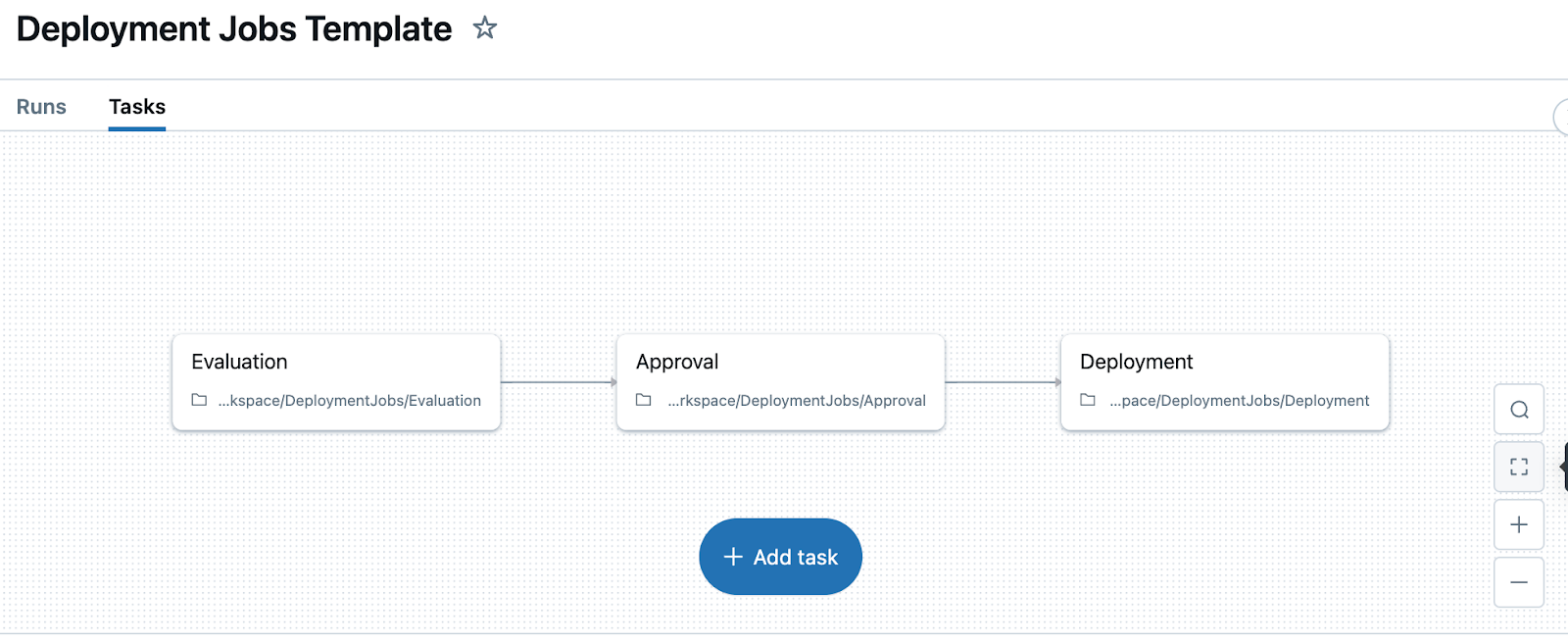
Un sencillo trabajo de implementación de ejemplo consta de tres pasos: evaluación, aprobación e implementación. Las llamadas de evaluación a mlflow.evaluate generan métricas de validación en la versión del modelo proporcionada. La aprobación permite a un usuario con privilegios determinar si estas métricas son satisfactorias y, si es así, aprobar el modelo. Por último, la implementación implementa la versión del modelo a un punto de conexión de servicio de Databricks.
En la imagen siguiente se muestran las tareas de trabajos de Lakeflow que componen este trabajo de implementación simple que consta de tareas de evaluación, aprobación e implementación:
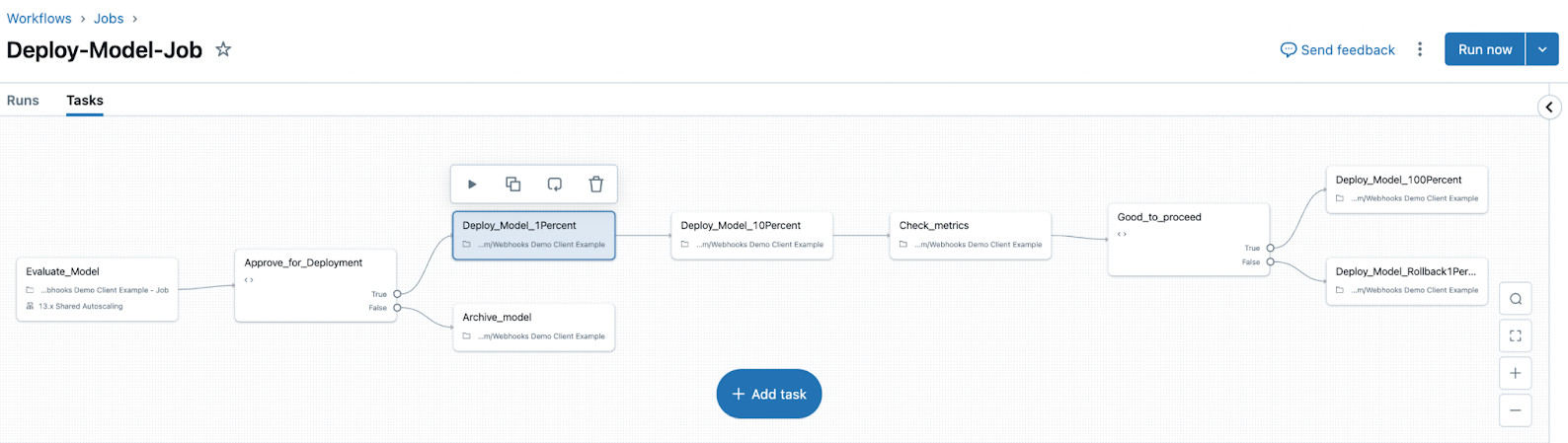
También puede crear un trabajo de implementación más complejo. Por ejemplo, puede querer realizar un despliegue gradual con un paso de recopilación de métricas como parte del flujo de trabajo. Para crear este trabajo de implementación, podría agregar tareas adicionales después de la tarea de aprobación para implementar el modelo en 1%, implementar el modelo en 10%, recopilar y comprobar métricas, decidir si continuar o revertir, y finalmente implementar el modelo en 100% o revertir el modelo. En la imagen siguiente se muestra el aspecto de este trabajo de implementación más complejo:
Crear un trabajo de implementación
Los trabajos de implementación permiten administrar el ciclo de vida de una versión del modelo. Para usar trabajos de implementación, primero necesita versiones de modelo creadas en un modelo registrado. Consulte los cuadernos de ejemplo de MLflow 3 para conocer los enfoques recomendados para entrenar y registrar modelos.
Databricks recomienda establecer el campo Ejecutar como en un principal de servicio con permisos mínimos. Además, para la tarea de aprobación, Databricks recomienda deshabilitar los reintentos , ya que se espera que se produzca un error en la tarea al principio. Esto evita una espera más larga y el registro de múltiples errores.
Un trabajo de implementación debe tener dos parámetros de trabajo: model_name y model_version. Databricks también recomienda establecer el límite máximo de ejecución simultánea en 1 (valor predeterminado) para evitar las condiciones de carrera de implementación.
Hay dos maneras de crear un trabajo de implementación: mediante programación mediante un cuaderno de implementación o mediante la interfaz de usuario. En ambos casos, tiene que proporcionar cada una de las tareas de trabajo en forma de cuaderno.
Creación de un trabajo de implementación mediante programación mediante un cuaderno (recomendado)
Se recomienda usar un cuaderno de implementación para crear mediante programación el trabajo de implementación, ya que usa el SDK de Databricks y, como tal, todas las configuraciones se configuran fácilmente con el origen de la verdad en el código. Este método también permite implementar fácilmente varios trabajos y otros recursos en varias áreas de trabajo.
Para obtener las instrucciones siguientes, se usa una plantilla de ejemplo sencilla para configurar el trabajo de implementación con tareas básicas de evaluación, aprobación e implementación.
- Cree y registre un modelo de catálogo de Unity. Por ejemplo, consulte el ejemplo de flujo de trabajo de ML tradicional de MLflow 3 .
- Cree un cuaderno que defina la tarea de evaluación. Por ejemplo, importe el cuaderno de evaluación para ml clásico para evaluar el modelo creado a partir del ejemplo de ML tradicional . El cuaderno de evaluación de GenAI proporciona un ejemplo de evaluación de un modelo externo de GenAI. Actualice los elementos OBLIGATORIOs según sea necesario. Para otros modelos, use este cuaderno como plantilla y personalícelo para evaluar el modelo según sea necesario para su caso único.
- Cree un cuaderno que defina la tarea de aprobación. Por ejemplo, importe el cuaderno de aprobación en el área de trabajo. Puede encontrar más detalles sobre cómo funciona este cuaderno en la sección Aprobaciones . También puede usar este cuaderno como plantilla y actualizarlo para adaptarlo a sus necesidades.
- Cree un cuaderno que defina la tarea de implementación. Por ejemplo, importe el cuaderno de implementación siguiente en el área de trabajo. También puede usar este cuaderno como plantilla y actualizarlo para adaptarlo a sus necesidades.
- Cree un cuaderno que cree y organice el trabajo de implementación. Por ejemplo, importe el cuaderno del trabajo de implementación al área de trabajo. Este cuaderno crea el trabajo de Databricks que se convierte en el trabajo de implementación. Asegúrese de actualizar los elementos REQUIRED del cuaderno para definir correctamente el trabajo, con el modelo de Catálogo de Unity y las tareas adecuadas. También puede usar este cuaderno como plantilla y actualizarlo para adaptarlo a sus necesidades. Por ejemplo, puede que quiera incluir más tareas si tiene un plan de lanzamiento más complejo.
- Ejecute el cuaderno del trabajo de implementación para crear su trabajo de implementación.
Creación de un trabajo de implementación mediante la interfaz de usuario de trabajos
Los trabajos también se pueden crear mediante la interfaz de usuario, en lugar de usar el SDK en la plantilla anterior. Sin embargo, para cada tarea de cuaderno, los cuadernos deben crearse manualmente y guardarse en algún lugar del área de trabajo. Para el modelo de instrucciones, se supone un flujo de trabajo de implementación simple, con tareas de evaluación, aprobación e implementación. Personalice las instrucciones agregando más tareas si tiene un flujo de trabajo de implementación más complejo.
Cree y registre un modelo de catálogo de Unity. Por ejemplo, consulte el ejemplo de flujo de trabajo de ML tradicional de MLflow 3 .
Cree un cuaderno que defina la tarea de evaluación. Por ejemplo, importe el cuaderno de evaluación para ml clásico para evaluar el modelo creado a partir del ejemplo de ML tradicional . El cuaderno de evaluación de GenAI proporciona un ejemplo de evaluación de un modelo externo de GenAI. Actualice los elementos OBLIGATORIOs según sea necesario. Para otros modelos, use este cuaderno como plantilla y personalícelo para evaluar el modelo según sea necesario para su caso único.
Cree un cuaderno que defina la tarea de aprobación. Por ejemplo, importe el cuaderno de aprobación en el área de trabajo. Puede encontrar más detalles sobre cómo funciona este cuaderno en la sección Aprobaciones . También puede usar este cuaderno como plantilla y actualizarlo para adaptarlo a sus necesidades.
Cree un cuaderno que defina la tarea de implementación. Por ejemplo, importe el cuaderno de implementación siguiente en el área de trabajo. También puede usar este cuaderno como plantilla y actualizarlo para adaptarlo a sus necesidades.
Cree la tarea de implementación en la interfaz de Jobs de Lakeflow.
En el panel de navegación izquierdo, haga clic en + Nuevo > trabajo para crear un nuevo trabajo.
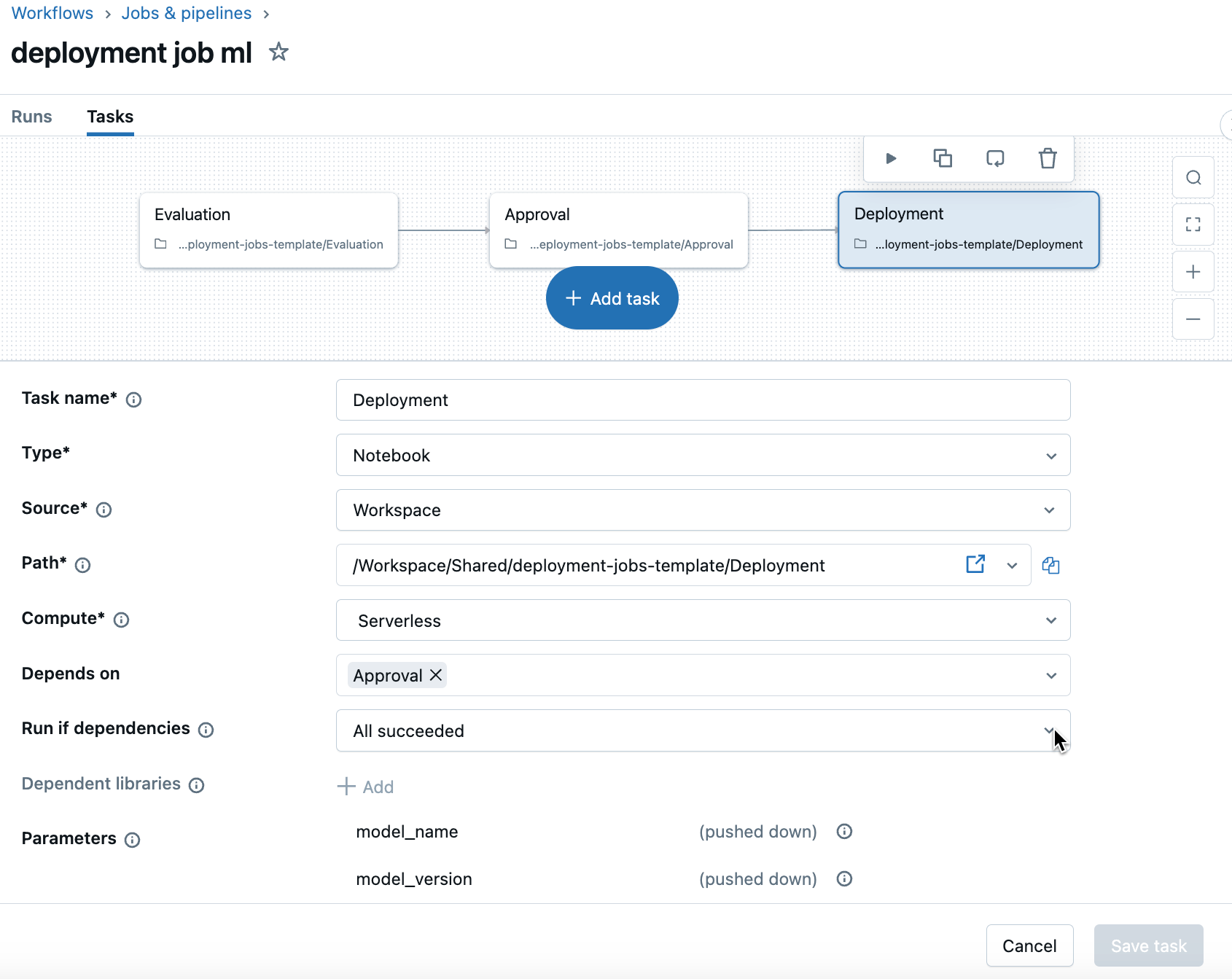
Configura cada tarea. Por ejemplo, para la tarea de implementación:
- Nombre de tarea: Implementación
- Tipo: Cuaderno
- Origen: Área de trabajo
- Ruta de acceso:
/Workspace/Users/<user.name@email.com>/deployment - Proceso: sin servidor
Para obtener más información sobre la configuración, consulte Tareas de cuaderno para trabajos.
Una vez que haya terminado de crear cada tarea, agregue los parámetros del trabajo. En el panel derecho, haga clic en Editar parámetros. Agregue
model_nameymodel_version.- Nota: Un error común es agregar estos parámetros como parámetros de nivel de tarea. Asegúrese de agregarlos como parámetros de nivel de trabajomediante el panel derecho.
A continuación se muestra un ejemplo de creación del trabajo de plantilla anterior mediante la interfaz de usuario:
Conexión del trabajo de implementación a un modelo
Después de crear el modelo de Unity Catalog y el trabajo de implementación, debe conectar la tarea al modelo como un trabajo de implementación. Puede usar la interfaz de usuario o hacerlo mediante programación en el cuaderno de implementación.
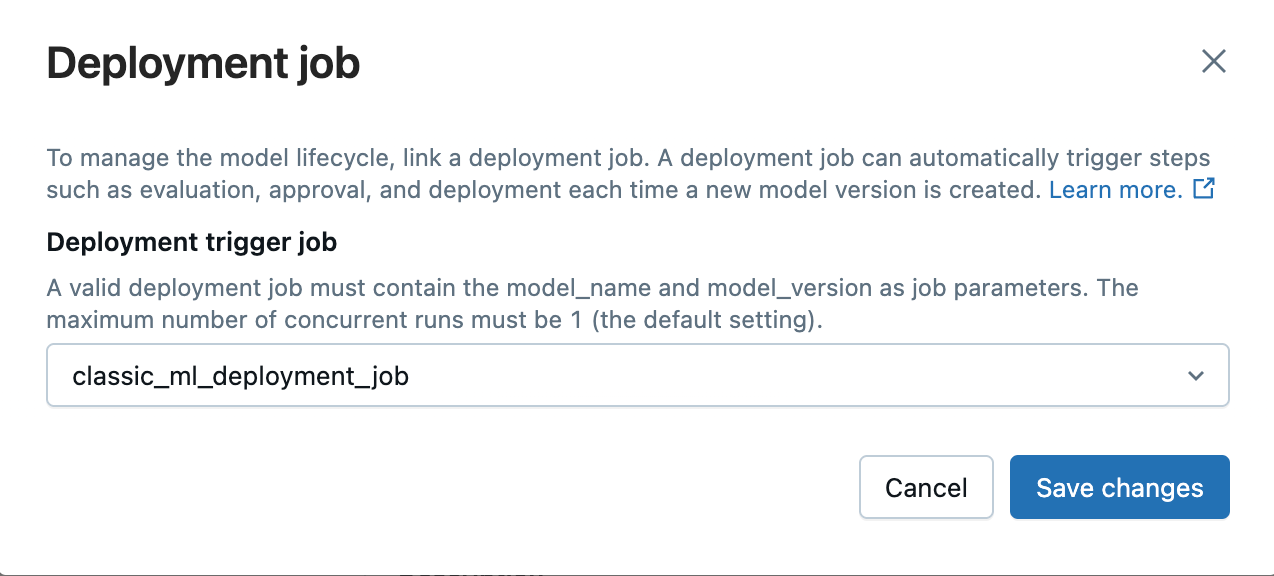
Una vez que un trabajo de implementación se ha conectado a un modelo, está vinculado en la página del modelo.
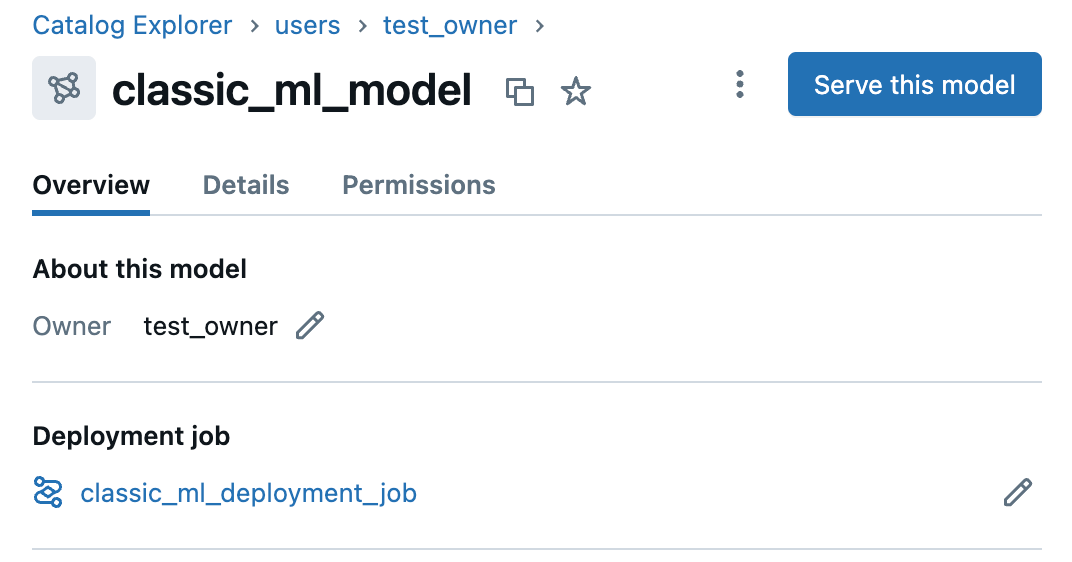
Conexión del trabajo de implementación a un modelo mediante la interfaz de usuario
En la página del modelo, en la pestaña Información general , en Trabajo de implementación, haga clic en Conectar trabajo de implementación.
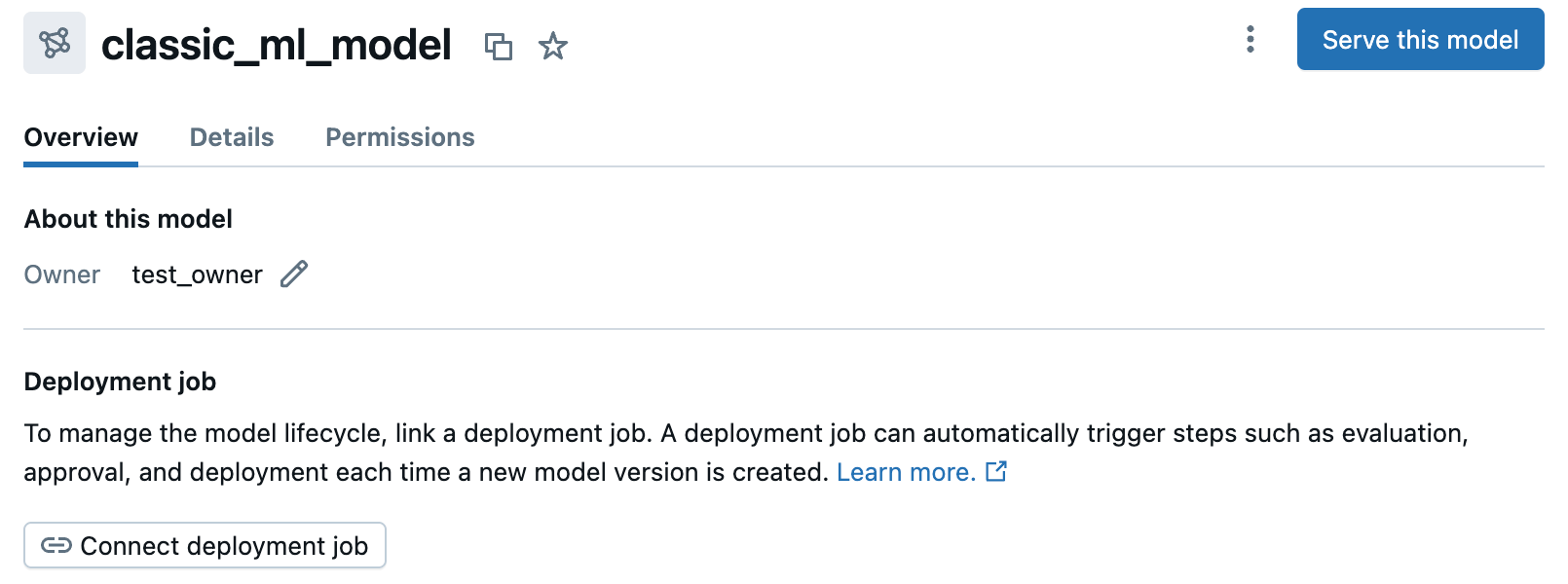
Seleccione el trabajo de implementación en la lista desplegable. También puede usar la barra de búsqueda para buscar trabajos por su nombre o identificador. Haga clic en Guardar cambios.
Conexión del trabajo de implementación a un modelo mediante el cliente MLflow
La forma principal de conectar el trabajo de implementación mediante programación es usar el cliente de MLflow. Puede hacerlo al crear un modelo registrado llamando a client.create_registered_model(model_name, deployment_job_id=<your-created-job-id>)o al actualizar un modelo registrado llamando a client.update_registered_model(model_name, deployment_job_id=<your-created-job-id>).
La manera principal de desconectar el trabajo de implementación mediante programación también es usar el cliente de MLflow. Para ello, especifique una cadena "" vacía y llame a update con ella (por ejemplo, client.update_registered_model(model_name, deployment_job_id="")).
Use código similar al siguiente en el cuaderno de implementación:
import mlflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient(registry_uri="databricks-uc")
# model_name specifies the location of a model in Unity Catalog
# model_name should be in the format <catalog>.<schema>.<model>
try:
if client.get_registered_model(model_name):
client.update_registered_model(model_name, deployment_job_id=created_job.job_id)
except mlflow.exceptions.RestException:
client.create_registered_model(model_name, deployment_job_id=created_job.job_id)
Permisos necesarios
Se requieren los siguientes permisos para conectarse y desencadenar trabajos de implementación:
- MANAGE o OWNER en el modelo para conectar el trabajo de implementación
- El propietario del modelo deberá tener permisos CAN MANAGE RUN o permisos superiores en el trabajo de implementación para establecer la conexión.
- NOTA: Este campo de trabajo de implementación también se puede actualizar en el modelo por parte de alguien con permisos MANAGE o superior. En este caso, tanto el actualizador como el propietario del modelo deberán tener permisos CAN MANAGE RUN o superior en el trabajo de implementación para conectarlo.
Iniciar el trabajo de implementación
El trabajo de implementación se desencadenará automáticamente en cualquier versión de modelo nueva que se cree y también se puede desencadenar manualmente en versiones existentes e implementadas previamente en la página versión del modelo haciendo clic en Iniciar trabajo de implementación.
El trabajo también se puede desencadenar directamente desde la interfaz de usuario de trabajos o la API. El nombre y la versión del modelo adecuados deben especificarse en los parámetros del trabajo.
Permisos necesarios
Los permisos siguientes son necesarios para desencadenar trabajos de implementación:
- Para desencadenar o reparar manualmente el trabajo de implementación mediante la interfaz de usuario de la versión del modelo, el usuario debe tener ACL de CAN MANAGE RUN o superiores en el trabajo de implementación (las mismas ACL necesarias para desencadenar un trabajo mediante la interfaz de usuario de trabajos).
- Ya que el trabajo se activa automáticamente cuando se crea una nueva versión y utiliza las credenciales del propietario del modelo, este debe tener permisos CAN MANAGE RUN o permisos ACL superiores en el trabajo de implementación.
Aprobar el trabajo de implementación (experimental)
Databricks proporciona un mecanismo de aprobación experimental para los trabajos de implementación, lo que permite un proceso con intervención humana para las canalizaciones de ML. Una vez activado un trabajo de implementación, las métricas de la ejecución de evaluación aparecen en la página de la versión del modelo. Después de revisar estas métricas, un aprobador puede aprobar la versión del modelo en la interfaz de usuario haciendo clic en Aprobar. Esta característica usa etiquetas de Unity Catalog para determinar si la tarea de aprobación debe aprobarse o rechazarse. Las tareas de aprobación se identifican mediante nombres de tareas de trabajo que comienzan por "aprobación" (sin distinción entre mayúsculas y minúsculas) y se considerarán completadas cuando la etiqueta del Catálogo de Unity esté establecida en Approved (ya sea haciendo clic en el botón Aprobación de la interfaz de usuario o de esa manera).
Este es el funcionamiento del proceso de aprobación:
- Ejecución inicial: la primera ejecución del trabajo de implementación siempre producirá un error en una tarea de aprobación porque la versión del modelo aún no se ha aprobado y, por tanto, no tiene la etiqueta de catálogo de Unity necesaria.
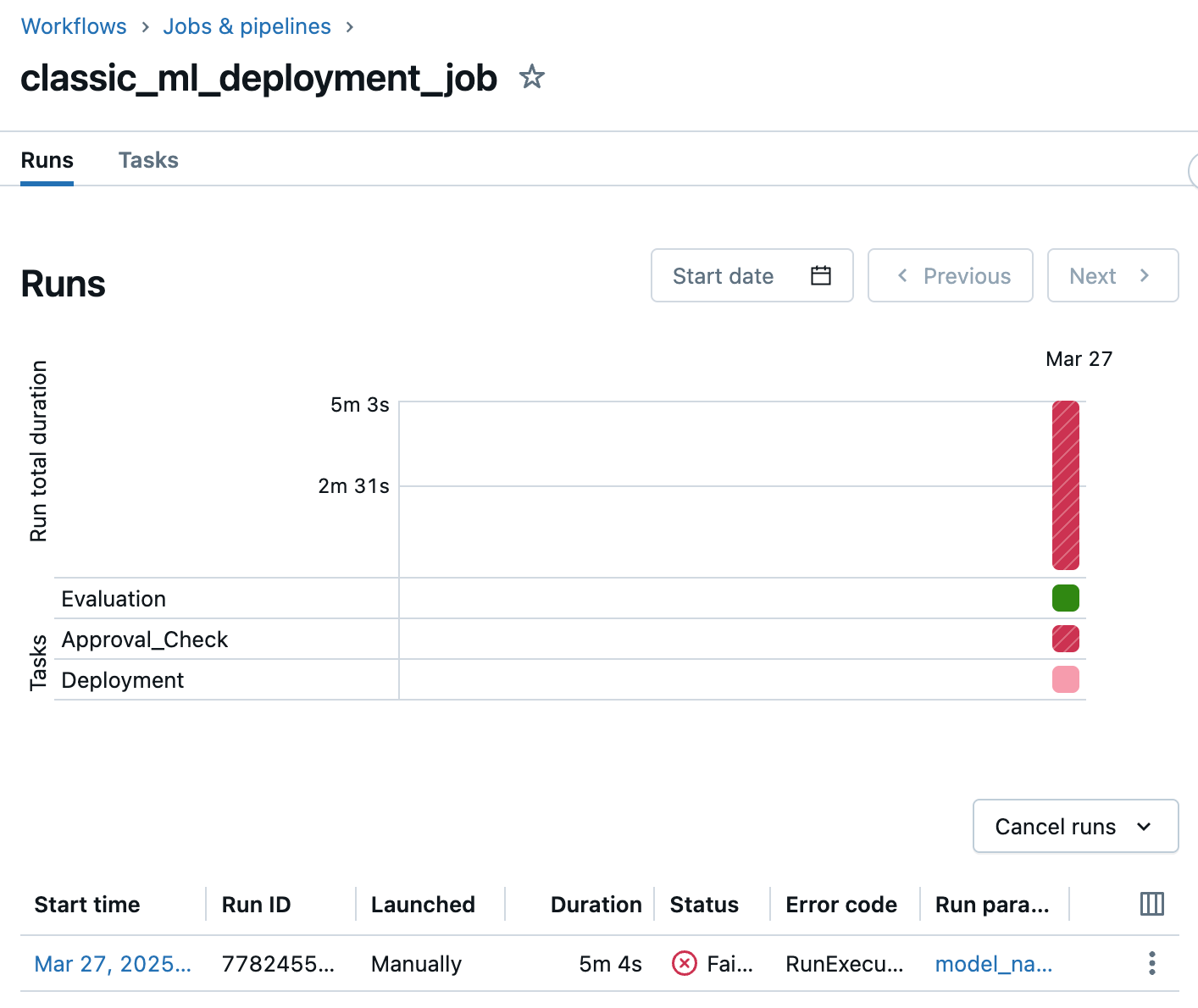
- Evaluación de aprobación: el aprobador revisa la versión del modelo y sus métricas de evaluación, que se muestran en la página versión del modelo. Esto permite al aprobador evaluar la calidad y la preparación de la versión del modelo.
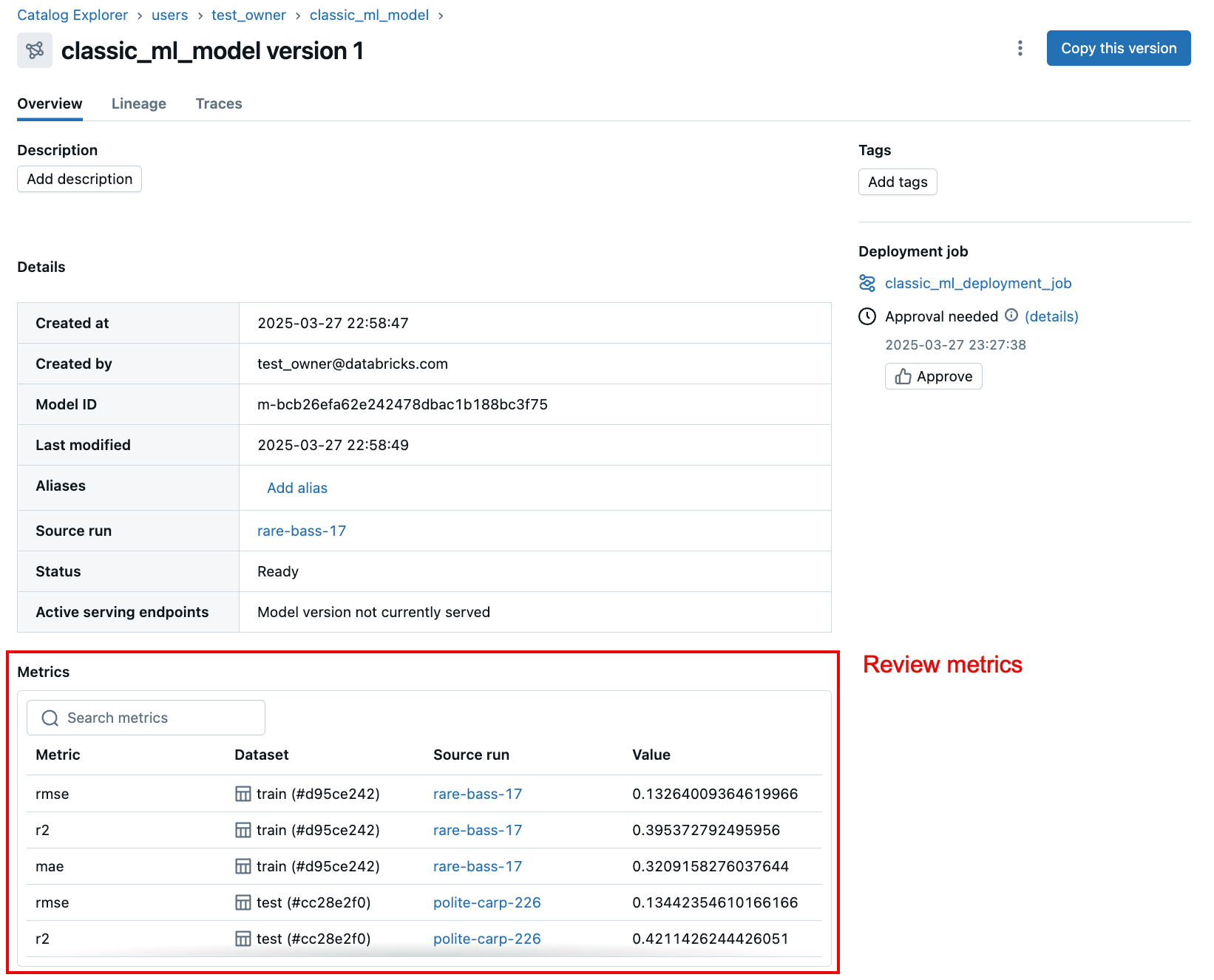
- Acción de aprobación: si el aprobador considera que la versión del modelo es satisfactoria, hacen clic en el botón Aprobar de la sección barra lateral del trabajo de implementación de la página versión del modelo.
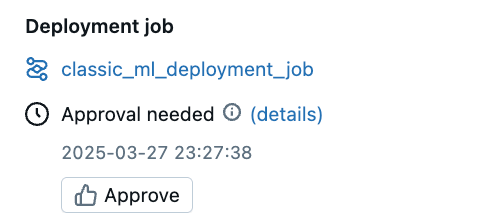
Esta acción repara automáticamente la ejecución del trabajo y agrega una etiqueta de Unity Catálogo a la versión del modelo, donde:
- La clave de etiqueta coincide con el nombre de la tarea de aprobación. Por ejemplo, en el cuaderno de aprobación de ejemplo, es
Approval_Check. - El valor de etiqueta se establece en
Approved.
- Continuación del trabajo: el trabajo de implementación que ha sido reparado se reanuda automáticamente a partir de la tarea de aprobación. Esta vez, se aprueba porque la etiqueta del Unity Catalog necesaria ahora está presente. A continuación, continúa con las tareas posteriores, como la implementación.
Permisos necesarios
Los permisos siguientes son necesarios para agregar etiquetas de Catálogo de Unity y desencadenar trabajos de implementación:
- APPLY TAG en el modelo de Unity Catalog.
- CAN MANAGE RUN en el trabajo de implementación.
Visualización del estado del trabajo de implementación y el registro de actividad
Una vez que los trabajos de implementación se han desencadenado en las versiones del modelo, el estado actual de esas implementaciones se puede ver en la página del modelo en la pestaña Información general . Debajo del estado, puede ver la actividad histórica en el registro de actividad. El registro de actividad también se muestra en la página de versión del modelo.
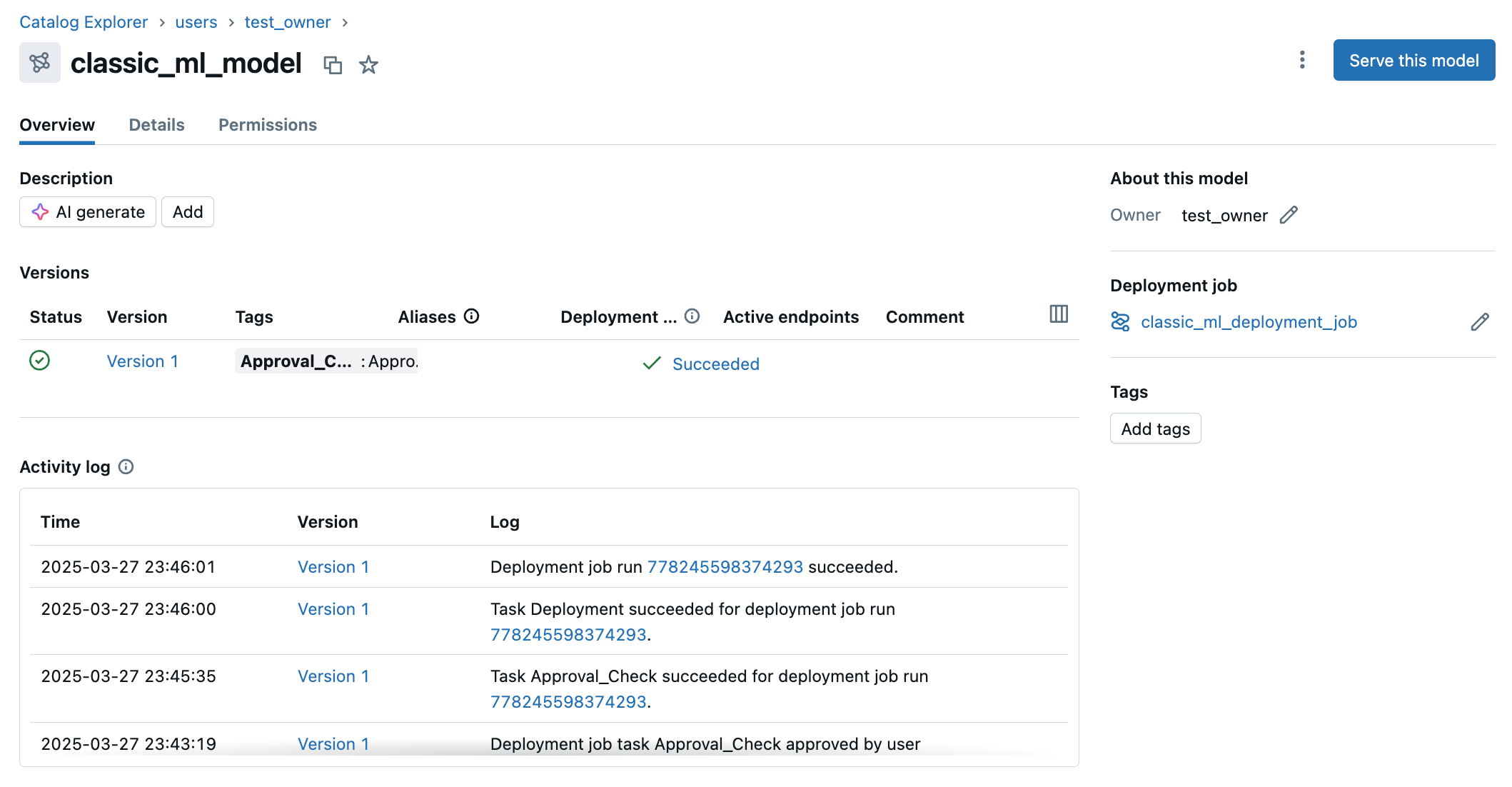
Permisos necesarios
Los permisos siguientes son necesarios para ver los trabajos de implementación y el registro de actividad (igual que ver el modelo):
- EXECUTE en el modelo de Unity Catalog.
Ejemplo de cuadernos de plantilla para trabajos de implementación
Los cuadernos de ejemplo siguientes se pueden usar como plantilla para crear un trabajo de implementación simple que consta de tareas de evaluación, aprobación e implementación. Asegúrese de proporcionar los REQUIRED valores en los cuadernos para configurar el trabajo de implementación a su modelo.
Cuaderno de evaluación para GenAI
Cuaderno de evaluación de ejemplo para GenAI
Cuaderno de evaluación para Aprendizaje Automático clásico
Cuaderno de evaluación de ejemplo para el ML clásico
Cuaderno de aprobación
Cuaderno de aprobación de ejemplo
Cuaderno de implementación
Cuaderno de despliegue de ejemplo
Creación de un cuaderno de trabajo de implementación
Cuaderno de ejemplo para crear un trabajo de implementación
Pasos siguientes
Para obtener más información sobre las nuevas características de MLflow 3 y empezar, consulte el siguiente artículo: